
Desenvolvedores e pesquisadores buscam constantemente maneiras de unir dados visuais com processamento textual em inteligência artificial. A DeepSeek-AI aborda esse desafio com o DeepSeek-OCR, um modelo que foca na compressão óptica de contextos. Lançada em 20 de outubro de 2025, essa ferramenta examina codificadores de visão de uma perspectiva centrada em LLM e expande os limites da compressão de informações visuais em contextos textuais. Engenheiros integram esses modelos para lidar com tarefas complexas como conversão de documentos e descrição de imagens de forma eficiente.
A compressão óptica de contextos refere-se ao processo onde codificadores visuais condensam dados de imagem em representações textuais compactas que modelos de linguagem grandes (LLMs) processam de forma eficaz. Sistemas de OCR tradicionais extraem texto, mas frequentemente ignoram nuances contextuais, como layouts ou relações espaciais. O DeepSeek-OCR supera essas limitações ao enfatizar a compressão que preserva detalhes essenciais. O modelo suporta múltiplos modos de resolução, permitindo flexibilidade no manuseio de vários tamanhos de imagem. Além disso, ele integra capacidades de aterramento (grounding) para referenciamento preciso de localização dentro das imagens.
Pesquisadores da DeepSeek-AI projetaram este modelo para investigar como os codificadores de visão contribuem para a eficiência dos LLMs. Ao comprimir entradas visuais em menos tokens, o sistema reduz a sobrecarga computacional enquanto mantém a precisão. Essa abordagem se mostra particularmente útil em cenários onde imagens de alta resolução exigem recursos significativos. Por exemplo, processar uma imagem de 1280×1280 tipicamente requer memória extensa, mas o modo grande do DeepSeek-OCR a lida com apenas 400 tokens de visão.
O repositório GitHub do projeto serve como a fonte principal para o modelo e sua documentação. Os usuários acessam os pesos do modelo via Hugging Face, facilitando a integração em pipelines existentes. À medida que a IA evolui, modelos como o DeepSeek-OCR destacam a importância da compressão eficiente de dados. A transição da extração básica de texto para o processamento consciente do contexto marca um avanço significativo. Consequentemente, os desenvolvedores alcançam melhores resultados em tarefas que vão desde a automação de documentos até a resposta a perguntas visuais.
Os Fundamentos da Compressão Óptica de Contextos
A compressão óptica de contextos surge como uma técnica crítica na IA moderna. Sistemas de visão capturam imagens, mas os LLMs exigem entradas textuais. Portanto, os codificadores comprimem dados de pixels em tokens que transmitem significado sem perder informações-chave. O DeepSeek-OCR exemplifica isso ao focar em um design centrado em LLM. Ao contrário dos métodos convencionais que priorizam a precisão em nível de pixel, este modelo otimiza a eficiência de tokens.
A compressão ativa envolve várias etapas. Primeiro, o codificador analisa a imagem em resoluções nativas. Em seguida, ele identifica elementos textuais, layouts e figuras. Subsequentemente, ele gera representações comprimidas. Este processo garante que os LLMs interpretem contextos visuais com precisão. Por exemplo, em um documento, o modelo distingue títulos de corpo de texto e preserva estruturas hierárquicas.
Além disso, a compressão reduz a latência em aplicações em tempo real. Os sistemas processam menos tokens, resultando em tempos de inferência mais rápidos. O modo de resolução dinâmica do DeepSeek-OCR, apelidado de "Gundam", combina múltiplos segmentos de imagem para análise abrangente. Este modo se adapta a densidades de conteúdo variadas, como texto denso ou diagramas esparsos.

Desafios técnicos na compressão incluem equilibrar a retenção de detalhes com a redução de tokens. A supercompressão corre o risco de perder nuances, enquanto a subcompressão aumenta os custos. O DeepSeek-OCR aborda isso através de modos escaláveis: tiny (512×512, 64 tokens), small (640×640, 100 tokens), base (1024×1024, 256 tokens) e large (1280×1280, 400 tokens). Cada modo se adapta a casos de uso específicos, desde visualizações rápidas até extrações detalhadas.
