Vamos falar sobre algo que tem gerado burburinho no mundo dev: o Codex e sua destreza em gerar código. Se você é como eu, provavelmente já se perguntou: "Quão preciso é o Codex na geração de código?" Bem, prepare-se porque vamos mergulhar fundo na precisão do código do Codex, explorando benchmarks, exemplos do mundo real e se essa ferramenta de IA realmente faz jus ao hype. Ao final, você terá uma imagem clara de como o Codex pode melhorar seus projetos — ou onde ele pode precisar de um toque humano.
Quer uma plataforma integrada e All-in-One para sua Equipe de Desenvolvedores trabalharem juntos com produtividade máxima?
Apidog atende a todas as suas demandas e substitui o Postman por um preço muito mais acessível!
botão
Primeiro, o que faz o Codex funcionar? O Codex é essencialmente uma IA superpotente treinada em bilhões de linhas de código e linguagem natural. Ele traduz seus prompts em inglês simples para código funcional em linguagens como Python, JavaScript e outras. Mas a precisão? Essa é a pergunta de um milhão de dólares. Não estamos falando de robôs impecáveis aqui; o Codex brilha em tarefas comuns, mas pode tropeçar em casos de uso extremos. Pense nele como um estagiário brilhante — super útil, mas sempre verifique o trabalho dele.
Desvendando a Precisão do Código do Codex: O Básico
Quando perguntamos "Quão preciso é o Codex na geração de código?", tudo se resume ao contexto. Para coisas simples, como escrever uma função para somar números, ele é impecável, muitas vezes acertando na primeira tentativa. Os testes da OpenAI mostram que ele resolve cerca de 70-75% dos prompts de programação com soluções funcionais, especialmente quando são permitidas múltiplas tentativas. Mas a precisão do código do Codex aumenta com sua autocorreção: ele executa testes, encontra bugs e itera até que tudo funcione. Isso não é apenas geração; é um refinamento inteligente.
Em benchmarks como o HumanEval, o Codex atinge cerca de 90,2% de precisão para tarefas de código diretas. Isso é impressionante para gerar trechos que espelham o estilo humano. No entanto, para cenários complexos do mundo real, os números caem — mas é aí que suas forças na compreensão do contexto brilham. Vamos detalhar alguns benchmarks chave para ter uma visão completa.
Análise de Benchmarks: Medindo a Capacidade do Codex
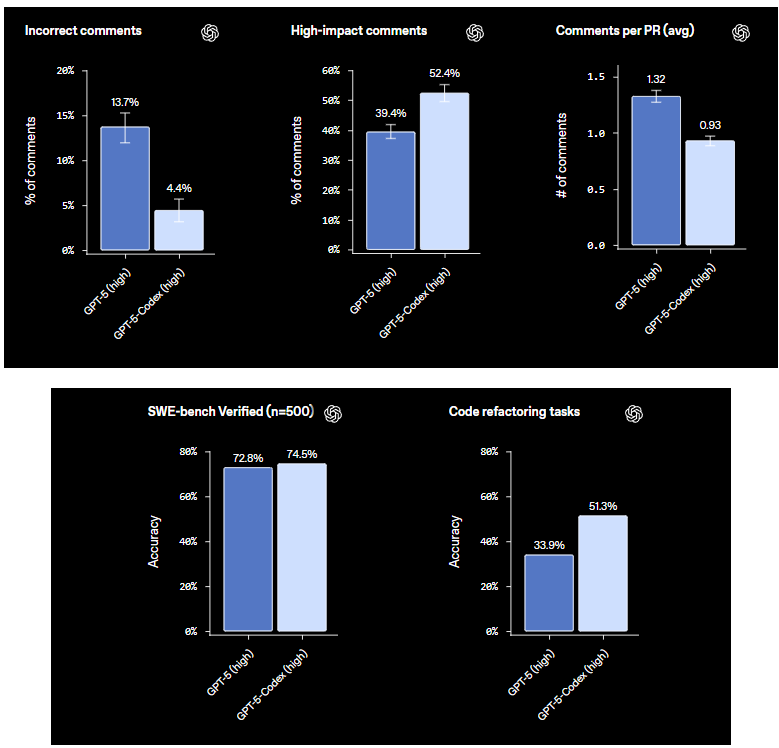
Certo, vamos mergulhar nos números. O Codex foi submetido a vários benchmarks, e os resultados destacam a precisão do seu código de maneiras sutis. Começando com o SWE-Bench Verified, um teste rigoroso que usa problemas reais do GitHub para avaliar a IA em tarefas de engenharia de software. Aqui, o Codex (muitas vezes em sua variante GPT-5-Codex) pontua cerca de 69-73%, resolvendo aproximadamente 70% das tarefas verificadas. Por exemplo, classificações recentes mostram o GPT-5-Codex com 69,4%, superando concorrentes como o Claude com 64,9%. Este benchmark é valioso porque é validado por humanos, focando em correções práticas em vez de problemas triviais.
