
人工知能の分野は、情報を処理するだけでなく、行動することができるエージェントに向かってますます進化しています。この領域で登場するのが、自然言語の指示を理解し、複雑な現実のタスクをあなたの代わりに直接実行することができるデジタルコンパニオンとして設計された、魅力的なオープンソースの汎用AIエージェントであるSuna AIです。Kortix AIによって開発され、許可されたApache 2.0ライセンスの下でリリースされたSunaは、ユーザーの意図と具体的なデジタルアクションとのギャップを埋めることを目的として、強力なツール群と会話インターフェースを組み合わせることで独自性を発揮しています。
Sunaの強みは、専用のAIツールとは異なり、その多様性にあります。これは、会話のプロンプトによって駆動される様々な機能をオーケストレーションできるように構築されており、ウェブを閲覧したり、ファイルを管理したり、コードを実行したり、APIと対話したりすることができます。この記事では、Sunaの中核的な機能とアーキテクチャの概要を提供し、自己のインスタンスをローカルでセットアップして実行する方法について詳細なステップバイステップのチュートリアルを続けることで、この強力なAIエージェントを自分の環境内で活用できるようにします。
開発者チームが最大の生産性で協力するための統合されたオールインワンプラットフォームが欲しいですか?
Apidogはすべての要求を満たし、Postmanをより手頃な価格で代替します!

Suna AIとは何で、Suna AIはどのように機能しますか?
Sunaが何をできるのかを理解するためには、彼女が扱うツールを把握することが不可欠です。これらの機能により、Sunaは人間のユーザーのようにデジタル世界と相互作用しますが、自動化され、AIによって駆動されます。
- ブラウザー自動化(Playwright経由): Sunaは、セキュアな環境内でウェブブラウザーインスタンスを起動し、制御することができます。これにより、特定のURLにナビゲートし、ウェブサイトにログイン(安全に提供された場合)、ボタンをクリックし、フォームに記入し、ページをスクロールし、特に、ウェブページコンテンツからデータを直接抽出することができます。この機能により、ウェブ上での自動化に利用できる膨大な情報と機能が解放されます。
- ファイル管理: エージェントは、ウェブデータだけに制限されません。彼女は、サンドボックス環境内でファイルシステムと相互作用する能力を持っています。これには、新しいファイル(レポートやデータエクスポートなど)を作成し、既存のドキュメントを読み、その内容を編集し、ファイルをディレクトリに整理することが含まれます。これは、出力を生成したり、ローカルデータを処理したりするタスクにとって重要です。
- ウェブクロール&強化検索: 単一ページのブラウジングを超えて、Sunaはウェブサイトを体系的にクロール(リンクを辿って)し、包括的な情報を収集できます。また、専用の検索API(オプションのTavily統合など)と統合することで、標準的な検索エンジンの使用よりも洗練されたターゲットを絞った情報取得を行い、より深いリサーチ能力を提供します。
- コマンドライン実行: セキュアなDockerコンテナ内で、Sunaはシェルコマンドを実行する能力を持っています。この強力な機能により、スクリプトを実行し、他のコマンドラインユーティリティを利用し、システムリソース(コンテナの制限内)と相互作用し、適切に構成されていればソフトウェアビルドやデプロイメントのようなタスクを自動化することが可能です。ここでセキュリティは非常に重要であり、隔離された環境で管理されます。
- API統合(RapidAPI&直接呼び出し経由): Sunaは外部アプリケーションプログラミングインターフェース(API)に呼び出しを行うことができます。これにより、第三者サービスの広大なエコシステムに接続できます。ドキュメンテーションはオプションのRapidAPI統合を強調し、LinkedInデータ、財務情報など、さまざまなデータプロバイダへのアクセスを可能にしますが、他のRESTful APIと直接相互作用するようにも構成でき、データ収集とアクションの可能性を大幅に拡張します。
