
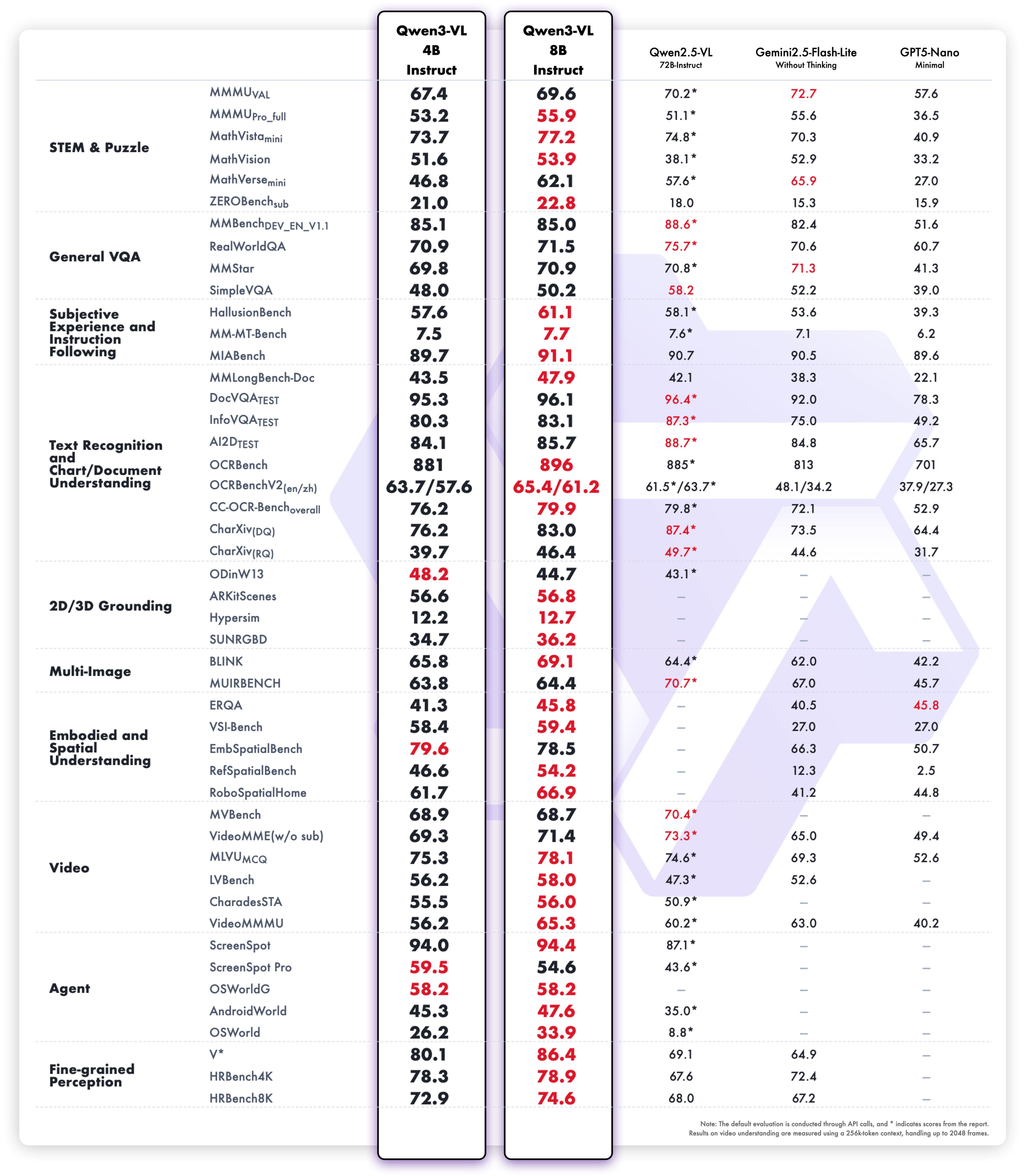
A família Qwen 3 domina o cenário de LLMs de código aberto em 2025. Engenheiros implantam esses modelos em todos os lugares — desde agentes empresariais de missão crítica até assistentes móveis. Antes de começar a enviar solicitações para o Alibaba Cloud ou a hospedar você mesmo, otimize seu fluxo de trabalho com o Apidog.
Visão Geral do Qwen 3: Inovações Arquitetônicas Impulsionando o Desempenho em 2025
A equipe Qwen da Alibaba lançou a série Qwen 3 em 29 de abril de 2025, marcando um avanço fundamental em modelos de linguagem grandes de código aberto (LLMs). Os desenvolvedores elogiam sua licença Apache 2.0, que permite ajuste fino e implantação comercial irrestritos. Em sua essência, o Qwen 3 emprega uma arquitetura baseada em Transformer com aprimoramentos em embeddings posicionais e mecanismos de atenção, suportando comprimentos de contexto de até 128K tokens nativamente — e extensíveis para 131K via YaRN.

