
ElevenLabs는 텍스트를 자연스러운 음성으로 변환하며, 다양한 음성, 언어, 스타일을 지원합니다. 이 API를 사용하면 음성을 앱에 쉽게 내장하거나, 내레이션 파이프라인을 자동화하거나, 음성 에이전트와 같은 실시간 경험을 구축할 수 있습니다. HTTP 요청을 보낼 수 있다면 몇 초 만에 오디오를 생성할 수 있습니다.
ElevenLabs API란 무엇인가요?
ElevenLabs API는 오디오를 생성, 변환 및 분석하는 AI 모델에 대한 프로그래밍 방식의 접근을 제공합니다. 이 플랫폼은 텍스트 음성 변환 서비스로 시작했지만, 전체 오디오 AI 스위트로 확장되었습니다.
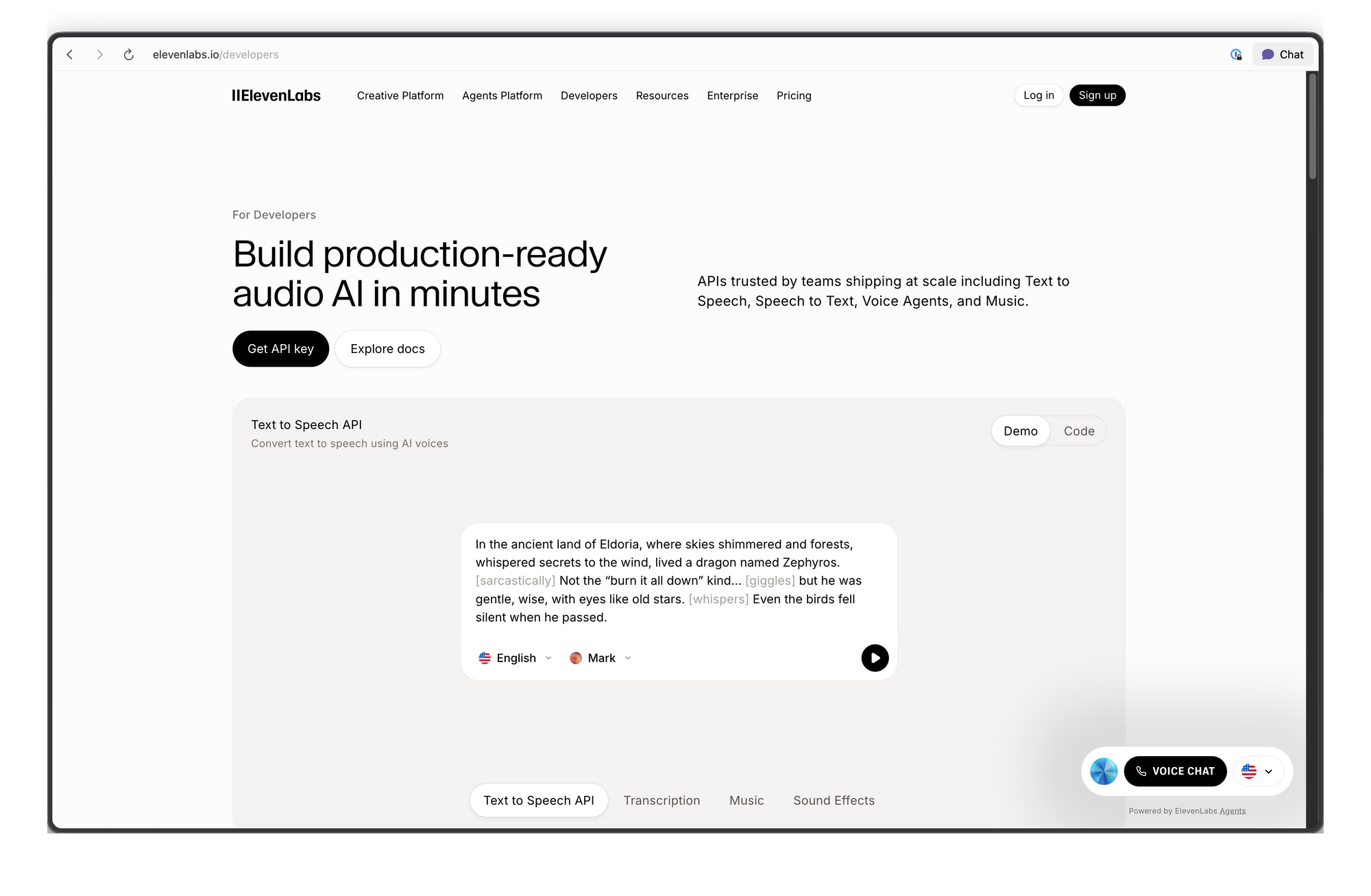
핵심 기능:
- 텍스트 음성 변환 (TTS): 작성된 텍스트를 음성 특성, 감정, 속도 조절이 가능한 음성 오디오로 변환합니다.
- 음성 간 변환 (STS): 원본 억양과 타이밍을 유지하면서 하나의 음성을 다른 음성으로 변환합니다.
- 음성 복제: 60초의 깨끗한 오디오만으로 모든 음성의 디지털 복제본을 만듭니다.
