
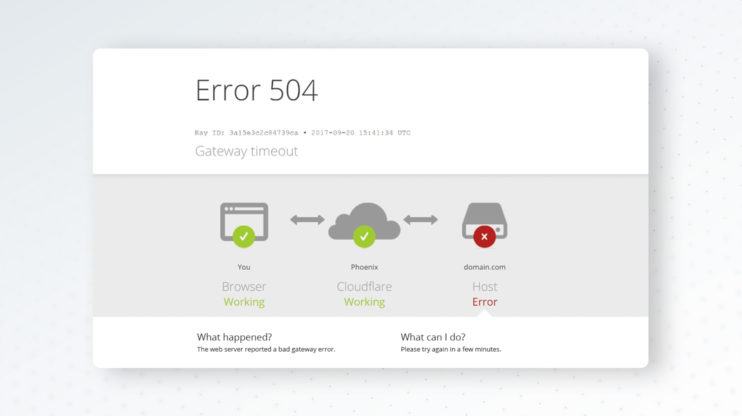
ウェブサイトを閲覧しているときに、ページが読み込まれる代わりに「504 Gateway Timeout」というメッセージが表示され、スピナーが永遠に回り続けているように感じたことはありませんか?更新ボタンを押しても、同じエラーが表示されます。ウェブサイトは技術的に「ダウン」しているわけではありませんが、そのインフラストウェアのどこかが応答を待つのを諦めてしまった状態です。
このイライラする経験は、現代のウェブで最も一般的なサーバーサイドエラーの1つである504 Gateway Timeoutステータスコードによって引き起こされます。
通常ユーザーの「過失」とされる404 Not Foundのようなクライアントエラーや、アプリケーション内部で発生する500 Internal Server Errorのようなサーバーエラーとは異なり、504はサーバー間の通信障害です。これは、仲介者が「あなたが本当に話したい相手をあまりにも長く待っていたが、もう諦める」と両手を上げて言うデジタル版です。
しかし、HTTPステータスコード 504: Gateway Timeoutとは一体何で、なぜ発生するのでしょうか?さらに重要なことに、アプリ、API、またはウェブサイトで表示されないように修正または防止するにはどうすればよいのでしょうか?
あなたが開発者、システム管理者、あるいは単に好奇心旺盛なウェブユーザーであるなら、504エラーの原因と修正方法を理解することは非常に価値があります。
このコードが何を意味するのかから、一般的な原因、実践的な修正方法まで、すべてを詳しく説明します。
それでは、504 Gateway Timeoutに遭遇したときに舞台裏で何が起こっているのかを探ってみましょう。
現代のウェブアーキテクチャ:単一のサーバーだけでは決してない
504を理解するには、現代のウェブサイトやアプリケーションがどのように構築されているかを理解する必要があります。もはや単一のサーバーで動作するアプリケーションはほとんどありません。ほとんどは、次のような多層アーキテクチャを使用しています。
- ユーザーのブラウザ: 最初のリクエストを行います。
- ロードバランサー / リバースプロキシ: 複数のバックエンドサーバー(例:NGINX、HAProxy、AWS ALB)にトラフィックを分散します。
- ウェブ/アプリケーションサーバー: 実際のアプリケーションコード(例:Node.js、Python/Django、PHP)を実行します。
- バックエンドサービス / API: 認証、決済、データ処理などの特定のタスクを処理します(多くの場合マイクロサービス)。
- データベース / キャッシュ: データを保存および取得します。
504エラーは通常、ステップ2と3の間、またはステップ3と4の間で発生します。「Gateway Timeout」の「ゲートウェイ」とは、ロードバランサーやリバースプロキシといった仲介役として機能するサーバーを指します。
HTTP 504 Gateway Timeoutとは実際に何を意味するのか?
