
Desenvolvedores buscam constantemente maneiras eficientes de integrar modelos avançados de IA em aplicativos. A API Gemini 3 Flash oferece uma opção poderosa que equilibra alta inteligência com velocidade e custo-benefício.
O Google continua a avançar suas ofertas de IA generativa. Além disso, o modelo Gemini 3 Flash se destaca na linha atual. Engenheiros o acessam através da API Gemini, permitindo prototipagem rápida e implantação em produção.
Obtendo Sua Chave API Gemini
Você começa adquirindo uma chave API. Primeiro, navegue até o Google AI Studio em aistudio.google.com. Faça login com sua conta Google, se necessário. Em seguida, selecione o modelo de pré-visualização Gemini 3 Flash dentre as opções disponíveis. Depois, clique na opção para gerar uma chave API.
O Google fornece esta chave instantaneamente. Além disso, guarde-a com segurança — trate-a como credenciais sensíveis. Você a utiliza no cabeçalho x-goog-api-key para todas as requisições. Alternativamente, defina-a como uma variável de ambiente para conveniência em scripts.
Sem uma chave válida, as requisições falham imediatamente com erros de autenticação. Portanto, verifique a funcionalidade da chave desde o início, testando na interface interativa do Google AI Studio.
Entendendo as Capacidades do Gemini 3 Flash
O Gemini 3 Flash entrega inteligência de nível Pro em velocidades Flash. Especificamente, o ID do modelo permanece gemini-3-flash-preview durante sua fase de pré-visualização. Ele suporta uma janela de contexto de entrada massiva de 1.048.576 tokens e um limite de saída de 65.536 tokens.
Além disso, ele lida com entradas multimodais de forma eficaz. Você pode fornecer texto, imagens, vídeos, áudio e PDFs. As saídas consistem principalmente em texto, com opções para JSON estruturado via imposição de esquema.
Os recursos chave incluem controle de raciocínio integrado. Desenvolvedores ajustam a profundidade de pensamento usando o parâmetro thinking_level: minimal, low, medium ou high (padrão). O nível 'high' maximiza a qualidade do raciocínio, enquanto níveis mais baixos priorizam a latência para cenários de alto rendimento.
Além disso, controle a resolução de mídia para tarefas de visão. As opções variam de 'low' a 'ultra_high', influenciando o consumo de tokens por quadro ou imagem. Escolha apropriadamente — 'high' para imagens detalhadas, 'medium' para documentos.
O modelo integra ferramentas como aterramento do Google Search, execução de código e chamada de funções. No entanto, ele exclui geração de imagens e certas ferramentas avançadas de robótica.
Preços para a API Gemini 3 Flash
O gerenciamento de custos é importante nas integrações de API. O Gemini 3 Flash opera em um modelo de pagamento conforme o uso. Tokens de entrada custam US$ 0,50 por milhão, enquanto tokens de saída (incluindo tokens de pensamento) custam US$ 3 por milhão.
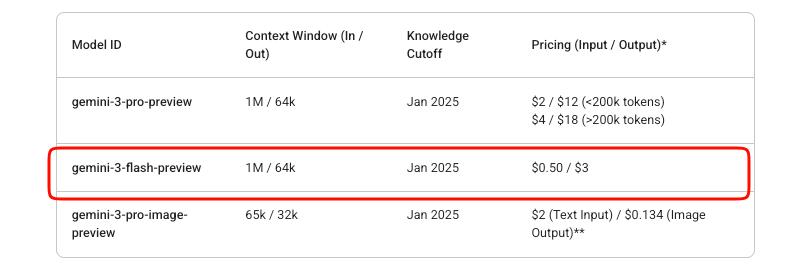
O Google oferece experimentação gratuita no AI Studio. No entanto, o uso da API em produção incorre em cobranças assim que o faturamento é ativado. Não existe um nível gratuito além das avaliações do Studio para este modelo de pré-visualização.
O cache de contexto e o processamento em lote ajudam a otimizar ainda mais os custos. O cache reduz o processamento redundante de tokens para contextos repetidos. A API de lote é adequada para trabalhos assíncronos de alto volume.
Monitore o uso através dos painéis de Faturamento do Google Cloud. Picos repentinos geralmente resultam de configurações de media_resolution altas ou raciocínio extensivo.
Fazendo Sua Primeira Requisição à API
Você começa com a geração simples de texto. O endpoint é https://generativelanguage.googleapis.com/v1beta/models/gemini-3-flash-preview:generateContent.
Construa uma requisição POST. Inclua sua chave API nos cabeçalhos. O corpo contém `contents` como um array de objetos `role-part`.
Aqui está um exemplo básico de cURL:
curl "https://generativelanguage.googleapis.com/v1beta/models/gemini-3-flash-preview:generateContent" \
-H "x-goog-api-key: YOUR_API_KEY" \
-H "Content-Type: application/json" \
-X POST \
-d '{
"contents": [{
"parts": [{"text": "Explain quantum entanglement briefly."}]
}]
}'
A resposta retorna candidatos com partes de texto. Além disso, lide com metadados de uso para contagens de tokens.
