
Gemini 3 Pro disponível no nível gratuito do Ollama, e os desenvolvedores imediatamente perceberam. Você não precisa mais de uma assinatura paga do Cloud Max ou Pro para experimentar um dos modelos multimodais mais capazes disponíveis. Além disso, esta integração traz o raciocínio de ponta do Gemini 3 Pro diretamente para o fluxo de trabalho familiar do Ollama que milhões já usam para modelos locais.
A seguir, você explorará o que mudou, como configurá-lo e como maximizar o desempenho em hardware de consumidor.
O que mudou com o Gemini 3 Pro no Ollama?
O Ollama inicialmente restringia o Gemini 3 Pro aos planos pagos do Ollama Cloud. No entanto, em 18 de novembro de 2025, a conta oficial do Ollama anunciou que o modelo agora aparece no nível gratuito, juntamente com os níveis Pro e Max.
Agora você executa um único comando:
ollama run gemini-3-pro-preview
Este comando baixa e executa o modelo sem barreiras de cobrança adicionais. Além disso, o modelo suporta uma janela de contexto de 1M de tokens, entradas multimodais nativas (texto, imagens, áudio, vídeo) e capacidades agenticas avançadas.
| Nível | Acesso ao Gemini 3 Pro | Limites de Taxa (aprox.) | Custo |
|---|---|---|---|
| Grátis | Sim (prévia) | Moderado | $0 |
| Pro | Sim | Mais alto | Pago |
| Max | Sim | Mais alto ainda | Mais caro |
Essa mudança democratiza o acesso. Consequentemente, desenvolvedores independentes, pesquisadores e entusiastas ganham o mesmo raciocínio de ponta que antes exigia assinaturas corporativas.
Pré-requisitos antes de começar
Você precisa Instalar a versão mais recente do Ollama — A versão 0.3.12 ou mais nova lida com modelos hospedados na nuvem sem problemas. Baixe em https://ollama.com/download.
Passo a passo: Executando o Gemini 3 Pro Preview no nível gratuito
Siga estes passos exatos para iniciar o modelo.
Primeiro, abra seu terminal e verifique se o Ollama está em execução:
ollama --version
Você deve ver a versão 0.3.12 ou superior.
Segundo, baixe e execute o modelo diretamente:
ollama run gemini-3-pro-preview
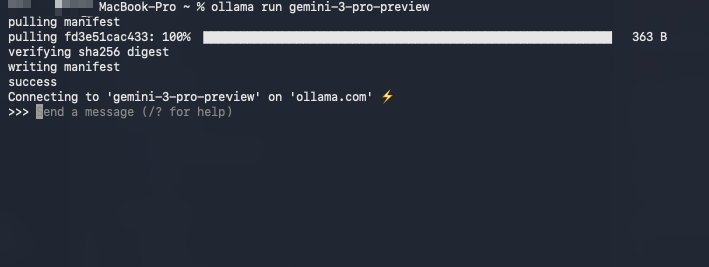
O Ollama detecta automaticamente sua elegibilidade para o nível gratuito e se conecta ao backend do Google via sua chave de API (armazenada de forma segura após a primeira execução). Além disso, a primeira execução solicita a chave, caso não a encontre.