- コード解釈: Sunaには、安全な環境内でコードスニペット(主にPython)を実行する能力が含まれています。これは、既存のスクリプトを実行するだけでなく、エージェントが動的に生成したコードを実行して複雑な計算やデータ分析、カスタムロジック処理、あるいは他のツールの能力を超える変換を行うことを可能にします。
Sunaの真の力は、AIがユーザーの要求に基づいて適切にこれらのツールを選択し、シーケンスを構築する能力にあります。単一の指示が、ウェブを検索し、データを抽出し、解釈されたコードで処理し、その結果をファイルにフォーマットし、保存する、エージェントによって管理されるワークフローをトリガーする可能性があります。
Sunaのアーキテクチャ:関与するコンポーネント
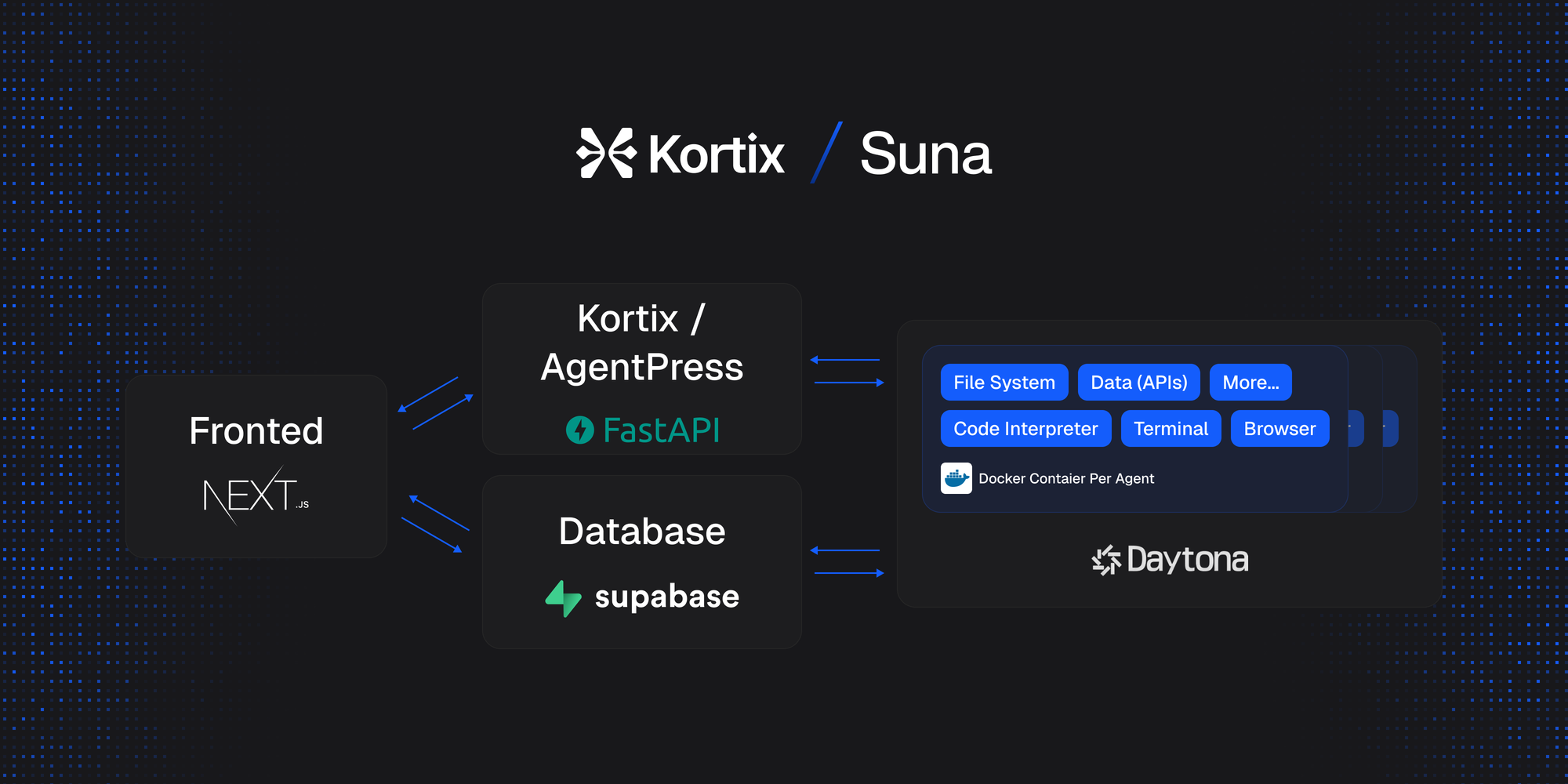
セットアッププロセスを理解するためには、Sunaの主なアーキテクチャコンポーネントの基本を把握する必要があります:
- バックエンドAPI(Python/FastAPI): コアロジックはここに存在します。ユーザーのリクエストを管理し、会話の状態を維持し、エージェントのツールの使用をオーケストレーションし、選択された大規模言語モデル(LLM)との通信をLiteLLM経由で処理します(OpenAIやAnthropicのようなプロバイダとの柔軟性を提供)。
- フロントエンド(Next.js/React): これはユーザー向けのウェブアプリケーションです。Sunaと相互作用するためのチャットインターフェースを提供し、結果を表示し、エージェントの活動を監視するためのダッシュボード要素を含みます。
- エージェントDocker環境(Daytona経由): セキュリティと隔離は重要です。各エージェントタスクは、Daytonaによって管理される専用のDockerコンテナ内で実行されます。このサンドボックスには、必要なすべてのツール(ブラウザー、コードインタプリタ、ファイルシステムアクセス)が含まれ、エージェントがホストシステムに干渉することを防ぎます。
- Supabaseデータベース(PostgreSQL): ユーザーアカウントや認証、会話履歴、エージェントによって生成されたファイルの保存、エージェントの状態追跡、さらには分析を含む、すべてのデータ永続化ニーズを処理します。
これらのコンポーネントは共同で働き、APIを介して通信し、Sunaの体験を提供します。自己ホスティングのセットアップには、これらの相互接続されたパーツを構成し、実行することが含まれます。
Suna AIをセットアップする方法
 kortix-ai
kortix-aiSunaを自分で実行することで、最大の制御とプライバシーを提供します。以下の手順がセットアッププロセスを案内します:
フェーズ1: 前提条件を集める
Sunaをインストールする前に、いくつかの外部サービスと資格情報が必要です:
Supabaseプロジェクト:
- supabase.comでサインアップまたはログインし、新しいプロジェクトを作成します。
- プロジェクトの設定 > APIに移動します。プロジェクトURL、
anon公共キー、およびservice_role秘密キーを注意深くコピーします。 - Supabase CLIをインストールします: supabase.com/docs/guides/cliの指示に従います。
Redisデータベース:
- オプション1(クラウド - 推奨): Upstashのようなサービスを利用します(無料プランあり)。データベースを作成し、そのホスト/エンドポイント、ポート、パスワードを記録し、SSL/TLSが必要か確認します(通常は必要です)。
- オプション2(ローカル): ローカルにRedisをインストールします(例:
brew install redison macOS、sudo apt install redis-serveron Debian/Ubuntu、またはDocker/WSL経由でWindows上で)。ホスト(localhost)、ポート(通常は6379)、パスワード(通常はなし)、およびSSL設定(False)をメモします。
Daytonaアカウントとイメージ構成:
