
Como uma ferramenta colaborativa para **design** de API, **documentação**, **depuração**, **simulação** (mocking) e **testes**, o Apidog possui um recurso muito elogiado: **o suporte a operações de banco de dados ao enviar/receber requisições**. Esse recurso facilita muito os usuários que precisam preparar dados de requisição ao chamar um endpoint ou inserir dados em um banco de dados ao receber uma resposta, tornando-o um favorito entre os usuários.
No entanto, como muitos usuários fazem uso extensivo desse recurso diariamente, algumas áreas para melhoria foram identificadas. Um dos pontos mais frequentemente levantados é:
A configuração de conexão com o banco de dados pode ser configurada pelo administrador da equipe e, em seguida, usada colaborativamente por outros membros da equipe? É realmente problemático para todos terem que reinserir os detalhes da conexão.
Desde o design inicial desse recurso, já havíamos considerado permitir que as configurações de banco de dados fossem usadas colaborativamente. No entanto, permitir que os usuários salvem informações sensíveis, como nomes de usuário e senhas de banco de dados, em um servidor na nuvem é uma questão que exige consideração cuidadosa. Portanto, a **segurança dos dados** foi o motivo principal pelo qual o uso colaborativo das configurações de conexão com o banco de dados não foi implementado naquela época.
Hoje, o Apidog se tornou a principal ferramenta de colaboração e gerenciamento de API para milhões de desenvolvedores, e as próprias capacidades fundamentais do Apidog se tornaram mais poderosas. Portanto, reconsideramos esse requisito de otimização para o uso colaborativo das configurações de conexão com o banco de dados, buscando equilibrar a segurança dos dados e a eficiência do desenvolvimento para satisfazer nossos usuários.
Armazenando Configurações de Conexão com o Banco de Dados na Nuvem
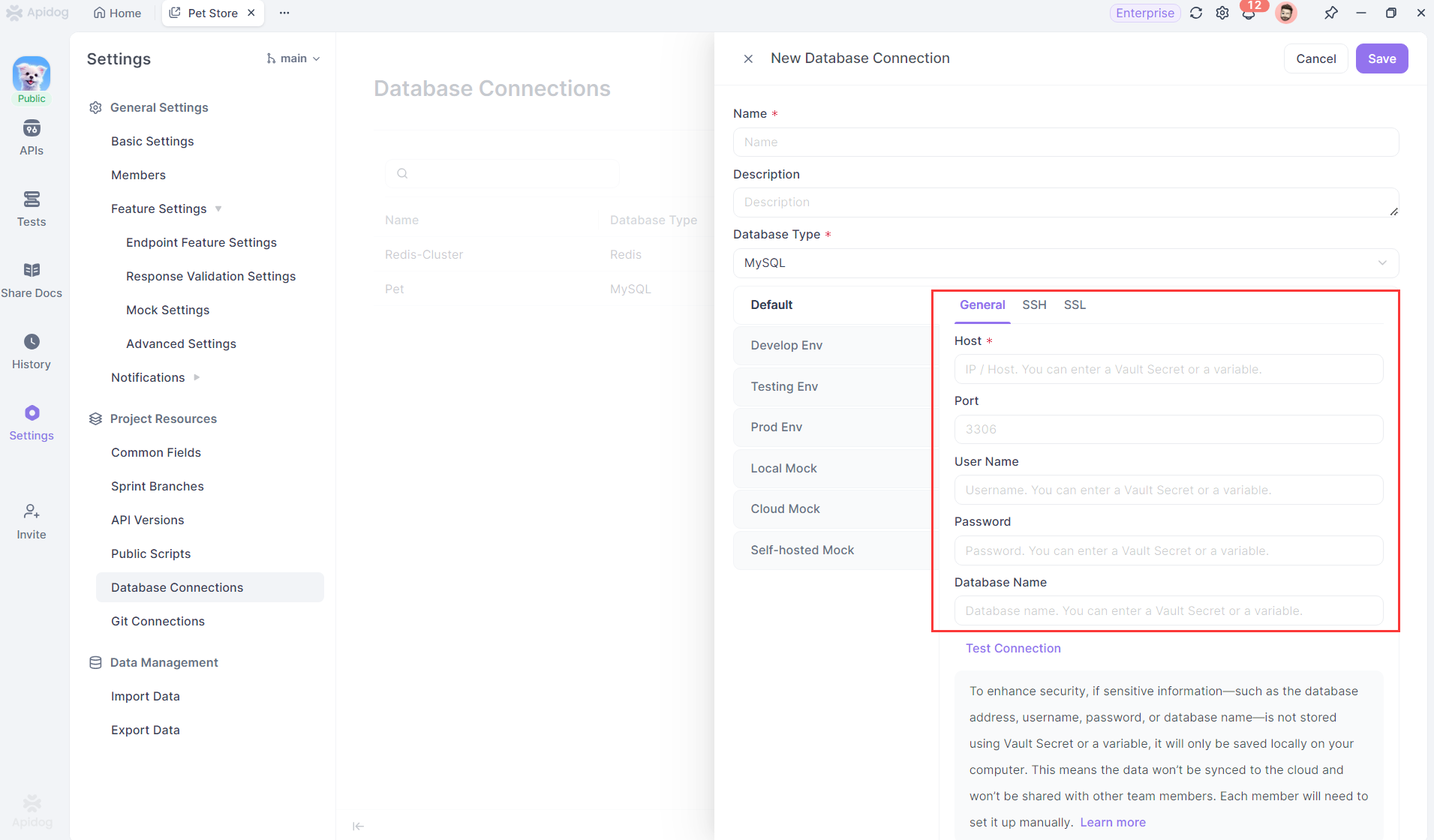
Passo 1: Criar Nova Conexão com o Banco de Dados
Quando sua versão do Apidog for atualizada para **2.6.50** ou superior, vá para "Configurações do Projeto -> Conexão com o Banco de Dados" e clique para criar uma nova conexão com o banco de dados. Você descobrirá que todos os campos de conexão o guiam a usar variáveis para preencher os valores dos campos.