Além disso, a série incorpora designs de Mixture-of-Experts (MoE) em variantes selecionadas, ativando apenas uma fração dos parâmetros durante a inferência. Essa abordagem reduz a sobrecarga computacional enquanto mantém alta fidelidade nas saídas. Por exemplo, engenheiros relatam um throughput até 10 vezes mais rápido em tarefas de longo contexto em comparação com predecessores densos como o Qwen2.5-72B. Como resultado, as variantes do Qwen 3 escalam eficientemente em hardware, desde dispositivos de borda até clusters de nuvem.
O Qwen 3 também se destaca no suporte multilíngue, lidando com mais de 119 idiomas com um seguimento de instruções diferenciado. Benchmarks confirmam sua vantagem em domínios STEM, onde ele processa dados sintéticos de matemática e código refinados a partir de 36 trilhões de tokens. Portanto, as aplicações em empresas globais se beneficiam de erros de tradução reduzidos e raciocínio interlinguístico aprimorado. Transicionando para os detalhes, o modo de raciocínio híbrido — alternado via sinalizadores de tokenizador — permite que os modelos usem lógica passo a passo para matemática ou codificação, ou padrão para "não-pensamento" para diálogo. Essa dualidade capacita os desenvolvedores a otimizar por caso de uso.
Principais Recursos que Unificam as Variantes do Qwen 3
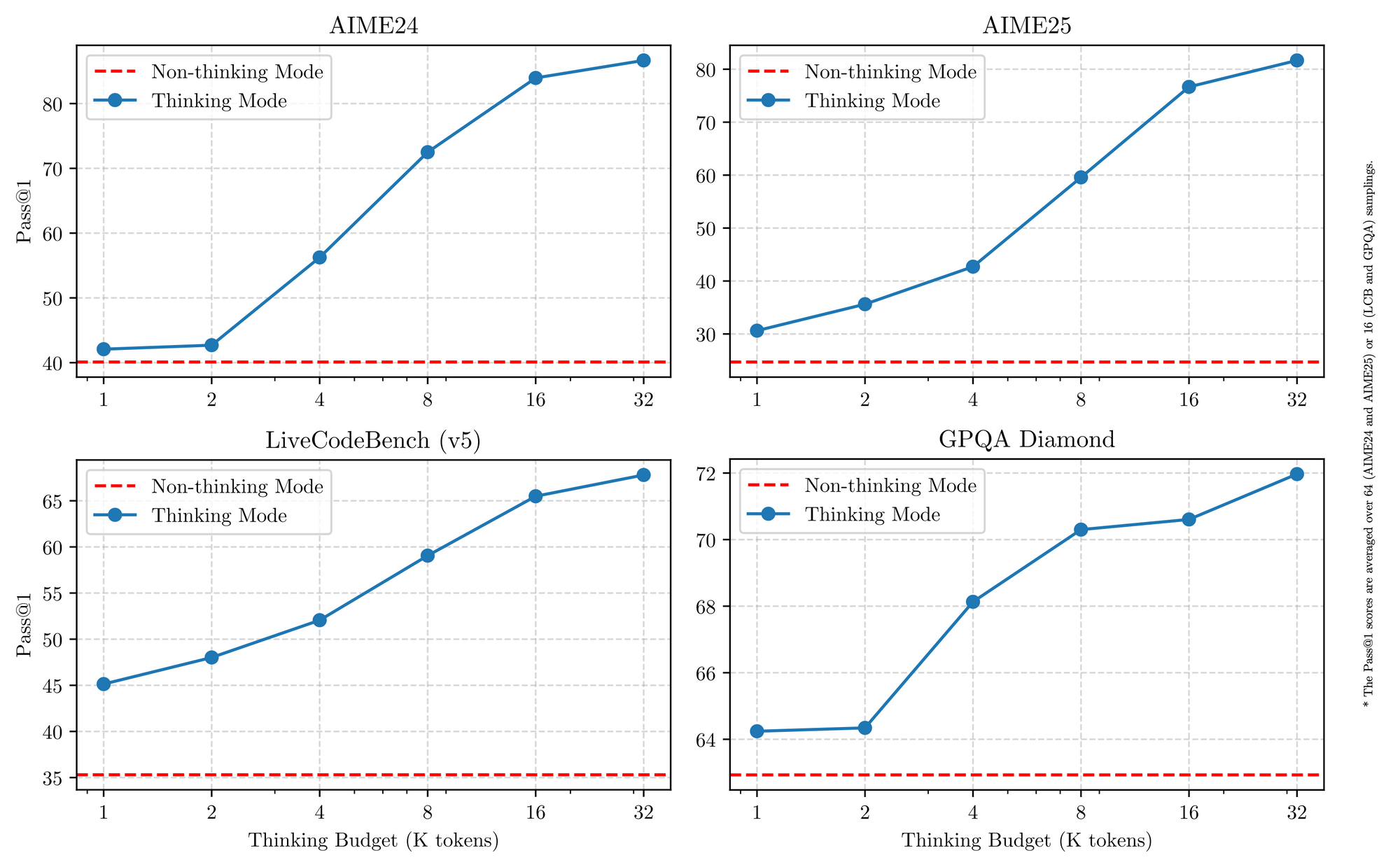
Todos os modelos Qwen 3 compartilham características fundamentais que elevam sua utilidade em 2025. Primeiro, eles suportam operação de modo duplo: o modo de pensamento ativa processos de cadeia de pensamento para benchmarks como AIME25, enquanto o modo de "não-pensamento" prioriza a velocidade para aplicações de chat. Engenheiros alternam isso com parâmetros simples, alcançando até 92,3% de precisão em matemática complexa sem sacrificar a latência.