504 Gateway Timeoutステータスコードは、ゲートウェイまたはプロキシとして機能するサーバーが、リクエストを完了するためにアクセスする必要があったアップストリームサーバーから、時間内に応答を受け取らなかったことを示します。
より簡単に言えば、「私(ゲートウェイ)は別のサーバーに助けを求めたが、そのサーバーからの応答があまりにも遅かったため、私は諦めて、問題が発生したことをあなたに伝えている」ということです。
典型的な504応答は非常に最小限です。
HTTP/1.1 504 Gateway TimeoutContent-Type: text/htmlContent-Length: 125
<html><head><title>504 Gateway Timeout</title></head><body><center><h1>504 Gateway Timeout</h1></center></body></html>
他のいくつかのエラーとは異なり、ゲートウェイ自体は凝ったエラーページを生成する方法を知らない単純なインフラストラクチャの一部であることが多いため、通常カスタムボディはありません。
このように考えてみてください。
友人にレストランが営業しているか確認するように頼みました。友人はレストランに電話をかけますが、誰も出ません。しばらく待った後、友人はあなたにこう言います。
「ごめん、誰も出なかったよ。タイムアウトになった。」
504 Gateway Timeoutで起こっていることは、まさにこれです。
ゲートウェイ(通常はNGINXのようなリバースプロキシまたはロードバランサー)は、アップストリームサーバー(ウェブアプリやデータベースなど)への接続を試みます。そのアップストリームサーバーからの応答があまりにも遅い場合、ゲートウェイは504を発生させてリクエストを中止します。
責任の連鎖:504はどのように発生するか
一般的なeコマースアーキテクチャを使用した具体的な例を見ていきましょう。
1. リクエスト: ユーザーが商品を検索します。ブラウザはhttps://shop.example.com/search?q=laptopにリクエストを送信します。
2. ロードバランサーの役割: リクエストはまずロードバランサー(ゲートウェイ)に到達します。ロードバランサーの仕事は、このリクエストを複数の利用可能なアプリケーションサーバーのいずれかに転送することです。ロードバランサーには、例えば30秒のタイムアウト設定があります。
3. アプリケーションサーバーのタスク: アプリケーションサーバーはリクエストを受信します。それを処理するために、他の2つのサービスを呼び出す必要があります。
- 商品結果を取得するために検索サービスを呼び出します。
- パーソナライズされたレコメンデーションを取得するためにユーザープロファイルサービスを呼び出します。
4. 問題: ユーザープロファイルサービスが高負荷またはデータベースデッドロックを経験しています。スタックして応答しません。
5. タイムアウト: アプリケーションサーバーは待ち続けます... 25秒... 28秒... 29秒... アプリケーションサーバーからの応答をまだ待っているロードバランサーは、30秒のタイムアウト制限に達します。
6. 504応答: ロードバランサーは諦めます。アプリケーションサーバーから検索結果を受け取らなかったため、それを返すことができません。そのため、ユーザーのブラウザに504 Gateway Timeoutを返します。
ここでの重要な洞察は、アプリケーションサーバーはまだ動作している可能性があるということです。ユーザープロファイルサービスからの応答を得ようとしているかもしれません。しかし、ロードバランサーはすでにその視点からリクエストを中止しています。