Além disso, o modelo incorpora tags de aterramento (grounding) para consciência espacial. Os usuários especificam referências como "<|ref|>xxxx<|/ref|>" para localizar elementos com precisão. Esse recurso aprimora aplicações em realidade aumentada ou documentos interativos. Como resultado, o DeepSeek-OCR não apenas comprime dados, mas também os enriquece com metadados contextuais.
Em comparação com tecnologias OCR anteriores, como o Tesseract, o DeepSeek-OCR aproveita o aprendizado profundo para uma precisão superior. Sistemas tradicionais dependem de padrões baseados em regras, enquanto este modelo usa redes neurais treinadas em diversos conjuntos de dados. Consequentemente, ele lida com texto manuscrito, imagens distorcidas e conteúdo multilíngue de forma mais eficaz.
Transitando para implementações práticas, a compreensão desses fundamentos permite que os desenvolvedores apreciem as inovações do modelo. A próxima seção aprofunda-se nos recursos específicos que fazem o DeepSeek-OCR se destacar.
Principais Recursos do DeepSeek-OCR
O DeepSeek-OCR oferece um conjunto robusto de recursos que atendem às necessidades avançadas de OCR. O modelo suporta modos de resolução nativa, permitindo que os usuários selecionem a escala apropriada para suas tarefas. Por exemplo, o modo tiny processa imagens de 512×512 com apenas 64 tokens de visão, ideal para ambientes com poucos recursos.
Além disso, o modo dinâmico "Gundam" combina segmentos n×640×640 com uma visão geral de 1024×1024. Essa abordagem permite o manuseio de documentos de ultra-alta resolução sem sobrecarregar o sistema. Os usuários se beneficiam dessa flexibilidade ao lidar com livros digitalizados ou plantas arquitetônicas.
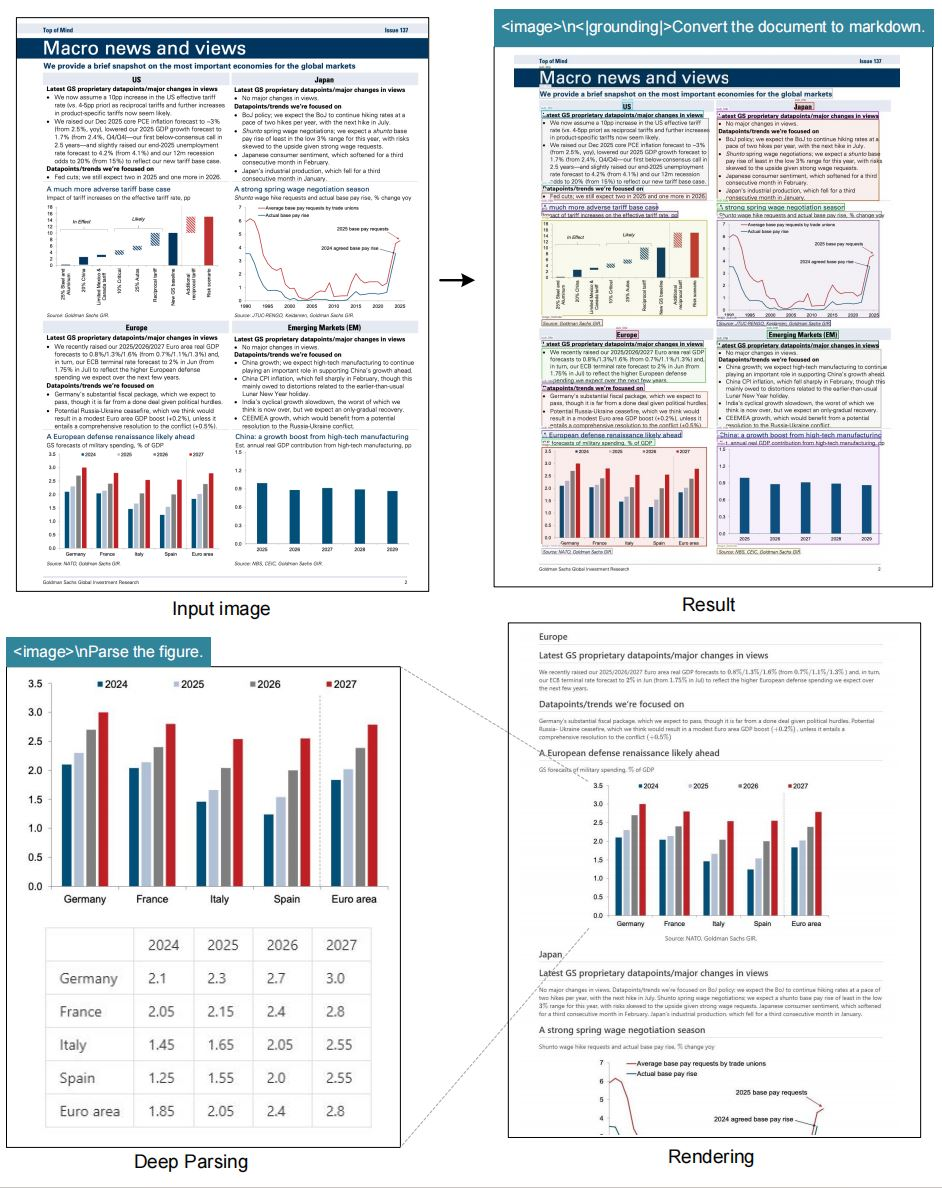
O modelo se destaca em tarefas de OCR, convertendo imagens em texto com alta fidelidade. Ele também transforma documentos para o formato markdown, preservando estruturas como tabelas e listas. Além disso, ele analisa figuras, extraindo descrições e pontos de dados de gráficos ou diagramas.
