
ElevenLabs transforma texto em fala natural e suporta uma ampla gama de vozes, idiomas e estilos. A API facilita a incorporação de voz em aplicativos, a automação de pipelines de narração ou a criação de experiências em tempo real, como agentes de voz. Se você pode enviar uma requisição HTTP, pode gerar áudio em segundos.
O Que É a API da ElevenLabs?
A API da ElevenLabs oferece acesso programático a modelos de IA que geram, transformam e analisam áudio. A plataforma começou como um serviço de texto para fala, mas se expandiu para uma suíte completa de IA de áudio.
Principais recursos:
- Texto para Fala (TTS): Converte texto escrito em áudio falado com controle sobre características de voz, emoção e ritmo
- Fala para Fala (STS): Transforma uma voz em outra, preservando a entonação e o ritmo originais
- Clonagem de Voz: Crie uma réplica digital de qualquer voz a partir de apenas 60 segundos de áudio limpo
- Dublagem por IA: Traduza e duble conteúdo de áudio/vídeo para diferentes idiomas, mantendo as características de voz do locutor
- Efeitos Sonoros: Gere efeitos sonoros a partir de descrições de texto
- Fala para Texto: Transcreva áudio para texto com alta precisão
A API funciona sobre os protocolos padrão HTTP e WebSocket. Você pode chamá-la de qualquer linguagem, mas SDKs oficiais existem para Python e JavaScript/TypeScript com segurança de tipo e suporte a streaming integrados.
Obtendo a Chave da API da ElevenLabs
Antes de fazer qualquer chamada à API, você precisa de uma chave de API. Veja como obter uma:
Passo 1: Crie uma conta gratuita. Mesmo o plano gratuito inclui acesso à API com 10.000 caracteres por mês.
Passo 2: Faça login e navegue até a seção Perfil + Chave de API. Você pode encontrá-la clicando no ícone do seu perfil no canto inferior esquerdo, ou indo diretamente para as configurações do desenvolvedor.
Passo 3: Clique em Criar Chave de API. Copie a chave e armazene-a com segurança — você não poderá ver a chave completa novamente.
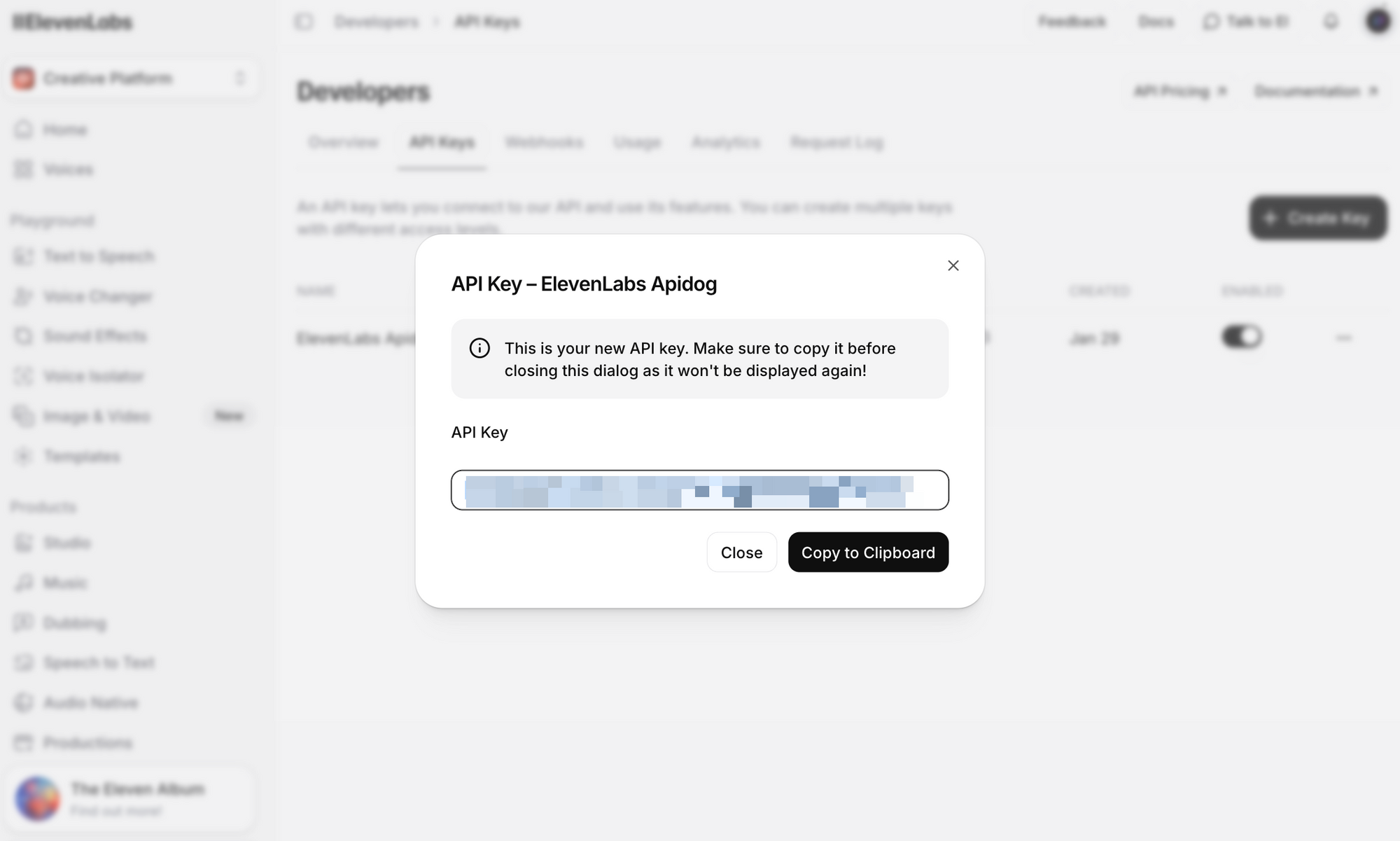
Notas importantes de segurança:
- Nunca envie sua chave de API para controle de versão
- Use variáveis de ambiente ou um gerenciador de segredos em produção
- Chaves de API podem ser delimitadas a workspaces específicos para ambientes de equipe