Em segundo lugar, os recursos agentic permitem a chamada de ferramentas sem interrupções, superando os pares de código aberto em tarefas como navegação em navegador ou execução de código. Por exemplo, as variantes do Qwen 3 obtêm 69,6 no Tau2-Bench Verified, rivalizando com modelos proprietários. Além disso, a proficiência multilíngue abrange dialetos do Mandarim ao Suaíli, com 73,0 em benchmarks MultiIF.
Terceiro, a eficiência provém de variantes quantizadas (por exemplo, Q4_K_M) e frameworks como vLLM ou SGLang, que entregam 25 tokens/segundo em GPUs de consumidor. No entanto, modelos maiores exigem 16GB+ de VRAM, incentivando implantações na nuvem. Os preços permanecem competitivos, com tokens de entrada a US$ 0,20–US$ 1,20 por milhão via Alibaba Cloud.
Além disso, o Qwen 3 enfatiza a segurança por meio de moderação integrada, reduzindo as alucinações em 15% em relação ao Qwen2.5. Os desenvolvedores aproveitam isso para aplicativos de nível de produção, desde recomendadores de e-commerce até analisadores jurídicos. À medida que mudamos para variantes individuais, essas forças compartilhadas fornecem uma base consistente para comparação.
As 5 Melhores Variantes do Modelo Qwen 3 em 2025
Com base nos benchmarks de 2025 da LMSYS Arena, LiveCodeBench e SWE-Bench, classificamos as cinco principais variantes do Qwen 3. Os critérios de seleção incluem pontuações de raciocínio, velocidade de inferência, eficiência de parâmetros e acessibilidade de API. Cada uma se destaca em cenários distintos, mas todas avançam as fronteiras do código aberto.
