
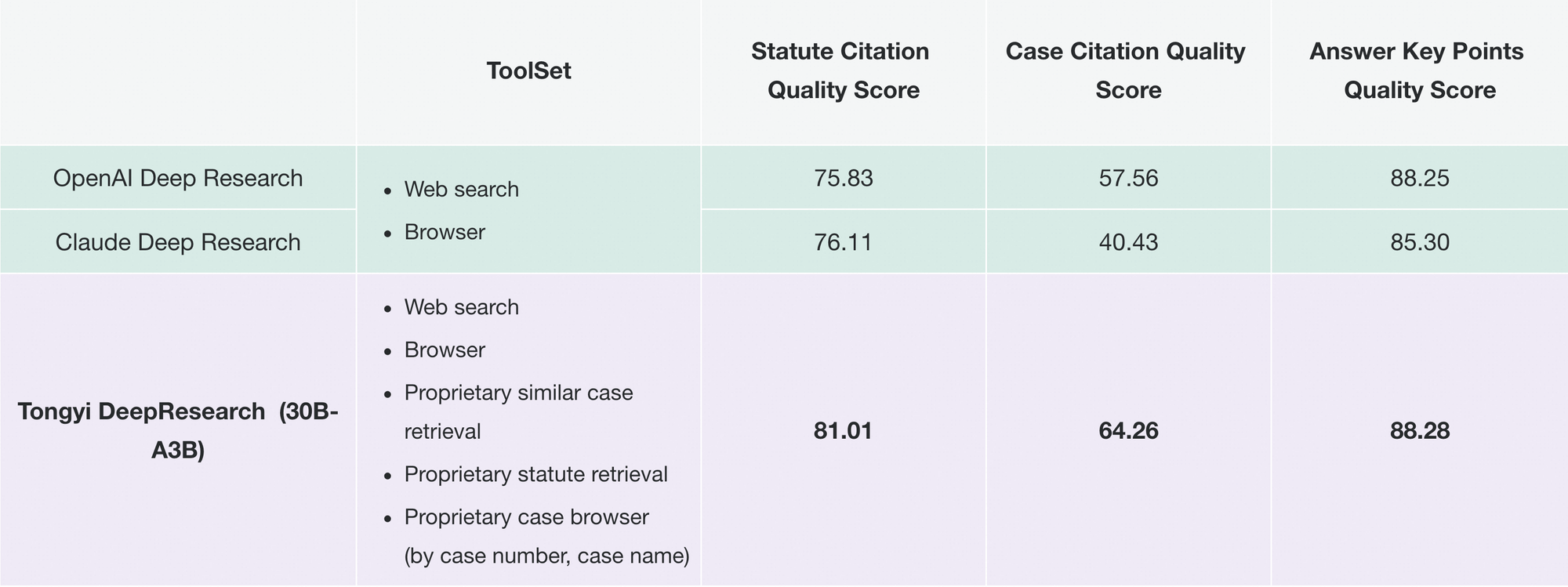
アリババの通義DeepResearchは、300億パラメータのMixture of Experts (MoE) モデルにより自律型AIエージェントを再定義します。このモデルはトークンあたりわずか30億パラメータをアクティブ化することで、効率的で高精度なWebリサーチを実現します。このオープンソースの強力なシステムは、Humanity's Last Exam (32.9% vs. OpenAI o3の24.9%) やxbench-DeepSearch (75.0% vs. 67.0%) といったベンチマークを圧倒し、開発者が法務分析から旅行計画まで、複雑な多段階クエリに独自のロックインなしで取り組むことを可能にします。
通義ラボのエンジニアは、長期間にわたる推論と動的なツール使用に正面から取り組むために、このエージェントを設計しました。その結果、Hugging Faceを介してローカルで実行しながら、実際の合成においてクローズドモデルを上回る性能を発揮します。この技術解説では、そのスパースアーキテクチャ、自動データパイプライン、RL最適化トレーニング、ベンチマークでの優位性、およびデプロイメントのハックについて詳しく説明します。読み終える頃には、Tongyi DeepResearchとApidogのようなツールが、あなたのプロジェクトのためにスケーラブルなエージェントAIをどのように解放するかを理解できるでしょう。
Tongyi DeepResearchの理解:核となる概念とイノベーション
Tongyi DeepResearchは、深い情報検索と合成に焦点を当てることで、エージェントAIを再定義します。短い形式の生成に優れる従来の大規模言語モデル(LLM)とは異なり、このエージェントは、Webブラウザのような動的な環境をナビゲートし、微妙な洞察を明らかにします。具体的には、Mixture of Experts (MoE) アーキテクチャを採用しており、300億の全パラメータのうち、トークンあたりわずか30億が選択的にアクティブ化されます。この効率性により、リソースに制約のあるハードウェアでも堅牢なパフォーマンスを発揮し、128Kトークンまでの高い文脈認識能力を維持します。
