
O domínio da inteligência artificial continua sua rápida expansão, com os Modelos de Linguagem Grandes (LLMs) demonstrando cada vez mais habilidades cognitivas sofisticadas. Entre estes, o FractalAIResearch/Fathom-R1-14B surge como um modelo notável, abrigando aproximadamente 14,8 bilhões de parâmetros. Este modelo foi especificamente projetado pela Fractal AI Research para se destacar em tarefas complexas de raciocínio matemático e geral. O que diferencia o Fathom-R1-14B é sua capacidade de alcançar este alto nível de desempenho com notável eficiência de custo e dentro de uma janela de contexto prática de 16.384 (16K) tokens. Este artigo oferece uma visão técnica do Fathom-R1-14B, detalhando seu desenvolvimento, arquitetura, processos de treinamento, desempenho em benchmarks e fornecendo um guia focado para sua implementação prática com base em métodos estabelecidos.
Fractal AI: Os Inovadores por Trás do Modelo

O Fathom-R1-14B é um produto da Fractal AI Research, a divisão de pesquisa da Fractal, uma distinta empresa de IA e análise sediada em Mumbai, Índia. A Fractal conquistou uma reputação global por fornecer soluções de inteligência artificial e análise avançada para empresas da Fortune 500. A criação do Fathom-R1-14B alinha-se estreitamente com as crescentes ambições da Índia no setor de inteligência artificial.
As Aspirações de IA da Índia
O desenvolvimento deste modelo é particularmente significativo dentro do contexto da Missão IndiaAI. Srikanth Velamakanni, Co-fundador, CEO do Grupo e Vice-Presidente da Fractal, indicou que o Fathom-R1-14B é uma demonstração inicial de uma iniciativa maior. Ele mencionou: "Propusemos construir o primeiro grande modelo de raciocínio (LRM) da Índia como parte da missão IndiaAI... Este [Fathom-R1-14B] é apenas uma pequena prova do que é possível", aludindo a planos para uma série de modelos, incluindo uma versão muito maior de 70 bilhões de parâmetros. Essa direção estratégica destaca um compromisso nacional com a autossuficiência em IA e a criação de modelos fundacionais indígenas. As contribuições mais amplas da Fractal para a IA incluem outros projetos impactantes, como o Vaidya.ai, uma plataforma de IA multimodal para assistência médica. O lançamento do Fathom-R1-14B como uma ferramenta de código aberto, portanto, não apenas beneficia a comunidade global de IA, mas também significa uma conquista chave no cenário de IA em evolução da Índia.
Design Fundacional e Projeto Arquitetônico do Fathom-R1-14B
As impressionantes capacidades do Fathom-R1-14B são construídas sobre uma base cuidadosamente escolhida e um design arquitetônico robusto, otimizado para tarefas de raciocínio.
A jornada do Fathom-R1-14B começou com a seleção do Deepseek-R1-Distilled-Qwen-14B como seu modelo base. A natureza "destilada" deste modelo significa que ele é um derivado mais compacto e computacionalmente eficiente de um modelo pai maior, especificamente projetado para reter uma porção significativa das capacidades originais, particularmente aquelas da renomada família Qwen. Isso forneceu um forte ponto de partida, que a Fractal AI Research então meticulosamente aprimorou por meio de técnicas especializadas de pós-treinamento. Para suas operações, o modelo geralmente utiliza precisão bfloat16 (Brain Floating Point Format), que atinge um equilíbrio eficaz entre a velocidade computacional e a precisão numérica necessária para cálculos complexos.
O Fathom-R1-14B é construído sobre a arquitetura Qwen2, uma poderosa iteração dentro da família de modelos Transformer. Os modelos Transformer são o padrão atual para LLMs de alto desempenho, em grande parte devido aos seus inovadores mecanismos de autoatenção. Esses mecanismos permitem que o modelo pondere dinamicamente a importância de diferentes tokens — sejam palavras, subpalavras ou símbolos matemáticos — dentro de uma sequência de entrada ao gerar sua saída. Essa capacidade é crucial para compreender as dependências intrincadas presentes em problemas matemáticos complexos e argumentos lógicos nuançados.