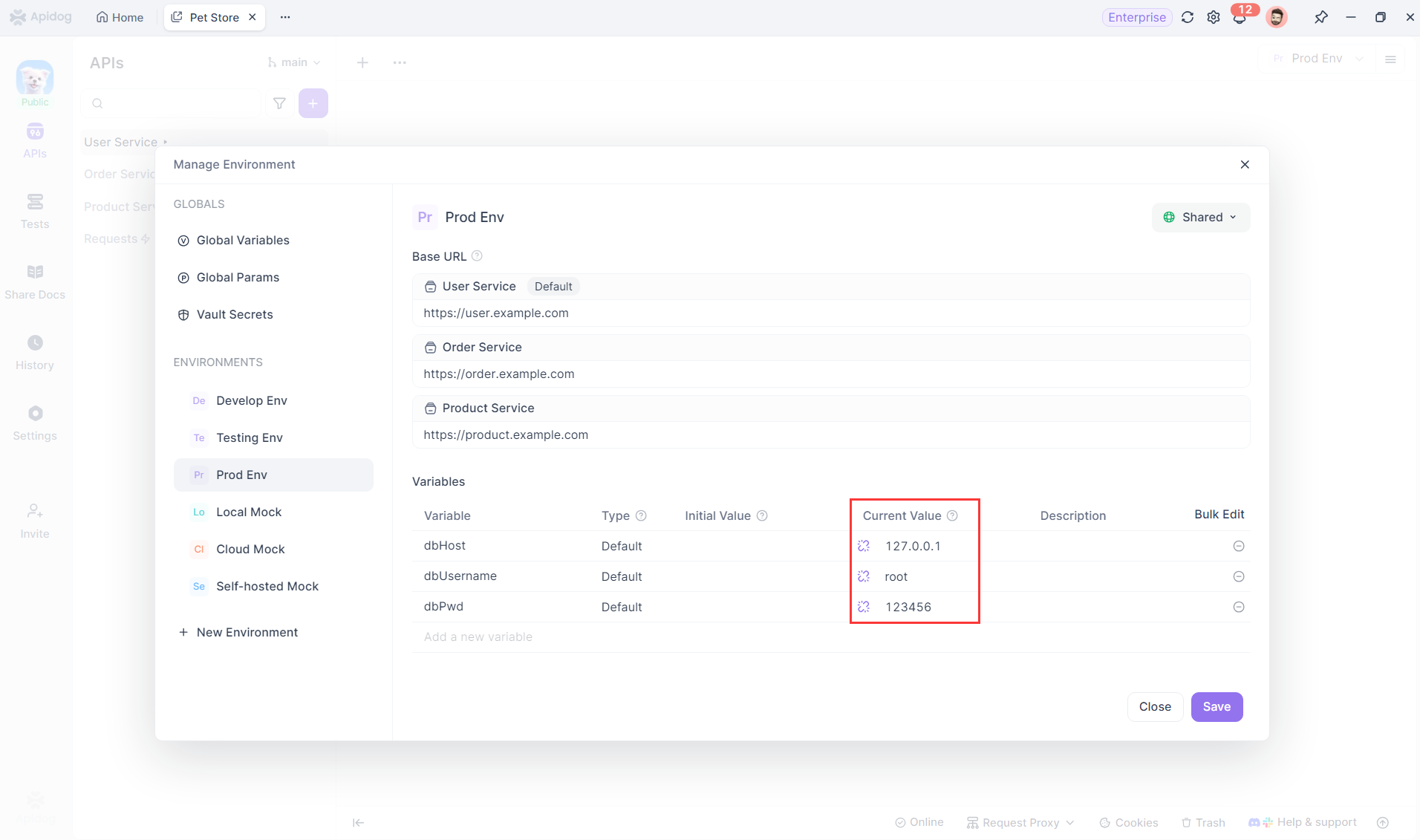
Passo 2: Configurar Variáveis em Diferentes Ambientes
No gerenciamento de ambientes, configure variáveis para conexões de banco de dados a serem usadas em diferentes ambientes. Dessa forma, essas variáveis podem ser aplicadas nas configurações de conexão com o banco de dados.
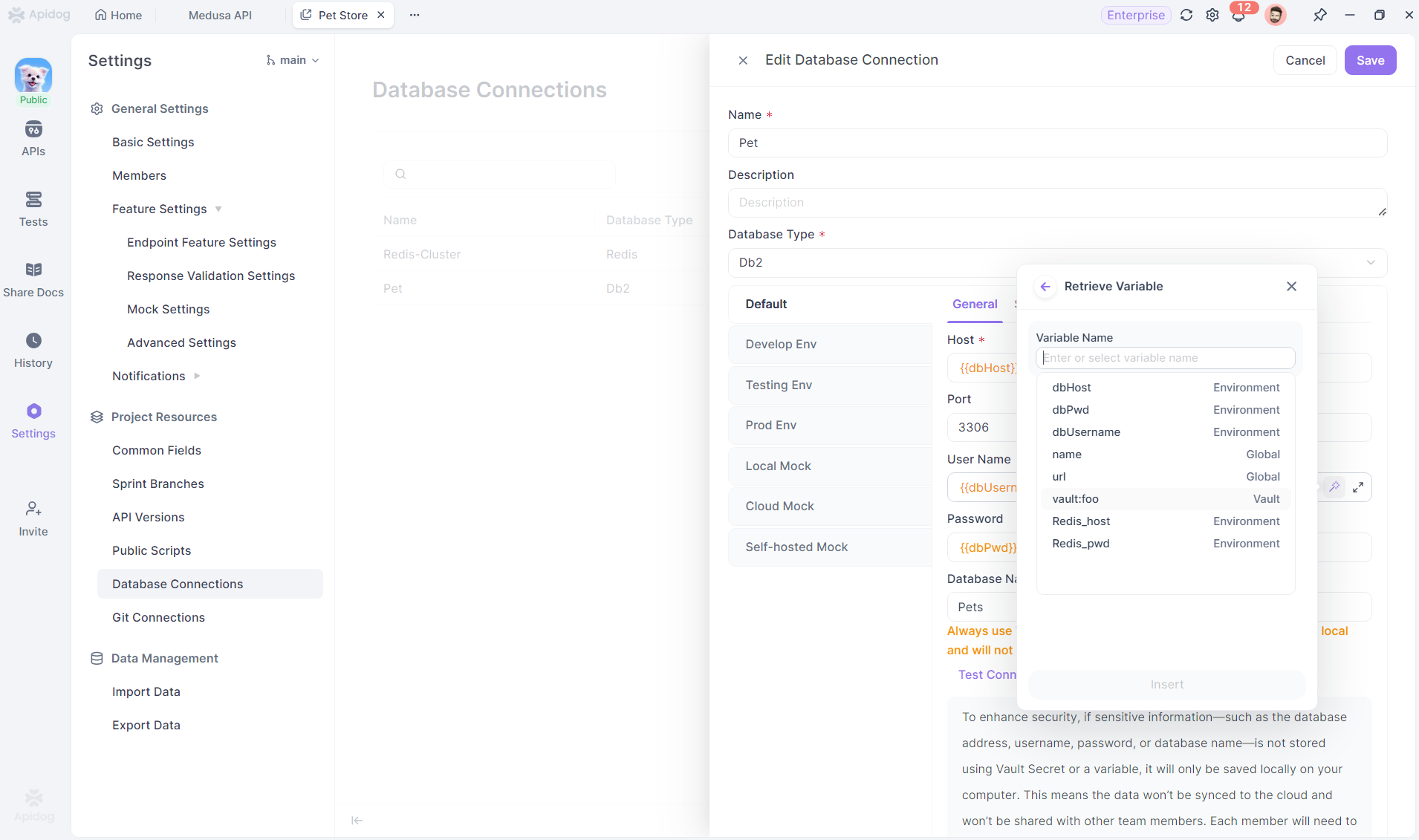
Passo 3: Configurar Conexões com o Banco de Dados Usando Variáveis
De volta à página de configuração da conexão com o banco de dados, você pode preencher manualmente as variáveis usando o formato de variável, ou