- AI 더빙: 화자의 음성 특성을 유지하면서 오디오/비디오 콘텐츠를 다른 언어로 번역하고 더빙합니다.
- 음향 효과: 텍스트 설명에서 음향 효과를 생성합니다.
- 음성 텍스트 변환: 오디오를 높은 정확도로 텍스트로 변환합니다.
API는 표준 HTTP 및 WebSocket 프로토콜을 통해 작동합니다. 모든 언어에서 호출할 수 있지만, 타입 안전성과 스트리밍 지원이 내장된 Python 및 JavaScript/TypeScript용 공식 SDK가 존재합니다.
ElevenLabs API 키 얻기
API 호출을 하기 전에 API 키가 필요합니다. 다음은 키를 얻는 방법입니다:
1단계: 무료 계정을 만드세요. 무료 플랜도 매월 10,000자까지 API 접근을 포함합니다.
2단계: 로그인하여 프로필 + API 키 섹션으로 이동하세요. 이 섹션은 왼쪽 하단 모서리에 있는 프로필 아이콘을 클릭하거나 개발자 설정으로 직접 이동하여 찾을 수 있습니다.
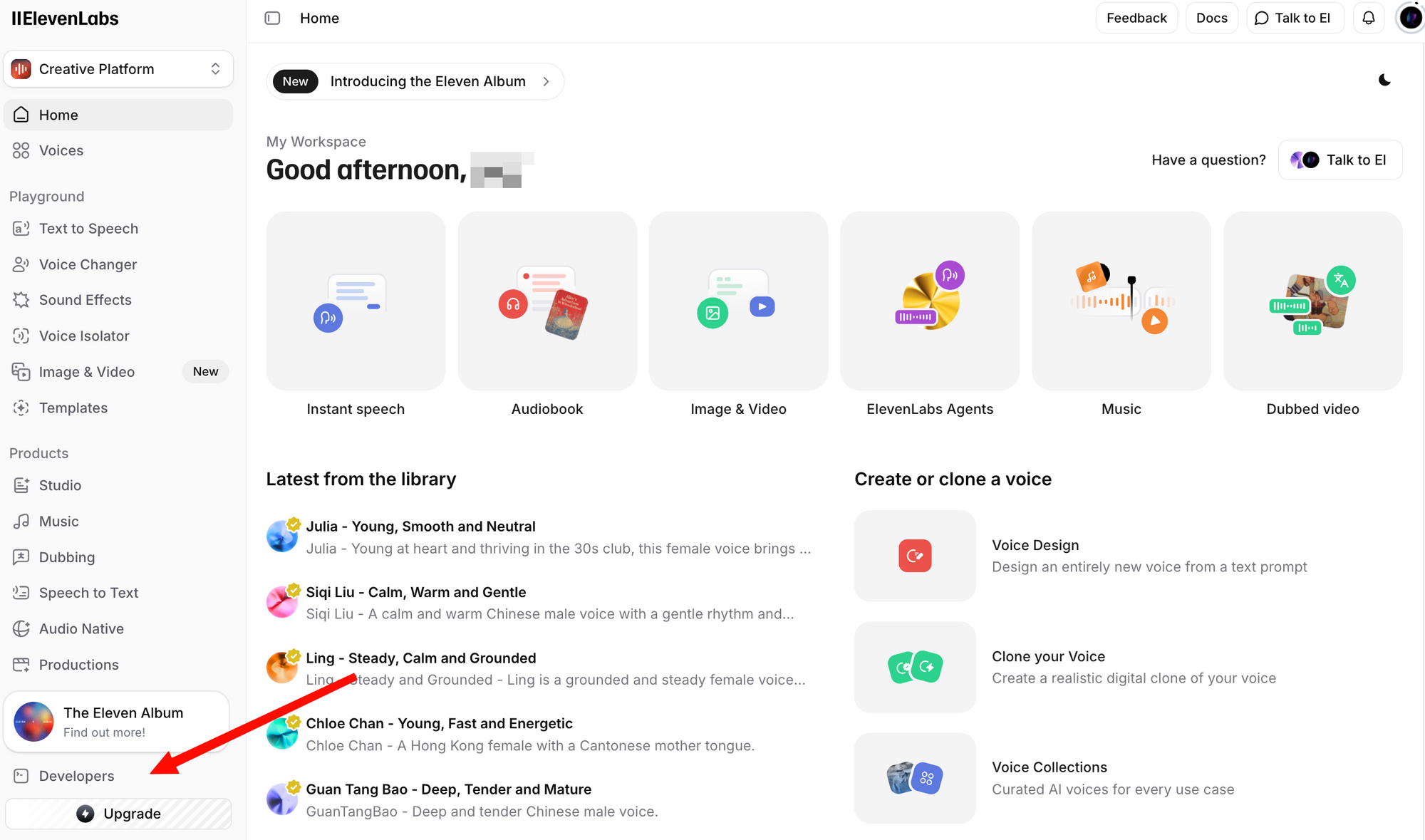
3단계: API 키 생성 버튼을 클릭하세요. 키를 복사하여 안전하게 보관하세요. 전체 키는 다시 볼 수 없습니다.
중요 보안 유의사항:
- API 키를 버전 관리 시스템에 커밋하지 마세요.
- 운영 환경에서는 환경 변수 또는 비밀 관리자를 사용하세요.