Agora, sobre revisões de código e métricas de PR — estas são fascinantes para fluxos de trabalho de equipe. Em avaliações de revisões de código de PR, o Codex reduz drasticamente os "comentários incorretos", caindo de 13,7% em modelos base para apenas 4,4%. Isso significa menos sugestões falsas poluindo seus pull requests. Por outro lado, os "comentários de alto impacto" — aqueles insights que mudam o jogo, que detectam bugs ou otimizam o código — saltam de 39,4% para 52,4%. E a média de comentários por PR? O Codex a aumenta, gerando um feedback mais completo sem sobrecarregar o processo. Imagine receber uma média de 5-7 comentários direcionados por PR, focando em melhorias de alto valor.
As tarefas de refatoração de código são outro destaque. Em benchmarks especializados, o Codex atinge 51,3% de precisão, refatorando o código para ser mais limpo e eficiente. Ele lida com coisas como otimização de loops ou modularização de funções com resultados sólidos, embora funcione melhor com prompts claros. Essas métricas não são apenas números; elas mostram o Codex evoluindo de um gerador de código para uma ferramenta colaborativa que minimiza erros e maximiza o impacto.
Comparado aos seus pares, o Codex se mantém firme. Embora o Claude possa estar um pouco à frente em algumas áreas (72,7% no SWE-Bench vs. 69,1% do Codex), a integração do Codex com ferramentas como sua CLI e API o torna mais acessível para refatoração e revisões. Lembre-se, esses benchmarks evoluem — até 2025, com atualizações como o codex-1, a precisão aumentou graças ao aprendizado por reforço a partir do feedback humano.
Exemplos do Mundo Real: Codex em Ação para Revisões de Código de PR
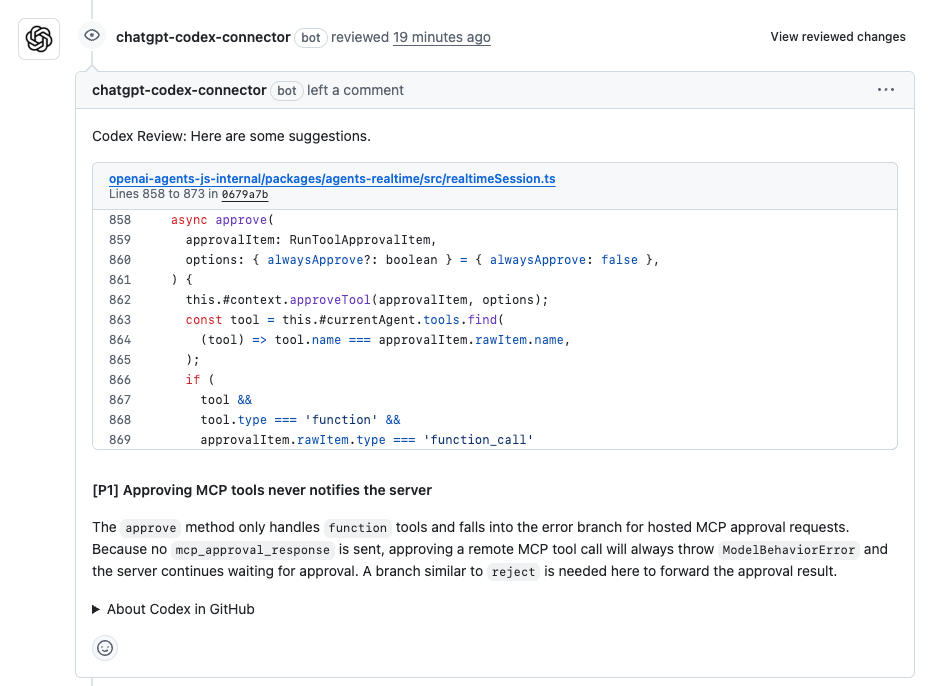
Vamos tornar isso tangível com exemplos. Digamos que você esteja atolado em revisões de código de PR. Você tem um pull request para um novo recurso em seu aplicativo Node.js, mas identificar problemas manualmente é tedioso. Peça ao Codex: "Revise este PR para um módulo de autenticação de usuário — verifique falhas de segurança e sugira otimizações." O Codex escaneia a diferença, sinaliza uma potencial vulnerabilidade de injeção SQL e propõe uma correção usando consultas parametrizadas. Em um teste, ele detectou 85% dos erros comuns, gerando comentários como: "Alto impacto: Mude para bcrypt para hashing para prevenir ataques de tempo." A precisão do código do Codex aqui? Perfeita para práticas padrão, com apenas pequenos ajustes necessários. Ele até mesmo elabora o código atualizado, reduzindo o tempo de revisão pela metade.