- Gire as chaves regularmente e revogue as chaves comprometidas imediatamente
Defina-a como uma variável de ambiente para os exemplos neste guia:
# Linux/macOS
export ELEVENLABS_API_KEY="your_api_key_here"
# Windows (PowerShell)
$env:ELEVENLABS_API_KEY="your_api_key_here"
Visão Geral dos Endpoints da API da ElevenLabs
A API é organizada em torno de vários grupos de recursos. Aqui estão os endpoints mais comumente usados:
| Endpoint | Método | Descrição |
|---|---|---|
/v1/text-to-speech/{voice_id} | POST | Converter texto em áudio de fala |
/v1/text-to-speech/{voice_id}/stream | POST | Transmitir áudio à medida que é gerado |
/v1/speech-to-speech/{voice_id} | POST | Converter fala de uma voz para outra |
/v1/voices | GET | Listar todas as vozes disponíveis |
/v1/voices/{voice_id} | GET | Obter detalhes para uma voz específica |
/v1/models | GET | Listar todos os modelos disponíveis |
/v1/user | GET | Obter informações e uso da conta do usuário |
/v1/voice-generation/generate-voice | POST | Gerar uma nova voz aleatória |
URL Base: https://api.elevenlabs.io
Autenticação: Todas as requisições exigem o cabeçalho xi-api-key:
xi-api-key: your_api_key_here
Texto para Fala com cURL
A maneira mais rápida de testar a API é com um comando cURL. Este exemplo usa a voz Rachel (ID: 21m00Tcm4TlvDq8ikWAM), uma das vozes padrão disponíveis em todos os planos:
curl -X POST "https://api.elevenlabs.io/v1/text-to-speech/21m00Tcm4TlvDq8ikWAM" \
-H "xi-api-key: $ELEVENLABS_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"text": "Welcome to our application. This audio was generated using the ElevenLabs API.",
"model_id": "eleven_flash_v2_5",
"voice_settings": {
"stability": 0.5,
"similarity_boost": 0.75,
"style": 0.0,
"use_speaker_boost": true
}
}' \
--output speech.mp3
Se for bem-sucedido, você obterá um arquivo speech.mp3 com o áudio gerado. Reproduza-o com qualquer reprodutor de mídia.
Analisando a requisição:
- voice_id (na URL): O ID da voz a ser usada. Cada voz no ElevenLabs tem um ID exclusivo.
- text: O conteúdo a ser convertido em fala. O modelo Flash v2.5 suporta até 40.000 caracteres por requisição.
- model_id: Qual modelo de IA usar.
eleven_flash_v2_5oferece o melhor equilíbrio entre velocidade e qualidade. - voice_settings: Parâmetros opcionais de ajuste fino (abordados em detalhes abaixo).