1. Qwen3-235B-A22B – O Monstro MoE Absoluto Carro-Chefe
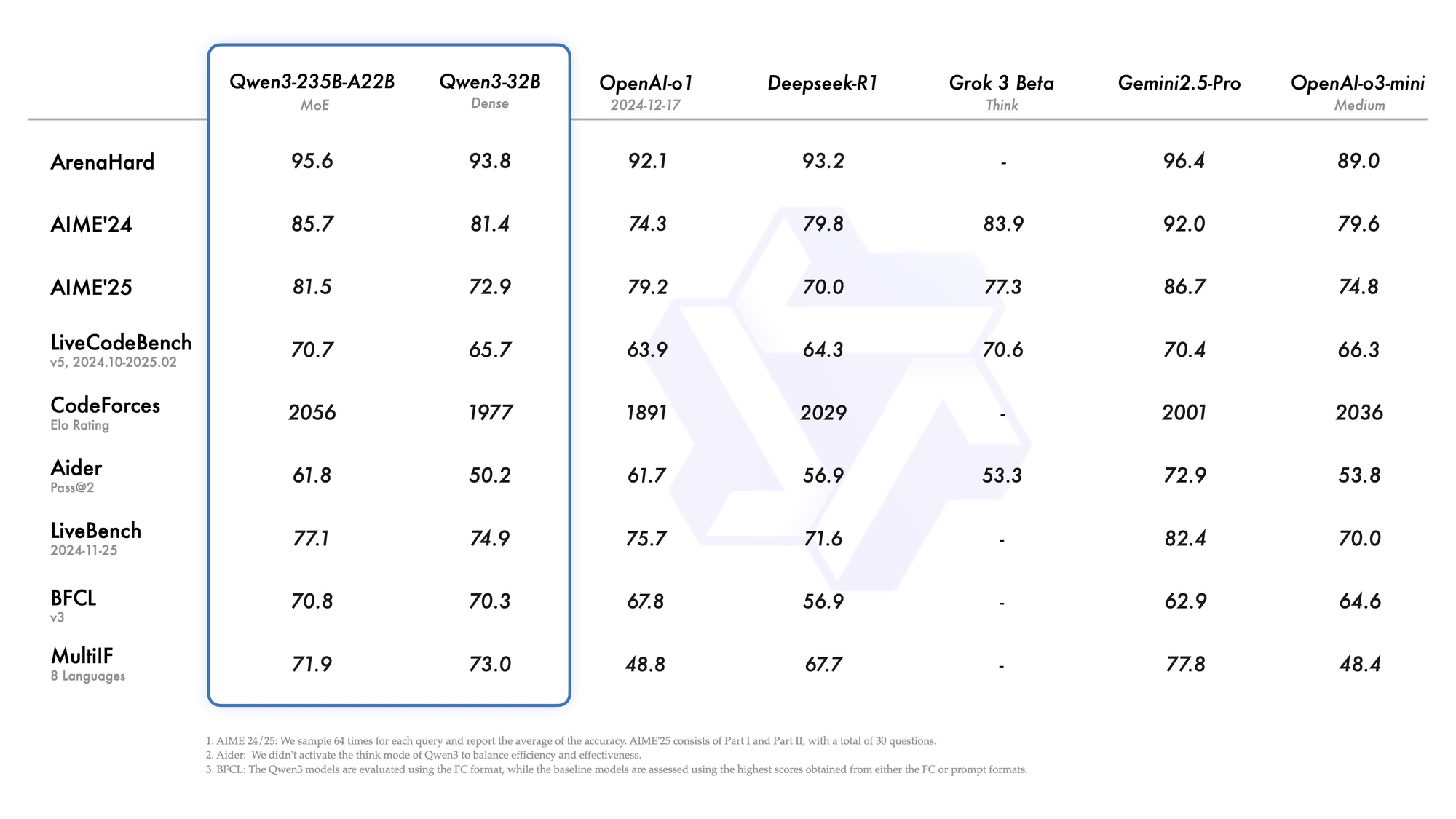
Qwen3-235B-A22B chama a atenção como a principal variante MoE, com 235 bilhões de parâmetros totais e 22 bilhões ativos por token. Lançado em julho de 2025 como Qwen3-235B-A22B-Instruct-2507, ele ativa oito especialistas via roteamento top-k, reduzindo o cálculo em 90% em comparação com equivalentes densos. Os benchmarks o posicionam lado a lado com o Gemini 2.5 Pro: 95,6 no ArenaHard, 77,1 no LiveBench e liderança no CodeForces Elo (liderando em 5%).
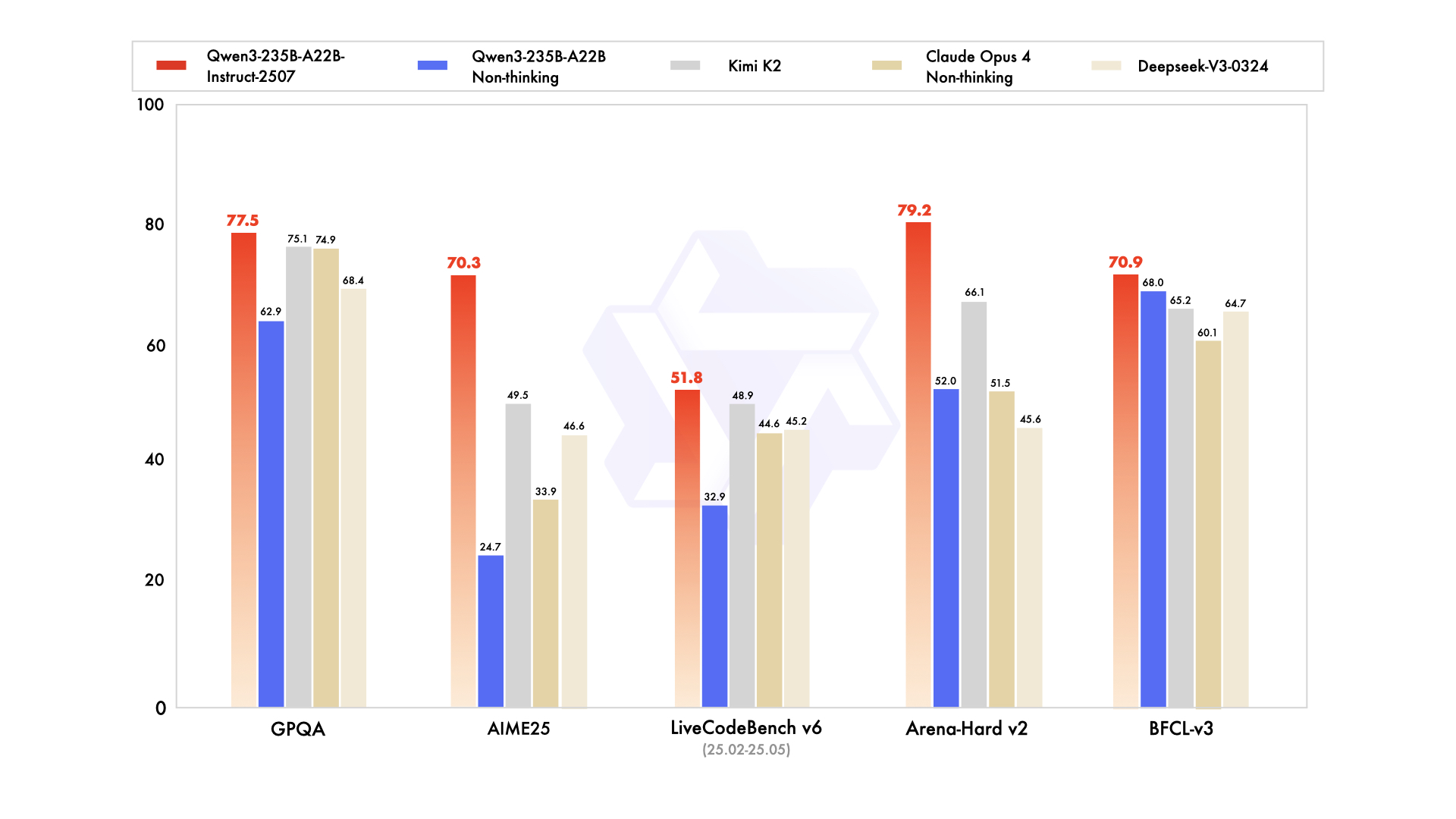
Em codificação, ele atinge 74,8 no LiveCodeBench v6, gerando TypeScript funcional com iterações mínimas. Para matemática, o modo de pensamento rende 92,3 no AIME25, resolvendo integrais multi-etapas via dedução explícita. Tarefas multilíngues veem 73,0 no MultiIF, processando consultas em árabe sem falhas.
A implantação favorece APIs na nuvem, onde ele lida com 256K contextos. No entanto, execuções locais exigem 8 GPUs H100. Engenheiros o integram para fluxos de trabalho agentic, como depuração em escala de repositório. No geral, essa variante estabelece o padrão de 2025 para profundidade, embora sua escala seja adequada para equipes com alto orçamento.
Pontos Fortes
- Iguala ou supera Gemini 2.5 Pro e Claude 3.7 Sonnet em quase todas as tabelas de classificação de 2025 (95,6 ArenaHard, 92,3 AIME25 em modo de pensamento, 74,8 LiveCodeBench v6).