- API 키는 팀 환경을 위해 특정 워크스페이스로 범위가 지정될 수 있습니다.
- 정기적으로 키를 교체하고, 유출된 키는 즉시 해지하세요.
이 가이드의 예제에서는 이를 환경 변수로 설정하세요:
# Linux/macOS
export ELEVENLABS_API_KEY="your_api_key_here"
# Windows (PowerShell)
$env:ELEVENLABS_API_KEY="your_api_key_here"
ElevenLabs API 엔드포인트 개요
API는 여러 리소스 그룹을 중심으로 구성되어 있습니다. 다음은 가장 일반적으로 사용되는 엔드포인트입니다:
| 엔드포인트 | 메서드 | 설명 |
|---|---|---|
/v1/text-to-speech/{voice_id} | POST | 텍스트를 음성 오디오로 변환 |
/v1/text-to-speech/{voice_id}/stream | POST | 오디오 생성과 동시에 스트리밍 |
/v1/speech-to-speech/{voice_id} | POST | 한 음성에서 다른 음성으로 음성 변환 |
/v1/voices | GET | 사용 가능한 모든 음성 목록 |
/v1/voices/{voice_id} | GET | 특정 음성의 세부 정보 가져오기 |
/v1/models | GET | 사용 가능한 모든 모델 목록 |
/v1/user | GET | 사용자 계정 정보 및 사용량 가져오기 |
/v1/voice-generation/generate-voice | POST | 새로운 무작위 음성 생성 |
기본 URL: https://api.elevenlabs.io
인증: 모든 요청에는 xi-api-key 헤더가 필요합니다:
xi-api-key: your_api_key_here
cURL을 이용한 텍스트 음성 변환
API를 테스트하는 가장 빠른 방법은 cURL 명령을 사용하는 것입니다. 이 예제는 모든 플랜에서 사용 가능한 기본 음성 중 하나인 Rachel 음성(ID: 21m00Tcm4TlvDq8ikWAM)을 사용합니다:
curl -X POST "https://api.elevenlabs.io/v1/text-to-speech/21m00Tcm4TlvDq8ikWAM" \
-H "xi-api-key: $ELEVENLABS_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"text": "저희 애플리케이션에 오신 것을 환영합니다. 이 오디오는 ElevenLabs API를 사용하여 생성되었습니다.",
"model_id": "eleven_flash_v2_5",
"voice_settings": {
"stability": 0.5,
"similarity_boost": 0.75,
"style": 0.0,
"use_speaker_boost": true
}
}' \
--output speech.mp3
성공하면 생성된 오디오가 담긴 speech.mp3 파일을 얻게 됩니다. 모든 미디어 플레이어로 재생할 수 있습니다.
요청 분석:
- voice_id (URL 내): 사용할 음성의 ID입니다. ElevenLabs의 모든 음성에는 고유 ID가 있습니다.
- text: 음성으로 변환할 내용입니다. Flash v2.5 모델은 요청당 최대 40,000자를 지원합니다.
- model_id: 사용할 AI 모델입니다.
eleven_flash_v2_5는 속도와 품질의 최적 균형을 제공합니다. - voice_settings: 선택적 미세 조정 매개변수입니다 (아래에서 자세히 다룹니다).
응답은 원시 오디오 데이터를 반환합니다. 기본 형식은 MP3이지만, output_format 쿼리 매개변수를 추가하여 다른 형식을 요청할 수 있습니다:
# MP3 대신 PCM 오디오 가져오기
curl -X POST "https://api.elevenlabs.io/v1/text-to-speech/21m00Tcm4TlvDq8ikWAM?output_format=pcm_44100" \
-H "xi-api-key: $ELEVENLABS_API_KEY" \
-H "Content-Type: application/json" \
-d '{"text": "안녕하세요", "model_id": "eleven_flash_v2_5"}' \
--output speech.pcm
Python SDK 사용하기
공식 Python SDK는 타입 힌트, 내장 오디오 재생 및 스트리밍 지원을 통해 통합을 간소화합니다.
설치
pip install elevenlabs
스피커를 통해 오디오를 직접 재생하려면 mpv 또는 ffmpeg가 필요할 수도 있습니다:
# macOS
brew install mpv
# Ubuntu/Debian
sudo apt install mpv
기본 텍스트 음성 변환
import os
from elevenlabs.client import ElevenLabs
from elevenlabs import play
client = ElevenLabs(
api_key=os.getenv("ELEVENLABS_API_KEY")
)
audio = client.text_to_speech.convert(
text="ElevenLabs API를 사용하면 어떤 애플리케이션에도 사실적인 음성 출력을 쉽게 추가할 수 있습니다.",
voice_id="JBFqnCBsd6RMkjVDRZzb", # George voice
model_id="eleven_multilingual_v2",
output_format="mp3_44100_128",
)
play(audio)
오디오 파일로 저장
from elevenlabs.client import ElevenLabs
client = ElevenLabs(api_key="your_api_key")
audio = client.text_to_speech.convert(
text="이 오디오는 파일로 저장될 것입니다.",
voice_id="21m00Tcm4TlvDq8ikWAM",
model_id="eleven_flash_v2_5",
)
with open("output.mp3", "wb") as f:
for chunk in audio:
f.write(chunk)
print("오디오가 output.mp3에 저장되었습니다.")