referenciar diretamente essas variáveis através do recurso de valor dinâmico. Recomendamos usar variáveis de ambiente aqui para que a configuração mude automaticamente com o contexto de diferentes ambientes. Exceto pelo número da porta, todos os outros campos são melhor preenchidos usando variáveis.
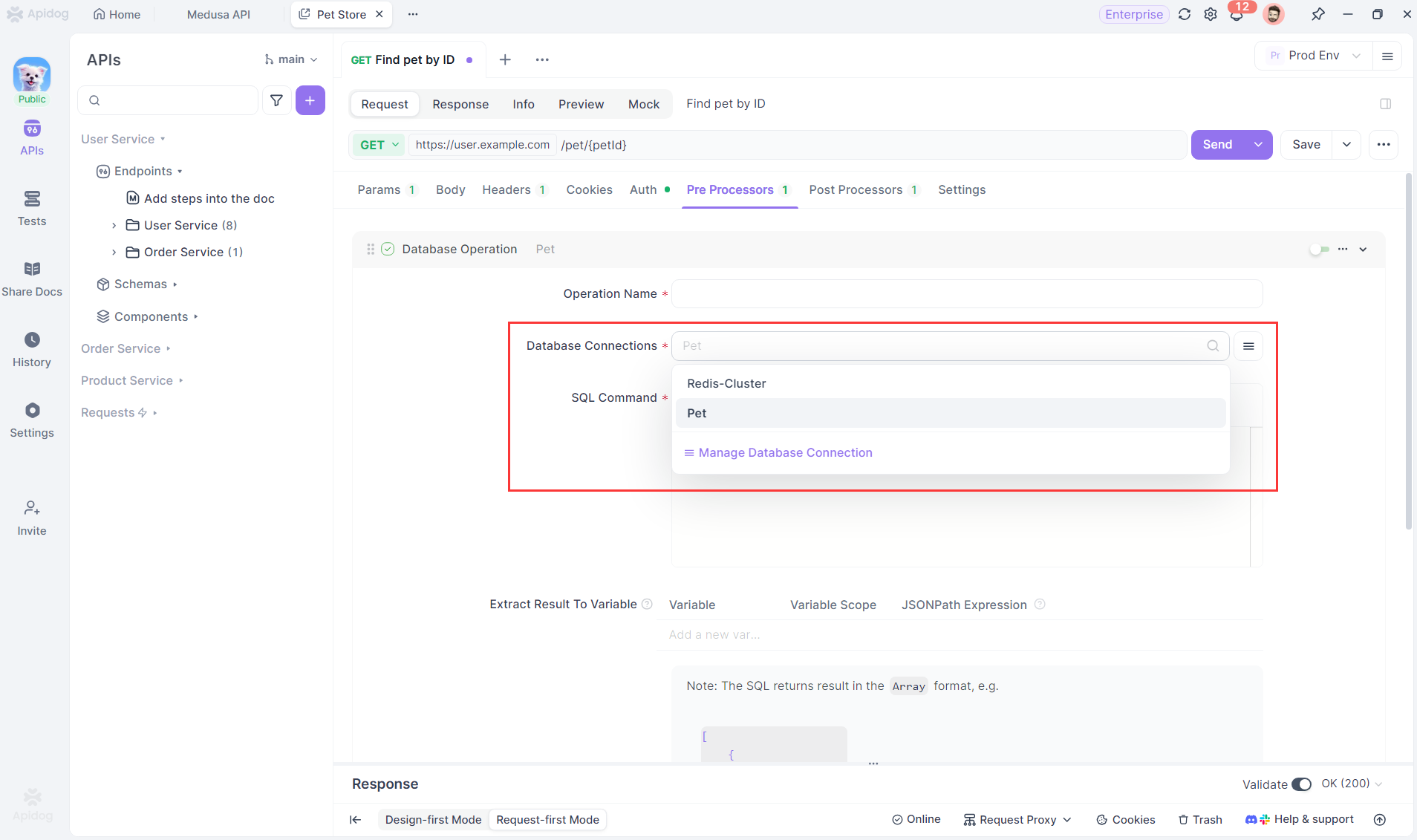
Passo 4: Salvar e Usar Conexões com o Banco de Dados
Salve a configuração de conexão com o banco de dados que usa variáveis, e ela poderá ser usada em operações de banco de dados no gerenciamento de API, testes automatizados e outras áreas.