- Destaca-se em fluxos de trabalho agentic multi-turno, chamada de ferramenta complexa e compreensão de código em nível de repositório.
- Lida com contexto de 256K a 1M com YaRN sem queda de qualidade.
- O modo de pensamento oferece raciocínio verificável de "cadeia de pensamento" que rivaliza com modelos de fronteira de código fechado.
Pontos Fracos
- Extremamente caro e lento localmente — requer 8×H100 ou equivalente para latência razoável.
- O preço da API é o mais alto da família (US$ 1,20–US$ 6,00/M tokens de saída em contexto de pico).
- Exagerado para 95% das cargas de trabalho de produção; a maioria das equipes nunca satura sua capacidade.
Quando Usar
- Agentes autônomos de nível empresarial que devem resolver matemática de nível de doutorado, depurar bases de código inteiras ou realizar análise de contratos legais com quase zero alucinação.
- Laboratórios de pesquisa de alto orçamento que buscam o estado da arte em novos benchmarks.
- Backends de raciocínio internos onde o custo por token é secundário à inteligência máxima.
2. Qwen3-30B-A3B – O Campeão MoE de Ponto Ideal
Qwen3-30B-A3B surge como a escolha ideal para configurações com recursos limitados, apresentando 30,5 bilhões de parâmetros totais e 3,3 bilhões ativos. Sua estrutura MoE — 48 camadas, 128 especialistas (oito roteados) — espelha o carro-chefe, mas com 10% da pegada. Atualizado em julho de 2025, ele supera o QwQ-32B em 10 vezes em eficiência ativa, pontuando 91,0 no ArenaHard e 69,6 no SWE-Bench Verified.