사용 가능한 음성 목록
from elevenlabs.client import ElevenLabs
client = ElevenLabs(api_key="your_api_key")
response = client.voices.search()
for voice in response.voices:
print(f"이름: {voice.name}, ID: {voice.voice_id}, 카테고리: {voice.category}")
이것은 사전 제작된 음성, 복제된 음성, 그리고 사용자가 추가한 커뮤니티 음성을 포함하여 계정에서 사용 가능한 모든 음성을 출력합니다.
비동기 지원
asyncio를 사용하는 애플리케이션의 경우, SDK는 AsyncElevenLabs를 제공합니다:
import asyncio
from elevenlabs.client import AsyncElevenLabs
client = AsyncElevenLabs(api_key="your_api_key")
async def generate_speech():
audio = await client.text_to_speech.convert(
text="이것은 비동기적으로 생성되었습니다.",
voice_id="21m00Tcm4TlvDq8ikWAM",
model_id="eleven_flash_v2_5",
)
with open("async_output.mp3", "wb") as f:
async for chunk in audio:
f.write(chunk)
print("비동기 오디오가 저장되었습니다.")
asyncio.run(generate_speech())
JavaScript SDK 사용하기
공식 Node.js SDK (@elevenlabs/elevenlabs-js)는 완전한 TypeScript 지원을 제공하며 Node.js 환경에서 작동합니다.
설치
npm install @elevenlabs/elevenlabs-js
기본 텍스트 음성 변환
import { ElevenLabsClient, play } from "@elevenlabs/elevenlabs-js";
const elevenlabs = new ElevenLabsClient({
apiKey: process.env.ELEVENLABS_API_KEY,
});
const audio = await elevenlabs.textToSpeech.convert(
"21m00Tcm4TlvDq8ikWAM", // Rachel voice ID
{
text: "ElevenLabs JavaScript SDK에서 인사드립니다!",
modelId: "eleven_multilingual_v2",
}
);
await play(audio);
파일로 저장 (Node.js)
import { ElevenLabsClient } from "@elevenlabs/elevenlabs-js";
import { createWriteStream } from "fs";
import { Readable } from "stream";
import { pipeline } from "stream/promises";
const elevenlabs = new ElevenLabsClient({
apiKey: process.env.ELEVENLABS_API_KEY,
});
const audio = await elevenlabs.textToSpeech.convert(
"21m00Tcm4TlvDq8ikWAM",
{
text: "이 오디오는 Node.js 스트림을 사용하여 파일에 기록될 것입니다.",
modelId: "eleven_flash_v2_5",
}
);
const readable = Readable.from(audio);
const writeStream = createWriteStream("output.mp3");
await pipeline(readable, writeStream);
console.log("오디오가 output.mp3에 저장되었습니다.");
오류 처리
import { ElevenLabsClient, ElevenLabsError } from "@elevenlabs/elevenlabs-js";
const elevenlabs = new ElevenLabsClient({
apiKey: process.env.ELEVENLABS_API_KEY,
});
try {
const audio = await elevenlabs.textToSpeech.convert(
"21m00Tcm4TlvDq8ikWAM",
{
text: "오류 처리를 테스트합니다.",
modelId: "eleven_flash_v2_5",
}
);
await play(audio);
} catch (error) {
if (error instanceof ElevenLabsError) {
console.error(`API 오류: ${error.message}, 상태: ${error.statusCode}`);
} else {
console.error("예상치 못한 오류:", error);
}
}
SDK는 기본적으로 실패한 요청을 최대 2회까지 재시도하며, 60초의 타임아웃이 설정되어 있습니다. 두 값 모두 구성 가능합니다.
실시간 오디오 스트리밍
챗봇, 음성 비서 또는 지연 시간이 중요한 모든 애플리케이션의 경우, 스트리밍을 통해 전체 응답이 생성되기 전에 오디오 재생을 시작할 수 있습니다. 이는 사용자가 거의 즉각적인 응답을 기대하는 대화형 AI에 중요합니다.
Python 스트리밍
from elevenlabs import stream
from elevenlabs.client import ElevenLabs
client = ElevenLabs(api_key="your_api_key")
audio_stream = client.text_to_speech.stream(
text="스트리밍을 통해 전체 생성이 완료될 때까지 기다릴 필요 없이 거의 즉시 오디오를 들을 수 있습니다.",
voice_id="JBFqnCBsd6RMkjVDRZzb",
model_id="eleven_flash_v2_5",
)
# Play streamed audio through speakers in real time
stream(audio_stream)
JavaScript 스트리밍
import { ElevenLabsClient, stream } from "@elevenlabs/elevenlabs-js";
const elevenlabs = new ElevenLabsClient();
const audioStream = await elevenlabs.textToSpeech.stream(
"JBFqnCBsd6RMkjVDRZzb",
{
text: "이 오디오는 최소한의 지연으로 실시간 스트리밍됩니다.",
modelId: "eleven_flash_v2_5",
}
);
stream(audioStream);
WebSocket 스트리밍
최소 지연 시간을 위해서는 WebSocket 연결을 사용하세요. 이는 텍스트가 청크 단위로 도착하는 실시간 음성 에이전트(예: LLM으로부터)에 이상적입니다:
import asyncio
import websockets
import json
import base64
async def stream_tts_websocket():
voice_id = "21m00Tcm4TlvDq8ikWAM"
model_id = "eleven_flash_v2_5"
uri = f"wss://api.elevenlabs.io/v1/text-to-speech/{voice_id}/stream-input?model_id={model_id}"
async with websockets.connect(uri) as ws:
# Send initial config
await ws.send(json.dumps({
"text": " ",
"voice_settings": {"stability": 0.5, "similarity_boost": 0.75},
"xi_api_key": "your_api_key",
}))
# Send text chunks as they arrive (e.g., from an LLM)
text_chunks = [
"Hello! ",
"This is streaming ",
"via WebSockets. ",
"각 청크는 개별적으로 전송됩니다."