Em uso, o mecanismo de uso real para configurações de conexão com o banco de dados salvas localmente versus as salvas na nuvem é o seguinte:
| Configuração Salva Localmente (Sem Usar Variáveis) | Configuração Salva na Nuvem (Usando Variáveis) |
| 1. Quando uma requisição de endpoint aciona uma operação de banco de dados, a configuração de banco de dados especificada é lida. | 1. Quando uma requisição de endpoint aciona uma operação de banco de dados, a configuração de banco de dados especificada é lida. |
| 2. O sistema lê os detalhes da configuração de um arquivo local, usando valores reais diretamente. | 2. A configuração é buscada na nuvem e contém variáveis. O sistema resolve essas variáveis com base em seus nomes e prioridade. |
| 3. Esses valores (por exemplo, host, nome de usuário, senha) são usados para construir uma conexão completa com o banco de dados e iniciar a conexão. | 3. As variáveis são substituídas por seus valores reais para formar uma configuração completa de conexão com o banco de dados, e a conexão é iniciada. |
| 4. Uma vez que a conexão é bem-sucedida, as instruções SQL definidas na operação de banco de dados são executadas, juntamente com quaisquer operações como salvar resultados em variáveis. | 4. Uma vez que a conexão é bem-sucedida, as instruções SQL definidas na operação de banco de dados são executadas, juntamente com quaisquer operações como salvar resultados em variáveis. |
DICA PROFISSIONAL: Para outros membros do projeto que precisam usar essa configuração de conexão com o banco de dados, agora eles só precisam ir ao gerenciamento de ambiente, encontrar as variáveis correspondentes e preencher os valores locais, sem ter que configurar no gerenciamento de projeto como antes.
Esses são os passos detalhados para configurar conexões de banco de dados na nuvem. Como o uso de valores locais é recomendado, e a configuração real ainda é armazenada localmente, não há necessidade de se preocupar com riscos de segurança de dados. As variáveis simplesmente tornam o processo mais conveniente e gerenciável.
O Apidog também continua a suportar a inserção de valores reais diretamente nas configurações de conexão com o banco de dados. Isso garante compatibilidade com as configurações existentes e suporta usuários que preferem trabalhar com dados locais. No entanto, um lembrete claro será exibido, encorajando os usuários a mudar para variáveis e salvá-las na nuvem para uma experiência melhor e mais otimizada.
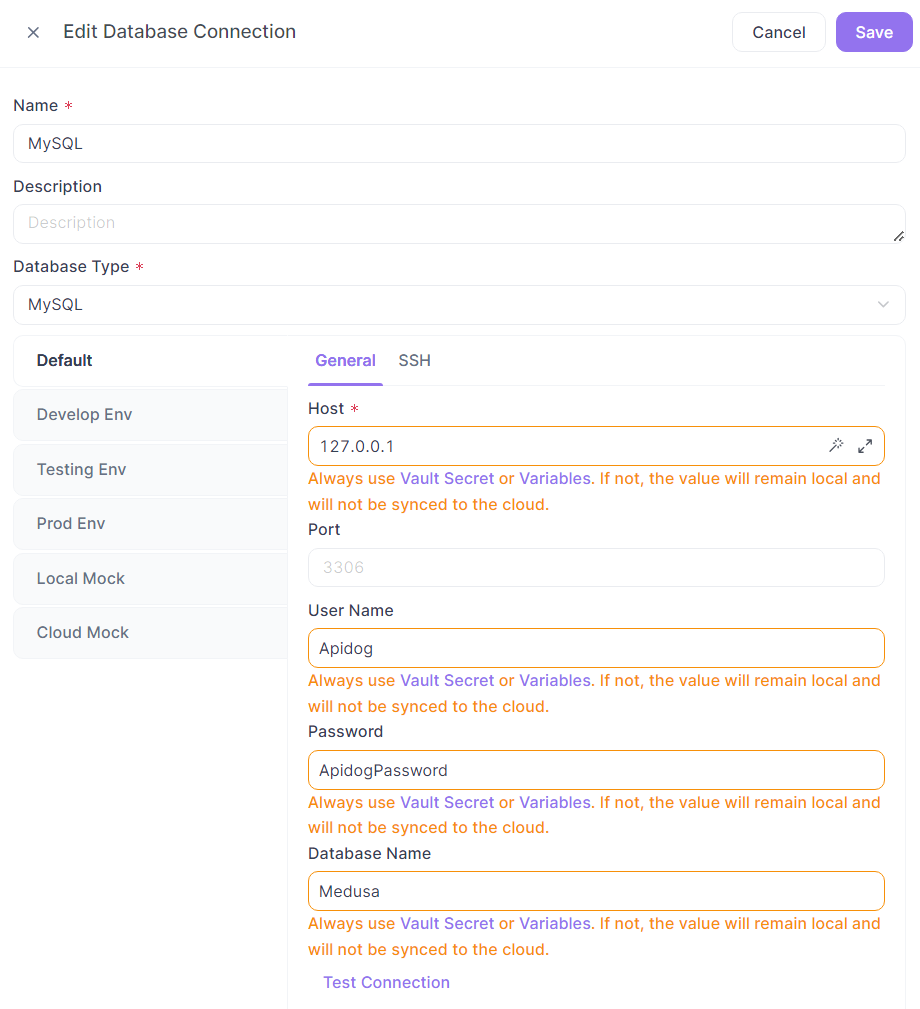
Precauções para Usar Conexões de Banco de Dados na Nuvem:
Nas configurações de conexão com o banco de dados, quando variáveis são usadas, o que é realmente salvo na nuvem é o nome da variável. Ao executar conexões de banco de dados, a configuração de conexão completa será montada de acordo com as regras de uso de variáveis para iniciar a conexão.
✅ Ações Recomendadas:
- Use "Valor Atual" ou "Variável Vault" para os valores das variáveis.
- O número da porta pode ser inserido diretamente, sem necessidade de usar uma variável, por conveniência e sem risco.
