コードを一行も書き直すことなくAIプロバイダーを切り替えられたらどうでしょう?Venice APIはまさにそれを実現します。データ保持ゼロ、検閲されていないモデルオプション、そしてあなたがコントロールできるプライバシーファーストのアーキテクチャを備えたOpenAI互換のエンドポイントを提供します。
ほとんどのAI APIは、ベンダー固有のSDKを強制し、モデルトレーニングのためにデータを保持し、基本的な機能に対しても高額な料金を請求します。プロバイダーを切り替えるたびにアプリケーションを書き直す必要があります。あなたのプロンプトが競合他社のモデルをトレーニングし、コストは予測不能に増加します。
Venice APIはこれらの摩擦を排除します。OpenAIのAPI構造を正確に模倣しており、ベースURLを変更するだけで既存のコードがすぐに機能します。あなたのデータはプライベートに保たれます。仮想通貨ステーキングや従量課金制のUSDクレジットを含む複数の支払いモデルから選択できます。
開発チームが最高の生産性で共同作業するための統合されたオールインワンプラットフォームが欲しいですか?
Apidogはあなたのすべての要求に応え、Postmanをはるかに手頃な価格で置き換えます!
Venice APIキーの生成
1. venice.ai/settings/apiに移動します。
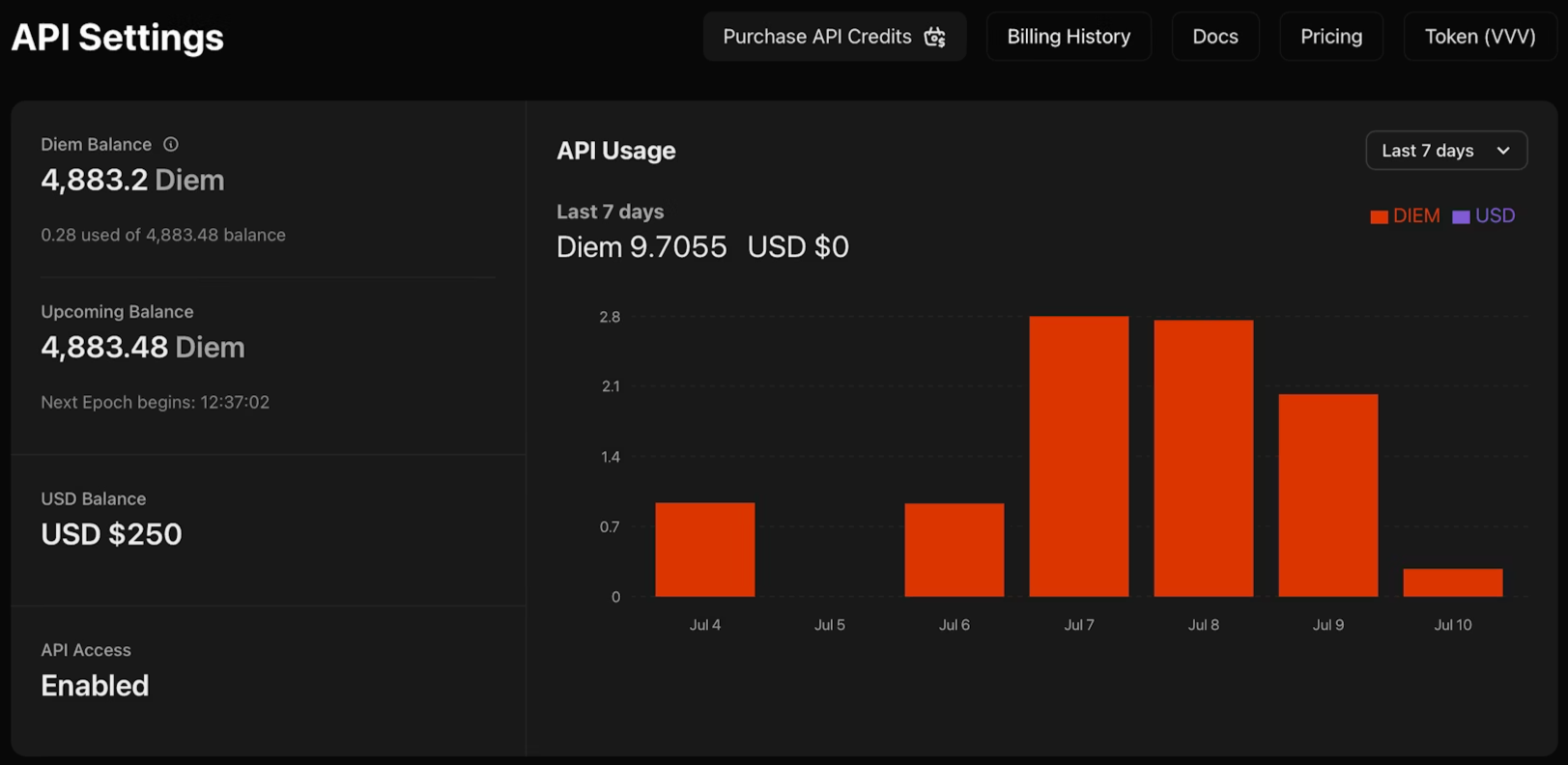
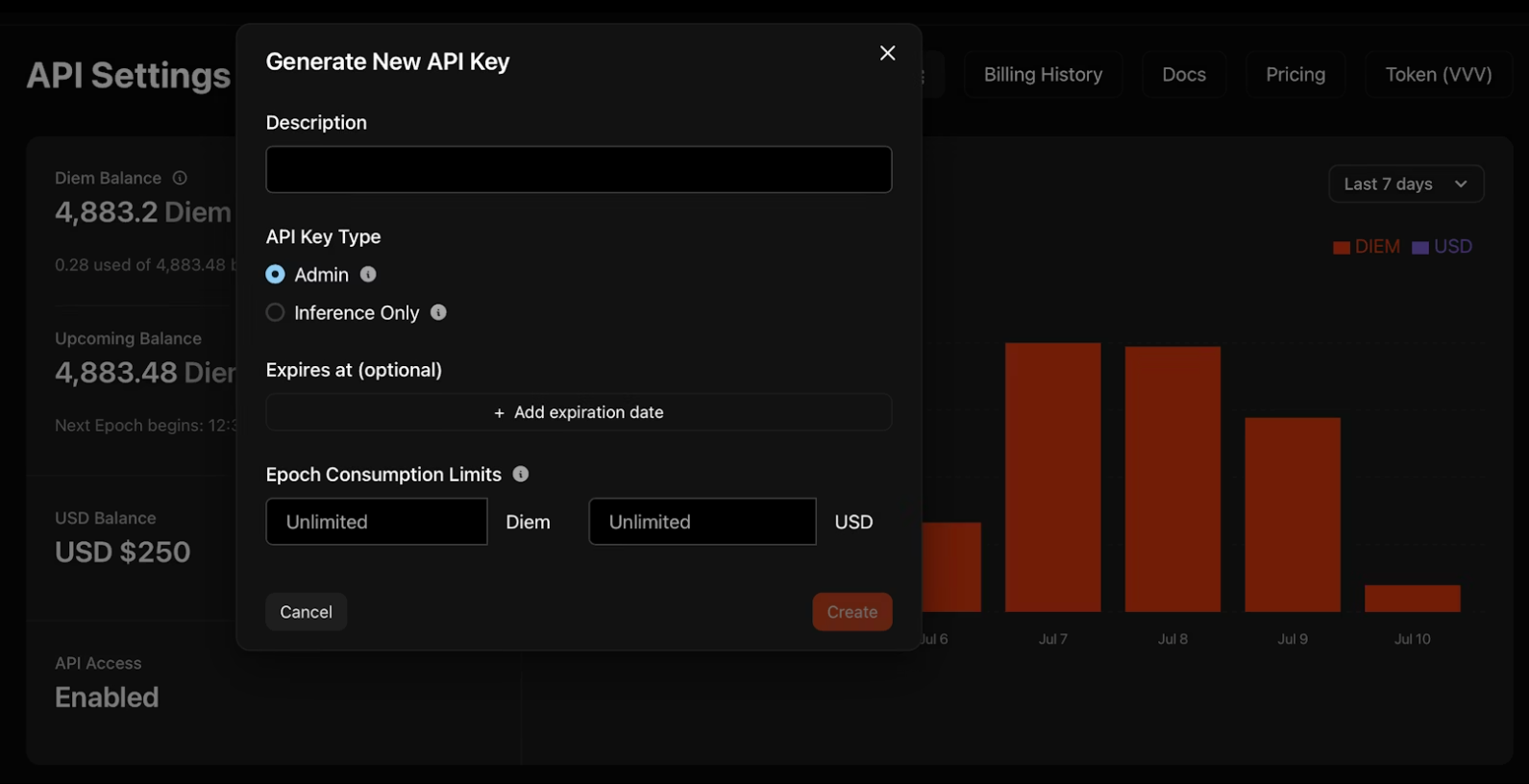
2. 「新しいAPIキーを生成」をクリックし、資格情報を設定します。
- 説明: 整理のためにキーに名前を付けます
- タイプ: 管理者キーは他のキーをプログラムで管理します。推論専用キーはモデルのみを実行します
- 有効期限: キーが自動的に無効になるオプションの日付
- 使用制限: 支出を管理するための日次DiemまたはUSDの上限
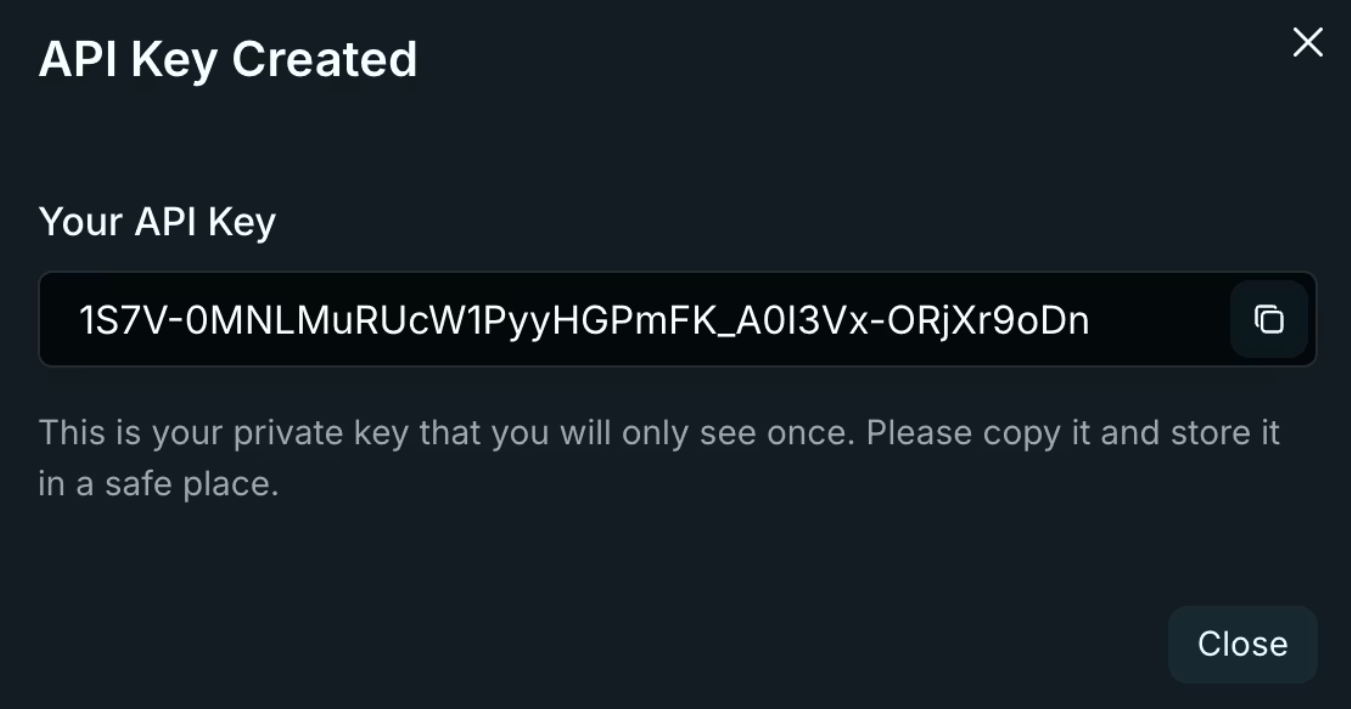
3. キーをすぐにコピーしてください。Veniceは一度だけ表示します!環境変数に保存し、コードリポジトリには決して保存しないでください。
export VENICE_API_KEY="your-key-here"
キーのセキュリティに関する考慮事項
管理者キーは、あなたのVeniceアカウントへの広範なアクセスを提供します。これらをルート資格情報として扱い、キーローテーションスクリプトやチーム管理にのみ使用し、アプリケーションコードには決して含めないでください。推論専用キーは操作をモデル実行に限定し、漏洩した場合の露出を制限します。ダッシュボードのアクティビティログを使用して期限切れの資格情報を特定し、キーを四半期ごとにローテーションしてください。
