人工知能は急速に進化し続けており、開発者は今、高度な推論機能を提供するツールを求めています。NVIDIAは、NVIDIA Llama Nemotronモデルファミリーによってこのニーズに応えています。これらのモデルは、複雑な推論を必要とするタスクに優れ、コンピュータ効率を提供し、企業使用のためのオープンライセンスが付いています。開発者はNVIDIAのNIMマイクロサービスから提供されるNVIDIA Llama Nemotron APIを通じてこれらのモデルにアクセスでき、アプリケーションへの統合がシームレスです。
NVIDIA Llama Nemotronモデルの理解
APIに飛び込む前に、NVIDIA Llama Nemotronモデルを見てみましょう。このファミリーには、Nano、Super、Ultraの3つのバリアントが含まれています。それぞれは特定の展開ニーズをターゲットにし、パフォーマンスとリソースの要求のバランスを取っています。
- Nano(8Bパラメータ): エンジニアはこのモデルをエッジデバイスやPC用に最適化しています。最小限の計算力で高精度を提供し、軽量アプリケーションに最適です。
- Super(49Bパラメータ): 開発者はこのモデルを単一GPUセットアップ向けに設計しています。スループットと精度のバランスを取り、適度に複雑なタスクに適しています。
- Ultra(253Bパラメータ): 専門家はこのモデルをマルチGPUデータセンターサーバー用に作成しています。最も要求の厳しいAIエージェントアプリケーション向けに最高レベルの精度を提供します。
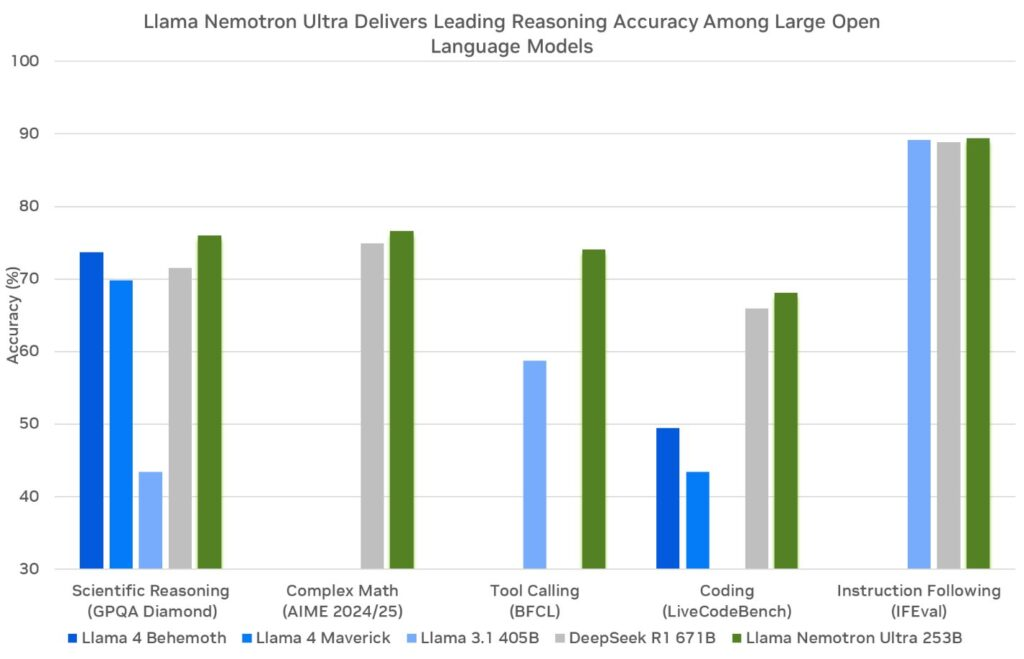
NVIDIAはこれらのモデルをMetaのLlamaフレームワーク上に構築し、蒸留や強化学習のような後処理技術で強化しています。その結果、科学分析、高度な数学、コーディング、指示に従うことなどの推論タスクに優れています。各モデルは128,000トークンのコンテキスト長をサポートしており、長文ドキュメントを処理したり、長期的な対話の文脈を維持したりできます。
注目すべき機能は、システムプロンプトを介して推論をオンまたはオフに切り替えられることです。開発者は複雑なクエリ、例えばトラブルシューティングには推論を有効にし、静的情報を取得するなど単純なタスクには無効にします。この柔軟性はリソースの使用を最適化し、実際のアプリケーションにおいて重要な利点です。
NVIDIA Llama Nemotron APIの設定
NVIDIA Llama Nemotron APIを利用するには、まず設定する必要があります。NVIDIAはこのAPIをNIMマイクロサービスを介して提供しており、クラウド、オンプレミス、またはエッジ環境に展開をサポートしています。開始にあたっては、次の手順を実行してください:
NVIDIA開発者プログラムに参加する: リソース、ドキュメント、およびツールにアクセスするには登録してください。このステップで必要なエコシステムが解放されます。
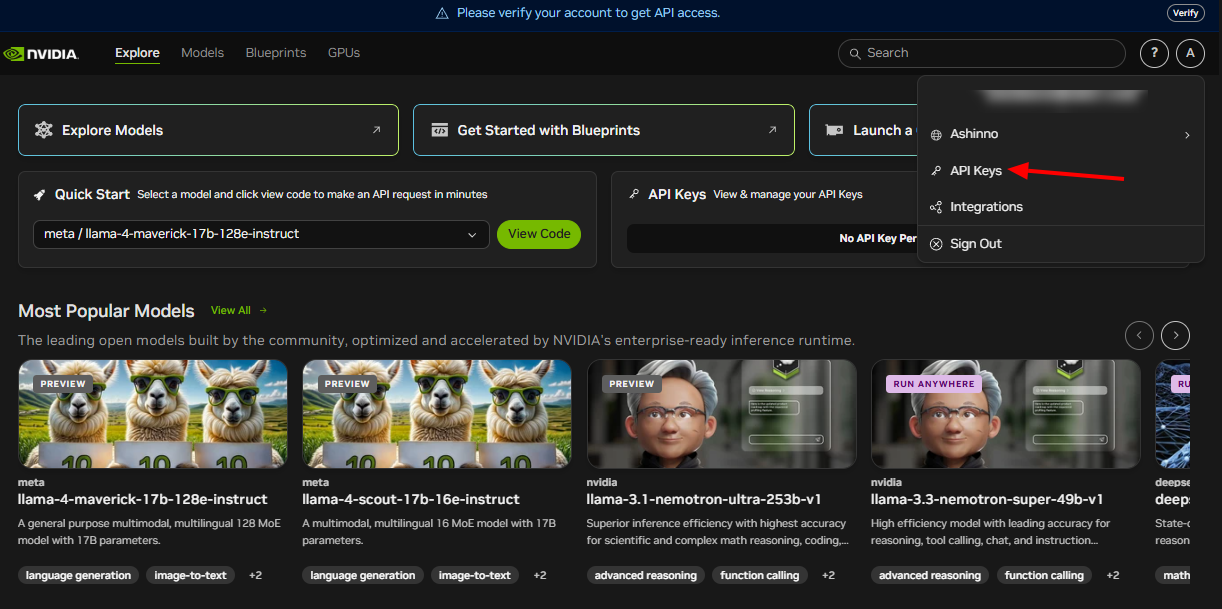
API認証情報を取得する: NVIDIAはAPIキーを提供します。これを使用して、リクエストを安全に認証します。
必要なライブラリをインストールする: Python開発者の場合、HTTPコールを処理するためにrequestsライブラリをインストールします。ターミナルで次のコマンドを実行してください:
pip install requests
これらのステップを完了することで、NVIDIA Llama Nemotron APIと対話するための環境を準備します。次に、リクエストの作成方法を探ります。
APIリクエストの作成