さらに、このモデルは人間のような意思決定を模倣する推論パラダイムとシームレスに統合されています。ReActモードでは、思考、行動、観察のステップをネイティブに循環し、複雑なプロンプトエンジニアリングを不要にします。より要求の厳しいタスクの場合、HeavyモードはIterResearchフレームワークを起動し、並列エージェント探索を調整してコンテキストの過負荷を回避します。その結果、ユーザーは学術文献レビューや市場分析など、反復的な洗練を必要とするシナリオで優れた成果を達成します。
Tongyi DeepResearchを際立たせているのは、そのオープン性へのコミットメントです。モデルの重みからトレーニングコードまで、スタック全体がHugging FaceやGitHubのようなプラットフォームに存在します。開発者はTongyi-DeepResearch-30B-A3Bバリアントに直接アクセスでき、ドメイン固有のニーズに合わせたファインチューニングを容易にします。さらに、標準的なPython環境との互換性により、参入障壁が低減されます。例えば、Python 3.10でConda環境をセットアップした後、簡単なpipコマンドでインストールできます。
実用的な側面では、Tongyi DeepResearchは検証可能な出力を要求するアプリケーションを強化します。法務調査では、法令や判例を解析し、正確な情報源を引用します。同様に、旅行計画では、リアルタイムデータを相互参照して複数日の旅程を作成します。これらの機能は、意図的な設計哲学、すなわち単なる予測よりもエージェント的推論を優先するという考え方から生まれています。
Tongyi DeepResearchのアーキテクチャ:効率性とパワーの融合
その核となるTongyi DeepResearchは、スパースなMoE設計を活用し、計算要件と表現力のバランスを取っています。このモデルは、トークンごとにエキスパートのサブセットのみをアクティブ化し、クエリの複雑さに基づいて入力を動的にルーティングします。このアプローチにより、密なモデルと比較してレイテンシが最大90%削減され、リアルタイムのエージェントデプロイメントに実行可能となります。さらに、128Kのコンテキストウィンドウは拡張されたインタラクションをサポートしており、長いドキュメントチェーンやスレッド化されたWeb検索を伴うタスクにとって重要です。