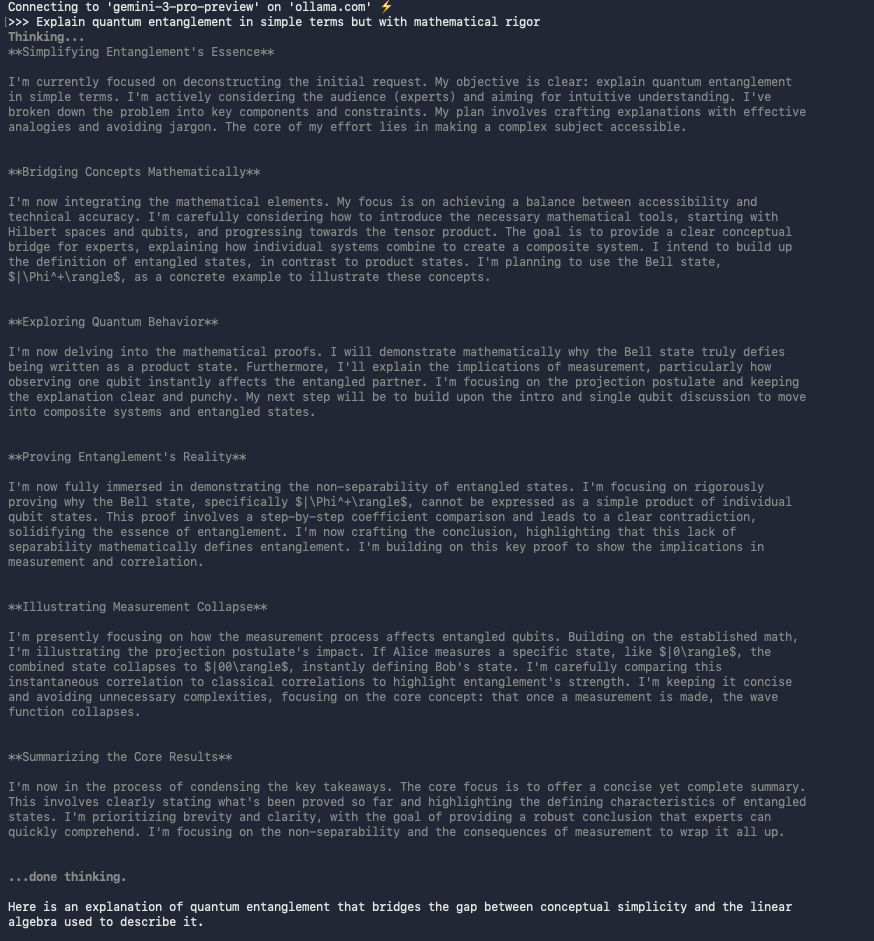
Terceiro, teste a interação básica:
>>> Explain quantum entanglement in simple terms but with mathematical rigor.
O modelo responde com explicações claras, muitas vezes incluindo equações formatadas em LaTeX.
Além disso, você pode carregar imagens ou documentos diretamente em ferramentas como o Open WebUI.
Testando a API do Gemini diretamente com o Apidog
Às vezes, você precisa de acesso direto ao endpoint do Gemini para scripts ou integração. O Apidog se destaca aqui porque suporta geração automática de requisições, variáveis de ambiente e validação de respostas.
Veja como testar o mesmo modelo via o endpoint oficial:
Abra o Apidog e crie uma nova requisição.
Defina o método como POST e a URL como:
https://generativelanguage.googleapis.com/v1/models/gemini-3-pro-preview:generateContent
Adicione o parâmetro de consulta: key=SUA_CHAVE_API
No corpo (JSON), use:
{
"contents": [{
"parts": [{
"text": "Compare Gemini 3 Pro to GPT-4o on reasoning benchmarks."
}]
}]
}
Envie a requisição.
O Apidog formata automaticamente a resposta, destaca o uso de tokens e permite que você salve a requisição como uma coleção. Essa abordagem se mostra inestimável quando você encadeia chamadas ou constrói agentes.
Capacidades Multimodais: Visão, Áudio e Vídeo
O Gemini 3 Pro se destaca com processamento multimodal nativo. Por exemplo, você pode alimentá-lo com uma URL de imagem ou arquivo local:
ollama run gemini-3-pro-preview
>>> (enviar imagem de um diagrama de circuito)
Explique este esquema e sugira melhorias para eficiência.
O modelo analisa o diagrama, identifica componentes e propõe otimizações. Da mesma forma, você processa quadros de vídeo ou transcrições de áudio na mesma sessão.
Na prática, os desenvolvedores relatam desempenho superior em tarefas de compreensão de documentos em comparação com o Gemini 1.5 Pro anterior, especialmente com PDFs mistos de texto/imagem.