A escala do modelo, caracterizada por aproximadamente 14,8 bilhões de parâmetros, é um fator chave em seu desempenho. Esses parâmetros, que são essencialmente os valores numéricos aprendidos dentro das camadas da rede neural, codificam o conhecimento e as capacidades de raciocínio do modelo. Um modelo desse tamanho oferece capacidade substancial para capturar e representar padrões complexos de seus dados de treinamento.
A Significância da Janela de Contexto de 16K
Uma especificação arquitetônica crítica é sua janela de contexto de 16.384 tokens. Isso determina o comprimento máximo da combinação do prompt de entrada e da saída gerada pelo modelo que pode ser processada em uma única operação. Embora alguns modelos ostentem janelas de contexto muito maiores, a capacidade de 16K do Fathom-R1-14B é uma escolha de design deliberada e pragmática. É suficientemente grande para acomodar declarações de problemas detalhadas, extensas cadeias de raciocínio passo a passo (como frequentemente exigido em matemática de nível Olímpico) e respostas abrangentes. Importante, isso é alcançado sem incorrer na escalabilidade quadrática de custo computacional que pode estar associada aos mecanismos de atenção em sequências extremamente longas, tornando o Fathom-R1-14B mais ágil e menos intensivo em recursos durante a inferência.
Fathom-R1-14B é Realmente, Realmente Custo-Efetivo
Um dos aspectos mais notáveis do Fathom-R1-14B é a eficiência de seu processo de pós-treinamento. A versão primária do modelo foi ajustada (fine-tuned) por um custo relatado de aproximadamente US$ 499. Essa notável viabilidade econômica foi alcançada por meio de uma estratégia de treinamento sofisticada e multifacetada, focada em maximizar as habilidades de raciocínio sem gastos computacionais excessivos.
As técnicas centrais que sustentam essa especialização eficiente incluíram:
- Supervised Fine-Tuning (SFT): Esta fase fundamental envolveu o treinamento do modelo base em um conjunto de dados curado de alta qualidade de pares problema-solução, especificamente adaptado para raciocínio matemático avançado. Através do SFT, o modelo aprendeu a emular caminhos de resolução de problemas corretos e dedução lógica.
- Aprendizagem Curricular Iterativa: Em vez de expor o modelo a todo o espectro de dificuldade de problemas de uma vez, esta estratégia introduz desafios de maneira gradual. O modelo começa com problemas matemáticos mais simples e progressivamente avança para problemas mais complexos, como aqueles do AIME e HMMT. Essa abordagem estruturada facilita uma aprendizagem mais estável e eficaz, permitindo que o modelo construa uma base sólida antes de abordar tarefas altamente desafiadoras. Esta técnica foi central para o desenvolvimento de um modelo precursor chave, o
Fathom-R1-14B-V0.6. - Fusão de Modelos (Model Merging): O modelo final Fathom-R1-14B é uma amalgamação de dois modelos predecessores especificamente ajustados:
Fathom-R1-14B-V0.6(que passou por SFT Curricular Iterativo) eFathom-R1-14B-V0.4(que focou em SFT com "Shortest-Chains", provavelmente enfatizando concisão nas soluções). Ao fundir modelos treinados com focos ligeiramente diferentes, o modelo resultante herda um conjunto mais amplo de pontos fortes.
O objetivo geral deste meticuloso processo de treinamento foi incutir um "raciocínio matemático conciso, porém preciso".