]
for chunk in text_chunks:
await ws.send(json.dumps({"text": chunk}))
# Signal end of input
await ws.send(json.dumps({"text": ""}))
# Receive audio chunks
audio_data = b""
async for message in ws:
data = json.loads(message)
if data.get("audio"):
audio_data += base64.b64decode(data["audio"])
if data.get("isFinal"):
break
with open("websocket_output.mp3", "wb") as f:
f.write(audio_data)
print("WebSocket 오디오가 저장되었습니다.")
asyncio.run(stream_tts_websocket())
음성 선택 및 관리
ElevenLabs는 수백 가지의 음성을 제공합니다. 적절한 음성을 선택하는 것은 애플리케이션의 사용자 경험에 중요합니다.
기본 음성
이 음성들은 무료 티어를 포함한 모든 플랜에서 사용 가능합니다:
| 음성 이름 | 음성 ID | 설명 |
|---|---|---|
| Rachel | 21m00Tcm4TlvDq8ikWAM | 차분하고 젊은 여성 |
| Drew | 29vD33N1CtxCmqQRPOHJ | 원만한 남성 |
| Clyde | 2EiwWnXFnvU5JabPnv8n | 참전 용사 캐릭터 |
| Paul | 5Q0t7uMcjvnagumLfvZi | 현장 기자 |
| Domi | AZnzlk1XvdvUeBnXmlld | 강하고 단호한 여성 |
| Dave | CYw3kZ02Hs0563khs1Fj | 대화형 영국 남성 |
| Fin | D38z5RcWu1voky8WS1ja | 아일랜드 남성 |
| Sarah | EXAVITQu4vr4xnSDxMaL | 부드럽고 젊은 여성 |
음성 ID 찾기
API를 사용하여 사용 가능한 모든 음성을 검색하세요:
curl -X GET "https://api.elevenlabs.io/v1/voices" \
-H "xi-api-key: $ELEVENLABS_API_KEY" | python3 -m json.tool
또는 카테고리별로 필터링하세요 (사전 제작, 복제, 생성):
from elevenlabs.client import ElevenLabs
client = ElevenLabs(api_key="your_api_key")
# List only premade voices
response = client.voices.search(category="premade")
for voice in response.voices:
print(f"{voice.name}: {voice.voice_id}")
ElevenLabs 웹사이트에서 직접 음성 ID를 복사할 수도 있습니다. 음성을 선택하고, 세 점 메뉴를 클릭한 다음 음성 ID 복사를 선택하세요.
올바른 모델 선택하기
ElevenLabs는 다양한 사용 사례에 최적화된 여러 모델을 제공합니다:

# 세부 정보와 함께 사용 가능한 모든 모델 나열
from elevenlabs.client import ElevenLabs
client = ElevenLabs(api_key="your_api_key")
models = client.models.list()
for model in models:
print(f"모델: {model.name}")
print(f" ID: {model.model_id}")
print(f" 언어: {len(model.languages)}")
print(f" 최대 문자: {model.max_characters_request_free_user}")
print()
Apidog로 ElevenLabs API 테스트하기
통합 코드를 작성하기 전에 API 엔드포인트를 대화식으로 테스트하는 것이 도움이 됩니다. Apidog는 이를 간단하게 만들어줍니다. 요청을 시각적으로 구성하고, 응답(오디오 포함)을 검사하며, 만족하면 클라이언트 코드를 생성할 수 있습니다.