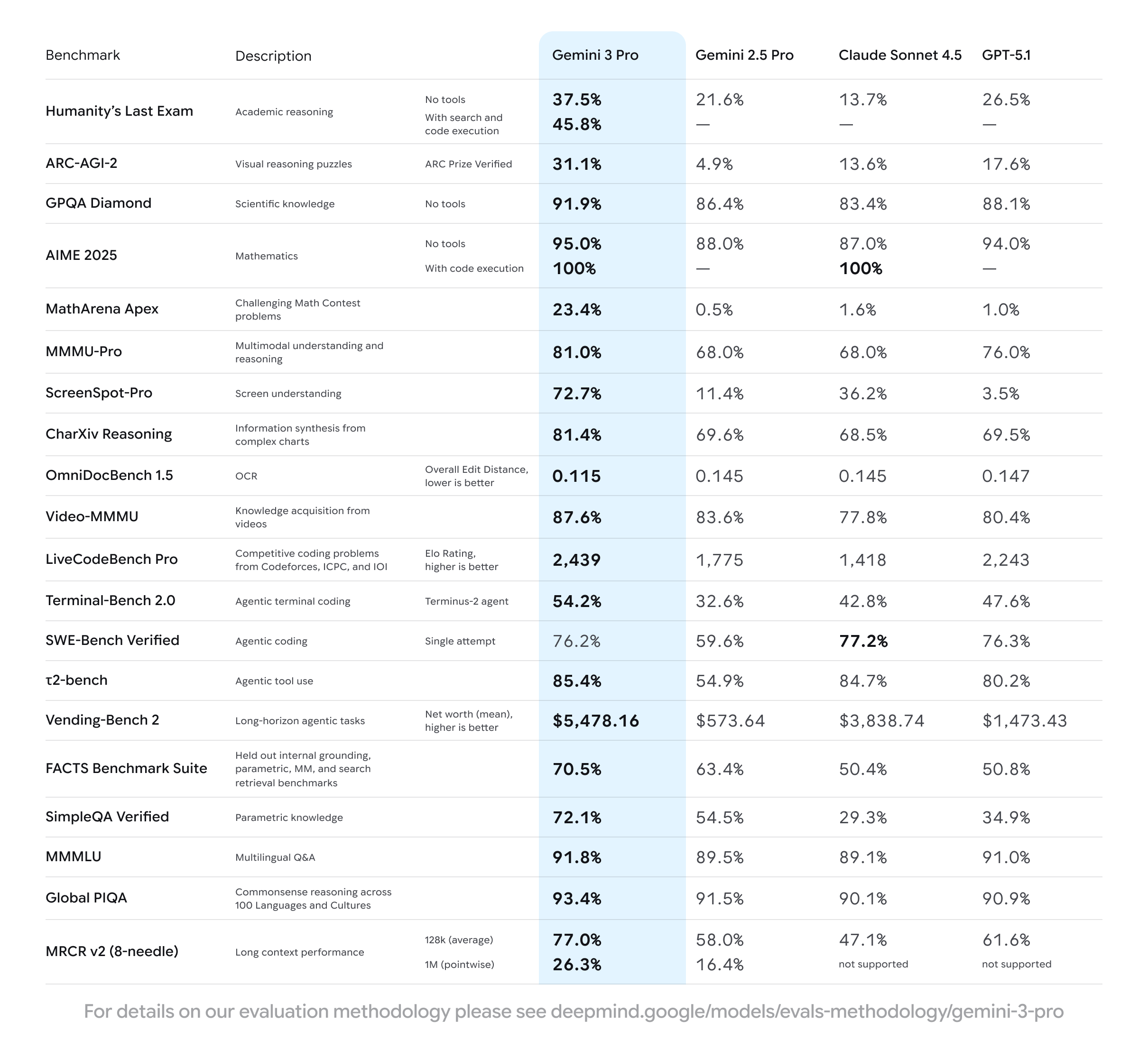
Benchmarks de Desempenho e Testes do Mundo Real
Testes independentes realizados em 18 de novembro de 2025 mostram o Gemini 3 Pro alcançando:
- MMLU-Pro: 88,2%
- GPQA Diamond: 82,7%
- LiveCodeBench: 74,1%
- MMMU (multimodal): 78,5%
Além disso, a velocidade de saída no nível gratuito é em média de 45 a 60 tokens/segundo para prompts somente de texto, o que rivaliza com os níveis pagos de modelos concorrentes.
