
Imagine ter a capacidade de extrair dados de qualquer site e reunir insights em grande escala—tudo isso com apenas algumas linhas de código. Parece mágica, certo? Bem, Firecrawl torna isso possível.
Neste guia para iniciantes, vou te mostrar tudo que você precisa saber sobre o Firecrawl, desde a instalação até técnicas avançadas de extração de dados. Seja você um desenvolvedor, analista de dados ou apenas curioso sobre web scraping, este tutorial vai te ajudar a começar com o Firecrawl e integrá-lo em seus fluxos de trabalho.

O que é Firecrawl?
Firecrawl é um mecanismo inovador de web scraping e crawling que converte o conteúdo de sites em formatos como markdown, HTML e dados estruturados. Isso o torna ideal para Modelos de Linguagem de Grande Escala (LLMs) e aplicações de IA. Com o Firecrawl, você pode coletar de forma eficiente dados estruturados e não estruturados de sites, simplificando seu fluxo de trabalho de análise de dados.
Principais Características do Firecrawl
Crawl: Crawling Web Abrangente
O endpoint /crawl do Firecrawl permite que você percorra recursivamente um site, extraindo conteúdo de todas as subpáginas. Este recurso é perfeito para descobrir e organizar grandes quantidades de dados da web, convertendo-os em formatos prontos para LLM.
Scrape: Extração de Dados Dirigida
Use o recurso Scrape para extrair dados específicos de uma única URL. O Firecrawl pode entregar o conteúdo em vários formatos, incluindo markdown, dados estruturados, capturas de tela e HTML. Isso é particularmente útil para extrair informações específicas de URLs conhecidas.
Map: Mapeamento Rápido de Sites
O recurso Map recupera rapidamente todas as URLs associadas a um determinado site, fornecendo uma visão abrangente de sua estrutura. Isso é inestimável para descoberta e organização de conteúdo.
Extract: Transformando Dados Não Estruturados em Formato Estruturado
O endpoint /extract é o recurso alimentado por IA do Firecrawl que simplifica o processo de coleta de dados estruturados de sites. Ele cuida do trabalho pesado de crawling, parsing e organização dos dados em um formato estruturado.
Começando com Firecrawl
Etapa 1: Cadastre-se e Obtenha Sua Chave API
Visite o site oficial do Firecrawl e crie uma conta. Uma vez logado, navegue até seu painel para encontrar sua chave API.
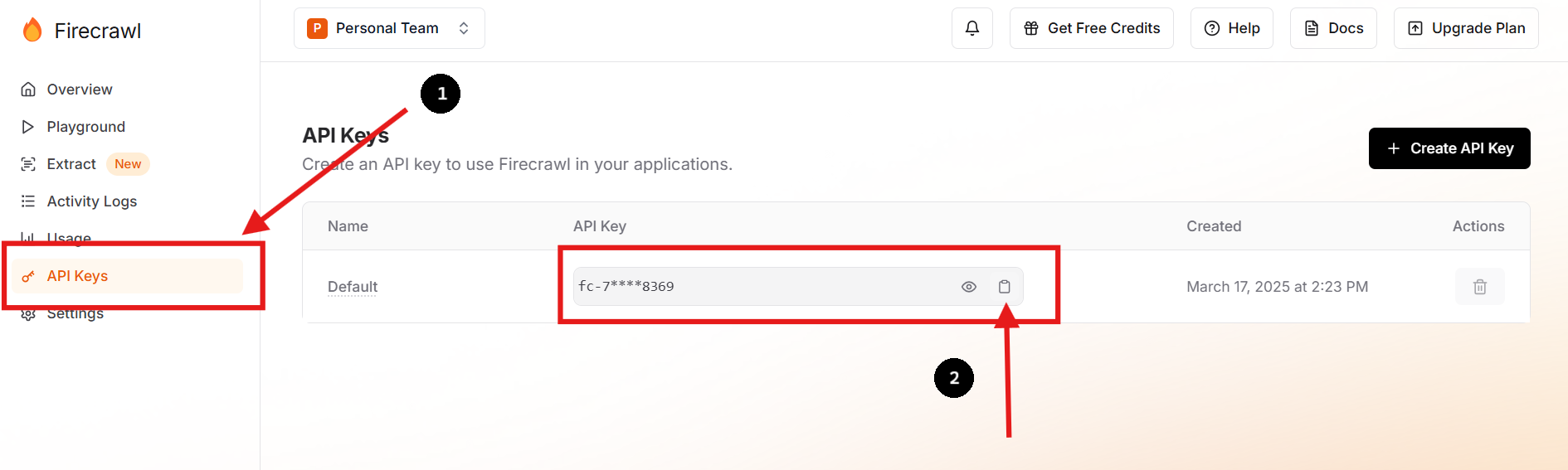
Você também pode criar uma nova chave API e excluir a anterior, se preferir ou precisar fazê-lo.

