
Você está procurando implementar o Deepseek R1 — um dos modelos de linguagem grandes mais poderosos — em uma plataforma de nuvem? Seja trabalhando com AWS, Azure ou Digital Ocean, este guia tem tudo o que você precisa. Ao final deste post, você terá um roteiro claro para colocar seu modelo Deepseek R1 em funcionamento com facilidade. Além disso, mostraremos como ferramentas como Apidog podem ajudar a otimizar os testes de API durante a implementação.
Por que implementar o Deepseek R1 na nuvem?
Implementar o Deepseek R1 na nuvem não é apenas sobre escalabilidade; é sobre aproveitar o poder das GPUs e a infraestrutura sem servidor para lidar com cargas de trabalho massivas de forma eficiente. Com seus 671 bilhões de parâmetros, Deepseek R1 exige hardware robusto e configurações otimizadas. A nuvem oferece flexibilidade, custo-benefício e recursos de alto desempenho que tornam a implementação de tais modelos viável mesmo para equipes menores.
Neste guia, vamos orientá-lo na implementação do Deepseek R1 em três plataformas populares: AWS, Azure e Digital Ocean. Também compartilharemos dicas para otimizar o desempenho e integrar ferramentas como Apidog para gerenciamento de APIs.
Preparando seu ambiente
Antes de começar a implementação, vamos preparar nosso ambiente. Isso envolve configurar tokens de autenticação, garantir a disponibilidade de GPU e organizar seus arquivos.
Tokens de autenticação
Todo provedor de nuvem exige alguma forma de autenticação. Por exemplo:
- Na AWS, você precisará de um papel IAM com permissões para acessar buckets S3 e instâncias EC2.
- No Azure, você pode usar experiências de autenticação simplificadas fornecidas pelos SDKs do Azure Machine Learning.
- No Digital Ocean, gere um token de API a partir do painel da sua conta.
Esses tokens são cruciais porque permitem a comunicação segura entre sua máquina local e a plataforma de nuvem.
Organização de arquivos
Organize seus arquivos de maneira sistemática. Se você estiver usando o Docker (que é altamente recomendado), crie um Dockerfile contendo todas as dependências. Ferramentas como Tensorfuse fornecem modelos pré-construídos para implementar Deepseek R1. Da mesma forma, usuários do IBM Cloud devem enviar seus arquivos de modelo para o Object Storage antes de prosseguir.
Opção 1: Implementando Deepseek R1 na AWS usando Tensorfuse
Vamos começar com a AWS (Amazon Web Services), uma das plataformas de nuvem mais amplamente utilizadas. A AWS é como um canivete suíço — tem ferramentas para cada tarefa, desde armazenamento até poder de computação. Nesta seção, vamos nos concentrar em implementar Deepseek R1 usando Tensorfuse, que simplifica o processo significativamente.
Por que construir com Deepseek-R1?
Antes de mergulhar nos detalhes técnicos, vamos entender por que o Deepseek R1 se destaca:
- Alto desempenho em avaliações: Consegue resultados fortes em benchmarks padrão da indústria, marcando 90,8% no MMLU e 79,8% no AIME 2024.
- Raciocínio avançado: Lida com tarefas de raciocínio lógico em múltiplas etapas com contexto mínimo, destacando-se em benchmarks como o LiveCodeBench (Pass@1-COT) com uma pontuação de 65,9%.
- Suporte multilíngue: Pré-treinado em dados linguísticos diversos, tornando-o apto para compreensão multilíngue.
- Modelos destilados escaláveis: Variantes destiladas menores (2B, 7B e 70B) oferecem opções mais baratas sem comprometer o custo.
Essas forças tornam o Deepseek R1 uma excelente escolha para aplicações prontas para a produção, de chatbots a análises de dados em nível empresarial.
Pré-requisitos
Antes de começar, certifique-se de que você configurou o Tensorfuse em sua conta da AWS. Se você ainda não fez isso, siga o guia de Introdução. Essa configuração é como preparar seu espaço de trabalho antes de iniciar um projeto — garante que tudo esteja no lugar para um processo tranquilo.
