
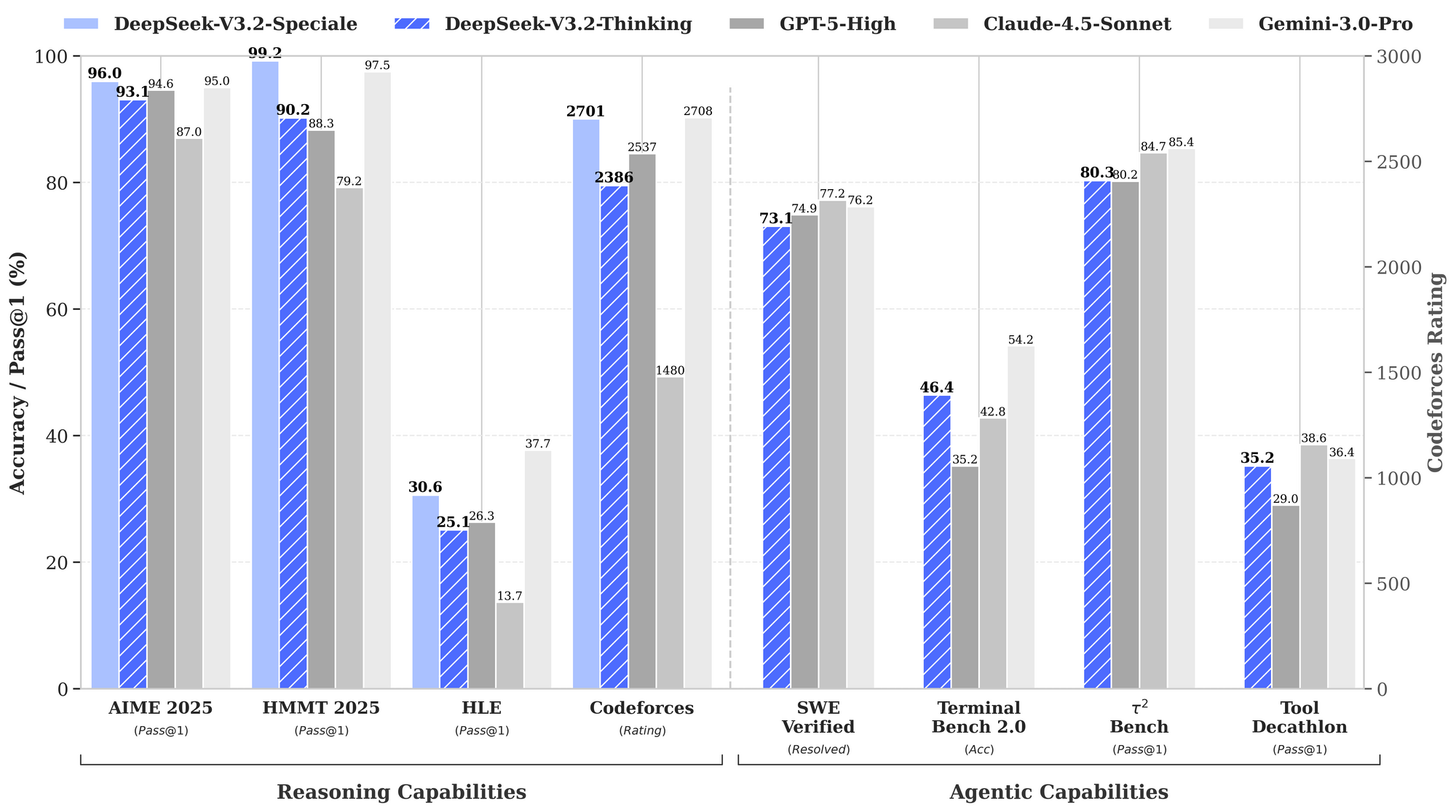
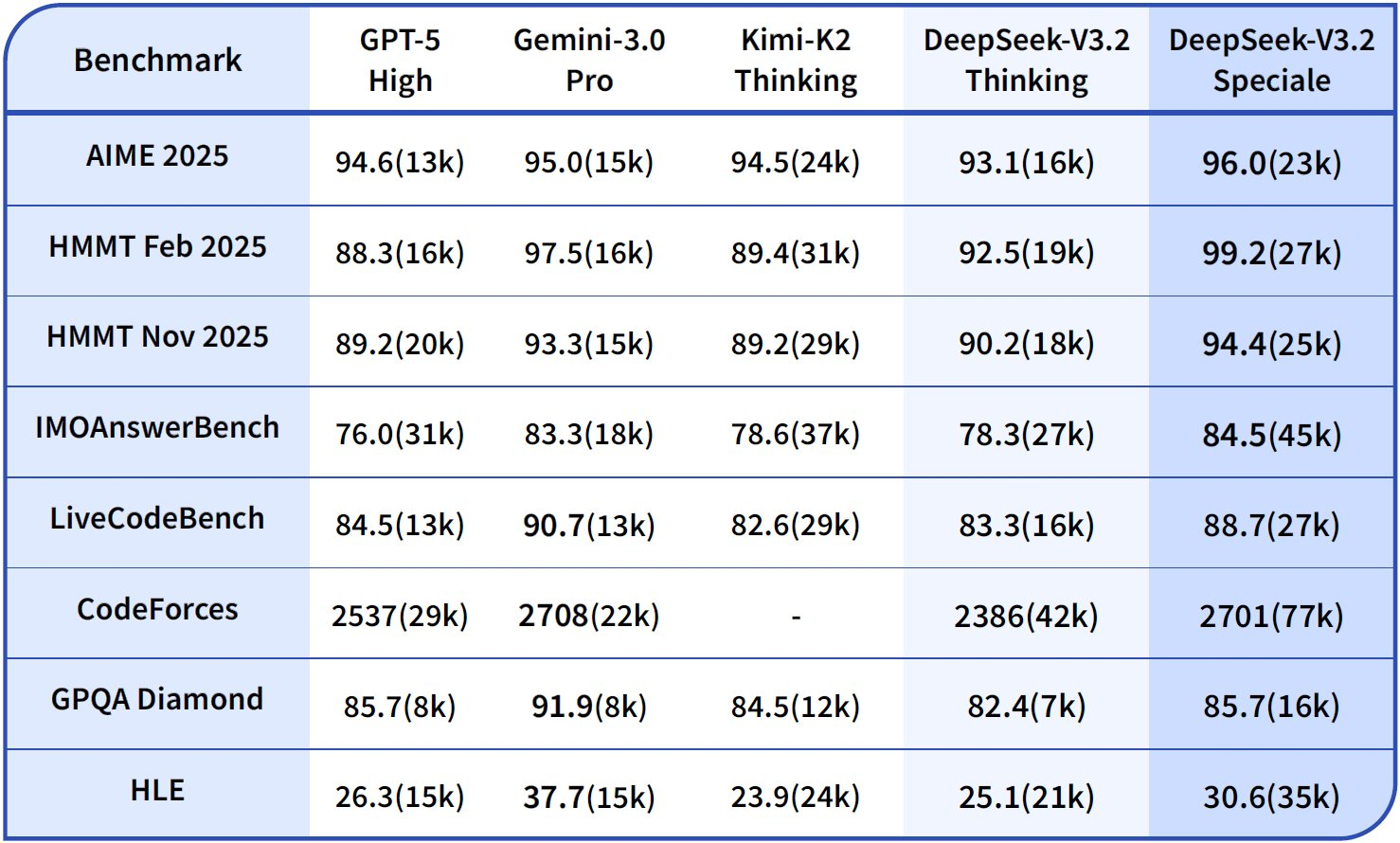
Desenvolvedores procuram ferramentas que aumentem a produtividade sem introduzir complexidade desnecessária. DeepSeek-V3.2 e DeepSeek-V3.2-Speciale surgem como poderosos modelos de código aberto otimizados para raciocínio e tarefas agênticas, oferecendo uma alternativa atraente a sistemas proprietários. Esses modelos se destacam na geração de código, resolução de problemas e processamento de contexto longo, tornando-os ideais para integração em ambientes de codificação baseados em terminal, como o Claude Code.
Entendendo o DeepSeek-V3.2: Uma Potência de Código Aberto para Tarefas de Raciocínio
Desenvolvedores valorizam modelos de código aberto por sua transparência e flexibilidade. O DeepSeek-V3.2 se destaca como um modelo de linguagem grande (LLM) focado em raciocínio, que prioriza inferência lógica, síntese de código e capacidades agênticas. Lançado sob uma licença MIT, este modelo baseia-se em iterações anteriores, como o DeepSeek-V3.1, incorporando avanços em mecanismos de atenção esparsa para lidar com contextos estendidos de até 128.000 tokens.