❌ Ações Não Recomendadas:
- Usar "Valor Inicial" para os valores das variáveis.
- Misturar texto simples e variáveis, o que ainda exige que todos configurem separadamente nas configurações do projeto.
Usando Variáveis Vault para Salvar Configurações de Conexão com o Banco de Dados
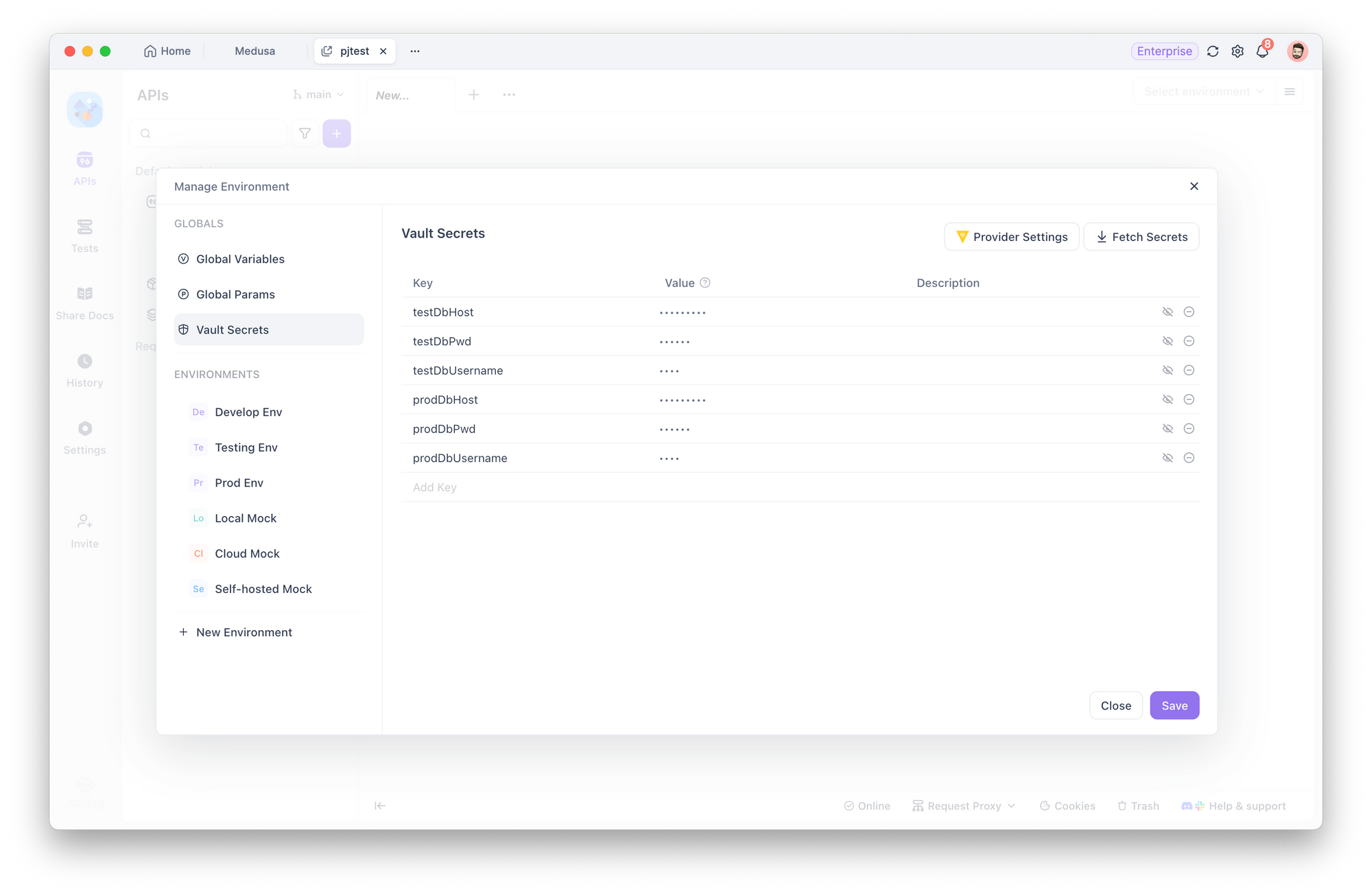
Passo 1: Configurar Variáveis Vault
Configure um provedor Vault e armazene o texto simples das credenciais de conexão com o banco de dados nele. Para configurações de conexão com o banco de dados em diferentes ambientes, você precisa criar diferentes Chaves Vault em seu provedor. Para métodos específicos, consulte a documentação de ajuda.
Passo 2: Criar Variáveis de Ambiente
Para cada ambiente, crie variáveis de ambiente com o mesmo nome — como dbHost. Em seguida, defina o Valor Inicial para referenciar a variável Vault apropriada para esse ambiente, e deixe o Valor Atual seguir o inicial.