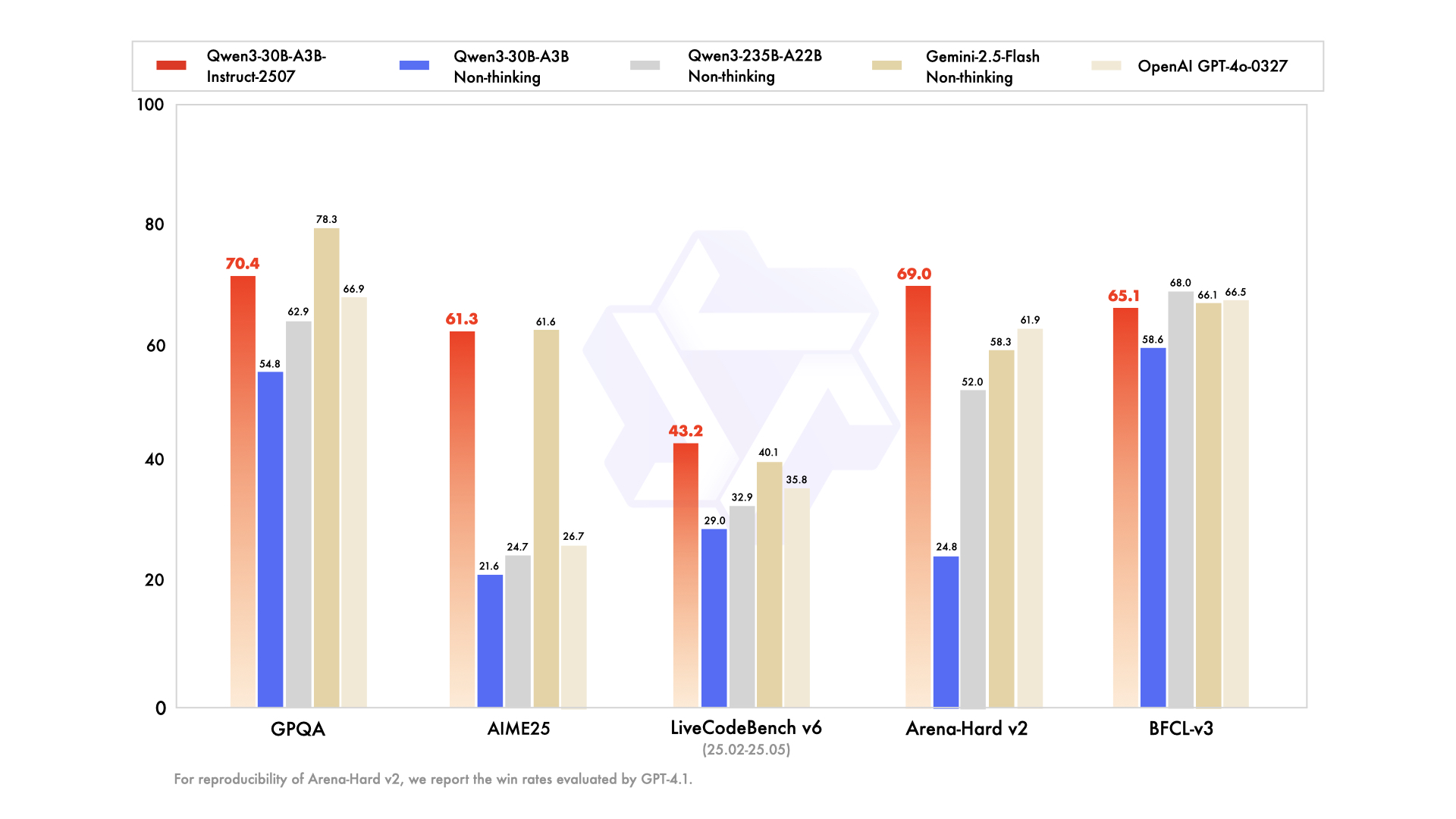
Avaliações de codificação destacam sua proeza: 32,4% de pass@5 em PRs recentes do GitHub, igualando o GPT-5-High. Benchmarks de matemática mostram 81,6 no AIME25 em modo de pensamento, rivalizando com irmãos maiores. Com 131K de contexto via YaRN, ele processa documentos longos sem truncamento.
Pontos Fortes
- Parâmetros ativos 10 vezes mais baratos que o 235B, mantendo ~90–95% da qualidade de raciocínio do carro-chefe (91,0 ArenaHard, 81,6 AIME25).
- Funciona confortavelmente em uma única A100 de 80GB ou duas placas de 40GB com vLLM + FlashAttention.
- Melhor relação preço-desempenho entre todos os modelos MoE abertos de 2025.
- Supera todos os modelos densos de 72B–110B em codificação e matemática.
Pontos Fracos
- Ainda precisa de ~24–30GB de VRAM em FP8/INT4; não é adequado para laptops.
- Fluência de escrita criativa ligeiramente inferior à de modelos densos puros de tamanho semelhante.
- A latência do modo de pensamento salta 2 a 3 vezes em comparação com o modo de "não-pensamento".
Quando Usar
- Agentes de codificação de produção, revisões automáticas de PRs ou copilotos DevOps internos.
- Pipelines de pesquisa de alto throughput que precisam de raciocínio matemático ou científico de nível de fronteira com um orçamento razoável.
- Qualquer equipe que usava anteriormente Llama-405B ou Mixtral-123B, mas deseja melhor raciocínio a um custo menor.