Você acessa o DeepSeek-V3.2 principalmente através do Hugging Face, onde o repositório em deepseek-ai/DeepSeek-V3.2 hospeda os pesos do modelo, arquivos de configuração e detalhes do tokenizador. Para carregar o modelo localmente, instale a biblioteca Transformers via pip e execute um script simples:
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
model_name = "deepseek-ai/DeepSeek-V3.2"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype=torch.float16, device_map="auto")
# Example inference
inputs = tokenizer("Write a Python function to compute Fibonacci sequence:", return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_new_tokens=100)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
Esta configuração requer uma GPU com pelo menos 16GB de VRAM para inferência eficiente, embora técnicas de quantização via bibliotecas como bitsandbytes reduzam a pegada de memória. A arquitetura do DeepSeek-V3.2 emprega um design de mistura de especialistas (MoE) com 236 bilhões de parâmetros, ativando apenas um subconjunto por token para otimizar o processamento. Consequentemente, ele atinge alta taxa de transferência em hardware de consumidor, mantendo um desempenho competitivo.
A transição da experimentação local para o uso em escala de produção frequentemente requer acesso à API. Essa mudança proporciona escalabilidade sem gerenciamento de hardware, abrindo caminho para integrações como o Claude Code.
DeepSeek-V3.2-Speciale: Capacidades Aprimoradas para Fluxos de Trabalho Agênticos Avançados
Enquanto o DeepSeek-V3.2 oferece ampla utilidade, o DeepSeek-V3.2-Speciale aprimora essas bases para demandas especializadas. Esta variante, ajustada para raciocínio de nível de competição e simulações de alto risco, expande os limites em matemática, competições de codificação e tarefas de agente de várias etapas. Disponível através do repositório Hugging Face em deepseek-ai/DeepSeek-V3.2-Speciale, ele compartilha a arquitetura MoE central, mas incorpora alinhamentos adicionais pós-treinamento para precisão.
Carregue o DeepSeek-V3.2-Speciale de forma similar:
model_name = "deepseek-ai/DeepSeek-V3.2-Speciale"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype=torch.bfloat16, device_map="auto")
Sua contagem de parâmetros espelha a do modelo base, mas as otimizações na atenção esparsa — DeepSeek Sparse Attention (DSA) — proporcionam uma inferência até 50% mais rápida em sequências longas. O DSA emprega esparsidade fina, preservando a qualidade enquanto reduz a complexidade quadrática nas camadas de atenção.
Na prática, o DeepSeek-V3.2-Speciale se destaca em cenários que exigem raciocínio encadeado, como a otimização de algoritmos para programação competitiva. Por exemplo, solicite-lhe: "Resolva este problema difícil do LeetCode: [descrição]. Explique sua abordagem passo a passo." O modelo gera soluções estruturadas com análise de complexidade de tempo, frequentemente superando modelos generalistas em 15-20% em casos extremos.
No entanto, execuções locais exigem mais recursos — recomenda-se 24GB+ de VRAM para precisão total. Para configurações mais leves, aplique quantização de 4 bits:
from transformers import BitsAndBytesConfig
quant_config = BitsAndBytesConfig(load_in_4bit=True)
model = AutoModelForCausalLM.from_pretrained(model_name, quantization_config=quant_config)
Esta configuração mantém 90% da fidelidade original, enquanto reduz pela metade o uso de memória. Assim como no modelo base, habilite os modos de 'pensamento' para aproveitar seus traços metacognitivos, onde ele se autocorrige durante o raciocínio.
O acesso de código aberto permite a personalização, mas para ambientes colaborativos ou em escala, os endpoints de API fornecem confiabilidade. Em seguida, examinaremos como conectar esses modelos a interações baseadas em nuvem.
Acessando a API DeepSeek: Integração Contínua para Desenvolvimento Escalável
Modelos de código aberto como DeepSeek-V3.2 e DeepSeek-V3.2-Speciale prosperam em configurações locais, mas o acesso à API libera aplicações mais amplas. A plataforma da DeepSeek oferece uma interface compatível, suportando SDKs OpenAI e Anthropic para uma migração sem esforço.
Cadastre-se em platform.deepseek.com para obter uma chave de API.
O painel fornece análises de uso e controles de faturamento. Invoque modelos através de endpoints padrão; para DeepSeek-V3.2, use o alias deepseek-chat. O DeepSeek-V3.2-Speciale requer uma URL base específica: https://api.deepseek.com/v3.2_speciale_expires_on_20251215 — observe que este roteamento temporário expira em 15 de dezembro de 2025.