A Fractal AI Research também explorou um caminho de treinamento alternativo com uma variante chamada Fathom-R1-14B-RS. Esta versão incorporou Aprendizagem por Reforço (RL), especificamente usando um algoritmo referido como GRPO (Generalized Reward Pushing Optimization), juntamente com SFT. Embora essa abordagem tenha produzido desempenho alto comparável, seu custo de pós-treinamento foi ligeiramente maior, em US$ 967. O desenvolvimento de ambas as versões sublinha um compromisso com a exploração de diversas metodologias para alcançar desempenho de raciocínio ótimo de forma eficiente. Como parte de seu compromisso com a transparência, a Fractal AI Research tornou os "recipes" de treinamento e os conjuntos de dados de código aberto.
Benchmarks de Desempenho: Quantificando a Excelência em Raciocínio
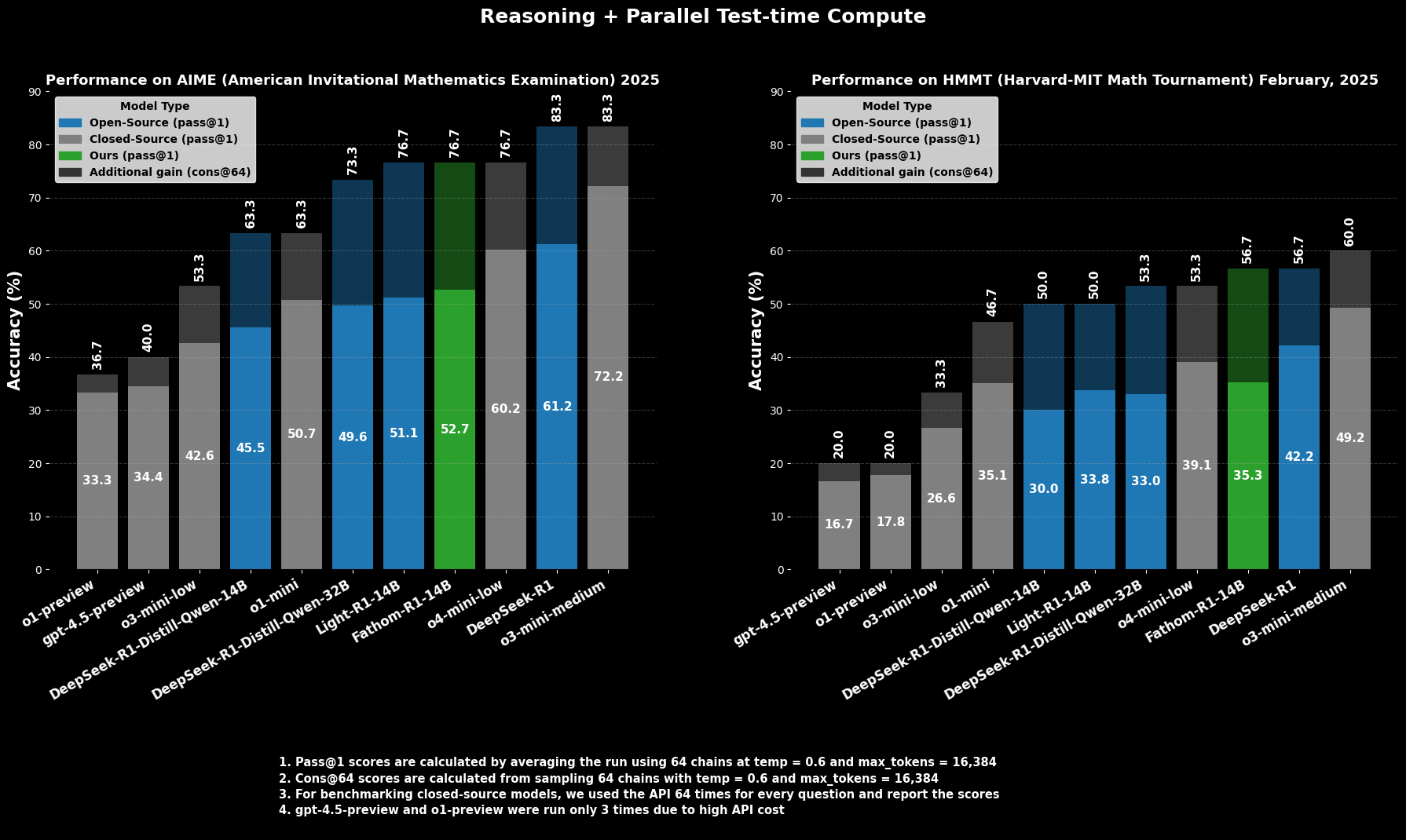
A proficiência do Fathom-R1-14B não é meramente teórica; é substanciada por um desempenho impressionante em benchmarks de raciocínio matemático rigorosos e reconhecidos internacionalmente.