Passo 1: Defina seu token de autenticação de API
Gere uma string aleatória que será usada como seu token de autenticação de API. Armazene-o como um segredo no Tensorfuse usando o seguinte comando:
tensorkube secret create vllm-token VLLM_API_KEY=vllm-key --env default
Certifique-se de que, na produção, você use um token gerado aleatoriamente. Você pode gerar um rapidamente usando openssl rand -base64 32 e lembre-se de mantê-lo seguro, pois os segredos do Tensorfuse são opacos.
Passo 2: Prepare o Dockerfile
Usaremos a imagem oficial vLLM da OpenAI como nossa imagem base. Esta imagem vem com todas as dependências necessárias para executar o vLLM.
Aqui está a configuração do Dockerfile:
# Dockerfile para Deepseek-R1-671B
FROM vllm/vllm-openai:latest
# Ativar HF Hub Transfer
ENV HF_HUB_ENABLE_HF_TRANSFER 1
# Expor a porta 80
EXPOSE 80
# Entrypoint com a chave da API
ENTRYPOINT ["python3", "-m", "vllm.entrypoints.openai.api_server", \
"--model", "deepseek-ai/DeepSeek-R1", \
"--dtype", "bfloat16", \
"--trust-remote-code", \
"--tensor-parallel-size","8", \
"--max-model-len", "4096", \
"--port", "80", \
"--cpu-offload-gb", "80", \
"--gpu-memory-utilization", "0.95", \
"--api-key", "${VLLM_API_KEY}"]
Essa configuração garante que o servidor vLLM esteja otimizado para os requisitos específicos do Deepseek R1, incluindo utilização de memória GPU e paralelismo de tensores.
Passo 3: Configuração de implementação
Crie um arquivo deployment.yaml para definir suas configurações de implementação:
# deployment.yaml para Deepseek-R1-671B
gpus: 8
gpu_type: h100
secret:
- vllm-token
min-scale: 1
readiness:
httpGet:
path: /health
port: 80
Implemente seu serviço usando o seguinte comando:
tensorkube deploy --config-file ./deployment.yaml
Este comando configura um serviço LLM em produção com escalonamento automático pronto para atender a solicitações autenticadas.
Passo 4: Acessando o aplicativo implementado
Uma vez que a implementação seja bem-sucedida, você pode testar seu endpoint usando curl ou a biblioteca cliente OpenAI do Python. Aqui está um exemplo usando curl:
curl --request POST \
--url YOUR_APP_URL/v1/completions \
--header 'Content-Type: application/json' \
--header 'Authorization: Bearer vllm-key' \
--data '{
"model": "deepseek-ai/DeepSeek-R1",
"prompt": "Earth to Robotland. What's up?",
"max_tokens": 200
}'
Para usuários Python, aqui está um trecho de exemplo:
import openai
# Substitua pela sua URL e token reais
base_url = "YOUR_APP_URL/v1"
api_key = "vllm-key"
openai.api_base = base_url
openai.api_key = api_key
response = openai.Completion.create(
model="deepseek-ai/DeepSeek-R1",
prompt="Olá, Deepseek R1! Como você está hoje?",
max_tokens=200
)
print(response)
Opção 2: Implementando Deepseek R1 na Azure
Implementar o Deepseek R1 no Azure Machine Learning (Azure ML) é um processo simplificado que aproveita a robusta infraestrutura da plataforma e ferramentas avançadas para inferência em tempo real. Nesta seção, vamos orientá-lo na implementação do Deepseek R1 usando os Endpoints Online Gerenciados do Azure ML. Essa abordagem garante escalabilidade, eficiência e facilidade de gerenciamento.
Passo 1: Crie um ambiente personalizado para vLLM no Azure ML
Para começar, precisamos criar um ambiente personalizado adaptado ao vLLM, que servirá como a espinha dorsal para implementar o Deepseek R1. O vLLM é otimizado para inferência de alta capacidade, tornando-o ideal para lidar com grandes modelos de linguagem como o Deepseek R1.