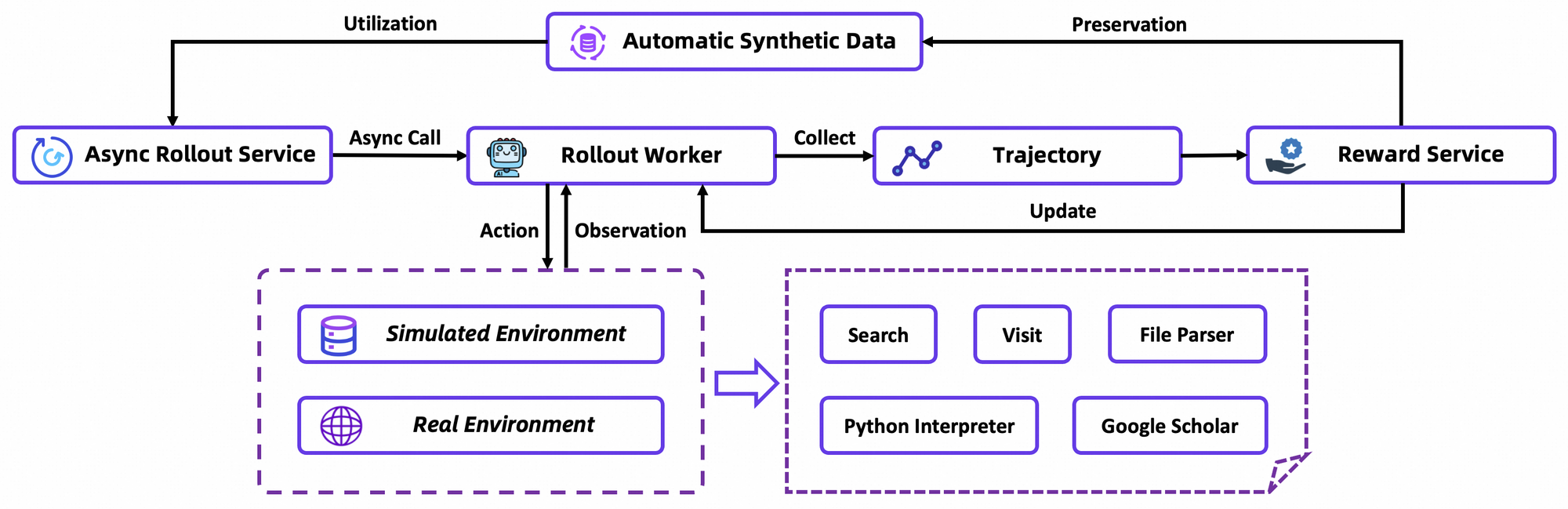
主要なアーキテクチャコンポーネントには、アクションプレフィックスや観察区切り文字などのエージェントトークン用に最適化されたカスタムトークナイザーと、ブラウザナビゲーション、検索、計算のための組み込みツールスイートが含まれます。このフレームワークは、エージェントが安定した環境でのシミュレートされたロールアウトから学習するオンポリシー強化学習(RL)統合をサポートしています。その結果、ツール使用ベンチマークでの高得点が示すように、このモデルはツール呼び出しにおける幻覚が少なくなっています。
さらに、Tongyi DeepResearchは、グラフベースのデータ合成から派生したエンティティアンカー型知識メモリを組み込んでいます。このメカニズムは、応答を事実に基づくエンティティに固定し、追跡可能性を高めます。例えば、量子コンピューティングの進歩に関するクエリ中に、エージェントはWebSailorのようなツールを介して論文を検索・合成し、検証可能な情報源に基づいて出力を生成します。したがって、このアーキテクチャは情報を処理するだけでなく、積極的にキュレーションも行います。
例として、モデルのマルチモーダル入力の処理について考えてみましょう。主にテキストベースですが、GitHubリポジトリを介した拡張により、画像パーサーやコード実行者との統合が可能です。開発者は、推論スクリプトでこれらを構成し、JSONL形式のデータセットのパスを指定します。このように、このアーキテクチャは拡張性を促進し、オープンソースコミュニティからの貢献を歓迎します。
自動データ合成:Tongyi DeepResearchの能力を強化する
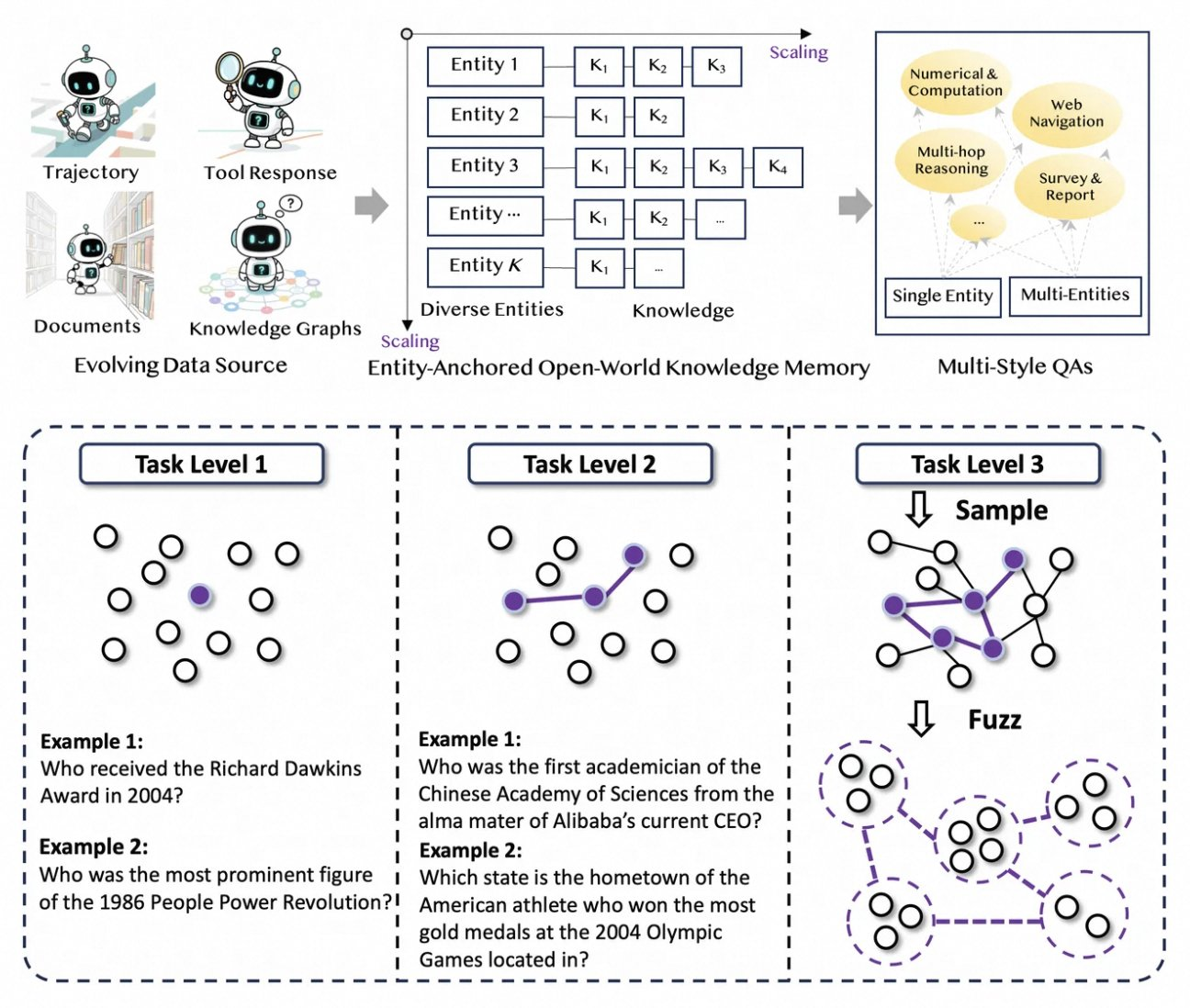
Tongyi DeepResearchは、人間のアノテーションのボトルネックを解消する、斬新で完全に自動化されたデータパイプラインによって発展しています。このプロセスは、生コーパス(ドキュメント、ウェブクロール、知識グラフ)をエンティティアンカー型QAペアに再編成する合成エンジンであるAgentFounderから始まります。このステップは、推論チェーン、ツール呼び出し、決定木をカバーする、継続的な事前学習(CPT)のための多様な軌跡を生成します。