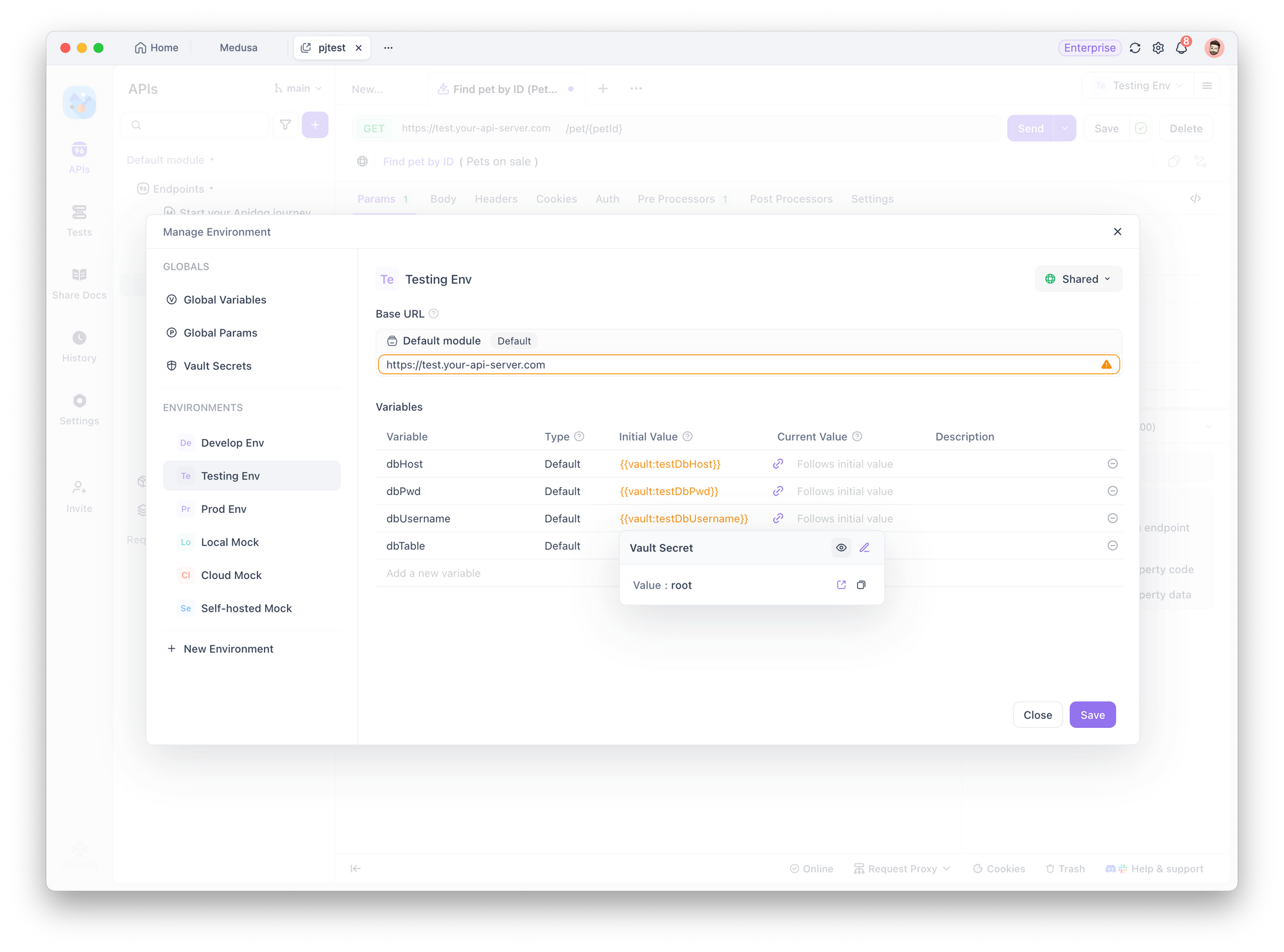
Por que fazer isso?
- Ele envolve a variável Vault em uma variável de ambiente. Assim, quando você configurar a conexão com o banco de dados mais tarde, você só precisará selecionar a variável de ambiente. O Apidog usará automaticamente o valor correto com base no ambiente atual.
- Armazenar os dados em um valor inicial garante que todos os membros do projeto possam usá-los sem ter que configurá-los manualmente novamente — aumentando a eficiência da equipe.
Passo 3: Configurar Conexões com o Banco de Dados Usando o Segredo Vault
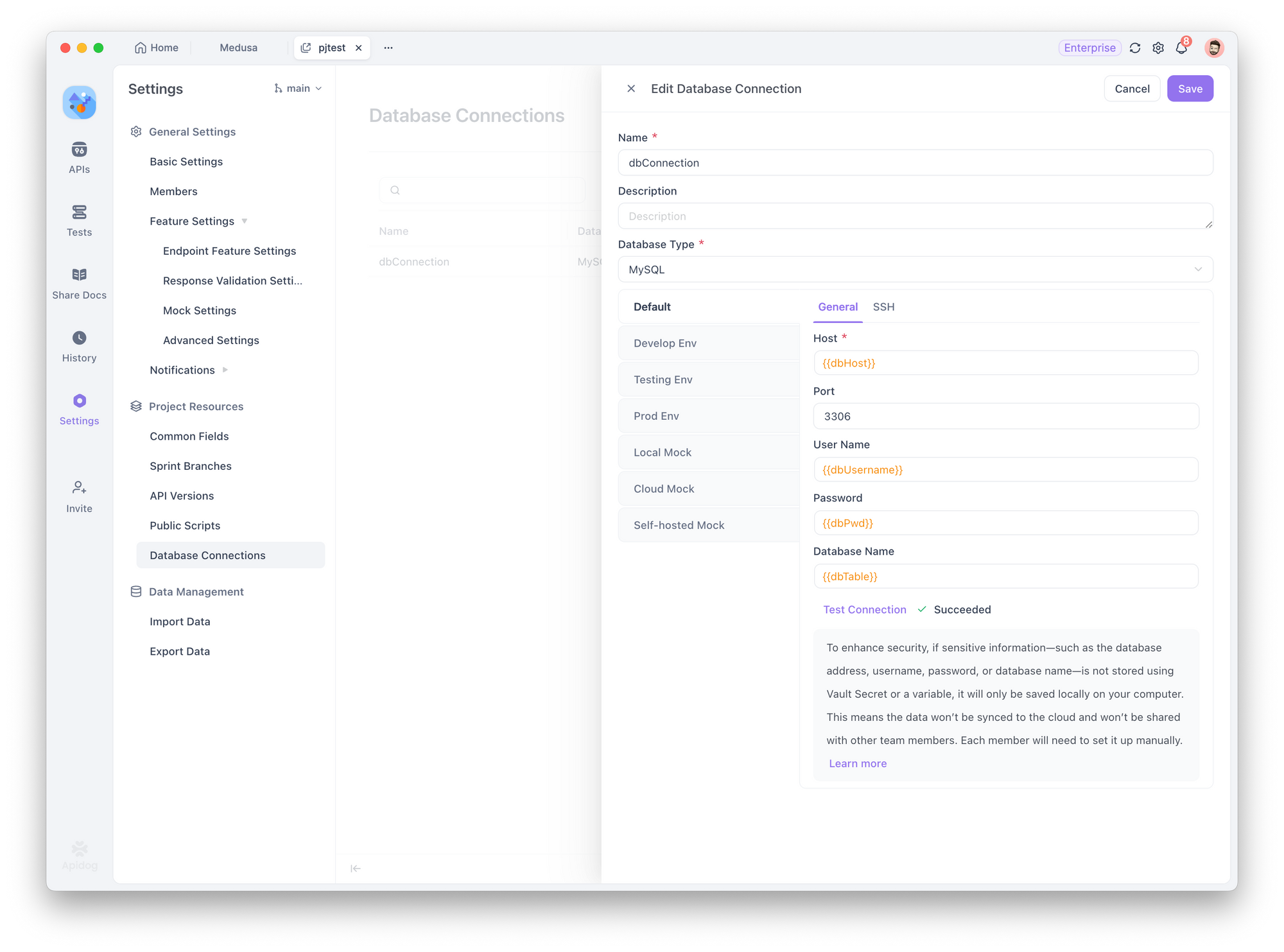
Ao configurar uma conexão com o banco de dados, use as variáveis de ambiente que você definiu em Gerenciamento de Ambiente (por exemplo, dbHost, dbUser, dbPassword). Para referenciar essas variáveis rapidamente, use o recurso de valor dinâmico.