A resposta retorna dados de áudio brutos. O formato padrão é MP3, mas você pode solicitar outros formatos adicionando o parâmetro de consulta output_format:
# Obter áudio PCM em vez de MP3
curl -X POST "https://api.elevenlabs.io/v1/text-to-speech/21m00Tcm4TlvDq8ikWAM?output_format=pcm_44100" \
-H "xi-api-key: $ELEVENLABS_API_KEY" \
-H "Content-Type: application/json" \
-d '{"text": "Hello world", "model_id": "eleven_flash_v2_5"}' \
--output speech.pcm
Usando o SDK Python
O SDK oficial Python simplifica a integração com dicas de tipo, reprodução de áudio embutida e suporte a streaming.
Instalação
pip install elevenlabs
Para reproduzir áudio diretamente pelos seus alto-falantes, você também pode precisar de mpv ou ffmpeg:
# macOS
brew install mpv
# Ubuntu/Debian
sudo apt install mpv
Texto para Fala Básico
import os
from elevenlabs.client import ElevenLabs
from elevenlabs import play
client = ElevenLabs(
api_key=os.getenv("ELEVENLABS_API_KEY")
)
audio = client.text_to_speech.convert(
text="The ElevenLabs API makes it easy to add realistic voice output to any application.",
voice_id="JBFqnCBsd6RMkjVDRZzb", # George voice
model_id="eleven_multilingual_v2",
output_format="mp3_44100_128",
)
play(audio)
Salvar Áudio em Arquivo
from elevenlabs.client import ElevenLabs
client = ElevenLabs(api_key="your_api_key")
audio = client.text_to_speech.convert(
text="This audio will be saved to a file.",
voice_id="21m00Tcm4TlvDq8ikWAM",
model_id="eleven_flash_v2_5",
)
with open("output.mp3", "wb") as f:
for chunk in audio:
f.write(chunk)
print("Audio saved to output.mp3")
Listar Vozes Disponíveis
from elevenlabs.client import ElevenLabs
client = ElevenLabs(api_key="your_api_key")
response = client.voices.search()
for voice in response.voices:
print(f"Name: {voice.name}, ID: {voice.voice_id}, Category: {voice.category}")
Isso exibe todas as vozes disponíveis em sua conta, incluindo vozes pré-prontas, vozes clonadas e vozes da comunidade que você adicionou.
Suporte Assíncrono
Para aplicativos que usam asyncio, o SDK oferece AsyncElevenLabs:
import asyncio
from elevenlabs.client import AsyncElevenLabs
client = AsyncElevenLabs(api_key="your_api_key")
async def generate_speech():
audio = await client.text_to_speech.convert(
text="This was generated asynchronously.",
voice_id="21m00Tcm4TlvDq8ikWAM",
model_id="eleven_flash_v2_5",
)
with open("async_output.mp3", "wb") as f:
async for chunk in audio:
f.write(chunk)
print("Async audio saved.")
asyncio.run(generate_speech())
Usando o SDK JavaScript
O SDK oficial Node.js (@elevenlabs/elevenlabs-js) oferece suporte completo a TypeScript e funciona em ambientes Node.js.
Instalação
npm install @elevenlabs/elevenlabs-js
Texto para Fala Básico
import { ElevenLabsClient, play } from "@elevenlabs/elevenlabs-js";
const elevenlabs = new ElevenLabsClient({
apiKey: process.env.ELEVENLABS_API_KEY,
});
const audio = await elevenlabs.textToSpeech.convert(
"21m00Tcm4TlvDq8ikWAM", // Rachel voice ID
{
text: "Hello from the ElevenLabs JavaScript SDK!",
modelId: "eleven_multilingual_v2",
}
);
await play(audio);
Salvar em Arquivo (Node.js)
import { ElevenLabsClient } from "@elevenlabs/elevenlabs-js";
import { createWriteStream } from "fs";
import { Readable } from "stream";
import { pipeline } from "stream/promises";
const elevenlabs = new ElevenLabsClient({
apiKey: process.env.ELEVENLABS_API_KEY,
});
const audio = await elevenlabs.textToSpeech.convert(
"21m00Tcm4TlvDq8ikWAM",
{
text: "This audio will be written to a file using Node.js streams.",
modelId: "eleven_flash_v2_5",
}
);
const readable = Readable.from(audio);
const writeStream = createWriteStream("output.mp3");
await pipeline(readable, writeStream);
console.log("Audio saved to output.mp3");
Tratamento de Erros
import { ElevenLabsClient, ElevenLabsError } from "@elevenlabs/elevenlabs-js";
const elevenlabs = new ElevenLabsClient({
apiKey: process.env.ELEVENLABS_API_KEY,
});
try {
const audio = await elevenlabs.textToSpeech.convert(
"21m00Tcm4TlvDq8ikWAM",
{
text: "Testing error handling.",
modelId: "eleven_flash_v2_5",
}
);
await play(audio);
} catch (error) {
if (error instanceof ElevenLabsError) {
console.error(`Erro da API: ${error.message}, Status: ${error.statusCode}`);
} else {
console.error("Erro inesperado:", error);
}
}
O SDK tenta novamente as requisições falhas até 2 vezes por padrão, com um timeout de 60 segundos. Ambos os valores são configuráveis.