504を予期すべき場合
504は、次のようなシナリオで最も一般的です。
- アプリケーションが複数のダウンストリームサービスまたはマイクロサービスに依存している場合。
- アップストリームサービスがメンテナンスまたは高負荷のために一時的に利用できない場合。
- サードパーティのAPIまたはデータベースが遅い、または応答しない場合。
- ネットワークパスで一時的な遅延またはパケットロスが発生する場合。
504は通常一時的なものであるため、堅牢な回復力計画の一部として、リトライ戦略やサーキットブレーカーがしばしば導入されます。
504が許容される場合
ゲートウェイタイムアウトが予期される、または許容される正当なケースがあります。
- アップストリームサービスが意図的に速度を落とされたり、オフラインになったりするメンテナンス期間。
- アップストリームサービスがすぐに吸収できない一時的なトラフィックの急増。
- ロールバックまたは軽減されている断続的な依存関係の問題。
これらのケースでは、透明性のあるコミュニケーションと適切に設計されたリトライポリシーが、ユーザーへの影響を最小限に抑えるのに役立ちます。
504 Gateway Timeoutの実際の例
eコマースウェブサイトを構築していると想像してください。チェックアウトプロセスでは、決済、在庫、配送、ユーザー認証など、複数のAPIを呼び出します。
ここで、決済APIが突然遅くなったり、利用できなくなったりした場合、あなたのサーバー(ゲートウェイとして機能)は応答を待ちます。タイムアウト制限(例えば30秒)内に応答が得られない場合、サーバーは次をスローします。
504 Gateway Timeout
ユーザーにはウェブサイトが壊れているように見えますが、技術的には、問題はサービス間の通信チェーンにあります。
504と他の5xxエラー:違いを知る
サーバーエラーは混同しやすいですが、それぞれ何が問題だったのかについて異なるストーリーを語ります。
504 Gateway Timeout vs. 502 Bad Gateway:
504は「アップストリームサーバーからの応答が遅すぎた。」(タイムアウト問題)を意味します。502は「アップストリームサーバーが不正なものやゴミを返してきた。」(応答が不正な形式だった、または接続が完全に拒否された)を意味します。
504 Gateway Timeout vs. 500 Internal Server Error:
504はサーバー間のインフラストラクチャレベルで発生します。500はコード内のアプリケーションレベルで発生します(例:PythonまたはJavaScriptコードでの未処理の例外)。
504 Gateway Timeout vs. 408 Request Timeout:
504はサーバーサイドのタイムアウトです。ゲートウェイが別のサーバーを待っている間にタイムアウトしました。408はクライアントサイドのタイムアウトです。サーバーがクライアントからの完全なリクエストを待っている間にタイムアウトしました。
504 Gateway Timeoutの一般的な原因
原因を理解することが、予防と解決への第一歩です。
1. 過負荷なバックエンドサーバー
これが最も一般的な原因です。アプリケーションサーバーが重い負荷を受けていると、応答が遅くなったり、まったく応答しなくなったりする可能性があります。これは次の原因によるものです。
- トラフィックの急増
- 非効率なデータベースクエリ
- サーバーリソース(CPU、RAM)の不足
2. ネットワークの問題
ゲートウェイとバックエンドサーバー間の接続問題がタイムアウトを引き起こす可能性があります。
- ネットワーク輻輳
- トラフィックをブロックするファイアウォールルール
