
Desenvolvedores recorrem cada vez mais a plataformas serverless para inferência de IA, e a API Fal.ai se destaca como uma opção robusta para mídia generativa. Esta API permite executar modelos para geração de imagens, vídeo, voz e código sem gerenciar infraestrutura. Você acessa mais de 600 modelos prontos para produção através de uma interface unificada, que escala eficientemente com GPUs sob demanda.
A seguir, exploramos os fundamentos da API Fal.ai e o guiamos através de seu acesso e uso.
O Que é a API Fal.ai?
A API Fal.ai fornece uma plataforma de mídia generativa que impulsiona aplicativos com inferência de IA rápida. Engenheiros a utilizam para integrar modelos de ponta em software, dispensando a necessidade de gerenciamento de servidores. A plataforma oferece desempenho 10x mais rápido em comparação com configurações tradicionais, graças a GPUs serverless otimizadas que escalam para milhares de equivalentes H100.

Em sua essência, a API Fal.ai foca na geração de mídia. Por exemplo, você gera imagens de alta qualidade a partir de prompts de texto usando modelos como o FLUX.1. Além disso, ela suporta animação de vídeo, conversão de fala em texto (speech-to-text) e interações com modelos de linguagem grandes. No entanto, a API enfatiza a prontidão para produção, com recursos como inferência de streaming e suporte a webhooks para tarefas assíncronas.
Além disso, a API Fal.ai opera em um modelo de pagamento por uso, o que mantém os custos previsíveis. Você paga apenas pelo poder de computação que consome, tornando-a adequada tanto para protótipos quanto para aplicações em escala. Passando para os detalhes, vamos examinar como se cadastrar.
Como Faço Para Me Cadastrar na API Fal.ai?
Você começa criando uma conta no site da Fal.ai. Navegue até fal.ai e localize o botão de cadastro no canto superior direito. Forneça seu endereço de e-mail, defina uma senha e verifique sua conta através do e-mail de confirmação. Este processo leva menos de um minuto.
Uma vez registrado, você acessa o painel. Aqui, você gerencia modelos, visualiza estatísticas de uso e gera chaves de API. A Fal.ai não exige cartão de crédito para o cadastro inicial, mas você adiciona detalhes de pagamento posteriormente para recursos pagos. Além disso, a plataforma oferece um nível gratuito com créditos limitados, que permite testar funcionalidades básicas.
Após o cadastro, explore o catálogo de modelos. Você pode selecionar entre categorias como texto para imagem ou texto para vídeo. Este passo o familiariza com os endpoints disponíveis. Agora, com uma conta pronta, você prossegue para obter sua chave de API.
Como Obter Sua Chave de API Fal.ai?
A API Fal.ai depende de chaves de API para autenticação. Você gera uma no painel. Primeiro, faça login e clique na seção "Keys" (Chaves) em seu perfil. Em seguida, selecione "Generate New Key" (Gerar Nova Chave) e nomeie-a para referência, como "Development Key" (Chave de Desenvolvimento).