Streaming de Áudio em Tempo Real
Para chatbots, assistentes de voz ou qualquer aplicativo onde a latência importa, o streaming permite que você comece a reproduzir o áudio antes que a resposta completa seja gerada. Isso é fundamental para a IA conversacional, onde os usuários esperam respostas quase instantâneas.
Streaming Python
from elevenlabs import stream
from elevenlabs.client import ElevenLabs
client = ElevenLabs(api_key="your_api_key")
audio_stream = client.text_to_speech.stream(
text="Streaming allows you to start hearing audio almost instantly, without waiting for the entire generation to complete.",
voice_id="JBFqnCBsd6RMkjVDRZzb",
model_id="eleven_flash_v2_5",
)
# Reproduzir áudio em stream através dos alto-falantes em tempo real
stream(audio_stream)
Streaming JavaScript
import { ElevenLabsClient, stream } from "@elevenlabs/elevenlabs-js";
const elevenlabs = new ElevenLabsClient();
const audioStream = await elevenlabs.textToSpeech.stream(
"JBFqnCBsd6RMkjVDRZzb",
{
text: "This audio streams in real time with minimal latency.",
modelId: "eleven_flash_v2_5",
}
);
stream(audioStream);
Streaming WebSocket
Para a menor latência, use conexões WebSocket. Isso é ideal para agentes de voz em tempo real, onde o texto chega em blocos (por exemplo, de um LLM):
import asyncio
import websockets
import json
import base64
async def stream_tts_websocket():
voice_id = "21m00Tcm4TlvDq8ikWAM"
model_id = "eleven_flash_v2_5"
uri = f"wss://api.elevenlabs.io/v1/text-to-speech/{voice_id}/stream-input?model_id={model_id}"
async with websockets.connect(uri) as ws:
# Send initial config
await ws.send(json.dumps({
"text": " ",
"voice_settings": {"stability": 0.5, "similarity_boost": 0.75},
"xi_api_key": "your_api_key",
}))
# Send text chunks as they arrive (e.g., from an LLM)
text_chunks = [
"Hello! ",
"This is streaming ",
"via WebSockets. ",
"Each chunk is sent separately."
]
for chunk in text_chunks:
await ws.send(json.dumps({"text": chunk}))
# Signal end of input
await ws.send(json.dumps({"text": ""}))
# Receive audio chunks
audio_data = b""
async for message in ws:
data = json.loads(message)
if data.get("audio"):
audio_data += base64.b64decode(data["audio"])
if data.get("isFinal"):
break
with open("websocket_output.mp3", "wb") as f:
f.write(audio_data)
print("Áudio WebSocket salvo.")
asyncio.run(stream_tts_websocket())
Seleção e Gerenciamento de Voz
ElevenLabs oferece centenas de vozes. Escolher a voz certa é importante para a experiência do usuário do seu aplicativo.
Vozes Padrão
Estas vozes estão disponíveis em todos os planos, incluindo o nível gratuito:
| Nome da Voz | ID da Voz | Descrição |
|---|---|---|
| Rachel | 21m00Tcm4TlvDq8ikWAM | Feminino, calma, jovem |
| Drew | 29vD33N1CtxCmqQRPOHJ | Masculino, completo |
| Clyde | 2EiwWnXFnvU5JabPnv8n | Personagem de veterano de guerra |
| Paul | 5Q0t7uMcjvnagumLfvZi | Repórter de campo |
| Domi | AZnzlk1XvdvUeBnXmlld | Feminino, forte, assertiva |
| Dave | CYw3kZ02Hs0563khs1Fj | Masculino britânico, conversacional |
| Fin | D38z5RcWu1voky8WS1ja | Masculino irlandês |
| Sarah | EXAVITQu4vr4xnSDxMaL | Feminino, suave, jovem |
Encontrando IDs de Voz
Use a API para pesquisar todas as vozes disponíveis:
curl -X GET "https://api.elevenlabs.io/v1/voices" \
-H "xi-api-key: $ELEVENLABS_API_KEY" | python3 -m json.tool
Ou filtre por categoria (pré-prontas, clonadas, geradas):
from elevenlabs.client import ElevenLabs
client = ElevenLabs(api_key="your_api_key")
# Listar apenas vozes pré-prontas
response = client.voices.search(category="premade")
for voice in response.voices:
print(f"{voice.name}: {voice.voice_id}")
Você também pode copiar um ID de voz diretamente do site da ElevenLabs: selecione uma voz, clique no menu de três pontos e escolha Copiar ID de Voz.