Etapa 2: Configure Seu Ambiente
No diretório do seu projeto, crie um arquivo .env para armazenar com segurança sua chave API como uma variável de ambiente. Você pode fazer isso executando os seguintes comandos no seu terminal:
touch .env
echo "FIRECRAWL_API_KEY='fc-SUA-CHAVE-AQUI'" >> .envEssa abordagem mantém informações sensíveis fora de seu código principal, aumentando a segurança e simplificando a gestão de configurações.
Etapa 3: Instale o SDK do Firecrawl
Para usuários de Python, instale o SDK do Firecrawl usando pip:
pip install firecrawlEtapa 4: Use a Função "Scrape" do Firecrawl
Aqui está um exemplo simples de como raspar um site usando o SDK Python:
from firecrawl import FirecrawlApp
from dotenv import load_dotenv
import os
# Carregar variáveis de ambiente do arquivo .env
load_dotenv()
# Inicializar FirecrawlApp com a chave API do .env
app = FirecrawlApp(api_key=os.getenv("FIRECRAWL_API_KEY"))
# Defina a URL para raspar
url = "https://www.python-unlimited.com/webscraping/hotels.php?page=1"
# Raspe o site
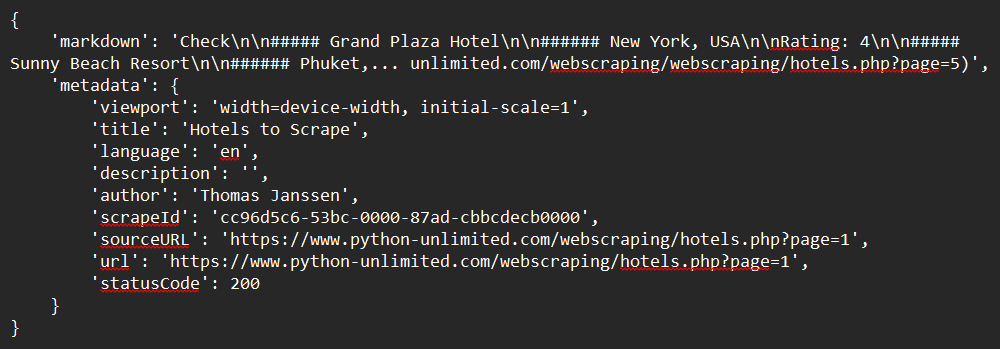
response = app.scrape_url(url)
# Imprima a resposta
print(response)Saída de Exemplo:
Etapa 5: Use a Função "Crawl" do Firecrawl
Aqui veremos um exemplo simples de como fazer crawling em um site usando o SDK Python:
from firecrawl import FirecrawlApp
from dotenv import load_dotenv
import os
# Carregar variáveis de ambiente do arquivo .env
load_dotenv()
# Inicializar FirecrawlApp com a chave API do .env
app = FirecrawlApp(api_key=os.getenv("FIRECRAWL_API_KEY"))
# Fazer crawling em um site e capturar a resposta:
crawl_status = app.crawl_url(
'https://www.python-unlimited.com/webscraping/hotels.php?page=1',
params={
'limit': 100,
'scrapeOptions': {'formats': ['markdown', 'html']}
},
poll_interval=30
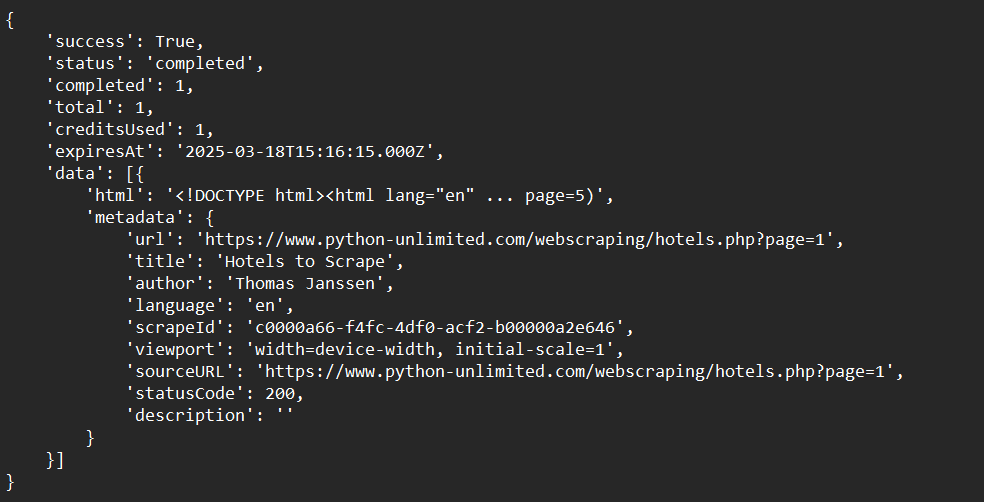
)
print(crawl_status)Saída de Exemplo:
Etapa 6: Use a Função "Map" do Firecrawl
Aqui está um exemplo simples de como mapear dados de um site usando o SDK Python:
from firecrawl import FirecrawlApp
from dotenv import load_dotenv
import os
# Carregar variáveis de ambiente do arquivo .env
load_dotenv()
# Inicializar FirecrawlApp com a chave API do .env
app = FirecrawlApp(api_key=os.getenv("FIRECRAWL_API_KEY"))
# Mapear um site:
map_result = app.map_url('https://www.python-unlimited.com/webscraping/hotels.php?page=1')
print(map_result)Saída de Exemplo:

Etapa 7: Use a Função "Extract" do Firecrawl (Beta Aberta)
Abaixo está um exemplo simples de como extrair dados de um site usando o SDK Python:
from firecrawl import FirecrawlApp
from pydantic import BaseModel, Field
from dotenv import load_dotenv
import os
# Carregar variáveis de ambiente do arquivo .env
load_dotenv()
# Inicializar FirecrawlApp com a chave API do .env
app = FirecrawlApp(api_key=os.getenv("FIRECRAWL_API_KEY"))
# Definir esquema para extrair conteúdos
class ExtractSchema(BaseModel):
company_mission: str
supports_sso: bool
is_open_source: bool
is_in_yc: bool