Venice APIの認証と基本構成
Veniceは標準のBearerトークン認証を使用します。すべてのリクエストには2つのヘッダーが必要です。
Authorization: Bearer $VENICE_API_KEY
Content-Type: application/json
ベースURLはOpenAIのパターンに完全に準拠しています。
import openai
import os
client = openai.OpenAI(
api_key=os.getenv("VENICE_API_KEY"),
base_url="https://api.venice.ai/api/v1"
)
この単一の構成変更により、既存のすべてのOpenAI SDK呼び出しがVeniceのインフラストラクチャを経由します。メソッドの変更も、パラメーターの書き換えも不要です。すぐにコードが機能します。
SDKの互換性
Veniceは、Python、TypeScript、Go、PHP、C#、Java、SwiftにわたるOpenAIの公式SDKとの互換性を維持しています。OpenAIの仕様に基づいて構築されたサードパーティライブラリも、変更なしで動作します。既存のコードベースをVeniceに対してテストするには、ベースURLとAPIキーのみを変更してください。標準のチャット補完、ストリーミング、または関数呼び出しを使用している場合、移行は数分で完了します。
OpenAIからの移行
移行には、ベースURL、APIキー、モデル名の3つの変更が必要です。`https://api.openai.com/v1` を `https://api.venice.ai/api/v1` に置き換えます。OpenAIのAPIキーをVeniceのキーと交換します。モデル識別子を `gpt-4` や `gpt-3.5-turbo` から `qwen3-4b` のようなVeniceの同等物に_変更します。本番展開の前に徹底的にテストしてください。ストリーミング応答が正しく処理されることを確認してください。関数呼び出しスキーマが検証されることを確認してください。画像生成パラメーターが要件と一致していることを確認してください。Veniceの互換性レイヤーはほとんどのエッジケースを処理しますが、エラーメッセージのフォーマットやレート制限ヘッダーには微妙な違いがあります。
ヒント: すべてのAPIエンドポイントをApidogで徹底的にテストしてください。
Venice APIのコアエンドポイントと機能
Veniceは、テキスト、画像、オーディオ、ビデオ生成をカバーする9つの異なるエンドポイントを提供します。
テキスト生成