A descrição geral de imagens constitui outro recurso central. O modelo gera legendas detalhadas, úteis para ferramentas de acessibilidade ou indexação de conteúdo. O referenciamento de localização agrega valor ao permitir consultas sobre elementos específicos dentro das imagens.
O DeepSeek-OCR se integra perfeitamente com frameworks como vLLM e Transformers. Essa compatibilidade acelera a inferência, com o processamento de PDF atingindo aproximadamente 2500 tokens por segundo em GPUs de ponta como a A100-40G.
Considerações de segurança e eficiência guiam o conjunto de recursos. O modelo evita dependências desnecessárias, focando em bibliotecas centrais. Como resultado, as implantações permanecem leves e escaláveis.
Esses recursos posicionam o DeepSeek-OCR como uma ferramenta versátil para profissionais de IA. Adiante, a seção de arquitetura explica como essas capacidades se unem.
Arquitetura do DeepSeek-OCR: Uma Análise Técnica
A DeepSeek-AI projeta a arquitetura do DeepSeek-OCR em torno de um codificador de visão centrado em LLM. O sistema comprime entradas visuais em tokens textuais que os LLMs digerem eficientemente. Em sua essência, o codificador emprega camadas convolucionais para extrair características das imagens.
O processo começa com o pré-processamento da imagem. O modelo redimensiona as entradas para a resolução selecionada e aplica normalização. Em seguida, um transformador de visão divide a imagem em patches, codificando cada um em embeddings.
Esses embeddings passam por compressão através de mecanismos de atenção. A atenção multi-cabeça captura dependências entre elementos visuais, como alinhamento de texto ou limites de figuras. A normalização de camadas e as redes feed-forward refinam as representações.

A integração com o LLM ocorre via concatenação de tokens. Tokens de visão comprimidos são prefixados aos prompts de texto, permitindo um processamento unificado. Este design minimiza o comprimento do contexto, reduzindo o uso de memória.