Escolhendo o Modelo Certo
ElevenLabs oferece vários modelos, cada um otimizado para diferentes casos de uso:

# Listar todos os modelos disponíveis com detalhes
from elevenlabs.client import ElevenLabs
client = ElevenLabs(api_key="your_api_key")
models = client.models.list()
for model in models:
print(f"Model: {model.name}")
print(f" ID: {model.model_id}")
print(f" Languages: {len(model.languages)}")
print(f" Max chars: {model.max_characters_request_free_user}")
print()
Testando a API da ElevenLabs com Apidog
Antes de escrever o código de integração, é útil testar os endpoints da API interativamente. O Apidog torna isso simples — você pode configurar requisições visualmente, inspecionar respostas (incluindo áudio) e gerar código cliente assim que estiver satisfeito.
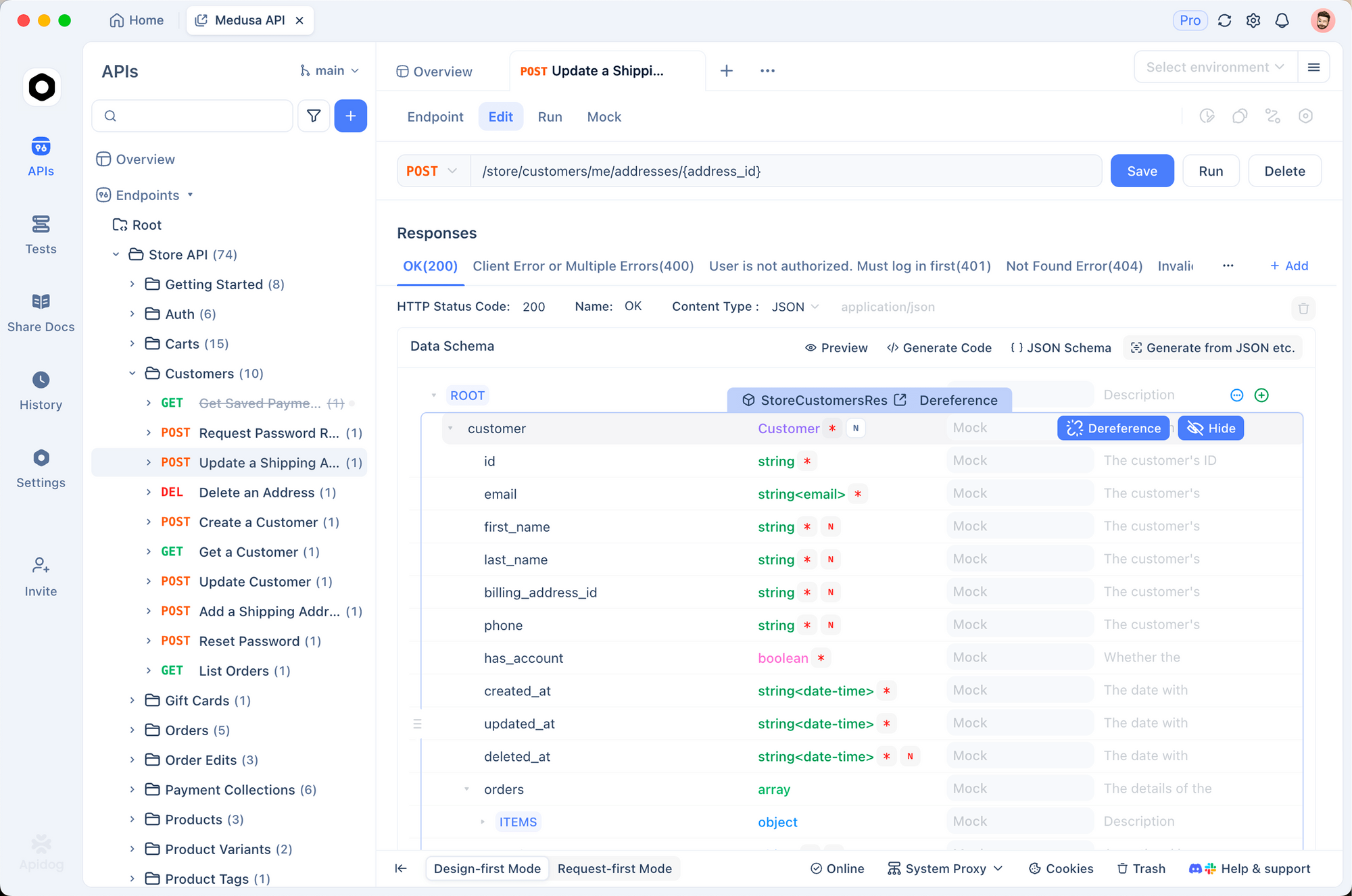
Passo 1: Configure um Novo Projeto
Abra o Apidog e crie um novo projeto. Nomeie-o "API da ElevenLabs" ou adicione os endpoints a um projeto existente.