/api/v1/chat/completions- ストリーミングをサポートする会話型AI/api/v1/embeddings/generate- RAGアプリケーション向けのベクトル埋め込み
画像処理
/api/v1/image/generate- テキストから画像への生成/api/v1/image/upscale- 解像度向上/api/v1/image/edit- AIによるインペインティングと修正
オーディオ
/api/v1/audio/speech- テキストから音声への合成/api/v1/audio/transcriptions- 音声からテキストへの変換
ビデオとキャラクター
/api/v1/video/queue- テキスト/ビデオからビデオへの生成/api/v1/characters/list- AIペルソナ管理
各エンドポイントは、該当する場合、OpenAI互換のリクエスト/レスポンス形式を維持します。既存の解析ロジックを再利用できます。
エンドポイント選択戦略
ユースケースの複雑さに応じてエンドポイントを_選択してください。チャット補完はほとんどのテキスト生成ニーズに対応します。セマンティック検索やRAGパイプラインには埋め込みを追加してください。クリエイティブなワークフローやコンテンツモデレーションには画像エンドポイントを使用してください。オーディオエンドポイントはアクセシビリティ機能や音声インターフェースを可能にします。まず1つのエンドポイントから始めて統合を検証し、その後マルチモーダルワークフローに拡張してください。
ストリーミング応答の扱い
ストリーミングはチャットアプリケーションの体感的な遅延を低減します。VeniceはOpenAIの実装と同一のServer-Sent Events (SSE) を使用します。完全な応答を待つのではなく、到着した部分的なコンテンツを処理します。`[DONE]`メッセージをチェックしてストリームの終了を処理します。中断されたストリームには再接続ロジックを実装し、会話履歴をクライアント側に保存して失敗したリクエストを再試行します。ストリームチャンク内のトークン使用量を監視して、コストをリアルタイムで追跡します。
Venice API固有のパラメーター
OpenAIの標準パラメーターに加えて、Veniceは `venice_parameters` オブジェクトを通じて機能制御を追加します。
{
"model": "qwen3-4b",
"messages": [{"role": "user", "content": "Latest AI developments?"}],
"venice_parameters": {
"enable_web_search": "on",