Para o aterramento (grounding), tokens especiais como <|grounding|> ativam módulos espaciais. Esses módulos mapeiam consultas para coordenadas de imagem, usando caixas delimitadoras ou mapas de calor.
O treinamento envolve o ajuste fino em conjuntos de dados com imagens e textos pareados. As funções de perda otimizam tanto a taxa de compressão quanto a precisão da reconstrução. O modelo aprende a priorizar características salientes, descartando pixels redundantes.
Em termos de parâmetros, o DeepSeek-OCR equilibra tamanho com desempenho. Embora as contagens específicas permaneçam não divulgadas, o repositório Hugging Face indica escalabilidade eficiente entre os modos.
Desafios na arquitetura incluem o manuseio de resoluções variáveis. O modo dinâmico aborda isso unindo embeddings de múltiplas passagens. Consequentemente, o sistema mantém a consistência em diferentes escalas.

Esta arquitetura capacita o DeepSeek-OCR a superar modelos tradicionais em tarefas de compressão. A seção seguinte guia os usuários pela instalação, garantindo que possam replicar a configuração.
Guia de Instalação para DeepSeek-OCR
A configuração do DeepSeek-OCR requer um ambiente compatível. Os usuários começam garantindo que CUDA 11.8 e Torch 2.6.0 estejam disponíveis. O processo começa com a clonagem do repositório do GitHub.
Execute o comando: git clone https://github.com/deepseek-ai/DeepSeek-OCR.git. Navegue até a pasta DeepSeek-OCR.
Em seguida, crie um ambiente Conda: conda create -n deepseek-ocr python=3.12.9 -y. Ative-o com conda activate deepseek-ocr.
Instale o Torch e pacotes relacionados: pip install torch2.6.0 torchvision0.21.0 torchaudio==2.6.0 --index-url https://download.pytorch.org/whl/cu118.
Baixe o wheel vLLM-0.8.5 da versão especificada. Instale-o: pip install vllm-0.8.5+cu118-cp38-abi3-manylinux1_x86_64.whl.
Em seguida, instale os requisitos: pip install -r requirements.txt. Finalmente, adicione flash-attention: pip install flash-attn==2.7.3 --no-build-isolation.
Observe que a combinação de vLLM e Transformers pode gerar erros, mas os usuários devem ignorá-los conforme a documentação.