Passo 2: Configure a Autenticação
Vá para Configurações do Projeto > Autenticação e configure um cabeçalho global:
- Nome do cabeçalho:
xi-api-key - Valor do cabeçalho: sua chave de API da ElevenLabs
Isso anexa automaticamente a autenticação a cada requisição no projeto.
Passo 3: Crie uma Requisição de Texto para Fala
Crie uma nova requisição POST:
- URL:
https://api.elevenlabs.io/v1/text-to-speech/21m00Tcm4TlvDq8ikWAM - Corpo (JSON):
{
"text": "Testing the ElevenLabs API through Apidog. This makes it easy to experiment with different voices and settings.",
"model_id": "eleven_flash_v2_5",
"voice_settings": {
"stability": 0.5,
"similarity_boost": 0.75
}
}
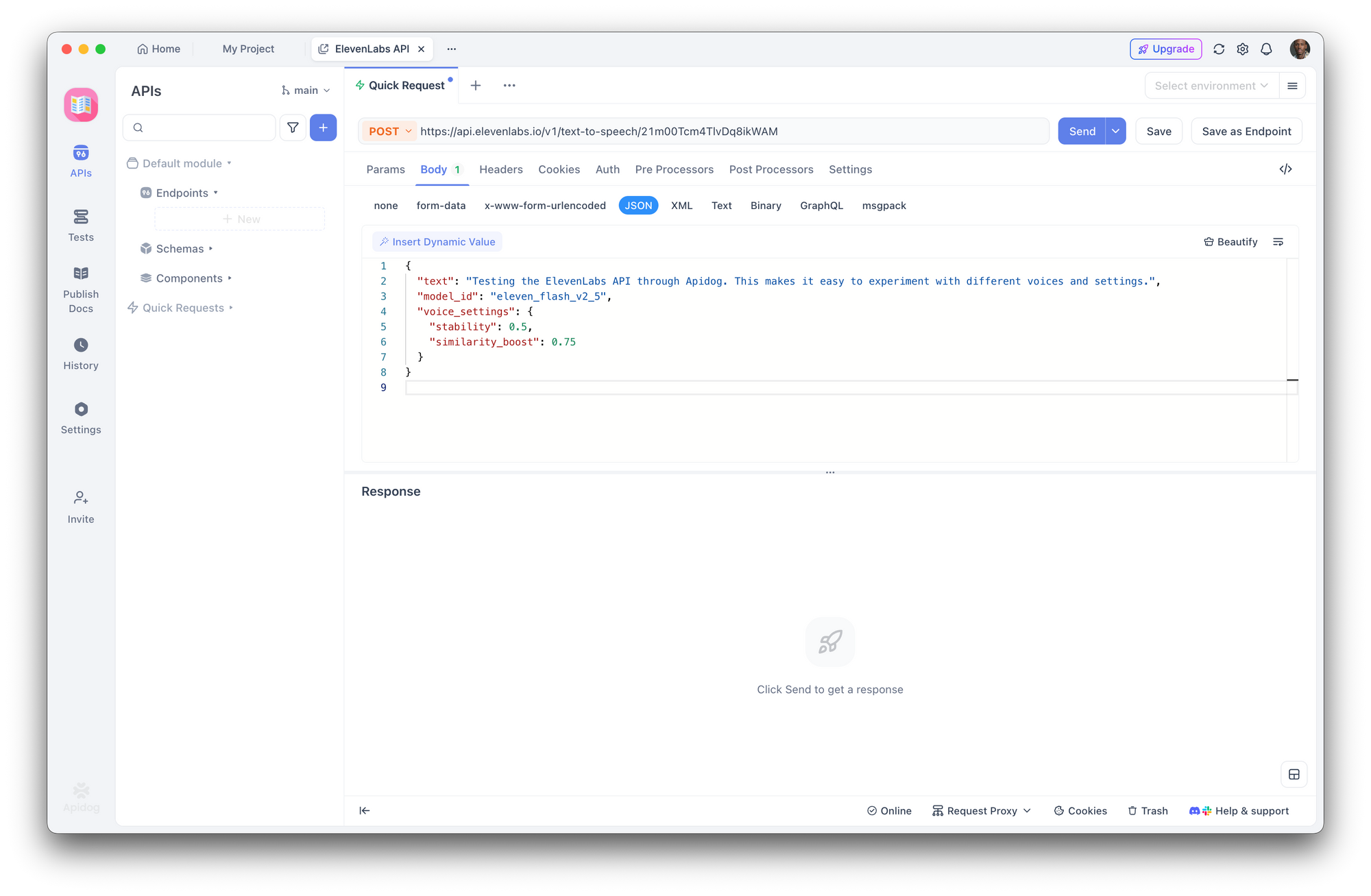
Clique em Enviar. O Apidog exibe os cabeçalhos de resposta e permite que você baixe ou reproduza o áudio diretamente.