NVIDIA Llama Nemotron APIはRESTful標準に準拠しており、プロジェクトへの統合が簡素化されています。APIエンドポイントにPOSTリクエストを送信し、リクエストボディにパラメータを埋め込みます。具体的な例で分解してみましょう。
以下は、Pythonを使用してAPIにクエリを送る方法です:
import requests
import json
# APIエンドポイントと認証を定義
endpoint = "https://your-nim-endpoint.com/api/v1/generate"
headers = {
"Authorization": "Bearer YOUR_API_KEY",
"Content-Type": "application/json"
}
# リクエストペイロードを作成
payload = {
"model": "llama-nemotron-super",
"prompt": "'ストロベリー'という言葉にはRがいくつありますか?",
"max_tokens": 100,
"temperature": 0.7,
"reasoning": "on"
}
# リクエストを送信
response = requests.post(endpoint, headers=headers, data=json.dumps(payload))
# レスポンスを処理
if response.status_code == 200:
result = response.json()
print(result["text"])
else:
print(f"エラー: {response.status_code} - {response.text}")
重要なパラメータの説明
model: モデルのバリアントを指定—Nano、Super、またはUltra。展開に基づいて選択します。prompt: モデルが処理するための入力テキストを提供します。max_tokens: トークンでのレスポンスの長さを制限します。出力サイズを調整するためにこれを変更します。temperature: 0から1までの範囲です。低い値(例:0.5)は予測可能な出力を生み出し、高い値(例:0.9)は創造性を高めます。reasoning: 推論機能を切り替えます。複雑なタスクには「on」に、単純なものには「off」に設定します。
たとえば、推論を有効にすることで数学の問題を解くようなタスクに適しますが、無効にすると基本的な検索に適します。多様性の制御のためにtop_pや、特定のトークンで生成を停止するためのstop_sequencesのようなパラメータを追加することもできます。例えば、"\n\n"などです。
以下は拡張例です:
payload = {
"model": "llama-nemotron-super",
"prompt": "プログラミングにおける再帰について説明してください。",
"max_tokens": 200,
"temperature": 0.6,
"top_p": 0.9,
"reasoning": "on",
"stop_sequences": ["\n\n"]
}
このリクエストは、ダブルニューラインで停止し、再帰の詳細な説明を生成します。Apidogのようなツールは、これらのリクエストを効率的にテストして洗練させるのに役立ちます。
APIレスポンスの処理
リクエストを送信した後、NVIDIA Llama Nemotron APIはJSONレスポンスを返します。これには生成されたテキストとメタデータが含まれます。以下はサンプルレスポンスです:
{
"text": "'ストロベリー'という言葉にはRが3つあります。",
"tokens_generated": 10,
"time_taken": 0.5
}
text: モデルの出力を含みます。tokens_generated: 生成されたトークンの数を示します。time_taken: 生成にかかった時間を秒単位で測ります。