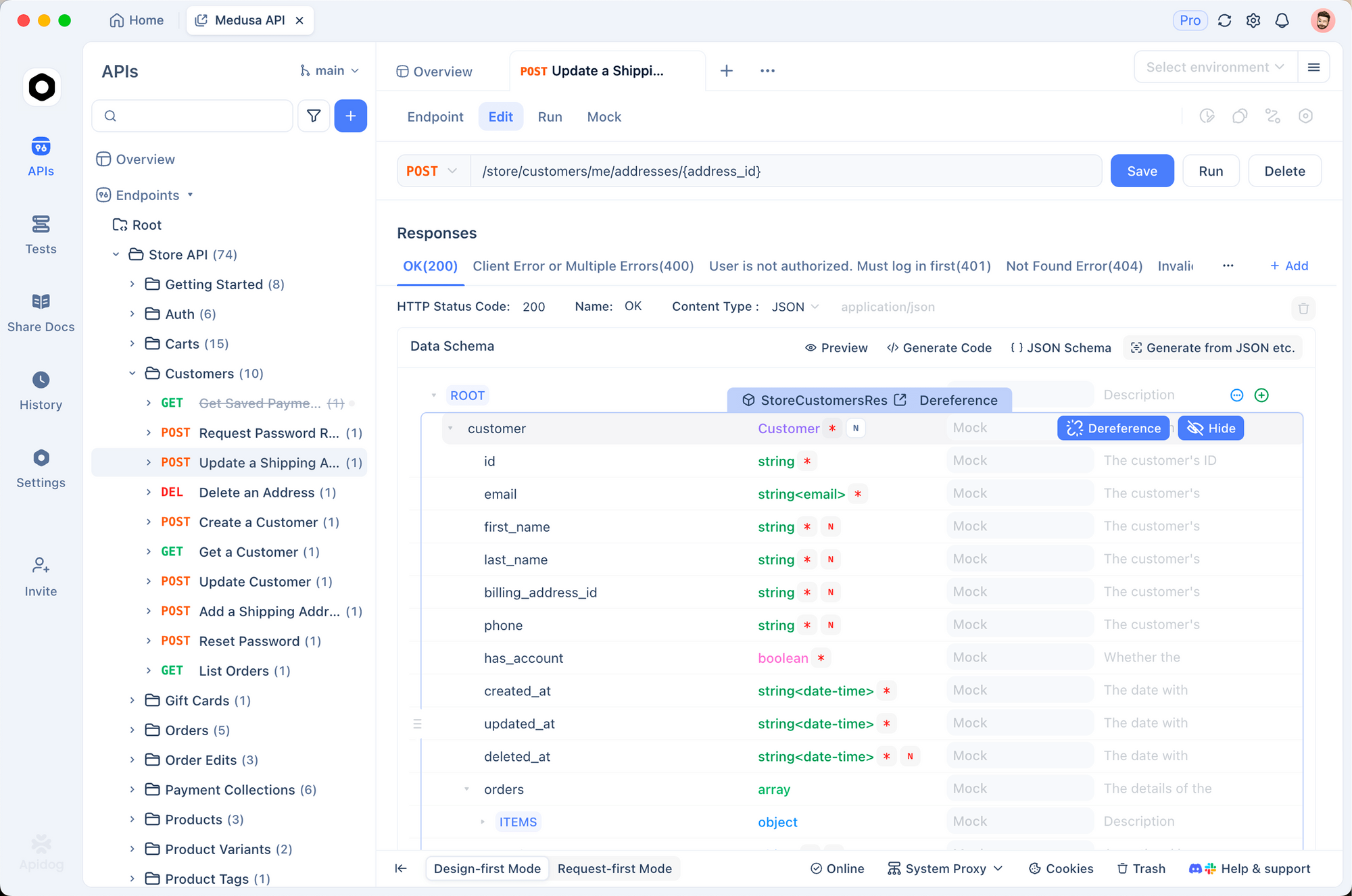
1단계: 새 프로젝트 설정
Apidog를 열고 새 프로젝트를 만드세요. 이름을 "ElevenLabs API"로 지정하거나 기존 프로젝트에 엔드포인트를 추가하세요.
2단계: 인증 구성
프로젝트 설정 > 인증으로 이동하여 전역 헤더를 설정하세요:
- 헤더 이름:
xi-api-key - 헤더 값: ElevenLabs API 키
이렇게 하면 프로젝트의 모든 요청에 인증이 자동으로 첨부됩니다.
3단계: 텍스트 음성 변환 요청 생성
새 POST 요청을 생성하세요:
- URL:
https://api.elevenlabs.io/v1/text-to-speech/21m00Tcm4TlvDq8ikWAM - 본문 (JSON):
{
"text": "Apidog를 통해 ElevenLabs API를 테스트하고 있습니다. 이를 통해 다양한 음성과 설정을 쉽게 실험할 수 있습니다.",
"model_id": "eleven_flash_v2_5",
"voice_settings": {
"stability": 0.5,
"similarity_boost": 0.75
}
}
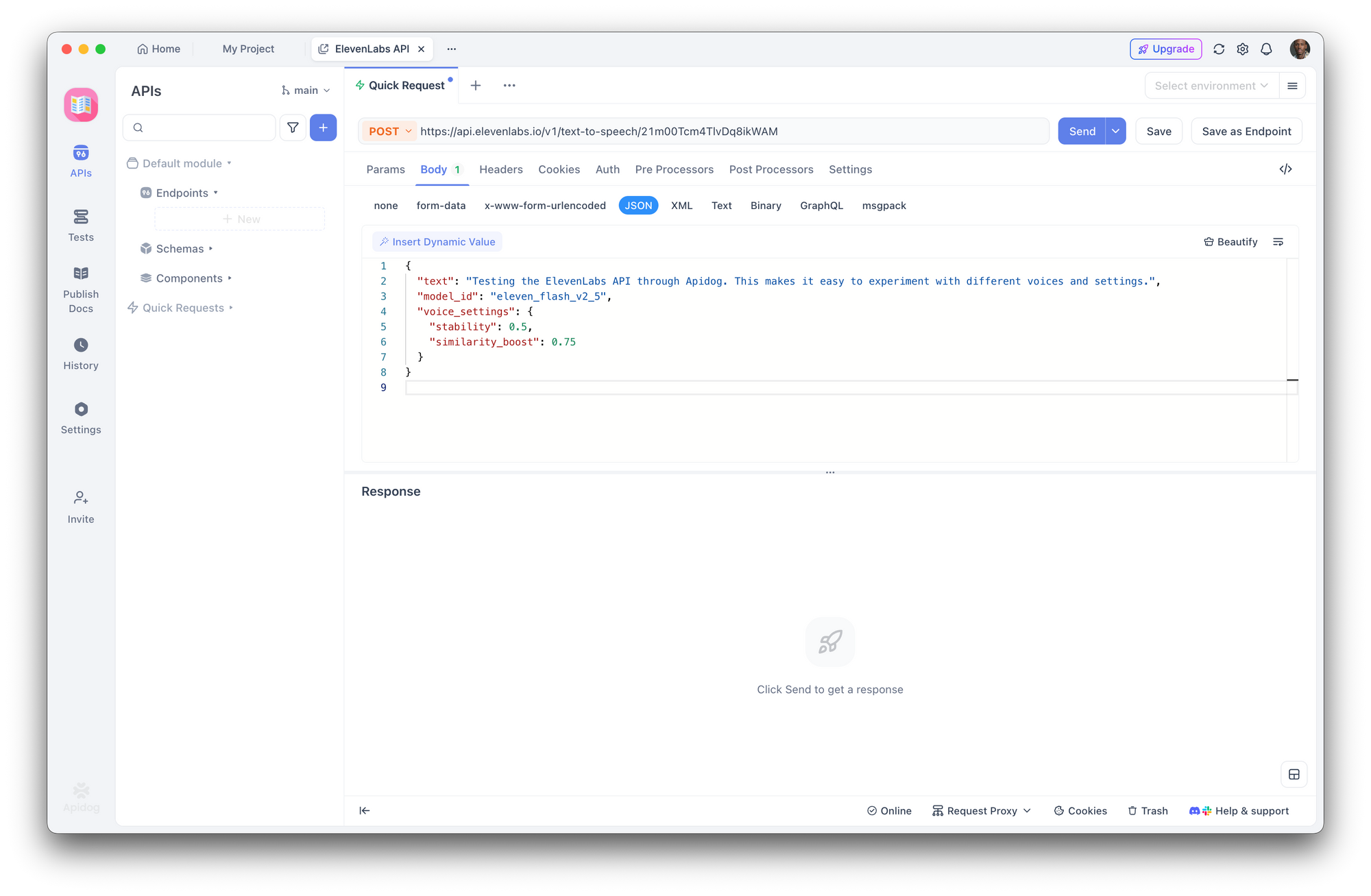
전송을 클릭하세요. Apidog는 응답 헤더를 표시하고 오디오를 직접 다운로드하거나 재생할 수 있도록 합니다.
4단계: 매개변수 실험
Apidog의 인터페이스를 사용하여 원시 JSON을 편집하지 않고도 음성 ID를 빠르게 변경하거나, 모델을 바꾸거나, 음성 설정을 조정할 수 있습니다. 쉬운 비교를 위해 다양한 구성을 컬렉션에 별도의 엔드포인트로 저장하세요.
5단계: 클라이언트 코드 생성
요청이 작동하는 것을 확인한 후, Apidog에서 코드 생성을 클릭하여 Python, JavaScript, cURL, Go, Java 등에서 바로 사용할 수 있는 클라이언트 코드를 얻으세요. 이는 API 문서에서 작동하는 코드로의 수동 번역을 없애줍니다.
지금 시도해보세요:Apidog를 무료로 다운로드
음성 설정 및 미세 조정
음성 설정을 통해 음성의 소리를 조절할 수 있습니다. 이 매개변수들은 voice_settings 객체로 전송됩니다:
| 매개변수 | 범위 | 기본값 | 효과 |