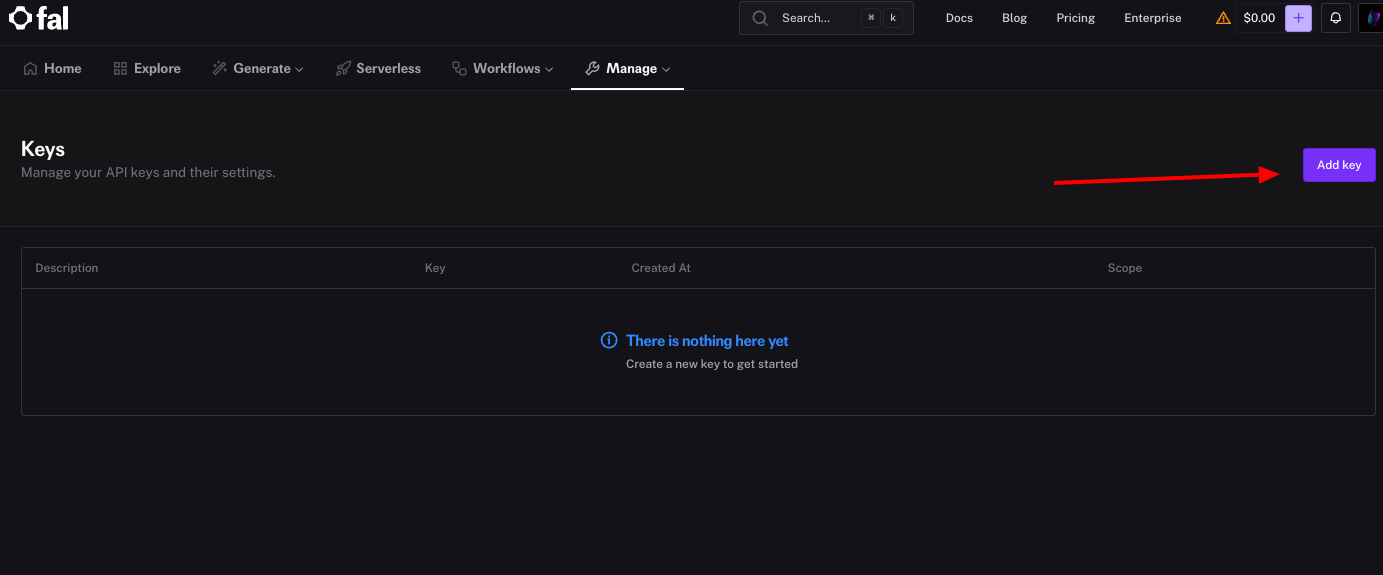
O sistema exibe a chave imediatamente — copie-a e armazene-a com segurança, pois a Fal.ai não a exibirá novamente. Você define esta chave como uma variável de ambiente, como export FAL_KEY="sua_chave_aqui", para evitar codificá-la diretamente em scripts.
Se você trabalha com vários projetos, gere chaves separadas para cada um. Essa prática aumenta a segurança, permitindo a revogação sem afetar outras integrações. Além disso, monitore o uso da chave no painel para detectar anomalias. Com a chave em mãos, você instala a biblioteca cliente a seguir.
Como Instalar o Cliente Fal.ai?
A Fal.ai fornece bibliotecas cliente oficiais para facilitar a integração. Para ambientes JavaScript ou Node.js, você instala o cliente via npm. Execute o comando npm install --save @fal-ai/client no diretório do seu projeto.
Esta biblioteca lida com autenticação, envio de requisições e análise de respostas. Ela substitui o @fal-ai/serverless-client depreciado, então certifique-se de usar a versão mais recente. Para usuários Python, instale fal-client com pip install fal-client.
Uma vez instalada, importe a biblioteca em seu código. Por exemplo, em JavaScript: import { fal } from "@fal-ai/client";. Você a configura com suas credenciais se não estiver usando variáveis de ambiente. Esta configuração simplifica as chamadas aos endpoints da API Fal.ai. A seguir, a autenticação se torna o próximo passo crítico.
Como Autenticar Requisições com a API Fal.ai?
A autenticação protege suas interações com a API Fal.ai. Você usa principalmente a chave de API em cabeçalhos ou variáveis de ambiente. Para requisições HTTP diretas, inclua Authorization: Key sua_chave_fal no cabeçalho.
No entanto, a biblioteca cliente automatiza isso. Configure-a uma vez: fal.config({ credentials: "sua_chave_fal" });. Essa abordagem evita a exposição em código do lado do cliente — sempre use proxies para requisições se estiver construindo aplicativos web.