Uma requisição curl básica demonstra o acesso:
curl https://api.deepseek.com/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $DEEPSEEK_API_KEY" \
-d '{
"model": "deepseek-chat",
"messages": [{"role": "user", "content": "Generate a REST API endpoint in Node.js for user authentication."}],
"max_tokens": 500,
"temperature": 0.7
}'
Isso retorna JSON com código gerado, incluindo tratamento de erros e integração JWT. Para compatibilidade com Anthropic — fundamental para o Claude Code — defina a URL base para https://api.deepseek.com/anthropic e use o SDK Python do Anthropic:
import anthropic
client = anthropic.Anthropic(base_url="https://api.deepseek.com/anthropic", api_key="your_deepseek_key")
message = client.messages.create(
model="deepseek-chat",
max_tokens=1000,
messages=[{"role": "user", "content": "Explain quantum entanglement in code terms."}]
)
print(message.content[0].text)
Tal compatibilidade garante substituições diretas. Os limites de taxa são de 10.000 tokens por minuto para os níveis padrão, escaláveis através de planos empresariais.
Use o Apidog para prototipar essas chamadas. Importe a especificação OpenAPI da documentação DeepSeek para o Apidog, então simule requisições com payloads variáveis. Esta ferramenta gera automaticamente conjuntos de testes, validando respostas contra esquemas — essencial para garantir que as saídas do modelo se alinhem aos padrões do seu código.
Com o acesso à API assegurado, integre esses endpoints em ferramentas de desenvolvimento. O Claude Code, em particular, se beneficia desta configuração, como explorado abaixo.
Detalhes de Preços: Estratégias Custo-Efetivas para o Uso da API DeepSeek
Desenvolvedores conscientes do orçamento apreciam custos previsíveis. O modelo de precificação da DeepSeek recompensa o prompting eficiente e o caching, impactando diretamente as sessões do Claude Code.
Detalhando a estrutura: Acertos de cache se aplicam a prefixos repetidos, ideal para codificação iterativa onde você refina prompts entre sessões. Erros (cache misses) cobram taxas de entrada completas, então estruture as conversas para maximizar a reutilização. As saídas escalam linearmente com o comprimento da geração — limite max_tokens para controlar as despesas.
| Variante do Modelo | Cache Hit de Entrada ($/1M Tokens) | Cache Miss de Entrada ($/1M Tokens) | Saída ($/1M Tokens) | Comprimento do Contexto |
|---|---|---|---|---|
| DeepSeek-V3.2 | 0.028 | 0.28 | 0.42 | 128K |
| DeepSeek-V3.2-Speciale | 0.028 | 0.28 | 0.42 | 128K |
Usuários empresariais negociam descontos por volume, mas os níveis gratuitos oferecem 1M de tokens mensais para testes. Monitore via painel; integre o log no Claude Code para rastrear o uso de tokens:
export ANTHROPIC_BASE_URL=https://api.deepseek.com/anthropic
export ANTHROPIC_API_KEY=$DEEPSEEK_API_KEY
claude --log-tokens
Este comando exibe métricas pós-sessão, ajudando a otimizar os prompts. Para codificação de contexto longo, o DSA nas variantes V3.2 mantém os custos estáveis mesmo com mais de 100K tokens, ao contrário de modelos densos que escalam quadraticamente.
Integrando DeepSeek-V3.2 e V3.2-Speciale ao Claude Code: Configuração Passo a Passo
O Claude Code revoluciona o desenvolvimento baseado em terminal como uma ferramenta agêntica da Anthropic. Ele interpreta comandos em linguagem natural, executa operações git, explica bases de código e automatiza rotinas — tudo dentro do seu shell. Ao rotear requisições para modelos DeepSeek, você aproveita um raciocínio custo-efetivo sem sacrificar a interface intuitiva do Claude Code.

Comece com os pré-requisitos: Instale o Claude Code via pip (pip install claude-code) ou do GitHub anthropics/claude-code. Certifique-se de que Node.js e git estejam em seu PATH.
Configure as variáveis de ambiente para compatibilidade com DeepSeek:
export ANTHROPIC_BASE_URL="https://api.deepseek.com/anthropic"
export ANTHROPIC_API_KEY="sk-your_deepseek_key_here"
export ANTHROPIC_MODEL="deepseek-chat" # Para V3.2
export ANTHROPIC_SMALL_FAST_MODEL="deepseek-chat"
export API_TIMEOUT_MS=600000 # 10 minutos para raciocínio longo
export CLAUDE_CODE_DISABLE_NONESSENTIAL_TRAFFIC=1 # Otimizar para API
Para o DeepSeek-V3.2-Speciale, anexe a base personalizada: export ANTHROPIC_BASE_URL="https://api.deepseek.com/v3.2_speciale_expires_on_20251215/anthropic". Verifique a configuração executando claude --version; ele detecta o endpoint automaticamente.