次に、パイプラインは反復的なアップグレードを通じて難易度を上げていきます。後学習では、WebSailor-V2のようなグラフベースの手法を用いて、集合論によってモデル化された博士課程レベルの質問など、「超人的な」課題をシミュレートします。その結果、データセットは数百万の高忠実度なインタラクションに及び、モデルがドメイン全体で一般化することを保証します。特筆すべきは、この自動化が計算量に線形にスケールし、手動でのキュレーションなしに継続的な更新を可能にすることです。
さらに、Tongyi DeepResearchは堅牢性のためにマルチスタイルのデータを取り入れています。アクション合成記録はツール使用パターンを捉え、多段階QAペアは計画スキルを洗練させます。実際には、これによりノイズの多いWeb環境に適応し、無関係なスニペットを効果的にフィルタリングするエージェントが生まれます。開発者向けに、リポジトリはこのパイプラインを再現するためのスクリプトを提供しており、カスタムデータセットの作成を可能にします。
量よりも質を優先することで、この合成戦略は、分布シフトなど、エージェントトレーニングにおける一般的な落とし穴に対処します。その結果、この方法でトレーニングされたモデルは、ベンチマークでの優位性に見られるように、実世界のタスクとの優れた整合性を示します。
エンドツーエンドのトレーニングパイプライン:CPTからRL最適化まで
Tongyi DeepResearchのトレーニングは、エージェントCPT、教師ありファインチューニング(SFT)、強化学習(RL)というシームレスなパイプラインで展開されます。まず、CPTはベースモデルを膨大なエージェントデータにさらし、ウェブナビゲーションの事前知識と鮮度シグナルを注入します。このフェーズでは、軌跡に対するマスク言語モデリングを通じて、暗黙的な計画などの潜在的な能力が活性化されます。

CPTの後、SFTは合成ロールアウトを使用して正確なアクションの定式化を教え、モデルを指示形式に合わせます。ここで、モデルは一貫したReActサイクルを生成し、観察解析におけるエラーを最小限に抑えることを学習します。スムーズに移行し、RL段階では、カスタムのオンポリシーアルゴリズムであるGroup Relative Policy Optimization (GRPO) が採用されます。