Sucesso em AIME e HMMT
No AIME2025 (American Invitational Mathematics Examination), uma desafiadora competição de matemática pré-universitária, o Fathom-R1-14B alcança uma precisão de Pass@1 de 52,71%. A métrica Pass@1 indica a porcentagem de problemas para os quais o modelo gera uma solução correta em uma única tentativa. Quando permitido um orçamento computacional maior no momento do teste, avaliado usando cons@64 (consistência entre 64 soluções amostradas), sua precisão no AIME2025 sobe para impressionantes 76,7%.
Da mesma forma, no HMMT25 (Harvard-MIT Mathematics Tournament), outra competição de alto nível, o modelo obtém 35,26% Pass@1, que aumenta para 56,7% cons@64. Esses resultados são particularmente notáveis porque são alcançados dentro do orçamento de saída de 16K tokens do modelo, refletindo considerações práticas de implantação.
Desempenho Comparativo
Em avaliações comparativas, o Fathom-R1-14B supera significativamente outros modelos de código aberto de tamanhos semelhantes ou até maiores nesses benchmarks matemáticos específicos em Pass@1. Mais notavelmente, seu desempenho, especialmente ao considerar a métrica cons@64, o posiciona como competitivo com alguns modelos de código fechado capazes, que muitas vezes são presumidos ter acesso a recursos vastamente maiores. Isso destaca a eficiência do Fathom-R1-14B em traduzir seus parâmetros e treinamento em raciocínio de alta fidelidade.
Vamos Tentar Executar o Fathom-R1-14B
https://nodeshift.com/blog/how-to-install-fathom-r1-14b-the-most-efficient-sota-math-reasoning-llm
Esta seção fornece um guia focado na execução do Fathom-R1-14B usando a biblioteca transformers do Hugging Face dentro de um ambiente Python. Esta abordagem é adequada para usuários com acesso a hardware GPU capaz, seja localmente ou através de provedores de nuvem. Os passos descritos aqui seguem de perto práticas estabelecidas para a implantação de tais modelos.
Configuração do Ambiente
Configurar um ambiente Python adequado é crucial. Os passos a seguir detalham uma configuração comum usando Conda em um sistema baseado em Linux (ou Windows Subsystem for Linux):
Acesse Sua Máquina: Se estiver usando uma instância de GPU remota na nuvem, conecte-se a ela via SSH.Bash
# Example: ssh your_user@your_gpu_instance_ip -p YOUR_PORT -i /path/to/your/ssh_key
Verifique o Reconhecimento da GPU: Certifique-se de que o sistema reconhece a GPU NVIDIA e que os drivers estão corretamente instalados.Bash
nvidia-smi
Crie e Ative um Ambiente Conda: É uma boa prática isolar as dependências do projeto.Bash
conda create -n fathom python=3.11 -y
conda activate fathom
Instale as Bibliotecas Necessárias: Instale PyTorch (compatível com sua versão CUDA), Hugging Face transformers, accelerate (para carregamento e distribuição eficientes do modelo), notebook (para Jupyter) e ipywidgets (para interatividade no notebook).Bash
# Ensure you install a PyTorch version compatible with your GPU's CUDA toolkit
# Example for CUDA 11.8:
# pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
# Or for CUDA 12.1:
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
conda install -c conda-forge --override-channels notebook -y
pip install ipywidgets transformers accelerate
Inferência Baseada em Python em um Jupyter Notebook
Com o ambiente preparado, você pode usar um Jupyter Notebook para carregar e interagir com o Fathom-R1-14B.