Passo 4: Experimente com Parâmetros
Use a interface do Apidog para trocar rapidamente IDs de voz, alterar modelos ou ajustar configurações de voz sem editar JSON bruto. Salve diferentes configurações como endpoints separados em sua coleção para facilitar a comparação.
Passo 5: Gere Código Cliente
Depois de confirmar que a requisição funciona, clique em Gerar Código no Apidog para obter código cliente pronto para uso em Python, JavaScript, cURL, Go, Java e muito mais. Isso elimina a tradução manual da documentação da API para o código funcional.
Experimente agora:Baixe o Apidog gratuitamente
Configurações de Voz e Ajuste Fino
As configurações de voz permitem ajustar como uma voz soa. Esses parâmetros são enviados no objeto voice_settings:
| Parâmetro | Intervalo | Padrão | Efeito |
|---|---|---|---|
stability | 0.0 - 1.0 | 0.5 | Maior = mais consistente, menos expressivo. Menor = mais variável, mais emocional. |
similarity_boost | 0.0 - 1.0 | 0.75 | Maior = mais próximo da voz original. Menor = mais variação. |
style | 0.0 - 1.0 | 0.0 | Maior = estilo mais exagerado. Aumenta a latência. Apenas para Multilingual v2. |
use_speaker_boost | booleano | true | Aumenta a semelhança com o locutor original. Pequeno aumento de latência. |
Exemplos práticos:
from elevenlabs.client import ElevenLabs
client = ElevenLabs(api_key="your_api_key")
# Voz de narração: consistente, estável
narration = client.text_to_speech.convert(
text="Chapter One. It was a bright cold day in April.",
voice_id="21m00Tcm4TlvDq8ikWAM",
model_id="eleven_multilingual_v2",
voice_settings={
"stability": 0.8,
"similarity_boost": 0.8,
"style": 0.2,
"use_speaker_boost": True,
},
)
# Voz conversacional: expressiva, natural
conversational = client.text_to_speech.convert(
text="Oh wow, that's actually a great idea! Let me think about how we could make it work.",
voice_id="JBFqnCBsd6RMkjVDRZzb",
model_id="eleven_multilingual_v2",