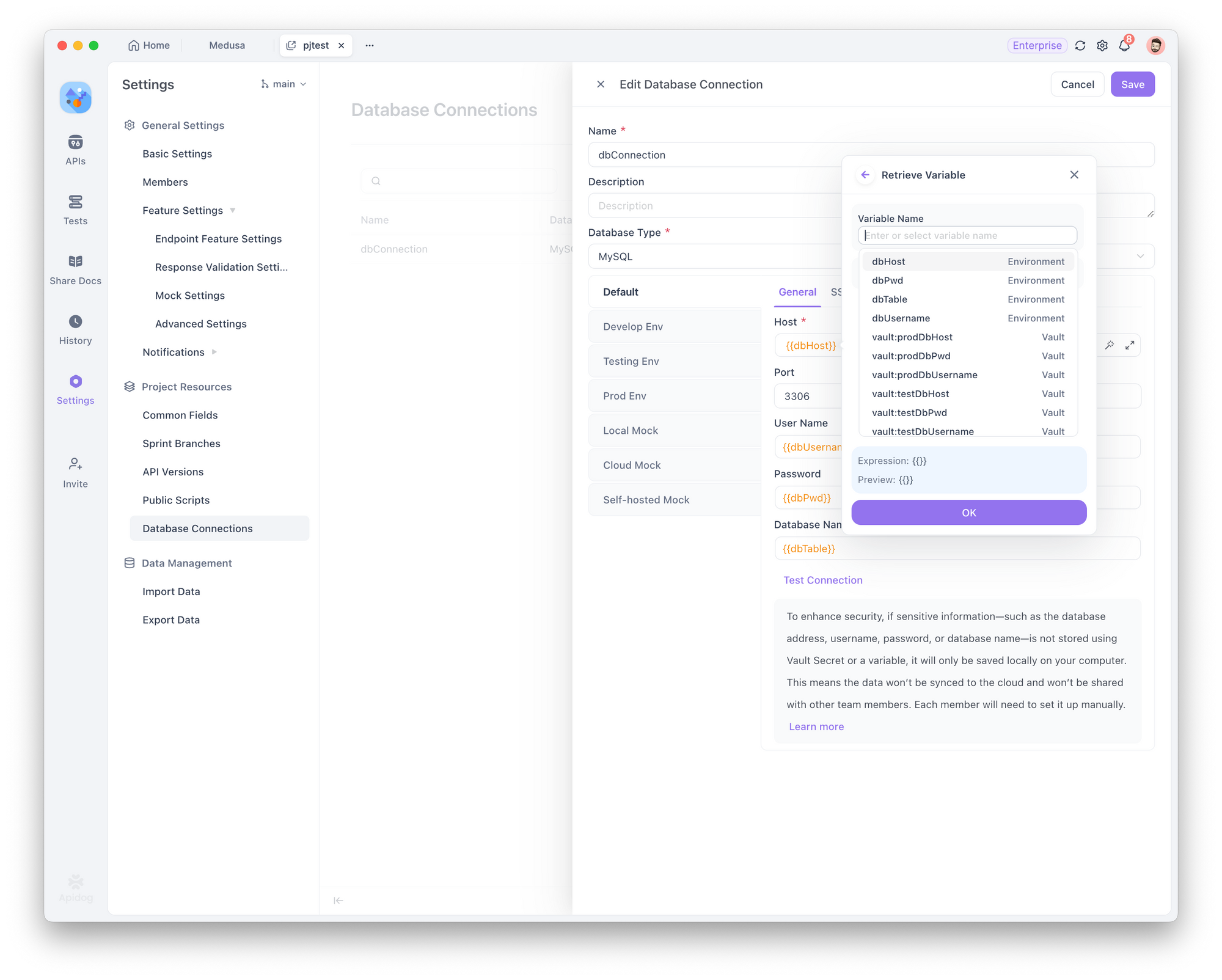
Passo 4: Testar a Conexão com o Banco de Dados
Clique em "Testar Conexão". Você será solicitado a escolher um ambiente para o teste.
Certifique-se de que as variáveis usadas na conexão (como host, porta, nome de usuário, etc.) estejam configuradas corretamente para esse ambiente. Uma vez confirmado, o sistema testará a conexão:
- ✅ Se bem-sucedido, você está pronto para prosseguir.
- ❌ Se falhar, verifique a mensagem de erro para passos específicos de solução de problemas.
Passo 5: Usar Operações de Banco de Dados em Requisições de Endpoint
Nos Pre Processors ou Post Processors de uma requisição de endpoint, você pode adicionar uma operação de banco de dados usando a configuração de banco de dados na nuvem salva.