GRPOは、リーブワンアウト優位推定を用いてトークンレベルのポリシー勾配を計算し、非定常環境における分散を低減します。また、カスタムシミュレーター(オフラインのWikipediaデータベースとツールサンドボックスを組み合わせたもの)での更新を安定させるために、負のサンプルを慎重にフィルタリングします。rLLMフレームワークを介した非同期ロールアウトは収束を加速させ、控えめな計算量でSOTA(State-of-the-Art)を達成します。
詳細には、RL環境はブラウザのインタラクションを忠実にシミュレートし、単一のアクションよりも多段階の成功に報酬を与えます。これにより、エージェントが部分的な失敗を反復する長期的な計画が促進されます。技術的な注意点として、損失関数は保守性のためにKLダイバージェンスを組み込んでおり、モード崩壊を防ぎます。開発者は、リポジトリの評価スクリプトを介してこれを再現し、カスタムポリシーのベンチマークを行うことができます。
全体として、このパイプラインは画期的なものです。サイロ化することなく事前学習とデプロイメントを結びつけ、試行錯誤を通じて進化するエージェントを生み出します。
ベンチマーク性能:Tongyi DeepResearchがいかに優れているか
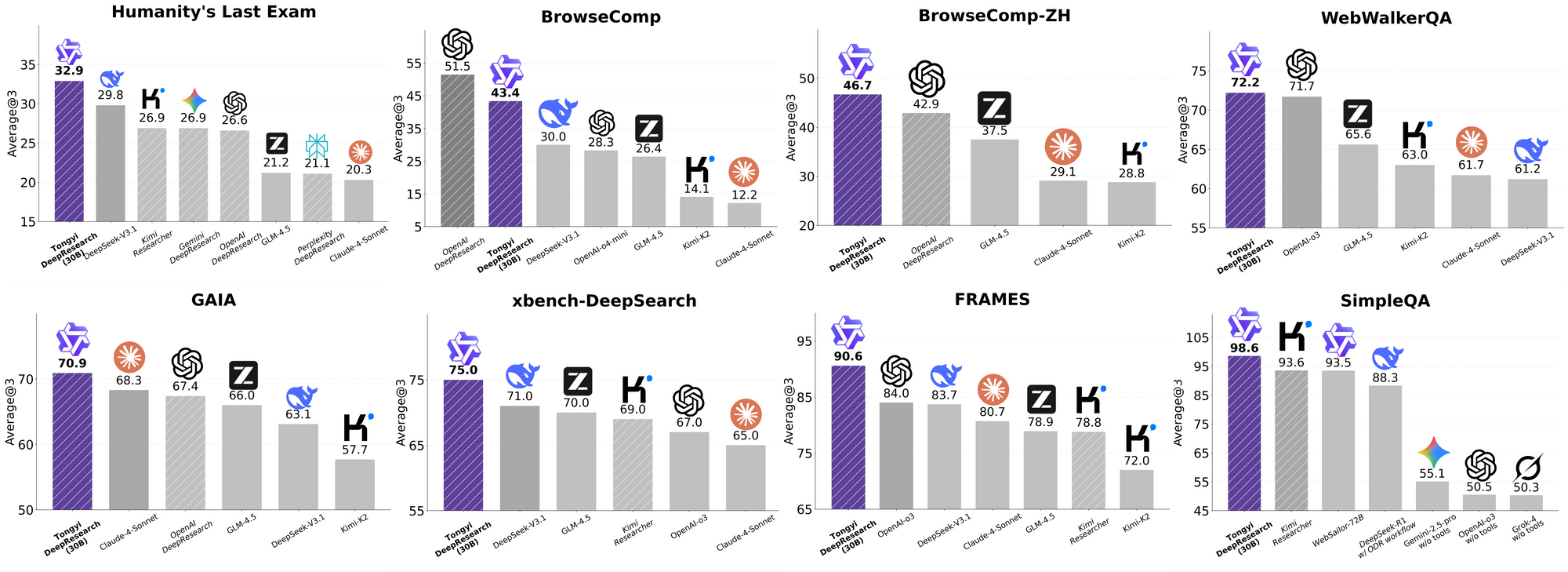
Tongyi DeepResearchは、厳格なエージェントベンチマークで輝かしい成績を収め、その設計の正当性を証明しています。学術的推論のテストであるHumanity's Last Exam (HLE) では、ReActモードで32.9点を記録し、OpenAIのo3の24.9点を上回りました。この差はHeavyモードでは38.3点に広がり、IterResearchの有効性を強調しています。
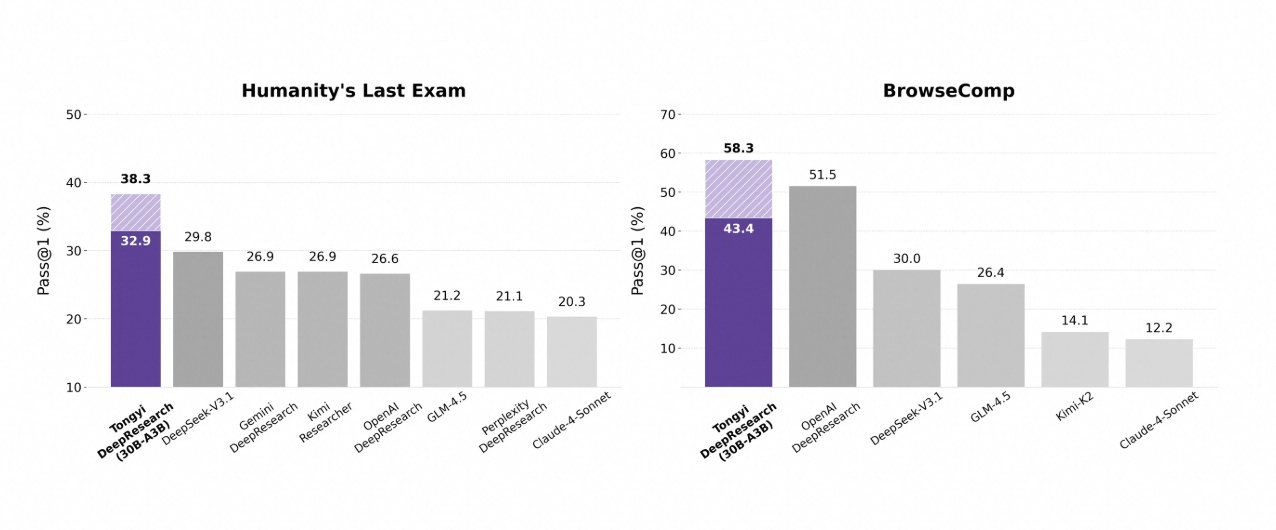
同様に、BrowseCompは複雑な情報探索を評価するもので、Tongyiは効率性において43.4点(英語)と46.7点(中国語)を達成し、o3の49.7点と58.1点にそれぞれ肉薄しています。深いクエリにユーザー中心のxbench-DeepSearchベンチマークでは、Tongyiが75.0点に対しo3が67.0点となり、優れた検索合成能力を強調しています。