常にステータスコードを確認してください。200コードは成功を示し、JSONを解析できるようになっています。エラーは400または500のようなコードを返し、デバッグのためにレスポンスボディに詳細が含まれます。生産環境での堅牢性を確保するために、再試行やフォールバックなどのエラーハンドリングを実装してください。
たとえば、前のコードを拡張します:
if response.status_code == 200:
result = response.json()
print(f"レスポンス: {result['text']}")
print(f"使用されたトークン: {result['tokens_generated']}")
else:
print(f"失敗: {response.text}")
# 必要に応じて再試行ロジックを追加
このアプローチは、さまざまな条件下でアプリケーションを信頼性の高いものに保ちます。
ベストプラクティスとユースケース
NVIDIA Llama Nemotron APIの潜在能力を最大化するために、以下のベストプラクティスを採用してください:
- リソース使用の最適化: 複雑なタスクのみに推論を有効にします。これにより、計算コストが大幅に削減されます。
- パフォーマンスの監視:
time_takenを追跡してリアルタイムアプリケーションでもタイムリーな応答を確保します。 - パラメータの調整:
temperatureやmax_tokensを調整して創造性と精度のバランスを取ります。 - 認証情報の保護: APIキーを環境変数やセキュアなボールトに保存し、コード内には決して保存しないでください。
- バッチリクエスト: 複数のプロンプトを一度のコールで処理して効率を高めます。
実用的なユースケース
このAPIの多用途性は、さまざまなアプリケーションをサポートします:
- 顧客サポート: トラブルシューティングなど複雑なクエリを解決するチャットボットを開発します。
- 教育: 段階的な論理で微積分の概念を説明するチューターを構築します。
- 研究: 科学者がデータを分析したり仮説を作成したりするのを支援します。
- ソフトウェア開発: 自然言語の入力に基づいてコードを生成したりスクリプトをデバッグします。
コーディングの例:
payload = {
"model": "llama-nemotron-super",
"prompt": "階乗を計算するPython関数を書いてください。",
"max_tokens": 200,
"temperature": 0.5,
"reasoning": "on"
}
モデルは以下のように返すかもしれません:
def factorial(n):
if n == 0 or n == 1:
return 1
return n * factorial(n - 1)
これは、再帰的ロジックを推論する能力を示しています。Apidogは、このようなAPIコールをテストし、正確性を確保するのに役立ちます。
結論
NVIDIA Llama Nemotron APIは、開発者が強力な推論機能を持つ高度なAIエージェントを作成できるようにします。トグル可能な推論機能はパフォーマンスを最適化し、Nano、Super、Ultraモデル全体でのスケーラビリティは多様なニーズに対応します。チャットボット、教育ツール、コーディングアシスタントを構築するかどうかにかかわらず、このAPIは柔軟性と力を提供します。
さらに、Apidogのようなツールと統合することでワークフローが向上します。エンドポイントをテストし、レスポンスを検証し、迅速に反復して革新に注力できます。AIが進化する中、NVIDIA Llama Nemotron APIを習得することで、この変革的な分野の最前線に立つことができます。