1.1: Defina o Dockerfile: Começamos criando um Dockerfile que especifica o ambiente para nosso modelo. O contêiner base do vLLM inclui todas as dependências e drivers necessários, garantindo uma configuração tranquila:
FROM vllm/vllm-openai:latest
ENV MODEL_NAME deepseek-ai/DeepSeek-R1-Distill-Llama-8B
ENTRYPOINT python3 -m vllm.entrypoints.openai.api_server --model $MODEL_NAME $VLLM_ARGS
Este Dockerfile nos permite passar o nome do modelo via uma variável de ambiente (MODEL_NAME), habilitando flexibilidade na seleção do modelo desejado durante a implementação. Por exemplo, você pode facilmente alternar entre diferentes versões do Deepseek R1 sem modificar o código subjacente.
1.2: Faça login no Azure ML Workspace: A seguir, faça login no seu workspace do Azure ML usando a CLI do Azure. Substitua <subscription ID>, <Azure Machine Learning workspace name> e <resource group> pelos seus detalhes específicos:
az account set --subscription <subscription ID>
az configure --defaults workspace=<Azure Machine Learning workspace name> group=<resource group>
Esta etapa garante que todos os comandos subsequentes sejam executados no contexto do seu workspace.
1.3: Crie o arquivo de configuração do ambiente: Agora, crie um arquivo environment.yml para definir as configurações do ambiente. Este arquivo referencia o Dockerfile que criamos anteriormente:
$schema: https://azuremlschemas.azureedge.net/latest/environment.schema.json
name: r1
build:
path: .
dockerfile_path: Dockerfile
1.4: Construa o ambiente: Com o arquivo de configuração pronto, construa o ambiente usando o seguinte comando:
az ml environment create -f environment.yml
Esta etapa compila o ambiente, tornando-o disponível para uso em sua implementação.
Passo 2: Implemente o Endpoint Online Gerenciado do Azure ML
Uma vez que o ambiente esteja configurado, passamos a implementar o modelo Deepseek R1 usando Endpoints Online Gerenciados do Azure ML. Esses endpoints fornecem capacidades de inferência em tempo real escaláveis, tornando-os perfeitos para aplicações de qualidade de produção.
2.1: Crie o arquivo de configuração do Endpoint: Comece criando um arquivo endpoint.yml para definir o Endpoint Online Gerenciado:
$schema: https://azuremlsdk2.blob.core.windows.net/latest/managedOnlineEndpoint.schema.json
name: r1-prod
auth_mode: key