Você obtém respostas ainda mais rápidas usando o frontend Open WebUI ou integrando-se via o endpoint compatível com OpenAI que o Ollama expõe.
Integrando o Gemini 3 Pro em Aplicações
O Ollama expõe uma API compatível com OpenAI em http://localhost:11434/v1. Portanto, você pode apontar qualquer projeto LangChain, LlamaIndex ou Haystack para ele:
from openai import OpenAI
client = OpenAI(
base_url="http://localhost:11434/v1",
api_key="ollama", # chave fictícia
)
response = client.chat.completions.create(
model="gemini-3-pro-preview",
messages=[{"role": "user", "content": "Write a FastAPI endpoint for user auth."}]
)
print(response.choices[0].message.content)
Esta compatibilidade significa que você pode trocar pelo Gemini 3 Pro sem reescrever bases de código construídas para modelos GPT.
Limitações do nível gratuito que você deve conhecer
O acesso gratuito inclui limites de taxa generosos, mas finitos. Usuários intensivos atingem os limites de cerca de 50 a 100 requisições por minuto, dependendo da região e da carga. Além disso, o modelo permanece hospedado na nuvem, então a latência depende da sua conexão (tipicamente 800-1500ms TTF).
Para uso ilimitado, faça upgrade para o Ollama Pro ou Max, mas a maioria dos desenvolvedores considera o nível gratuito suficiente para prototipagem e trabalho diário.

Uso Avançado: Chamada de Função e Uso de Ferramentas
O Gemini 3 Pro suporta chamada de função nativa. Defina ferramentas em seu Modelfile ou via API:
{
"tools": [{
"type": "function",
"function": {
"name": "get_weather",
"description": "Get current weather",
"parameters": { ... }
}
}]
}
O modelo então decide quando chamar suas funções, permitindo fluxos de trabalho agenticos como navegação na web ou consultas a bancos de dados.
Solucionando problemas comuns
- Erro 401/403: Gere novamente sua chave de API do Gemini e execute
ollama runnovamente para reautenticar. - Modelo não encontrado: Atualize o Ollama (
ollama update) e tente novamente. - Respostas lentas: Mude para uma conexão com fio ou use durante horários de pico.
- Multimodal falha: Certifique-se de que está usando a versão mais recente do Ollama e carregue os arquivos via clientes suportados (Open WebUI funciona melhor).
Por que isso importa para os desenvolvedores em 2025
Agora você acessa inteligência de nível de ponta com custo zero de infraestrutura. Isso nivela drasticamente o campo de atuação. Pequenas equipes constroem agentes sofisticados, pesquisadores comparam com o modelo SOTA mais recente e entusiastas exploram a IA multimodal – tudo sem aprovação de orçamento.
Além disso, combinar isso com ferramentas como o Apidog para gerenciamento de API acelera os ciclos de desenvolvimento de dias para horas.
Conclusão: Comece a usar o Gemini 3 Pro hoje
Execute ollama run gemini-3-pro-preview agora mesmo e experimente a diferença por si mesmo. O Google e o Ollama acabaram de remover a maior barreira para a experimentação avançada de IA.
Baixe o Apidog gratuitamente hoje para potencializar seu fluxo de trabalho de teste de API – seja para depurar requisições do Gemini ou construir aplicações full-stack em torno do Ollama.
O futuro da IA aberta e acessível chegou. Você só precisa de um comando para fazer parte dele.