"enable_web_citations": true,
"strip_thinking_response": false
}
}
ウェブ検索統合
`enable_web_search` を `auto`、`on`、または `off` に設定します。`auto` は、最新情報が応答を改善する場合にモデルが判断できるようにします。最近のイベントや急速に変化する技術に関するリアルタイムクエリには、強制的に `on` に設定します。`enable_web_citations` と組み合わせてソースURLを返すことで、研究ツールや事実確認に不可欠です。
推論制御
DeepSeek R1のような推論モデルは、デフォルトで段階的な思考プロセスを表示します。最終回答のみを返すように `strip_thinking_response` を `true` に設定すると、トークン消費量を削減できます。簡単なクエリの場合は、`disable_thinking` を使用して推論を完全にバイパスします。
代替構文
簡潔なリクエストのために、モデルサフィックスを介してパラメーターを渡します。
model="qwen3-4b:enable_web_search=on&enable_web_citations=true"
パラメーターの階層
Venice固有のパラメーターはデフォルトを上書きしますが、明示的な設定は尊重します。ルートオブジェクトで `temperature: 0.5` を指定し、`venice_parameters` で `enable_web_search: on` を指定した場合、両方が同時に適用されます。本番環境にデプロイする前に、パラメーターの組み合わせを個別にテストしてください。一部のパラメーターは特定のモデルと予測不能な相互作用を起こす可能性があります。
Venice APIを使用する際の具体的な実装例
基本的なチャット補完
curl --request POST \
--url https://api.venice.ai/api/v1/chat/completions \
--header "Authorization: Bearer $VENICE_API_KEY" \
--header "Content-Type: application/json" \
--data '{
"model": "qwen3-4b",
"messages": [{"role": "user", "content": "Explain zero-knowledge proofs"}],
"stream": true
}'
ストリーミングはOpenAIとまったく同じように機能します。SSEチャンクが到着するにつれて処理します。
関数呼び出し