Para respostas de streaming, use o endpoint `:streamGenerateContent`. Isso gera resultados parciais incrementalmente, melhorando a latência percebida em aplicativos.
Integrando com SDKs Oficiais
O Google mantém SDKs que simplificam as interações. Instale o pacote Python via pip install google-generativeai.
Inicialize o cliente:
import google.generativeai as genai
genai.configure(api_key="YOUR_API_KEY")
model = genai.GenerativeModel("gemini-3-flash-preview")
response = model.generate_content("Summarize recent AI advancements.")
print(response.text)
O SDK gerencia automaticamente as assinaturas de pensamento para conversas multi-turno e uso de ferramentas. Consequentemente, prefira SDKs em vez de HTTP puro para código de produção.
Usuários de Node.js acessam conveniência semelhante através de @google/generative-ai.
Lidando com Entradas Multimodais
O Gemini 3 Flash se destaca no processamento multimodal. Faça upload de arquivos ou forneça URIs de dados inline.
Em Python:
model = genai.GenerativeModel("gemini-3-flash-preview")
image = genai.upload_file("diagram.png")
response = model.generate_content(["Describe this image in detail.", image])
print(response.text)
Ajuste media_resolution na configuração de geração para eficiência de tokens:
generation_config = {
"media_resolution": "media_resolution_high"
}
Vídeos e PDFs seguem padrões semelhantes. Além disso, combine múltiplas modalidades em uma única requisição para tarefas de análise complexas.
Recursos Avançados: Níveis de Pensamento e Ferramentas
Controle o raciocínio explicitamente. Defina thinking_level como "low" para respostas rápidas:
"generationConfig": {
"thinking_level": "low"
}
O 'high thinking' permite um processamento interno mais profundo da cadeia de pensamento.
Habilite ferramentas como a chamada de funções. Defina funções na requisição; o modelo retorna chamadas quando apropriado.
Saídas estruturadas impõem esquemas JSON:
"generationConfig": {
"response_mime_type": "application/json",
"response_schema": {...}
}
Combine estes para fluxos de trabalho agentic. Por exemplo, fundamente respostas com pesquisa em tempo real.
Testando e Depurando com Apidog
Testes eficazes garantem integrações confiáveis. O Apidog surge como uma ferramenta robusta para este propósito. Ele combina design de API, depuração, mocking e testes automatizados em uma única plataforma.
Primeiro, importe o endpoint Gemini para o Apidog. Crie uma nova requisição apontando para o método `generateContent`. Armazene sua chave API como uma variável de ambiente — o Apidog suporta múltiplos ambientes para desenvolvimento, staging e produção.
Envie requisições visualmente. O Apidog exibe as respostas claramente, destacando o uso de tokens e erros. Além disso, configure asserções para validar automaticamente as estruturas de resposta.
Para chats multi-turno, mantenha o histórico da conversa entre as requisições usando os scripts ou variáveis do Apidog. Isso simula sessões de usuário reais de forma eficiente.
O Apidog também gera servidores mock. Simule respostas do Gemini durante o desenvolvimento frontend sem consumir cota.
Além disso, automatize suítes de teste. Defina cenários que abrangem diferentes níveis de pensamento, entradas multimodais e casos de erro. Execute-os em pipelines de CI/CD.
Muitos desenvolvedores acham que o Apidog reduz significativamente o tempo de depuração em comparação com cURL puro ou clientes básicos. Sua interface intuitiva lida com corpos JSON complexos sem esforço.
Melhores Práticas para Uso em Produção
Implemente lógica de retentativa com backoff exponencial. Limites de taxa se aplicam, especialmente na pré-visualização.
Armazene contextos em cache sempre que possível para minimizar tokens. Use assinaturas de pensamento precisamente em requisições brutas para evitar erros de validação.
Monitore os custos proativamente. Registre a contagem de tokens de entrada/saída por requisição.
Mantenha a temperatura no padrão 1.0 — desvios degradam o desempenho do raciocínio.
Por fim, mantenha-se atualizado através da documentação oficial. Modelos de pré-visualização evoluem; planeje para possíveis alterações que possam quebrar a compatibilidade.
Conclusão
Agora você possui o conhecimento para integrar o Gemini 3 Flash de forma eficaz. Comece com requisições simples e, em seguida, expanda para aplicativos multimodais e aprimorados com ferramentas. Aproveite ferramentas como o Apidog para otimizar os fluxos de trabalho de desenvolvimento.
O Gemini 3 Flash capacita os desenvolvedores a criar sistemas inteligentes e responsivos de forma acessível. Experimente livremente no AI Studio e, em seguida, faça a transição para a API para implantação.