Essa configuração especifica o nome do endpoint (r1-prod) e o modo de autenticação (key). Você poderá recuperar a URI de pontuação do endpoint e as chaves da API posteriormente para fins de teste.
2.2: Crie o Endpoint: Use o seguinte comando para criar o endpoint:
az ml online-endpoint create -f endpoint.yml
2.3: Recupere o endereço da imagem Docker: Antes de prosseguir, recupere o endereço da imagem Docker criada no Passo 1. Navegue até Azure ML Studio > Environments > r1 para localizar o endereço da imagem. Ele se parecerá com isto:
xxxxxx.azurecr.io/azureml/azureml_xxxxxxxx
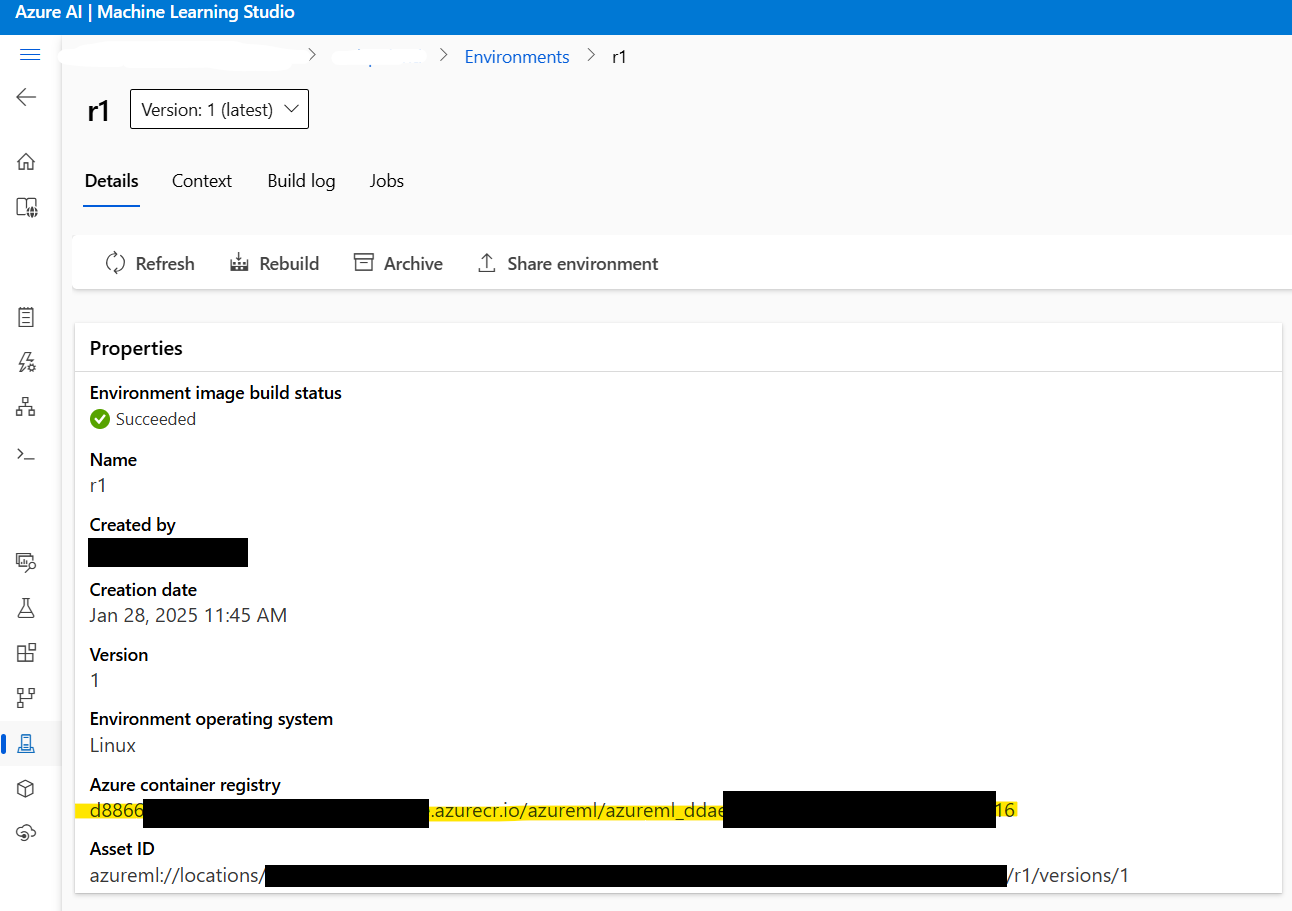
2.4: Crie o arquivo de configuração de implementação: A seguir, crie um arquivo deployment.yml para configurar as definições de implementação. Este arquivo especifica o modelo, o tipo de instância e outros parâmetros:
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineDeployment.schema.json
name: current
endpoint_name: r1-prod
environment_variables:
MODEL_NAME: deepseek-ai/DeepSeek-R1-Distill-Llama-8B
VLLM_ARGS: "" # Argumentos opcionais para o tempo de execução do vLLM
environment:
image: xxxxxx.azurecr.io/azureml/azureml_xxxxxxxx # Cole aqui o endereço da imagem Docker
inference_config:
liveness_route:
port: 8000
path: /ping
readiness_route:
port: 8000
path: /health
scoring_route:
port: 8000
path: /
instance_type: Standard_NC24ads_A100_v4
instance_count: 1
request_settings: # Opcionais, mas importantes para otimizar o throughput
max_concurrent_requests_per_instance: 32
request_timeout_ms: 60000
liveness_probe:
initial_delay: 10
period: 10
timeout: 2
success_threshold: 1
failure_threshold: 30
readiness_probe:
initial_delay: 120 # Aguarde 120 segundos antes de sondar, permitindo que o modelo carregue pacificamente
period: 10
timeout: 2
success_threshold: 1
failure_threshold: 30
Parâmetros-chave a considerar:
instance_count: Define quantos nós deStandard_NC24ads_A100_v4devem ser iniciados. Aumentar esse valor escala o throughput linearmente, mas também aumenta o custo.max_concurrent_requests_per_instance: Controla o número de solicitações simultâneas permitidas por instância. Valores mais altos aumentam o throughput, mas podem elevar a latência.request_timeout_ms: Especifica o tempo máximo (em milissegundos) que o endpoint espera por uma resposta antes de expirar. Ajuste isso com base nas suas necessidades de carga de trabalho.