Inicie o Claude Code no diretório do seu projeto:
cd /path/to/your/repo
claude
Interaja via comandos. Para geração de código: "/generate Implemente uma árvore de busca binária em C++ com balanceamento AVL." O DeepSeek-V3.2 processa isso, gerando arquivos com explicações. Seu modo de 'pensamento' é ativado implicitamente para tarefas complexas, rastreando a lógica antes do código.
Gerencie fluxos de trabalho agênticos: "/agent Depure esta suíte de testes com falha e sugira correções." O modelo analisa rastreamentos de pilha, propõe patches e faz commits via git — tudo alimentado pela pontuação de 84.8% do DeepSeek no SWE-Bench. O uso paralelo de ferramentas se destaca aqui; especifique "/use-tool pytest" para executar testes em linha.
Personalize com plugins. Estenda a configuração YAML do Claude Code (~/.claude-code/config.yaml) para priorizar o DeepSeek em prompts que exigem muito raciocínio:
models:
default: deepseek-chat
fallback: deepseek-chat # Para V3.2-Speciale, substitua por sessão
reasoning_enabled: true
max_context: 100000 # Aproveite a janela de 128K
Teste as integrações usando o Apidog. Exporte as sessões do Claude Code como arquivos HAR, importe para o Apidog e reproduza contra os endpoints DeepSeek. Isso valida a latência (geralmente <2s para 1K tokens) e as taxas de erro, refinando os prompts para produção.
Solucione problemas comuns: Se a autenticação falhar, regenere sua chave de API. Para limites de tokens, fragmente grandes bases de código com "/summarize repo structure first." Esses ajustes garantem uma operação tranquila.
Técnicas Avançadas: Aproveitando o DeepSeek no Claude Code para Desempenho Ótimo
Além do básico, usuários avançados exploram os pontos fortes do DeepSeek. Habilite explicitamente o encadeamento de pensamentos (CoT): "/think Resolva este problema de programação dinâmica: [detalhes]." O V3.2-Speciale gera traços metacognitivos, autocorrige-se via simulações quase-Monte Carlo em texto — aumentando a precisão para 94.6% no HMMT.
Para edições de vários arquivos, use "/edit --files main.py utils.py Adicione decoradores de logging." O agente navega pelas dependências, aplicando mudanças atomicamente. Benchmarks mostram 80.3% de sucesso no Terminal-Bench 2.0, superando o Gemini-3.0-Pro.
Integre ferramentas externas: Configure "/tool npm run build" para validação pós-geração. O benchmark de uso de ferramentas do DeepSeek (84.7%) garante uma orquestração confiável.
Monitore a ética: O DeepSeek se alinha à segurança via RLHF, mas audite as saídas em busca de vieses nas suposições do código. Use a validação de esquema do Apidog para impor padrões seguros, como a sanitização de entrada.
Escale para equipes: Compartilhe configurações via repositórios de dotfiles. Em CI/CD, incorpore scripts do Claude Code com DeepSeek para revisões de PR automatizadas — reduzindo o tempo de revisão em 40%.
Aplicações no Mundo Real: Claude Code Potencializado por DeepSeek em Ação
Considere um projeto de fintech: "/generate API segura para processamento de transações usando GraphQL." O DeepSeek-V3.2 gera esquema, resolvers e middleware de limitação de taxa, validados contra os padrões OWASP.
Em pipelines de ML: "/agent Otimize este modelo PyTorch para implantação em edge." Ele refatora para quantização, testa em hardware simulado e documenta as compensações.
Esses casos demonstram ganhos de produtividade de 2-3x, corroborados por relatos de usuários em issues do GitHub.
Conclusão
DeepSeek-V3.2 e DeepSeek-V3.2-Speciale transformam o Claude Code em uma potência centrada no raciocínio. Desde o carregamento de código aberto até a escalabilidade impulsionada por API, esses modelos oferecem desempenho líder de benchmark a um preço fracionado. Implemente os passos descritos — começando com o Apidog para prototipagem de API — e testemunhe fluxos de trabalho otimizados.
Experimente hoje: Configure seu ambiente, execute um comando de exemplo e itere. A integração não só acelera o desenvolvimento, mas também promove uma compreensão mais profunda do código através de um raciocínio transparente. À medida que a IA evolui, ferramentas como estas garantem que os desenvolvedores permaneçam na vanguarda.