他の指標もこれを裏付けています。FRAMESで90.6点(o3の84.0点に対し)、GAIAで70.9点、SimpleQAで95.0点です。比較チャートはこれらを視覚化しており、Tongyi DeepResearchの棒グラフがHLE、BrowseComp、xbench、FRAMESなどのベンチマークでGemini、Claude、その他のモデルを凌駕しています。青い棒グラフはTongyiの優位性を示し、灰色のベースラインは競合他社の不足を示しています。
これらの結果は、検索タスクのための選択的エキスパートルーティングのような、ターゲットを絞った最適化に起因しています。したがって、Tongyi DeepResearchは競争するだけでなく、オープンソースのエージェントAI分野をリードしています。
Tongyi DeepResearchと業界リーダーの比較
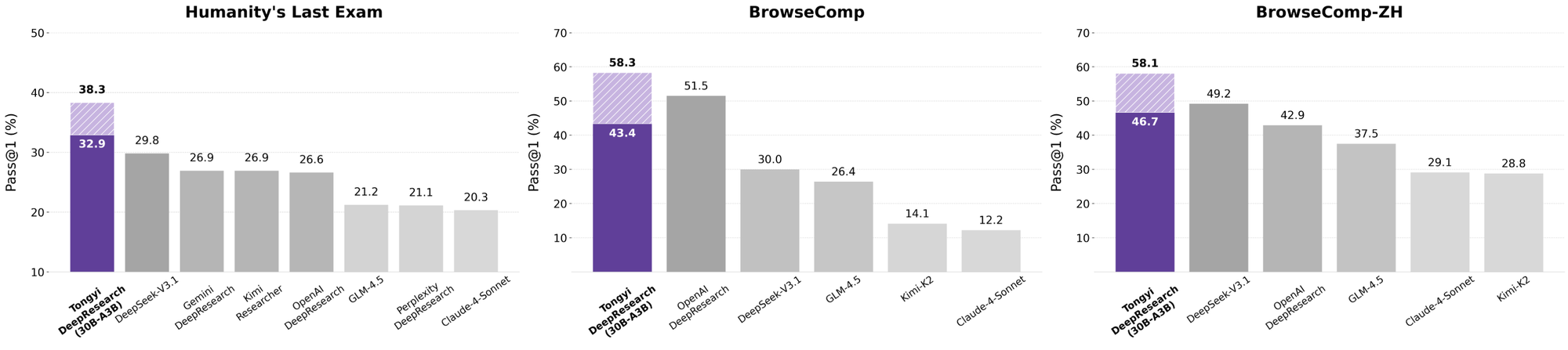
開発者がAIエージェントを評価する際、比較によって真の価値が明らかになります。30B-A3BのTongyi DeepResearchは、o3の規模が大きいにもかかわらず、HLE(32.9対24.9)とxbench(75.0対67.0)でOpenAIのo3を上回っています。GoogleのGeminiに対しては、BrowseComp-ZHで35.2点を記録し、10ポイントの差をつけています。
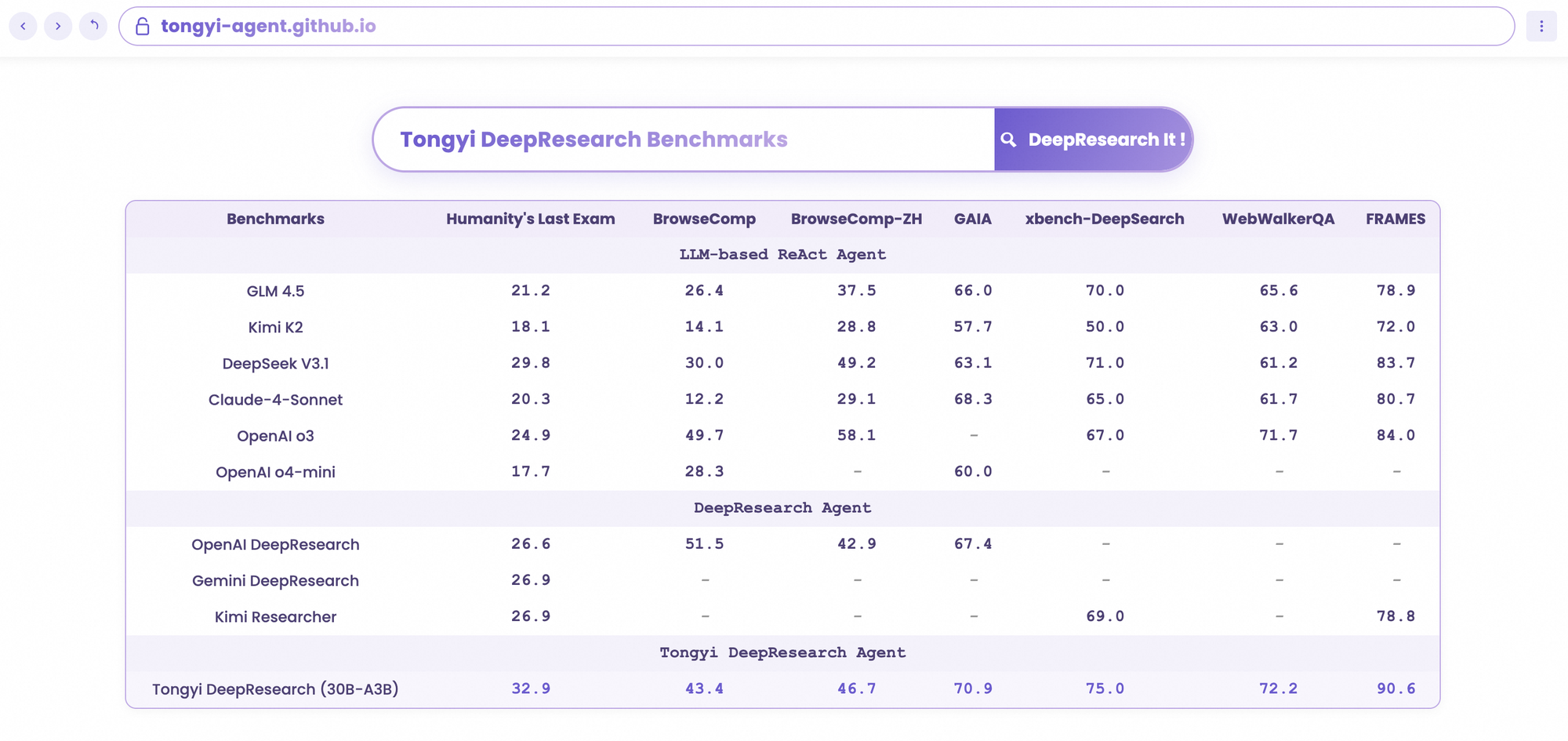
Claude 3.5 Sonnetのようなプロプライエタリモデルはツール使用で遅れをとっており、FRAMESでのTongyiの90.6点はSonnetの84.3点を大きく上回っています。Llamaの派生モデルのようなオープンソースの競合はさらに後塵を拝しており、例えばHLEでは21.1点です。TongyiのMoEスパース性により、この同等性が実現され、推論計算量が少なくて済みます。
さらに、アクセシビリティが優位性を決定づけます。o3がAPIクレジットを要求するのに対し、TongyiはHugging Faceを介してローカルで実行されます。APIを多用するワークフローでは、Apidogと組み合わせてエンドポイントをモックし、ツール呼び出しを効率的にシミュレートできます。