# Chamar a função de extração e capturar a resposta
response = app.extract([
'https://docs.firecrawl.dev/*',
'https://firecrawl.dev/',
'https://www.ycombinator.com/companies/'
], {
'prompt': "Extraia os dados fornecidos no esquema.",
'schema': ExtractSchema.model_json_schema()
})
# Imprimir a resposta
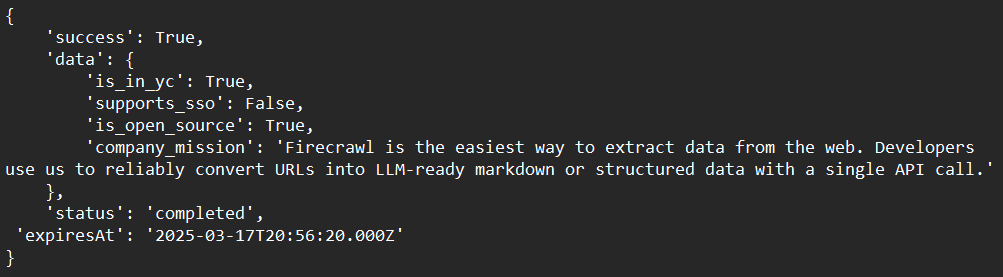
print(response)Saída de Exemplo:
Técnicas Avançadas com Firecrawl
Manipulando Conteúdo Dinâmico
O Firecrawl pode lidar com conteúdo dinâmico baseado em JavaScript usando navegadores sem cabeça para renderizar páginas antes da raspagem. Isso garante que você capture todo o conteúdo, mesmo que seja carregado dinamicamente.
Contornando Bloqueios de Web Scraping
Use os recursos embutidos do Firecrawl para contornar bloqueios comuns de web scraping, como CAPTCHAs ou limites de taxa. Isso envolve a rotação de agentes de usuário e endereços IP para imitar o tráfego natural.
Integrando com LLMs
Combine o Firecrawl com LLMs como LangChain para construir fluxos de trabalho de IA poderosos. Por exemplo, você pode usar o Firecrawl para coletar dados e, em seguida, alimentá-los em um LLM para tarefas de análise ou geração.
Solucionando Problemas Comuns
Problema: "Chave API Não Reconhecida"
Solução: Certifique-se de que sua chave API está armazenada corretamente como uma variável de ambiente ou em um arquivo .env.
Problema: "Crawling Muito Lento"
Solução: Use crawling assíncrono para acelerar o processo. O Firecrawl suporta requisições simultâneas para melhorar a eficiência.
Problema: "Conteúdo Não Extraído Corretamente"
Solução: Verifique se o site usa conteúdo dinâmico. Se sim, assegure-se de que o Firecrawl esteja configurado para lidar com a renderização em JavaScript.
Conclusão
Parabéns por completar este guia abrangente para iniciantes sobre Firecrawl! Nós cobrimos tudo o que você precisa para começar—desde o que é o Firecrawl, até instruções detalhadas de instalação, exemplos de uso e opções avançadas de personalização. Agora, você deve ter uma compreensão clara de como:
- Configurar e instalar o Firecrawl em seu ambiente de desenvolvimento.
- Configurar e executar o Firecrawl para raspar, crawlar, mapear e extrair dados de forma eficiente.
- Solucionar problemas em seus processos de crawling para atender às suas necessidades específicas.
O Firecrawl é uma ferramenta incrivelmente poderosa que pode simplificar significativamente seus fluxos de trabalho de extração de dados. Sua flexibilidade, eficiência e facilidade de integração a tornam uma escolha ideal para os desafios modernos de crawling na web.
Agora é hora de colocar suas novas habilidades em prática. Comece a experimentar com diferentes sites, ajuste seus parsers e integre com ferramentas adicionais para criar uma solução realmente personalizada que atenda aos seus requisitos únicos.
Pronto para multiplicar por 10 seu fluxo de trabalho de web scraping? Baixe o Apidog gratuitamente hoje e descubra como ele pode aprimorar sua integração com o Firecrawl!