3. Qwen3-32B – O Rei Todo-Poderoso Denso
O Qwen3-32B denso entrega 32 bilhões de parâmetros totalmente ativos, enfatizando o throughput bruto em detrimento da esparsidade. Treinado em 36T tokens, ele iguala o Qwen2.5-72B em desempenho base, mas se destaca no alinhamento pós-treinamento. Os benchmarks revelam 89,5 no ArenaHard e 73,0 no MultiIF, com forte escrita criativa (por exemplo, narrativas de role-playing pontuando 85% de preferência humana).
Em codificação, ele lidera o BFCL com 68,2, gerando UIs de arrastar e soltar a partir de prompts. A matemática rende 70,3 no AIME25, embora fique atrás dos pares MoE em "cadeia de pensamento". Seu contexto de 128K é adequado para bases de conhecimento, e o modo de "não-pensamento" aumenta a velocidade do diálogo para 20 tokens/segundo.
Pontos Fortes
- Seguimento de instruções excepcional e saída criativa — muitas vezes preferido em detrimento de modelos MoE maiores em avaliações humanas cegas para escrita e role-play.
- Fácil de ajustar com LoRA/QLoRA em hardware de consumidor (16–24GB de VRAM).
- Inferência mais rápida entre os modelos que ainda superam o GPT-4o em muitas tarefas (89,5 ArenaHard).
- Desempenho multilíngue muito forte em mais de 119 idiomas.
Pontos Fracos
- Fica ~8–12 pontos atrás dos irmãos MoE nos benchmarks mais difíceis de matemática e codificação quando o modo de pensamento está ativado.
- Sem truques de eficiência de parâmetros — cada token custa o cálculo total de 32B.
Quando Usar
- Plataformas de geração de conteúdo, assistentes de escrita de romances, ferramentas de redação de marketing.
- Projetos que exigem ajuste fino pesado (chatbots específicos de domínio, transferência de estilo).
- Equipes que desejam qualidade quase de carro-chefe, mas devem permanecer abaixo de 24GB de VRAM.
4. Qwen3-14B – Potência de Borda e Móvel
Qwen3-14B prioriza a portabilidade com 14,8 bilhões de parâmetros, suportando 128K contextos em hardware de médio porte. Ele rivaliza com o Qwen2.5-32B em eficiência, pontuando 85,5 no ArenaHard e trocando golpes com o Qwen3-30B-A3B em matemática/codificação (dentro de uma margem de 5%). Quantizado para Q4_0, ele roda a 24,5 tokens/segundo em dispositivos móveis como o RedMagic 8S Pro.
Tarefas agentic veem 65,1 no Tau2-Bench, permitindo o uso de ferramentas em aplicativos de baixa latência. O suporte multilíngue brilha, com 70% de precisão na inferência dialetal. Para dispositivos de borda, ele processa 32K contextos offline, ideal para análises de IoT.
Engenheiros valorizam sua pegada para aprendizado federado, onde a privacidade supera a escala. Portanto, ele se encaixa em assistentes de IA móveis ou sistemas embarcados.
Pontos Fortes
- Roda a 24–30 tokens/segundo mesmo em telefones modernos (Snapdragon 8 Gen 4, Dimensity 9400) quando quantizado para Q4_K_M.
- Ainda supera Qwen2.5-32B e Llama-3.1-70B na maioria dos benchmarks de raciocínio.
- Excelente para RAG no dispositivo com contexto de 32K–128K.
- Custo de API mais baixo na faixa de desempenho de alto nível.
Pontos Fracos
- Começa a ter dificuldade com tarefas agentic multi-etapas que exigem mais de 5 chamadas de ferramenta.
- Qualidade de escrita criativa notavelmente inferior a modelos 32B+.
- Menos à prova de futuro, pois os benchmarks continuam subindo.
Quando Usar
- Assistentes no dispositivo (aplicativos Android/iOS, vestíveis).
- Implantações sensíveis à privacidade (saúde, finanças) onde os dados não podem sair do dispositivo.
- Sistemas embarcados em tempo real (robôs, carros, gateways IoT).
5. Qwen3-8B – O Cavalo de Batalha Leve e Definitivo para Prototipagem
Completando os cinco primeiros, o Qwen3-8B oferece 8 bilhões de parâmetros para iteração rápida, superando o Qwen2.5-14B em 15 benchmarks. Ele atinge 81,5 no AIME25 (não-pensamento) e 60,2 no LiveCodeBench, suficiente para revisões básicas de código. Com 32K de contexto nativo, ele é implantado em laptops via Ollama, atingindo 25 tokens/segundo.
Esta variante é adequada para iniciantes que testam chat multilíngue ou agentes simples. Seu modo de pensamento aprimora quebra-cabeças lógicos, pontuando 75% em tarefas de dedução. Como resultado, ele acelera provas de conceito antes de escalar para irmãos maiores.
Pontos Fortes
- Roda a >25 tokens/segundo mesmo em laptops com 8–12GB de VRAM (MacBook M3 Pro, RTX 4070 mobile).