Atualmente, a API Fal.ai não suporta outros métodos de autenticação como OAuth. Teste a autenticação fazendo uma requisição simples; um erro 401 indica problemas. Além disso, rotacione as chaves periodicamente para as melhores práticas de segurança. Autenticado agora, você explora os modelos disponíveis.
Quais São os Modelos Disponíveis na API Fal.ai?
A API Fal.ai hospeda uma biblioteca de modelos diversificada. As principais categorias incluem texto para imagem, texto para vídeo, fala para texto e modelos de linguagem grandes. Por exemplo, o FLUX.1 [dev] gera imagens a partir de prompts com seu transformador de 12 bilhões de parâmetros.
Outros modelos notáveis: FLUX.1 [schnell] para geração rápida em 1-4 passos, Stable Diffusion 3.5 para imagens ricas em tipografia e Whisper para transcrição de áudio. Você os acessa via IDs únicos como "fal-ai/flux/dev".
Navegue pelo playground de modelos em fal.ai/models para testar interativamente. Cada página de modelo detalha parâmetros, exemplos e preços. Essa variedade permite seleções personalizadas. Por exemplo, escolha Recraft V3 para arte vetorial. Com os modelos identificados, você aprende a gerar imagens.
Como Gerar Imagens Usando a API Fal.ai?
Você gera imagens assinando um endpoint de modelo. Use o cliente para enviar uma requisição POST com parâmetros de entrada. Para o FLUX.1 [dev], o código se parece com isto:
import { fal } from "@fal-ai/client";
const result = await fal.subscribe("fal-ai/flux/dev", {
input: {
prompt: "Uma paisagem urbana futurista ao entardecer, com luzes de neon e carros voadores",
image_size: "landscape_16_9",
num_inference_steps: 28,
guidance_scale: 3.5
}
});
console.log(result.images[0].url);
Esta requisição produz um URL de imagem. A API processa o prompt e retorna metadados como tempos e semente. Além disso, ative as verificações de segurança para filtrar conteúdo NSFW: enable_safety_checker: true.
Teste variações ajustando os prompts. Para geração em lote, defina num_images: 4. As saídas incluem URLs, dimensões e tipos de conteúdo. Este método forma a base para tarefas de mídia. A seguir, personalize com parâmetros avançados.
Uso Avançado: Parâmetros e Customização na API Fal.ai
A API Fal.ai oferece parâmetros extensivos para ajuste fino. Para geração de imagens, o prompt impulsiona o conteúdo, enquanto o guidance_scale controla a aderência — valores mais altos produzem resultados mais rigorosos, tipicamente entre 1.0 e 20.0.
Defina image_size como enums como "square_hd" ou objetos personalizados: { width: 1024, height: 768 }. Os passos de inferência (num_inference_steps) equilibram velocidade e qualidade; 20-50 funciona bem. A semente (seed) garante a reprodutibilidade: forneça um número inteiro para saídas consistentes.
Modos de aceleração ("none", "regular", "high") otimizam o tempo de execução. Para a saída, escolha "jpeg" ou "png" via output_format. Lide com arquivos fazendo upload via fal.storage.upload(file) ou usando URLs/base64.
Personalize ainda mais com webhooks para notificações. Essas opções aumentam o controle. No entanto, monitore os custos, pois mais passos aumentam a cobrança. Transicionando para a eficiência, o tratamento assíncrono segue.
Como Lidar com Requisições Assíncronas e Filas na API Fal.ai?
A API Fal.ai suporta filas para tarefas longas. Envie via fal.queue.submit(model_id, { input: {...} }), recebendo um request_id. Consulte o status: fal.queue.status(model_id, { requestId: "id" }).
Recupere resultados: fal.queue.result(model_id, { requestId: "id" }). Inclua webhookUrl para callbacks. Isso desvincula o envio da espera, ideal para processamento em lote.