本質的に、Tongyi DeepResearchはエリートレベルのパフォーマンスを民主化し、クローズドなエコシステムに挑戦しています。
実世界での応用:Tongyi DeepResearchの活用
Tongyi DeepResearchはベンチマークを超越し、具体的な影響をもたらします。アリババのナビゲーションアプリGaode Mateでは、Heavyモードを介してフライト、ホテル、イベントを並行して照会し、複雑な旅行を計画します。ユーザーは引用付きの合成された旅程を受け取り、計画時間を70%削減します。
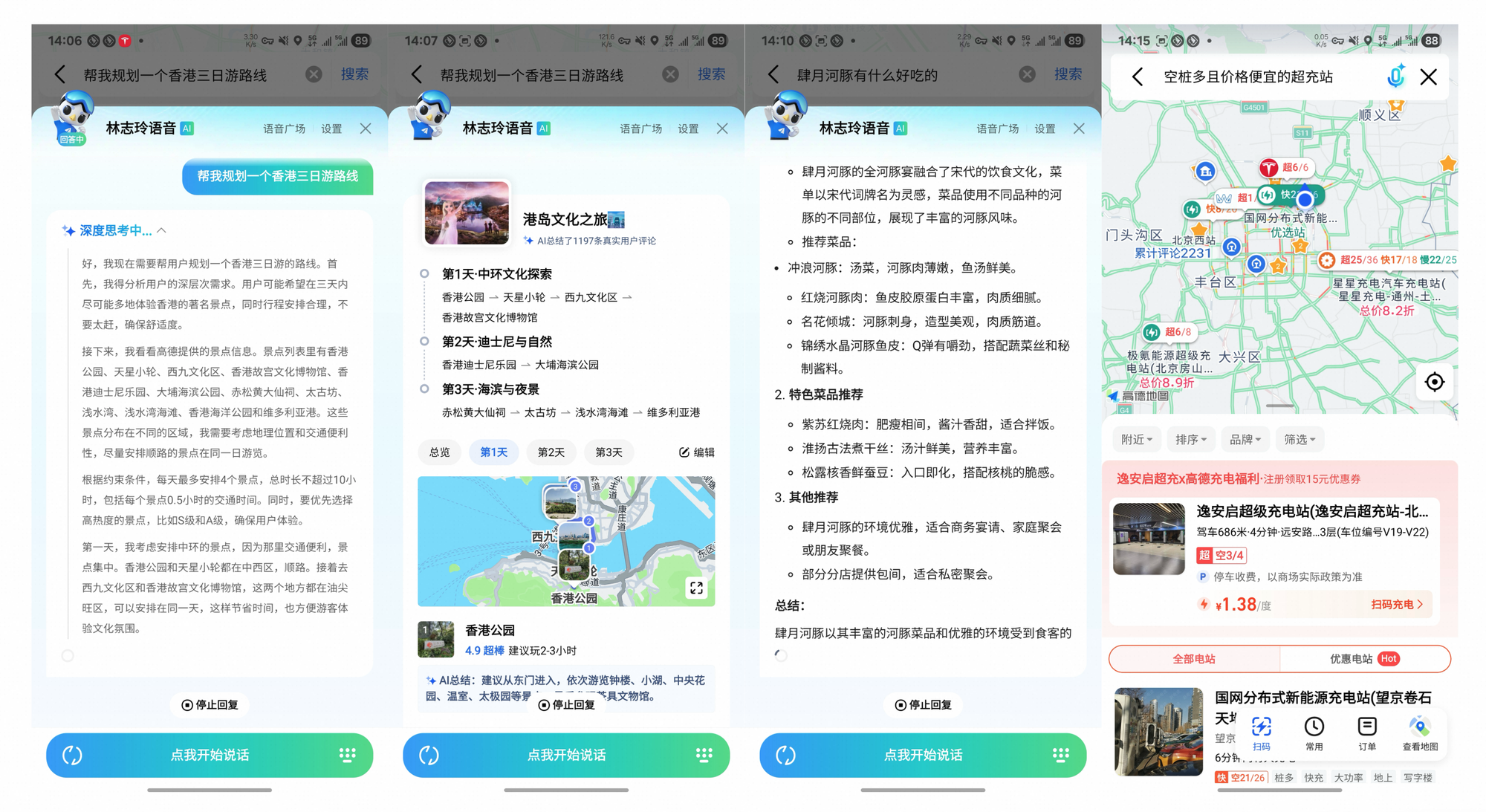
同様に、Tongyi FaRuiは法務調査に革命をもたらします。このエージェントは、法令を分析し、判例を相互参照し、検証可能なリンク付きの要約を作成します。専門家は出力を迅速に検証し、高リスクな分野でのエラーを最小限に抑えます。
これらに加えて、企業は市場インテリジェンスのためにこれを適応させています。競合他社のデータをスクレイピングし、トレンドを合成します。リポジトリのモジュール性はこのような拡張をサポートしており、JSON設定を介してカスタムツールを追加できます。
採用が進むにつれて、Tongyi DeepResearchはLangChainのようなエコシステムに統合され、エージェントスワームを増幅させています。API開発者にとって、Apidogはデプロイ前の統合を検証することでこれを補完します。
これらの事例はスケーラビリティを示しています。消費者向けアプリからB2Bツールまで、このモデルは信頼性の高い自律性を提供します。
Tongyi DeepResearchの始め方:開発者ガイド
Tongyi DeepResearchは、そのGitHubリポジトリを使って簡単に実装できます。まず、Conda環境を作成します: conda create -n deepresearch python=3.10。アクティブ化してインストールします: pip install -r requirements.txt。
eval_data/にJSONL形式でデータを準備し、questionとanswerキーを含めます。ファイルの場合、質問に名前を前置し、file_corpus/に保存します。モデルパス(例:Hugging Face URL)とツール用のAPIキーについては、run_react_infer.shを編集します。