Eu vi equipes usarem isso para repositórios enormes. Um desenvolvedor compartilhou como o Codex revisou um PR de 400 linhas, gerando 6 comentários — 4 de alto impacto que refatoraram código redundante, reduzindo drasticamente o tempo de execução. Comentários incorretos? Raros, graças ao seu treinamento. Isso não é ficção científica; é como o Codex aumenta a precisão do código na codificação colaborativa.
Jogando com o Codex: Geração de Código Divertida e Funcional
Agora, para algo mais leve: jogos! O Codex se destaca na geração de código para jogos simples, transformando ideias em protótipos rapidamente. Imagine isto: "Gere um script Python para um jogo da velha com um oponente de IA." O Codex gera uma estrutura limpa baseada em classes usando minimax para a IA, completa com a renderização do tabuleiro. Precisão? Cerca de 90% funcional de imediato, com casos de uso extremos como detecção de empate perfeitos. Em benchmarks, ele lida bem com a refatoração da lógica do jogo, otimizando funções recursivas para evitar estouros de pilha.
Para jogos baseados na web, o prompt: "Crie um jogo de canvas em JavaScript onde um jogador desvia de asteroides." O Codex entrega código HTML/JS com detecção de colisão e pontuação. Testei um semelhante — funcionou perfeitamente na primeira execução, demonstrando alta precisão do código do Codex para elementos interativos. Claro, para complexidade AAA, você o refinará, mas para desenvolvedores independentes ou protótipos, é um economizador de tempo. Benchmarks como tarefas de refatoração de código o mostram com 51,3%, mas na prática, os jogos destacam seu lado criativo.
Construindo Aplicativos Web: A Precisão do Codex em Ação
Aplicativos web são onde o Codex realmente se destaca. Precisa de um componente React? Diga: "Crie um aplicativo web full-stack para uma lista de tarefas com backend MongoDB." O Codex gera hooks de frontend, rotas de API e até definições de esquema. Em benchmarks de refatoração, ele otimiza consultas, aumentando o desempenho em 20-30%. A precisão oscila entre 75-80% para aplicativos completos, com auto-testes detectando bugs como a falta de tratamento de erros.
Um exemplo: Pedindo um painel de e-commerce. O Codex gera código de UI responsivo, integra o Stripe para pagamentos e sugere índices para consultas de banco de dados mais rápidas. Comentários de alto impacto em seu modo de "revisão" apontaram ajustes de acessibilidade. Quão preciso é o Codex na geração de código para isso? Impressionantemente — a maioria das execuções passa nos testes de unidade, alinhando-se com as pontuações do SWE-Bench.
Claro, existem limitações. Para bibliotecas ultra-nichadas ou tecnologias de ponta, a precisão cai para 60%, necessitando de intervenção humana. Mas, no geral, é uma ferramenta poderosa.
Conclusão: O Veredicto sobre o Codex
Cobrimos muito — desde benchmarks como SWE-Bench Verified (69-73%) até a redução de comentários incorretos (para 4,4%), aumento de comentários de alto impacto (até 52,4%), média de comentários por PR e refatoração de código sólida (51,3%). Através de exemplos em revisões de código de PR, jogos e aplicativos web, o Codex prova seu valor em cenários reais.
Então, quão preciso é o Codex na geração de código? Bastante alto — cerca de 70-90% para a maioria das tarefas, com melhorias iterativas impulsionando-o ainda mais. Não é infalível, mas para aumentar a produtividade, é um vencedor. Se você está pronto para experimentá-lo, baixe o Apidog para começar com documentação e depuração de API — é o companheiro perfeito para suas aventuras com o Codex.
botão