O streaming fornece atualizações em tempo real:
const stream = await fal.stream("fal-ai/flux/dev", { input: {...} });
for await (const event of stream) {
console.log(event);
}
const result = await stream.done();
As filas evitam timeouts. Além disso, os logs (logs: true) auxiliam na depuração. Com o assíncrono dominado, integre ferramentas de teste como o Apidog.
Como Integrar a API Fal.ai com o Apidog?
O Apidog aprimora o desenvolvimento da API Fal.ai ao fornecer uma plataforma unificada para testes. Primeiro, crie um projeto no Apidog e importe o esquema OpenAPI de fal.ai/docs (por exemplo, /api/openapi/queue/openapi.json?endpoint_id=fal-ai/flux/dev).
Configure a autenticação: Adicione Authorization: Key sua_chave_fal nos cabeçalhos. Configure requisições para endpoints como POST para "fal-ai/flux/dev", incluindo payloads JSON com prompt e parâmetros.
O Apidog simula respostas, simulando atrasos de GPU e saídas. Faça upload de arquivos para edições de imagem ou teste casos extremos. Execute coleções para cobrir cenários, depurando prompts iterativamente.
Os benefícios incluem iterações mais rápidas (até 40% relatado), economia de custos via mocks e detecção de erros (por exemplo, limites de taxa 429). Recursos de colaboração em equipe garantem consistência. Esta integração otimiza os fluxos de trabalho. A seguir, adote as melhores práticas.
Melhores Práticas para Usar a API Fal.ai
Otimize o desempenho selecionando modelos apropriados — use variantes *schneller* para velocidade. Limite os pontos de dados nas requisições para evitar latência. Além disso, implemente cache para prompts repetidos.
Proteja as chaves com variáveis de ambiente e proxies. Monitore o uso via painel para controlar os custos. Agrupe requisições quando possível, mas respeite os limites de taxa.
Para produção, use clusters dedicados para cargas pesadas. Teste minuciosamente com mocks no Apidog. Além disso, junte-se ao Discord da Fal.ai para insights da comunidade. Essas práticas garantem integrações confiáveis. No entanto, erros ocorrem, então lide com eles adequadamente.
Como Lidar com Erros na API Fal.ai?
A API Fal.ai retorna erros estruturados. Problemas do cliente (por exemplo, validação) resultam em códigos 4xx com detalhes como "Invalid prompt" (Prompt inválido). Erros de servidor são 5xx, frequentemente transitórios — tente novamente com backoff exponencial.
Erros comuns: 401 (falha de autenticação) — verifique a chave; 429 (limite de taxa) — espere e reduza a frequência; 400 (entrada inválida) — valide os parâmetros.
No código, capture exceções:
try {
const result = await fal.subscribe(...);
} catch (error) {
console.error(error.response.data);
}
Logs ajudam a diagnosticar. O Apidog simula erros para testes. O tratamento adequado mantém a robustez. Finalmente, considere os preços.
Qual é o Preço da API Fal.ai?
A API Fal.ai usa precificação por pagamento por uso. Os encargos serverless são por saída, por exemplo, US$ 0,0001 por megapixel para imagens. Modelos de vídeo como o Veo 3 custam US$ 0,20/segundo (áudio desligado).
O nível gratuito oferece créditos iniciais. Atualize para mais via painel. O preço por hora da GPU começa em US$ 1,2 para H100s no modo Compute.
Acompanhe as despesas no painel. Otimize reduzindo os passos ou usando modelos mais rápidos. Este modelo é adequado para cargas de trabalho variáveis. Em resumo, a API Fal.ai impulsiona o desenvolvimento eficiente de IA.
Conclusão
Agora você entende como acessar e usar a API Fal.ai de forma abrangente. Do cadastro e geração de chaves a integrações avançadas com o Apidog, este guia o prepara para aplicações prontas para produção. Experimente modelos, lide com erros diligentemente e monitore os custos. À medida que a IA evolui, a API Fal.ai permanece uma ferramenta versátil. Comece a construir hoje.