実行します: bash run_react_infer.sh。出力は指定されたパスに保存され、分析の準備が整います。
Heavyモードの場合、コード内でIterResearchパラメータを設定します。エージェント数とラウンドを設定します。evaluation/スクリプトを介してベンチマークを行い、ベースラインと比較します。
ログでトラブルシューティングを行います。トークナイザーの不一致などの一般的な問題は、BF16テンソルチェックを介して解決されます。機能を強化するには、Apidogを無料でダウンロードしてAPIシミュレーションを行い、ライブ呼び出しなしでツールエンドポイントをテストしてください。
このセットアップにより、エージェントを迅速にプロトタイプ化する準備が整います。
今後の展望:Tongyi DeepResearchのさらなるスケールアップ
今後、通義ラボは128Kを超えるコンテキスト拡張を目指しており、書籍規模の分析のような超長期間の処理を可能にします。彼らは、より大規模なMoEベースでの検証を計画しており、スケーラビリティの限界を探っています。
RLの強化には、効率性のための部分的なロールアウトや、シフトを軽減するためのオフポリシー手法が含まれます。コミュニティからの貢献により、ビジョンや多言語ツールが統合され、適用範囲が広がる可能性があります。
オープンソースが進化するにつれて、Tongyi DeepResearchは共同の進歩の要となり、AGI(汎用人工知能)の追求を促進するでしょう。
結論:Tongyi DeepResearch時代を受け入れよう
Tongyi DeepResearchは、効率性、オープン性、そして優れた能力を融合させ、エージェントAIを変革します。そのベンチマーク、アーキテクチャ、およびアプリケーションは、OpenAIの提供する製品のような競合他社を凌駕し、リーダーとしての地位を確立しています。開発者の皆さん、この力を活用してください。モデルをダウンロードし、実験し、Apidogと統合してシームレスなAPIを実現しましょう。
自律性へと向かう分野において、Tongyi DeepResearchは進歩を加速させます。今日から構築を始めましょう。洞察があなたを待っています。