- daytona.ioにサインアップします。
- 設定 > APIキーに移動し、新しいAPIキーを生成します。コピーします。
- 画像セクションに移動します。画像追加をクリックします。
- 画像名:
adamcohenhillel/kortix-suna:0.0.20 - エントリポイント:
/usr/bin/supervisord -n -c /etc/supervisor/conf.d/supervisord.conf - このイメージ構成を保存します。
LLM APIキー:
- OpenAI(platform.openai.com)またはAnthropic(console.anthropic.com)のいずれかを選択します。選択したプロバイダからAPIキーを取得します。
- 使用予定の具体的なモデル識別子(例:
gpt-4o、anthropic/claude-3-5-sonnet-latest)をメモします。
(オプション)Tavily APIキー: より良い検索結果を得るために。Tavily AIからキーを取得します。
(オプション)RapidAPIキー: 必要なプリビルドされた統合を使用する場合(特定のウェブスクレイパーなど)。
- rapidapi.comからキーを取得します。
- Sunaツールが使用する可能性のある特定のAPI(例: LinkedInスクレイパー)にRapidAPIマーケットプレイスで加入することを忘れないでください。関連するツールコードや必要なAPIのベースURLは
backend/agent/tools/data_providers/ディレクトリで確認できます。
フェーズ2: インストールと設定
次に、Sunaアプリケーションコンポーネントを設定します:
リポジトリをクローン:
git clone https://github.com/kortix-ai/suna.git
cd suna
バックエンドの設定(.env):
cd backendcp .env.example .env(例が欠けている場合は.envを作成)。- フェーズ1の資格情報を使用して
.envを編集します:
NEXT_PUBLIC_URL="http://localhost:3000" # または異なる場合はフロントエンドのURL
# Supabase
SUPABASE_URL=YOUR_SUPABASE_URL
SUPABASE_ANON_KEY=YOUR_SUPABASE_ANON_KEY
SUPABASE_SERVICE_ROLE_KEY=YOUR_SUPABASE_SERVICE_ROLE_KEY
# Redis
REDIS_HOST=YOUR_REDIS_HOST
REDIS_PORT=YOUR_REDIS_PORT
REDIS_PASSWORD=YOUR_REDIS_PASSWORD # なしの場合は空白
REDIS_SSL=True # またはローカルの非SSL RedisのためにFalse
# Daytona
DAYTONA_API_KEY=YOUR_DAYTONA_API_KEY
DAYTONA_SERVER_URL="https://app.daytona.io/api"
DAYTONA_TARGET="us" # またはあなたの地域
# --- LLM設定(いずれか一方のセットを記入)---
# Anthropicの例:
ANTHROPIC_API_KEY=YOUR_ANTHROPIC_API_KEY
MODEL_TO_USE="anthropic/claude-3-5-sonnet-latest" # または他のClaudeモデル
OPENAI_API_KEY=
# OpenAIの例:
# ANTHROPIC_API_KEY=
# OPENAI_API_KEY=YOUR_OPENAI_API_KEY
# MODEL_TO_USE="gpt-4o" # または他のOpenAIモデル
# -----------------------------------------
# オプション
TAVILY_API_KEY=YOUR_TAVILY_API_KEY # オプション
RAPID_API_KEY=YOUR_RAPID_API_KEY # オプション