|---|---|---|---|
stability | 0.0 - 1.0 | 0.5 | 높을수록 일관되고 덜 표현적입니다. 낮을수록 가변적이고 감정적입니다. |
similarity_boost | 0.0 - 1.0 | 0.75 | 높을수록 원본 음성에 가깝습니다. 낮을수록 변화가 많습니다. |
style | 0.0 - 1.0 | 0.0 | 높을수록 스타일이 과장됩니다. 지연 시간이 증가합니다. Multilingual v2에서만 해당됩니다. |
use_speaker_boost | boolean | true | 원본 화자와의 유사성을 높입니다. 약간의 지연 시간 증가가 있습니다. |
실용적인 예시:
from elevenlabs.client import ElevenLabs
client = ElevenLabs(api_key="your_api_key")
# Narration voice: consistent, stable
narration = client.text_to_speech.convert(
text="1장. 4월의 밝고 추운 날이었습니다.",
voice_id="21m00Tcm4TlvDq8ikWAM",
model_id="eleven_multilingual_v2",
voice_settings={
"stability": 0.8,
"similarity_boost": 0.8,
"style": 0.2,
"use_speaker_boost": True,
},
)
# Conversational voice: expressive, natural
conversational = client.text_to_speech.convert(
text="오, 정말 좋은 아이디어네요! 어떻게 하면 작동시킬 수 있을지 생각해볼게요.",
voice_id="JBFqnCBsd6RMkjVDRZzb",
model_id="eleven_multilingual_v2",
voice_settings={
"stability": 0.3,
"similarity_boost": 0.6,
"style": 0.5,
"use_speaker_boost": True,
},
)
가이드라인:
- 오디오북 및 내레이션의 경우, 일관된 전달을 위해 높은 안정성(0.7-0.9)을 사용하세요.