curl --request POST \
--url https://api.venice.ai/api/v1/chat/completions \
--header "Authorization: Bearer $VENICE_API_KEY" \
--header "Content-Type: application/json" \
--data '{
"model": "qwen3-4b",
"messages": [{"role": "user", "content": "Weather in Tokyo?"}],
"tools": [{
"type": "function",
"function": {
"name": "get_weather",
"description": "Get weather for location",
"parameters": {
"type": "object",
"properties": {
"location": {"type": "string"}
},
"required": ["location"]
}
}
}]
}'
Veniceモデルは、OpenAIの実装と同様に、並列関数呼び出しとスキーマの強制をサポートしています。
画像生成
curl --request POST \
--url https://api.venice.ai/api/v1/image/generate \
--header "Authorization: Bearer $VENICE_API_KEY" \
--header "Content-Type: application/json" \
--data '{
"model": "venice-sd35",
"prompt": "Cyberpunk cityscape at night, neon reflections",
"aspect_ratio": "16:9",
"resolution": "2K",
"hide_watermark": true
}'
利用可能なアスペクト比には、1:1、4:3、16:9、21:9が含まれます。解像度オプションは1Kと2Kです。
画像アップスケーリング
curl --request POST \
--url https://api.venice.ai/api/v1/image/upscale \
--header "Authorization: Bearer $VENICE_API_KEY" \
--header "Content-Type: application/json" \
--data '{
"model": "upscale-sd35",
"image": "base64encodedimage..."