- 重要: 1つのLLMプロバイダ(AnthropicまたはOpenAI)のキーのみを提供してください。
Supabaseデータベーススキーマを設定:
backendディレクトリにいることを確認してください。- ログイン:
supabase login - プロジェクトをリンク:
supabase link --project-ref YOUR_PROJECT_REF_ID(SupabaseダッシュボードからIDを取得)。 - マイグレーションを適用:
supabase db push - スキーマを確認: Supabaseプロジェクトダッシュボードに移動 -> プロジェクト設定 -> API -> スキーマセクションの「設定」の下に、
basejumpが「公開スキーマ」にリストされていることを確認します。欠けている場合は追加して保存します。
フロントエンドの設定(.env.local):
cd ../frontendcp .env.example .env.local(または.env.localを作成)。.env.localを編集します:
NEXT_PUBLIC_SUPABASE_URL=YOUR_SUPABASE_URL # バックエンドの.envと同じ
NEXT_PUBLIC_SUPABASE_ANON_KEY=YOUR_SUPABASE_ANON_KEY # バックエンドの.envと同じ
NEXT_PUBLIC_BACKEND_URL="http://localhost:8000/api" # デフォルトのバックエンドの位置
NEXT_PUBLIC_URL="http://localhost:3000" # デフォルトのフロントエンドの位置
依存関係をインストール:
- フロントエンド(Node.js/npm):
# フロントエンドディレクトリ内で
npm install
- バックエンド(Python 3.11):
# バックエンドディレクトリ内で(仮想環境を使用してください!)
# python -m venv venv
# source venv/bin/activate OR .\venv\Scripts\activate (Windows)
pip install -r requirements.txt
フェーズ3: Sunaを実行する
バックエンドサービスを開始:
- ターミナルを開きます。
path/to/suna/backendに移動します。- 仮想環境を使用している場合は、活性化します(
source venv/bin/activate)。 - 実行:
python api.py - サーバーが実行されているという確認を探します(おそらくポート8000で)。
フロントエンドサービスを開始:
- 2つ目のターミナルを開きます。
path/to/suna/frontendに移動します。- 実行:
npm run dev - サーバーが実行されているという確認を探します(おそらくポート3000で)。
あなたのSunaインスタンスにアクセス:
- ウェブブラウザーを開いて
http://localhost:3000に移動します。 - サインアップオプションを使用してユーザーアカウントを作成します(Supabase Authを利用)。
- ログインして自己ホストされたSunaエージェントに指示を出し始めます。
結論
Suna AIは、デジタル領域でタスクを実行できる自律的AIエージェントへの実用的なステップを表しています。そのオープンソースの性質、強力なツールキット、モジュラーアーキテクチャを組み合わせることで、開発者やカスタマイズ可能で自己ホスト可能なAIアシスタントを求めるユーザーにとって魅力的な選択肢です。上記の詳細なセットアッププロセスに従うことによって、Sunaの自分のインスタンスをデプロイし、ブラウジング、自動ファイル操作、データ収集、コード実行などを自分の制御する環境内で自動化するための会話インターフェースを得られます。設定にはその複数のコンポーネントへの注意が必要ですが、その結果はあなたのために行動する多用途なAIエージェントとなります。
開発者チームが最大の生産性で協力するための統合されたオールインワンプラットフォームが欲しいですか?
Apidogはすべての要求を満たし、Postmanをより手頃な価格で代替します!