- Seguimento de instruções surpreendentemente competente — supera Gemma-2-27B e Phi-4-14B na maioria das tabelas de classificação de 2025.
- Perfeito para experimentação local com Ollama ou LM Studio.
- Preço de API mais barato da família.
Pontos Fracos
- Teto de raciocínio óbvio em matemática de nível de pós-graduação e problemas de codificação avançados.
- Mais propenso a alucinações em tarefas intensivas em conhecimento.
- Contexto limitado (32K nativo, 128K com YaRN, mas mais lento).
Quando Usar
- Prototipagem rápida e construção de MVPs.
- Ferramentas educacionais, assistentes pessoais ou projetos de hobby.
- Camada de roteamento frontend em sistemas híbridos (use 8B para triagem, escale para 30B/235B quando necessário).
Preços da API e Considerações de Implantação para Modelos Qwen 3
O acesso ao Qwen 3 via APIs democratiza a IA avançada, com o Alibaba Cloud liderando com taxas competitivas. Níveis de preço por tokens: para Qwen3-235B-A22B, os custos de entrada são de US$ 0,20–US$ 1,20/milhão (faixa de 0–252K), saída de US$ 1,00–US$ 6,00/milhão. O Qwen3-30B-A3B reflete isso a 80% da taxa, enquanto modelos densos como o Qwen3-32B caem para US$ 0,15 de entrada/US$ 0,75 de saída.
Provedores terceirizados como Together AI oferecem Qwen3-32B a US$ 0,80/1M de tokens totais, com descontos por volume. Acertos de cache reduzem as contas: implícitos em 20%, explícitos em 10%. Comparado ao GPT-5 (US$ 3–15/1M), o Qwen 3 é 70% mais barato, permitindo uma escalabilidade econômica.
Dicas de implantação: Use vLLM para agrupamento, SGLang para compatibilidade com OpenAI. O Apidog aprimora isso simulando endpoints Qwen, testando payloads e gerando documentos — crucial para pipelines de CI/CD. Execuções locais via Ollama são adequadas para prototipagem, mas as APIs se destacam para produção.
Recursos de segurança como limitação de taxa e moderação adicionam valor, sem taxas extras. Portanto, equipes com orçamento limitado selecionam com base no volume de tokens: variantes pequenas para desenvolvimento, carros-chefe para inferência.
Tabela de Decisão – Escolha Seu Modelo Qwen 3 em 2025
| Posição | Modelo | Parâmetros (Total/Ativos) | Resumo dos Pontos Fortes | Principais Pontos Fracos | Melhor Para | Custo Aprox. da API (Entrada/Saída por 1M tokens) | VRAM Mínima (quantizada) |
|---|---|---|---|---|---|---|---|
| 1 | Qwen3-235B-A22B | 235B / 22B MoE | Raciocínio máximo, agentic, matemática, código | Extremamente caro e pesado | Pesquisa de fronteira, agentes empresariais, precisão com tolerância zero | $0.20–$1.20 / $1.00–$6.00 | 64GB+ (nuvem) |
| 2 | Qwen3-30B-A3B | 30.5B / 3.3B MoE | Melhor custo-benefício, raciocínio forte | Ainda precisa de GPU de servidor | Agentes de codificação de produção, backends de matemática/ciência, inferência de alto volume | $0.16–$0.96 / $0.80–$4.80 | 24–30GB |
| 3 | Qwen3-32B | 32B Dense | Escrita criativa, fácil ajuste fino, velocidade | Fica atrás do MoE nas tarefas mais difíceis | Plataformas de conteúdo, ajuste fino de domínio, chatbots multilíngues | $0.15 / $0.75 | 16–20GB |
| 4 | Qwen3-14B | 14.8B Dense | Capacidade de borda/móvel, excelente RAG no dispositivo | Habilidade de agente multi-etapas limitada | IA no dispositivo, aplicativos críticos de privacidade, sistemas embarcados | $0.12 / $0.60 | 8–12GB |
| 5 | Qwen3-8B | 8B Dense | Velocidade em laptop/celular, mais barato | Teto óbvio em tarefas complexas | Prototipagem, assistentes pessoais, camada de roteamento em sistemas híbridos | $0.10 / $0.50 | 4–8GB |
Recomendação Final para 2025
A maioria das equipes em 2025 deve optar pelo Qwen3-30B-A3B — ele entrega mais de 90% do poder do carro-chefe por uma fração do custo e dos requisitos de hardware. Somente passe para o 235B-A22B se você realmente precisar dos últimos 5 a 10% de qualidade de raciocínio e tiver o orçamento. Mude para o 32B denso para cargas de trabalho criativas ou de ajuste fino pesado, e use o 14B/8B quando a latência, privacidade ou restrições de dispositivo dominarem.
Qualquer que seja a variante que você escolher, o Apidog economizará horas de depuração de API. Baixe-o gratuitamente hoje e comece a construir com o Qwen 3 com confiança.