}'
ビジョン分析
curl --request POST \
--url https://api.venice.ai/api/v1/chat/completions \
--header "Authorization: Bearer $VENICE_API_KEY" \
--header "Content-Type: application/json" \
--data '{
"model": "qwen3-vl-235b-a22b",
"messages": [{
"role": "user",
"content": [
{"type": "text", "text": "What architecture style is this?"},
{"type": "image_url", "image_url": {"url": "data:image/jpeg;base64,..."}}
]
}]
}'
画像をbase64データURIまたはHTTPS URLとして渡します。ビジョンモデルは、比較タスクのためにメッセージごとに複数の画像を受け入れます。
音声合成
curl --request POST \
--url https://api.venice.ai/api/v1/audio/speech \
--header "Authorization: Bearer $VENICE_API_KEY" \
--header "Content-Type: application/json" \
--data '{
"model": "tts-kokoro",
"input": "Welcome to Venice API",
"voice": "af_sky",
"response_format": "mp3"
}'
音声オプションはプレフィックスを使用します: `af_` (アメリカ人女性)、`am_` (アメリカ人男性)、その他アクセントには同様のパターンを使用します。
エラー処理パターン
Veniceは標準のHTTPステータスコードを返します。401は認証失敗を示します。APIキーとヘッダーを確認してください。429はレート制限を示します。1秒から開始する指数関数的バックオフを実装してください。500エラーは一時的なインフラストラクチャの問題を示します。5秒後に再試行してください。特定のエラーメッセージについてはエラー応答を解析してください。Veniceは応答本文に詳細な失敗理由を含めます。
Venice APIのプライバシーとデータアーキテクチャ
Veniceのゼロデータ保持ポリシーは、法的約束だけでなく、技術的なアーキテクチャを通じて運用されます。ブラウザはIndexedDBを使用して会話履歴をローカルに保存します。Veniceサーバーは、現在のリクエストのみを処理するGPU上でプロンプトを処理します。会話履歴、ユーザーIDメタデータ、APIキー情報は一切ありません。
応答生成後、サーバーはプロンプトと出力を即座に破棄します。ディスクやログに何も永続化されません。あなたのデータがモデルのトレーニングに使用されることはありません。これは、悪用検出やモデル改善のためにデータを保持する集中型サービスとは根本的に異なります。