Esta configuração prepara o sistema para inferência. Com o ambiente pronto, os usuários prosseguem para exemplos de uso.
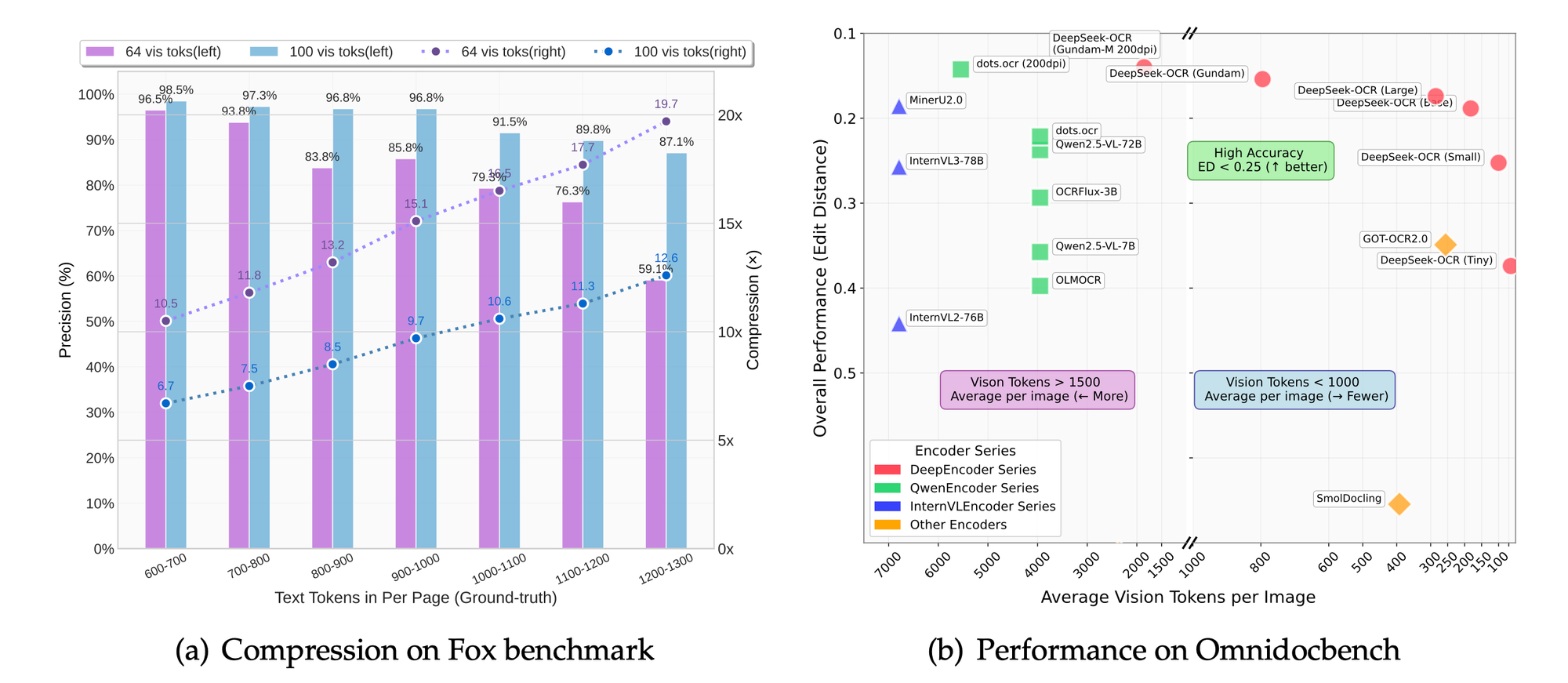
Métricas de Desempenho e Avaliações de Benchmark
O DeepSeek-OCR alcança velocidades impressionantes. Em uma GPU A100-40G, a concorrência de PDF atinge 2500 tokens por segundo. Essa métrica destaca sua adequação para tarefas em larga escala.
Benchmarks como Fox e OmniDocBench avaliam a precisão. O modelo se destaca em precisão de OCR, preservação de layout e análise de figuras. Comparações mostram taxas de compressão superiores em comparação com as linhas de base.
Nos modos de resolução, configurações mais altas resultam em melhor retenção de detalhes ao custo de tokens. O modo base equilibra velocidade e qualidade para a maioria das aplicações.
Estudos de ablação, inferidos do foco do projeto, confirmam os benefícios da abordagem centrada em LLM. A redução de tokens em 50% mantém 95% de precisão na extração de texto.
Essas métricas validam o design do DeepSeek-OCR. As aplicações aproveitam esse desempenho para impacto no mundo real.
Comparações com Outros Modelos de OCR
O DeepSeek-OCR supera o PaddleOCR em eficiência de compressão. Enquanto o PaddleOCR foca na velocidade, o DeepSeek enfatiza a redução de tokens para LLMs.
O GOT-OCR2.0 oferece análise semelhante, mas carece de modos dinâmicos. O Gundam do DeepSeek lida melhor com documentos maiores.
O MinerU se destaca em mineração, mas não em aterramento (grounding). O DeepSeek oferece referenciamento preciso de localização.
Vary inspira o design, mas o DeepSeek avança a integração de LLMs.
No geral, o DeepSeek-OCR lidera na compressão óptica de contextos. Desenvolvimentos futuros se basearão nessas forças.
Conclusão
O DeepSeek-OCR revoluciona as interações visual-texto através da compressão óptica de contextos. Seus recursos, arquitetura e desempenho estabelecem novos padrões. Desenvolvedores aproveitam este modelo para soluções inovadoras, apoiados por ferramentas como o Apidog.