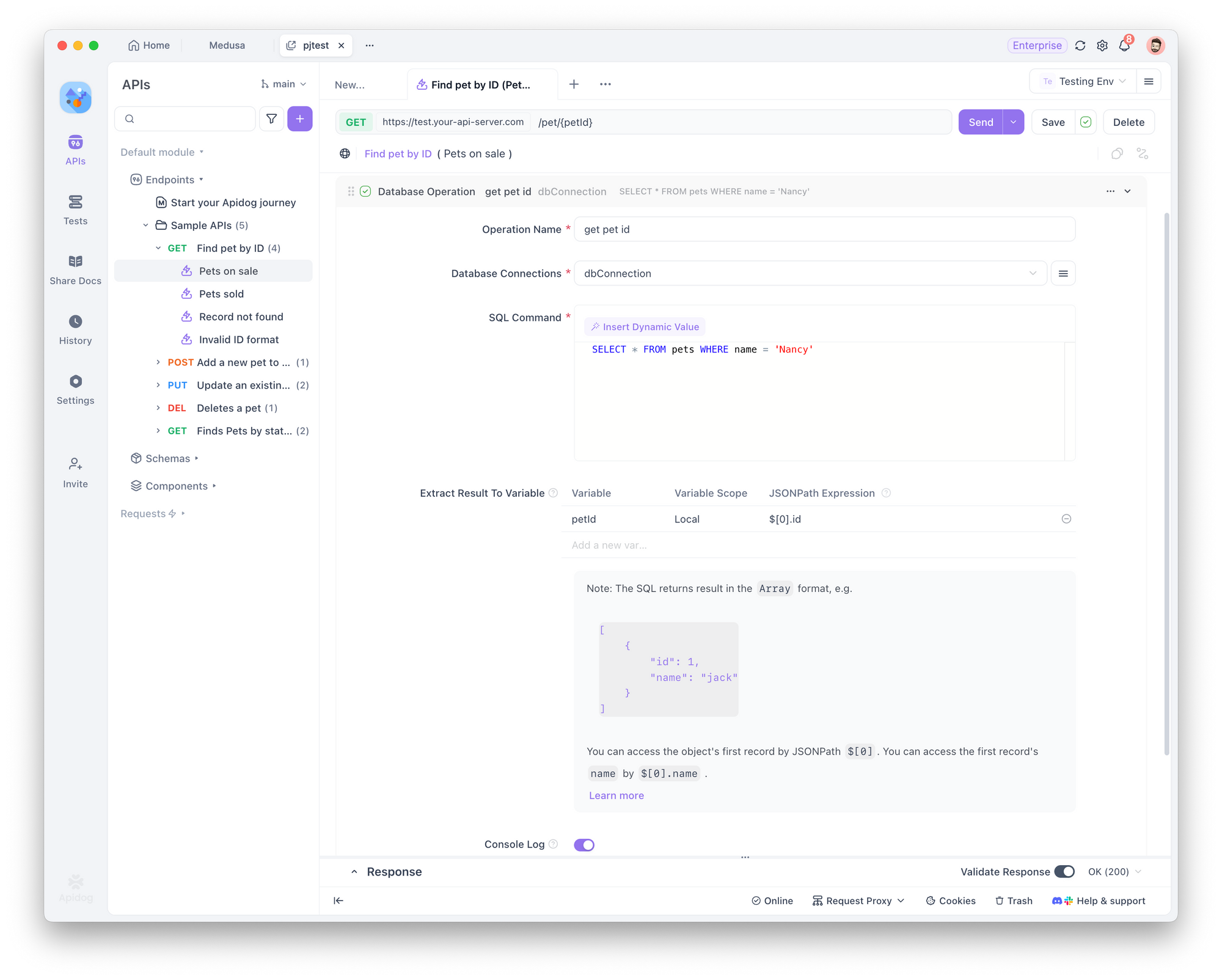
Exemplo:
Digamos que você queira:
- Buscar o
idde um pet chamado "Nancy" no banco de dados. - Usar esse ID para buscar informações detalhadas através de uma requisição de endpoint.
O Apidog então irá:
- Executar a operação de banco de dados
- Buscar o valor (por exemplo,
petID) - Salvá-lo como uma variável (por exemplo,
petId) - Usar essa variável na requisição de endpoint
Uma vez que a configuração do banco de dados é configurada na nuvem conforme descrito acima:
- Outros membros da equipe podem reutilizá-la em suas próprias operações de banco de dados.
- Não há necessidade de cada pessoa configurá-la manualmente.
- Economiza tempo e garante consistência em todo o seu projeto.
Conclusão Final
A prática acima mostra como usar variáveis Vault para armazenar e aplicar com segurança configurações de conexão com o banco de dados. Aqui está um resumo rápido dos passos:
- Crie variáveis Vault separadas para cada configuração de banco de dados em diferentes ambientes (por exemplo,
testDBHostpara teste,prodDBHostpara produção). Você pode pular a porta, pois ela geralmente permanece a mesma. - Defina variáveis de ambiente com o mesmo nome em todos os ambientes. Para cada ambiente, defina o *valor inicial* da variável de ambiente para referenciar sua variável Vault correspondente.
A tabela abaixo ilustra como configurar essas variáveis de ambiente para teste e produção. Você pode definir o *valor atual* para corresponder ao *valor inicial*.
| Ambiente | Nome da Variável de Ambiente | Valor Inicial | Descrição |
| Ambiente de Teste | dbHost | {{vault:testDbHost}} | Referencia a variável Vault para o endereço do banco de dados no ambiente de teste |
| dbUsername | {{vault:testDbUsername}} | Referencia a variável Vault para o nome de usuário do banco de dados no ambiente de teste | |
| dbPwd | {{vault:testDbPwd}} | Referencia a variável Vault para a senha do banco de dados no ambiente de teste | |
| dbTable | store | Sem preocupações com segurança de dados, então é inserido diretamente. Variável Vault é opcional | |
| Ambiente de Produção | dbHost | {{vault:prodDbHost}} | Referencia a variável Vault para o endereço do banco de dados no ambiente de produção |
| dbUsername | {{vault:prodDbUsername}} | Referencia a variável Vault para o nome de usuário do banco de dados no ambiente de produção | |
| dbPwd | {{vault:prodDbPwd}} | Referencia a variável Vault para a senha do banco de dados no ambiente de produção | |
| dbTable | store | Sem preocupações com segurança de dados, então é inserido diretamente. Variável Vault é opcional |