2.5: Implemente o modelo: Finalmente, implemente o modelo Deepseek R1 usando o seguinte comando:
az ml online-deployment create -f deployment.yml --all-traffic
Esta etapa completa a implementação, tornando o modelo acessível através do endpoint especificado.
Passo 3: Testando a implementação
Uma vez que a implementação seja concluída, é hora de testar o endpoint para garantir que tudo está funcionando conforme o esperado.
3.1: Recupere os detalhes do Endpoint: Use os seguintes comandos para recuperar a URI de pontuação do endpoint e as chaves da API:
az ml online-endpoint show -n r1-prod
az ml online-endpoint get-credentials -n r1-prod
3.2: Transmita respostas usando o SDK do OpenAI: Para transmitir respostas, você pode usar o SDK do OpenAI:
from openai import OpenAI
url = "https://r1-prod.polandcentral.inference.ml.azure.com/v1"
client = OpenAI(base_url=url, api_key="xxxxxxxx")
response = client.chat.completions.create(
model="deepseek-ai/DeepSeek-R1-Distill-Llama-8B",
messages=[
{"role": "user", "content": "Qual é melhor, verão ou inverno?"},
],
stream=True
)
for chunk in response:
delta = chunk.choices[0].delta
if hasattr(delta, "content"):
print(delta.content, end="", flush=True)
Passo 4: Monitoramento e escalonamento automático
O Azure Monitor fornece informações abrangentes sobre a utilização de recursos, incluindo métricas de GPU. Quando sob carga constante, você notará que o vLLM consome aproximadamente 90% da memória da GPU, com a utilização da GPU próxima de 100%. Essas métricas ajudam você a ajustar o desempenho e otimizar custos.
Para habilitar o escalonamento automático, configure políticas de escalonamento com base nos padrões de tráfego. Por exemplo, você pode aumentar o instance_count durante horários de pico e reduzi-lo durante horários fora de pico para equilibrar desempenho e custo.
Opção 3: Implementando Deepseek R1 no Digital Ocean
Finalmente, vamos discutir a implementação do Deepseek R1 no Digital Ocean, conhecido por sua simplicidade e acessibilidade.
Pré-requisitos
Antes de mergulhar no processo de implementação, vamos garantir que você tenha tudo o que precisa:
- Conta DigitalOcean: Se você ainda não tiver uma, inscreva-se para obter uma conta DigitalOcean. Novos usuários recebem um crédito de $100 pelos primeiros 60 dias, o que é perfeito para experimentar com droplet com GPU.
- Familiaridade com Shell Bash: Você usará o terminal para interagir com seu droplet, baixar dependências e executar comandos. Não se preocupe se você não é um especialista — cada comando será fornecido passo a passo.
- Droplet com GPU: A DigitalOcean agora oferece droplets com GPU projetados especificamente para cargas de trabalho de IA/ML. Esses droplets vêm equipados com GPUs NVIDIA H100, tornando-os ideais para implementar grandes modelos como o Deepseek R1.
Com esses pré-requisitos em ordem, você está pronto para seguir em frente.
Configurando o droplet com GPU
O primeiro passo é configurar sua máquina. Pense nisso como preparar a tela antes de pintar — você quer que tudo esteja pronto antes de mergulhar nos detalhes.