- 챗봇 및 대화형 AI의 경우, 자연스러운 변화를 위해 낮은 안정성(0.3-0.5)을 사용하세요.
- 캐릭터 음성의 경우, 독특한 개성을 만들기 위해 낮은
similarity_boost(0.4-0.6)로 실험해보세요. style매개변수는 Multilingual v2에서만 작동하며 지연 시간을 추가합니다. 실시간 애플리케이션에서는 사용하지 마세요.
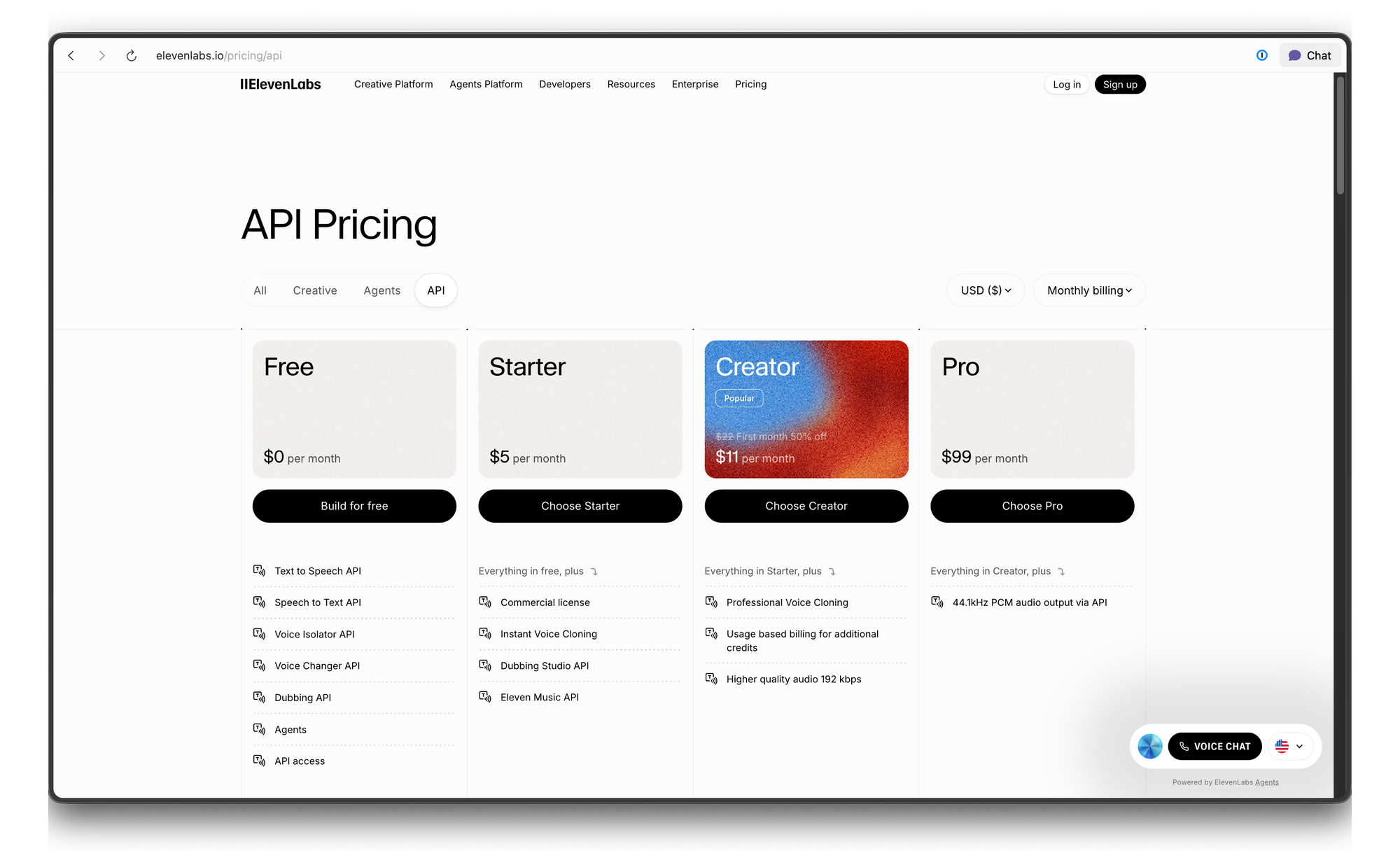
ElevenLabs API 가격 및 속도 제한
ElevenLabs는 크레딧 기반의 가격 시스템을 사용합니다. 다음은 세부 내역입니다:
문제 해결
| 오류 | 원인 | 해결책 |
|---|---|---|
| 401 Unauthorized | 유효하지 않거나 누락된 API 키 | xi-api-key 헤더 값을 확인하세요. |
| 422 Unprocessable Entity | 유효하지 않은 요청 본문 | voice_id가 존재하는지, 텍스트가 비어 있지 않은지 확인하세요. |
| 429 Too Many Requests | 속도 제한 초과 |