追加のプライバシーのために、Veniceはほとんどのモデルをサードパーティプロバイダーに依存するのではなく、プライベートインフラストラクチャでホストしています。検閲なしのオプションはVeniceが管理するハードウェア上で実行され、外部からのフィルタリングやロギングがないことを保証します。
データフロー検証
ネットワークトラフィックを監視して、Veniceのプライバシーに関する主張を監査してください。APIリクエストはTLS暗号化により `api.venice.ai` に直接送信されます。ドキュメントにはサードパーティの分析スクリプトはロードされません。応答ヘッダーにはキャッシュディレクティブがなく、サーバー側の非保持を確認できます。機密性の高いアプリケーションの場合は、プロンプトを送信する前にクライアント側の暗号化を実装してください。ただし、これによりモデルがコンテンツを理解できなくなります。
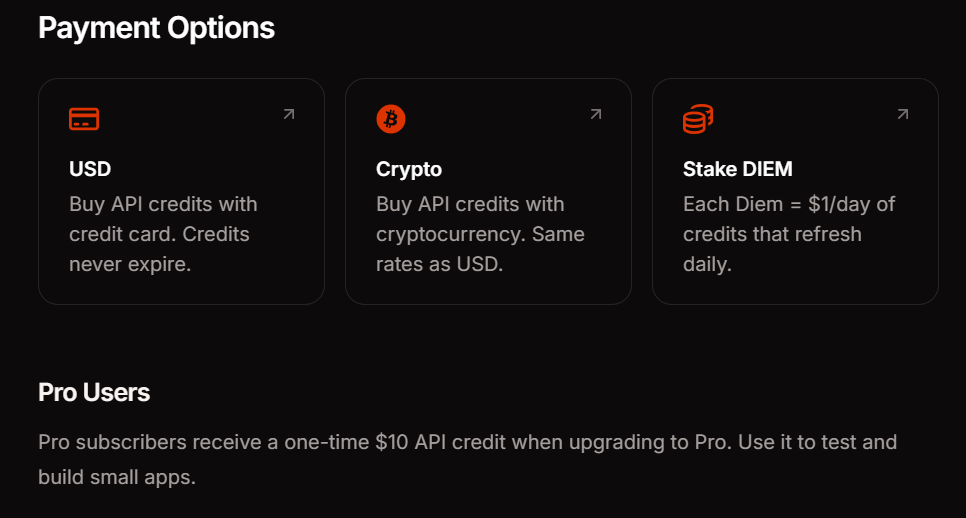
Venice APIの料金と支払いオプション
Veniceは、お客様の利用パターンに合わせた3つの支払い方法を提供しています。Proサブスクリプションは月額18ドルで、10ドルのAPIクレジットと消費者機能での無制限プロンプトが含まれています。DIEMステーキングにはVVVトークンの購入が必要で、これにより永続的な日次計算リソースが提供されます。これは予測可能なトラフィックを持つ大量のアプリケーションに最適です。USD従量課金制では、ドルでアカウントに資金を供給し、必要に応じてクレジットを消費できます。これは実験や変動するワークロードに最適です。
APIアクセスは現在ベータ期間中無料で提供されています。これにより、支払い方法を決定する前に統合パターンを検証し、コストを見積もることができます。使用状況ダッシュボードを監視して、エンドポイントとモデル間でのトークン消費を追跡してください。
モデル選択ガイドライン
機能要件と遅延制約に基づいてモデルを選択してください。プロトタイピングや簡単なクエリには `qwen3-4b` から始めると良いでしょう。これは迅速に応答し、ほとんどのテキスト生成タスクを適切に処理します。高度な推論、コード生成、複雑な指示の_追跡が必要な場合は、`llama-3.3-70b` や `deepseek-ai-DeepSeek-R1` のようなより大きなモデルにアップグレードしてください。ビジョンタスクには `qwen3-vl-235b-a22b` のようなマルチモーダルモデルが必要です。オーディオ生成には特殊な音声モデルが使用されます。`/api/v1/models` エンドポイントをプログラムでクエリしてリアルタイムの利用可能性を確認してください。Veniceは需要とインフラストラクチャの容量に基づいてモデルをローテーションします。
結論
Venice APIは、AI統合の障害を取り除きます。ロックインなしでOpenAI互換性、構成の複雑さなしでプライバシー、予期せぬ請求なしで柔軟な価格設定を提供します。ドロップイン置換アプローチにより、アプリケーションコードを書き換えることなく、現在のプロバイダーと並行してVeniceを評価できます。
Veniceエンドポイントのテスト、認証フローのデバッグ、複数のプロバイダー構成の管理など、API統合を構築する際には、Apidogを使用してワークフローを効率化してください。視覚的なAPIテスト、ドキュメント生成、チームコラボレーションを処理するため、機能の出荷に集中できます。