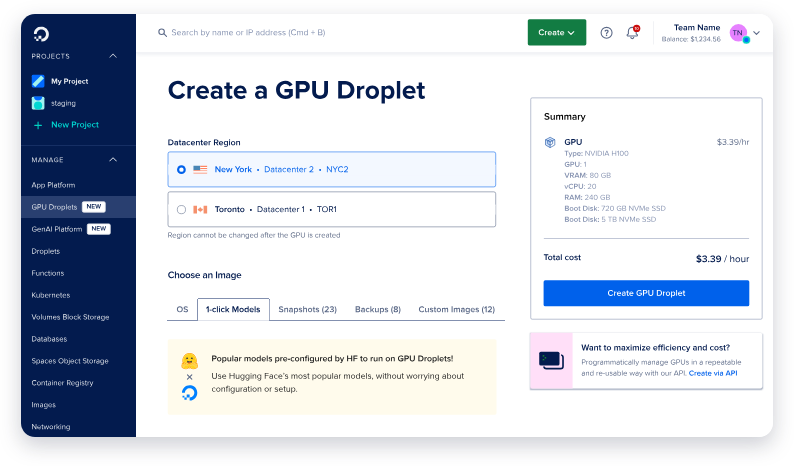
Passo 1: Crie um novo droplet com GPU
- Faça login na sua conta DigitalOcean e navegue até a seção Droplets.
- Clique em Criar Droplet e selecione o sistema operacional Pronto para IA/ML. Este SO vem pré-configurado com drivers CUDA e outras dependências necessárias para aceleração de GPU.
- Escolha um único GPU NVIDIA H100, a menos que você planeje implementar a maior versão de 671 bilhões de parâmetros do Deepseek R1, que pode requerer várias GPUs.
- Uma vez que seu droplet seja criado, aguarde enquanto ele é inicializado. Este processo geralmente leva apenas alguns minutos.
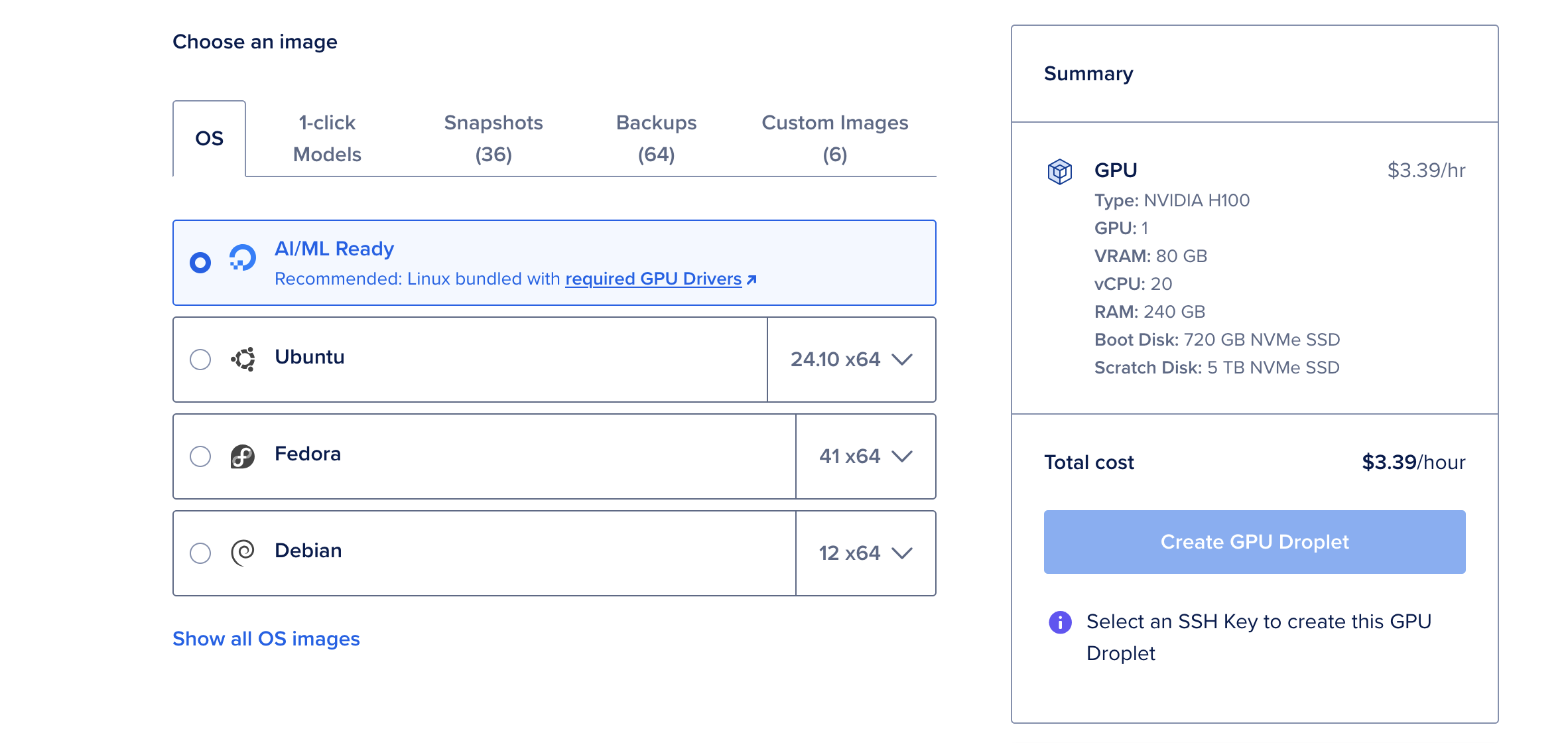
Por que escolher a GPU H100?