Inicie o Servidor Jupyter Notebook: Se estiver em um servidor remoto, inicie o Jupyter Notebook permitindo acesso remoto e especifique uma porta.Bash
jupyter notebook --no-browser --port=8888 --allow-root
Se estiver executando remotamente, você provavelmente precisará configurar o encaminhamento de porta SSH da sua máquina local para acessar a interface do Jupyter:Bash
# Example: ssh -N -L localhost:8889:localhost:8888 your_user@your_gpu_instance_ip
Então, abra http://localhost:8889 (ou sua porta local escolhida) no seu navegador web.
Código Python para Interação com o Modelo: Crie um novo Jupyter Notebook e use o seguinte código Python:Python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
# Define the model ID from Hugging Face
model_id = "FractalAIResearch/Fathom-R1-14B"
print(f"Loading tokenizer for {model_id}...")
tokenizer = AutoTokenizer.from_pretrained(model_id)
print(f"Loading model {model_id} (this may take a while)...")
# Load the model with bfloat16 precision for efficiency and device_map for auto distribution
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16, # Use bfloat16 if your GPU supports it
device_map="auto", # Automatically distributes model layers across available hardware
trust_remote_code=True # Some models may require this
)
print("Model and tokenizer loaded successfully.")
# Define a sample mathematical prompt
prompt = """Question: Natalia sold clips to 48 of her friends in April, and then she sold half as many clips in May. In June, she sold 4 more clips than in May. How many clips did Natalia sell altogether in April, May, and June? Provide a step-by-step solution.
Solution:"""
print(f"\nPrompt:\n{prompt}")
# Tokenize the input prompt
inputs = tokenizer(prompt, return_tensors="pt").to(model.device) # Ensure inputs are on the model's device
print("\nGenerating solution...")
# Generate the output from the model
# Adjust generation parameters as needed for different types of problems
outputs = model.generate(
**inputs,
max_new_tokens=768, # Maximum number of new tokens to generate for the solution
num_return_sequences=1, # Number of independent sequences to generate
temperature=0.1, # Lower temperature for more deterministic, factual outputs
top_p=0.7, # Use nucleus sampling with top_p
do_sample=True # Enable sampling for temperature and top_p to have an effect
)
# Decode the generated tokens into a string
solution_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
print("\nGenerated Solution:\n")
print(solution_text)
Conclusão: O Impacto do Fathom-R1-14B na IA Acessível
O FractalAIResearch/Fathom-R1-14B se destaca como uma demonstração convincente de engenhosidade técnica na arena da IA contemporânea. Seu design específico, apresentando aproximadamente 14,8 bilhões de parâmetros, a arquitetura Qwen2 e uma janela de contexto de 16K tokens, quando combinado com um treinamento inovador e custo-efetivo (cerca de US$ 499 para a versão primária), resultou em um LLM que oferece desempenho de ponta. Isso é evidenciado por seus resultados em benchmarks rigorosos de raciocínio matemático como AIME e HMMT.
O Fathom-R1-14B ilustra de forma convincente que as fronteiras do raciocínio em IA podem ser avançadas por meio de design inteligente e metodologias eficientes, promovendo um futuro onde a IA de alto desempenho seja mais democrática e amplamente benéfica.
Quer uma plataforma integrada, All-in-One, para sua Equipe de Desenvolvimento trabalhar junta com máxima produtividade?
Apidog entrega todas as suas demandas e substitui o Postman por um preço muito mais acessível!