- DNS解決の問題
3. リソースを大量に消費する操作
一部の操作は当然時間がかかります。
- 複雑なレポートの生成
- 大容量ファイルのアップロード処理
- 機械学習推論の実行
これらの操作がゲートウェイのタイムアウトしきい値を超えると、504エラーが発生します。
4. サービス依存関係
アプリケーションが、遅いまたはダウンしている外部APIまたはマイクロサービスに依存している場合、アプリケーションサーバーはそれらを待ち、ゲートウェイタイムアウトをトリガーする可能性があります。
5. タイムアウト設定の誤り
タイムアウトが単純に低く設定されすぎている場合があります。ゲートウェイのタイムアウトが10秒であっても、正当な複雑な操作には15秒かかることがあります。
Apidogを使ったAPIのテストとデバッグ
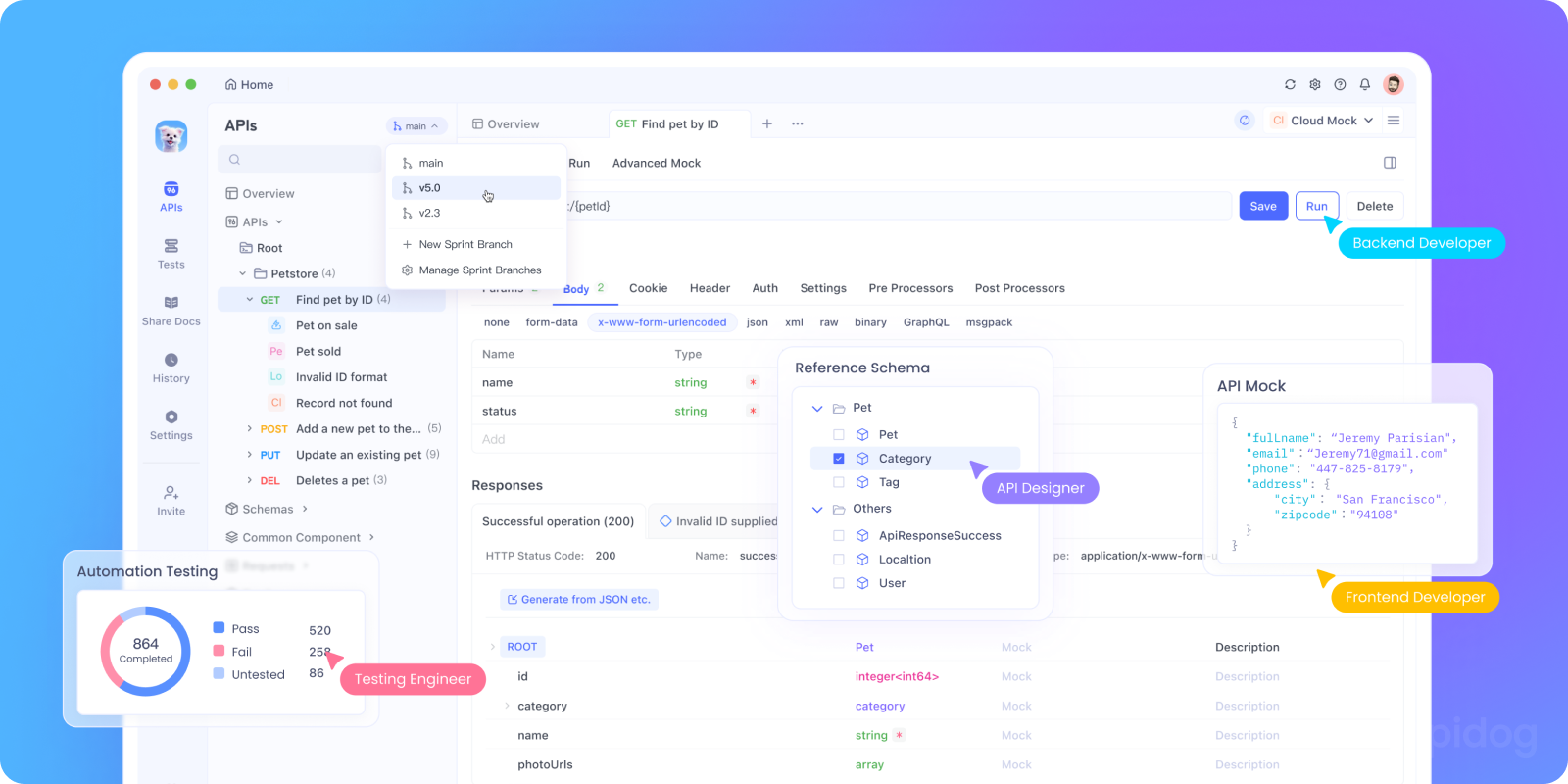
断続的な504エラーの根本原因を特定することは、干し草の山から針を見つけるようなものです。504のデバッグでは、開発者はどのサーバー、サービス、またはリクエストが原因であるかを特定する可視性の問題にしばしば苦労します。Apidogは、これをはるかに容易にするいくつかの機能を提供します。
- パフォーマンス テスト: Apidogを使用してAPIに複数の同時リクエストを送信し、応答時間を測定します。これにより、特定のエンドポイントが負荷時に遅いかどうかを特定でき、504エラーにつながる可能性があります。
- 監視設定: Apidogでエンドポイントを定期的にチェックする自動監視を作成します。リクエストが設定したしきい値(例:ゲートウェイタイムアウトが30秒の場合に25秒)よりも長くかかった場合、Apidogはユーザーが504エラーを目にする前にアラートを発することができます。
- サービス依存関係のテスト: APIが他のサービスを呼び出す場合、Apidogを使用してそれらの依存関係を個別にテストします。これにより、問題がアプリケーションにあるのか、ダウンストリームサービスにあるのかを特定できます。
- 遅い応答のシミュレーション: Apidogのモックサーバーを使用して、遅いバックエンド応答をシミュレートします。これにより、実際のプロダクションシステムに過負荷をかけることなく、ゲートウェイとアプリケーションがタイムアウトをどのように処理するかをテストできます。
- タイムアウトの期待値の文書化: Apidogのドキュメント機能を使用して、どのエンドポイントが長時間実行されると予想されるかを記録し、チームがインフラストラクチャで適切なタイムアウト値を設定するのに役立てます。
はい、Apidogは無料でダウンロードできます。これは単なるPostmanの代替品ではなく、API設計、テスト、パフォーマンス監視のための完全なエコシステムです。
504エラーのトラブルシューティングと修正
即時の対策:
- サーバーリソースの確認: アプリケーションサーバーのCPU、メモリ、ディスクI/Oを確認します。
- ログのレビュー: 504が発生した前後のアプリケーションログとゲートウェイログを確認します。
- 外部依存関係の検証: アプリケーションが使用するサードパーティAPIまたはサービスが正常であることを確認します。
長期的な解決策:
- アプリケーションパフォーマンスの最適化: 遅いデータベースクエリを特定して修正し、コードを最適化し、キャッシングを実装します。
- タイムアウト設定の調整: 正当な長時間実行操作がある場合は、ゲートウェイのタイムアウト値を増やします。
- サーキットブレーカーの実装: 複数の失敗後に失敗しているサービスの呼び出しを停止するパターンを使用し、カスケードタイムアウトを防ぎます。