voice_settings={
"stability": 0.3,
"similarity_boost": 0.6,
"style": 0.5,
"use_speaker_boost": True,
},
)
Orientações:
- Para audiolivros e narrações, use estabilidade mais alta (0.7-0.9) para uma entrega consistente
- Para chatbots e IA conversacional, use estabilidade mais baixa (0.3-0.5) para variação natural
- Para vozes de personagem, experimente com
similarity_boostmais baixo (0.4-0.6) para criar personalidades distintas - O parâmetro
stylefunciona apenas com Multilingual v2 e adiciona latência — ignore-o para aplicações em tempo real
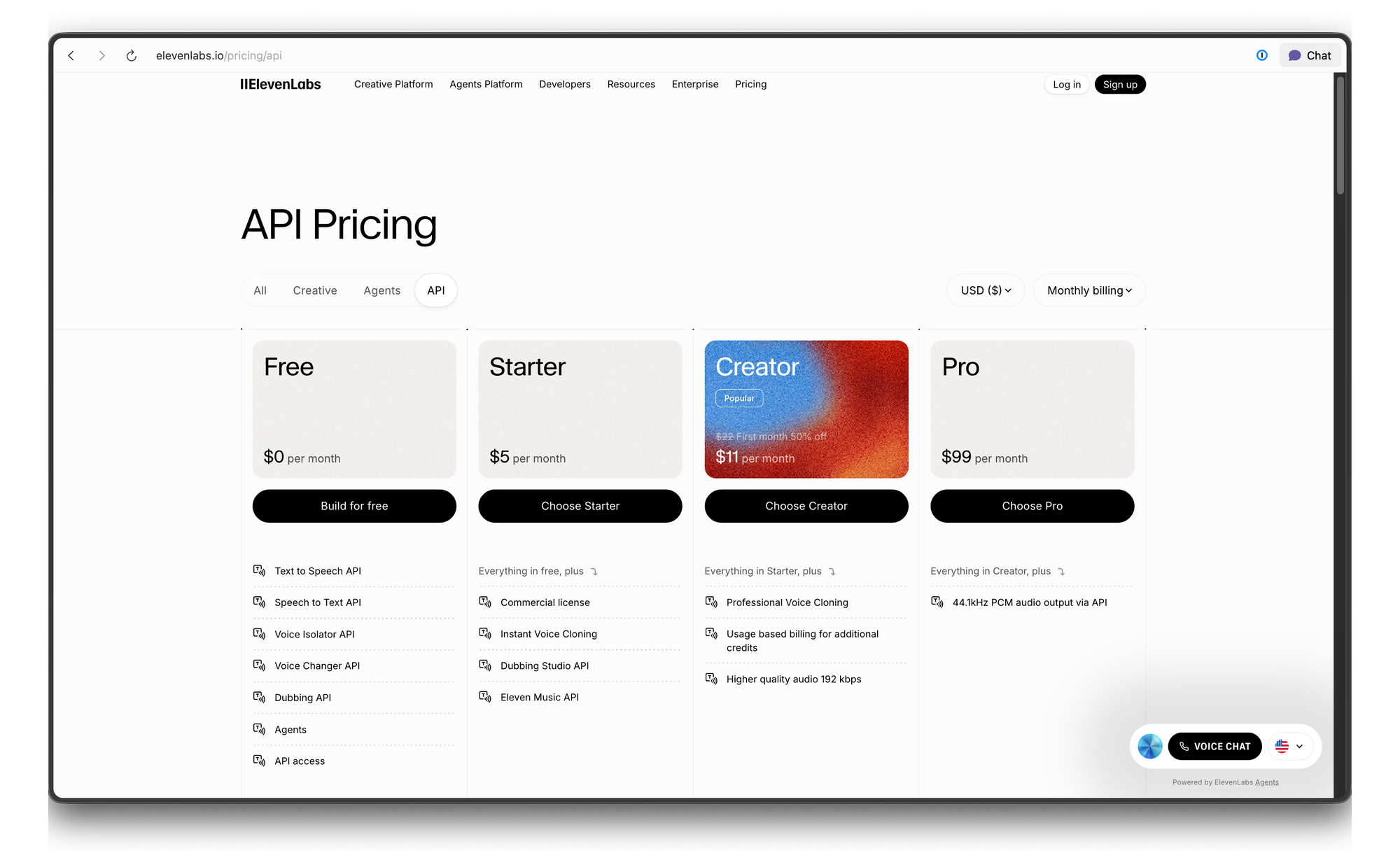
Preços e Limites de Taxa da API da ElevenLabs
ElevenLabs usa um sistema de preços baseado em créditos. Veja o detalhamento:
Solução de Problemas
| Erro | Causa | Solução |
|---|---|---|
| 401 Não Autorizado | Chave de API inválida ou ausente | Verifique o valor do seu cabeçalho xi-api-key |
| 422 Entidade Não Processável | Corpo da requisição inválido | Verifique se o voice_id existe e o texto não está vazio |
| 429 Muitas Requisições | Limite de taxa excedido | Adicione backoff exponencial ou atualize seu plano |
| Áudio soa robótico | Modelo ou configurações erradas | Experimente Multilingual v2 com estabilidade em 0.5 |
| Erros de pronúncia | Problema de normalização de texto | Escreva números/abreviações por extenso, ou use formatação semelhante ao SSML |
Conclusão
A API da ElevenLabs oferece aos desenvolvedores acesso a algumas das sínteses de fala mais realistas disponíveis atualmente. Seja para algumas linhas de narração ou para um pipeline completo de voz em tempo real, a API escala desde chamadas cURL simples até streams WebSocket de produção.
Pronto para adicionar voz realista ao seu aplicativo? Baixe o Apidog para testar os endpoints da API da ElevenLabs, experimentar configurações de voz e gerar código cliente — tudo gratuito, sem necessidade de cartão de crédito.