A GPU NVIDIA H100 é uma potência, oferecendo 80GB de vRAM, 240GB de RAM e 720GB de armazenamento. A $6,47 por hora, é uma opção econômica para implementar grandes modelos de linguagem como o Deepseek R1. Para modelos menores, como a versão de 70 bilhões de parâmetros, uma única GPU H100 é mais do que suficiente.
Instalando Ollama & Deepseek R1
Agora que seu droplet com GPU está em funcionamento, é hora de instalar as ferramentas necessárias para executar o Deepseek R1. Usaremos o Ollama, uma estrutura leve projetada para simplificar a implementação de grandes modelos de linguagem.
Passo 1: Abra o Console Web
A partir da página de detalhes do seu droplet, clique no botão Console Web localizado no canto superior direito. Isso abre uma janela de terminal diretamente no seu navegador, eliminando a necessidade de configuração SSH.
Passo 2: Instale o Ollama
No terminal, cole o seguinte comando para instalar o Ollama:
curl -fsSL https://ollama.com/install.sh | sh
Este script automatiza o processo de instalação, baixando e configurando todas as dependências necessárias. A instalação pode levar alguns minutos, mas, uma vez concluída, sua máquina estará pronta para executar o Deepseek R1.
Passo 3: Execute o Deepseek R1
Com o Ollama instalado, executar o Deepseek R1 é tão simples quanto rodar um único comando. Para esta demonstração, usaremos a versão de 70 bilhões de parâmetros, que encontra um equilíbrio entre desempenho e uso de recursos:
ollama run deepseek-r1:70b
Na primeira vez que você executar este comando, ele fará o download do modelo (aproximadamente 40GB) e o carregará na memória. Esse processo pode levar vários minutos, mas execuções subsequentes serão muito mais rápidas, pois o modelo estará armazenado em cache localmente.
Uma vez que o modelo esteja carregado, você verá um prompt interativo onde pode começar a interagir com o Deepseek R1. É como ter uma conversa com um assistente altamente inteligente!
Testando e monitorando com Apidog
Uma vez que seu modelo Deepseek R1 esteja implementado, é hora de testar e monitorar seu desempenho. É aqui que Apidog brilha.
O que é Apidog?
Apidog é uma poderosa ferramenta de teste de API projetada para simplificar a depuração e validação. Com sua interface intuitiva, você pode criar rapidamente casos de teste, simular respostas e monitorar a saúde da API.
Por que usar Apidog?
- Facilidade de uso: Sem necessidade de codificação! A funcionalidade de arrastar e soltar permite que você construa testes visualmente.
- Capacidades de integração: Integra-se perfeitamente com pipelines de CI/CD, tornando-o ideal para fluxos de trabalho DevOps.
- Insights em tempo real: Monitore latência, taxas de erro e throughput em tempo real.
Integrando o Apidog em seu fluxo de trabalho, você pode garantir que sua implementação do Deepseek R1 permaneça confiável e desempenhe de maneira ideal sob diferentes cargas.
Conclusão
Implementar o Deepseek R1 na nuvem não precisa ser intimidador. Ao seguir os passos descritos acima, você pode configurar com sucesso este modelo de ponta na AWS, Azure ou Digital Ocean. Lembre-se de aproveitar ferramentas como o Apidog para otimizar os processos de teste e monitoramento.