- インフラストラクチャのスケーリング: アプリケーションサーバーを追加するか、より強力なインスタンスにアップグレードします。
- 非同期処理の実装: 長時間実行されるタスクの場合、ジョブキュー(Redis QueueやAWS SQSなど)を使用し、
202 Acceptedですぐに返し、タスクが完了したらユーザーに通知します。
504エラーを長期的に防ぐためのベストプラクティス
技術的な部分を、将来の頭痛の種を減らすための予防戦略で締めくくりましょう。
1. 可能な限りキャッシングを使用する
応答をキャッシュする(アプリ、CDN、またはプロキシレベルで)ことで、バックエンドの負荷と応答時間を削減します。
2. データベースクエリを最適化する
最適化されていないSQLクエリは、しばしばバックエンドのボトルネックを引き起こします。インデックスを調整し、大規模な結合を避けてください。
3. APIの健全性を監視する
Apidog、Datadog、Pingdomなどのツールを使用して、APIの稼働時間とパフォーマンスを継続的に監視します。
4. サーキットブレーカーを実装する
APIにサーキットブレーカーパターンを追加し、失敗しているサービスへのリクエストを一時的に停止します。
5. 自動的にスケーリングする
AWSやAzureのようなクラウド環境でオートスケーリングを使用し、突然のトラフィック急増に対応します。
6. すべてをログに記録する
集中ログ記録は、完全に機能停止する前に遅いエンドポイントを検出するのに役立ちます。
人間的側面:障害発生時のコミュニケーション
ゲートウェイタイムアウト時の透明性のあるコミュニケーションは重要です。サービスが遅延している場合はユーザーに通知し、可能であれば予想される復旧時間を提供し、ステータス更新を行います。適切に管理されたインシデント対応計画は、ユーザーの不満を軽減し、信頼を構築します。
ゲートウェイを軽減するためのアーキテクチャパターン
- タイムアウトポリシーを持つサービスメッシュ: タイムアウト設定と障害処理を一元化します。
- ホップごとのタイムアウト: リクエストチェーンの各ホップで適切なタイムアウトを設定し、長い待機を防ぎます。
- バックプレッシャーとキューイング: 輻輳時にリクエストをバッファリングして、スパイクを平滑化します。
- カナリアデプロイメント: 変更を段階的に展開し、広範囲にわたるアップストリーム遅延のリスクを軽減します。
- 冗長なアップストリーム: 単一障害点を減らすために代替サービスを提供します。
これらのパターンは、アップストリームの遅延の影響を抑制し、ユーザーエクスペリエンスを損なわないようにするのに役立ちます。
結論:分散システムの代償
HTTP 504 Gateway Timeoutステータスコードは、現代の分散型ウェブアーキテクチャの自然な結果です。ユーザーにとってはイライラするものですが、リクエストが無限にハングアップするのを防ぎ、システム全体が応答性を保つという重要な目的を果たします。
504が本質的にサーバー間の通信問題であり、必ずしもアプリケーションのバグではないと理解することが、効果的なトラブルシューティングの鍵です。パフォーマンスを監視し、遅い操作を最適化し、インフラストラクチャを適切に構成することで、これらのエラーを最小限に抑え、ユーザーにより良いエクスペリエンスを提供できます。
次に504エラーを見たときには、それは最終的に待つのを諦めざるを得なかった忍耐強いゲートウェイサーバーの物語だとわかるでしょう。そして、これらのタイムアウトを回避する必要があるシステムを構築する際には、Apidogのようなツールが、パフォーマンスのボトルネックを特定し、APIがタイムリーに応答することを保証するための最良の味方となるでしょう。