
2025年4月13日、SkyworkAIはSkywork-OR1(Open Reasoner 1)シリーズをリリースしました。このシリーズには3つのモデルが含まれます:Skywork-OR1-Math-7B、Skywork-OR1-7B-Preview、そしてSkywork-OR1-32B-Previewです。
- これらのモデルは、数学的推論能力とコード推論能力に特化した大規模なルールベースの強化学習を用いてトレーニングされています。
- モデルはDeepSeekの蒸留アーキテクチャを基盤として構築されています:7BバリアントはDeepSeek-R1-Distill-Qwen-7Bをベースとしており、32BモデルはDeepSeek-R1-Distill-Qwen-32Bをベースとしています。
開発チームが最大の生産性で一緒に作業するための統合型オールインワンプラットフォームが欲しいですか?
Apidogはすべての要求を満たし、より手頃な価格でPostmanを置き換えます!

Skywork-OR1-32B: 単なるオープンソース推論モデルではない
Skywork-OR1-32B-Previewモデルは328億のパラメータを含み、数値精度のためにBF16テンソルタイプを使用しています。このモデルはsafetensors形式で配布されており、Qwen2アーキテクチャに基づいています。モデルリポジトリによると、基本モデルであるDeepSeek-R1-Distill-Qwen-32Bと同じアーキテクチャを維持していますが、数学的推論とコーディング推論タスクに特化したトレーニングが施されています。
Skyworkモデルファミリーの基本的な技術情報を見てみましょう:
Skywork-OR1-32B-Preview
- パラメータ数:328億
- 基本モデル:DeepSeek-R1-Distill-Qwen-32B
- テンソルタイプ:BF16
- 特化分野:汎用推論
- 主要パフォーマンス:
- AIME24:79.7(Avg@32)
- AIME25:69.0(Avg@32)
- LiveCodeBench:63.9(Avg@4)
32Bモデルは、基本モデルと比較してAIME24で6.8ポイント、AIME25で10.0ポイントの改善を示しています。671BパラメータのDeepSeek-R1と同等のパフォーマンスを、わずか4.9%のパラメータで達成することで、パラメータ効率を実現しています。
Skywork-OR1-Math-7B
- パラメータ数:7.62億
- 基本モデル:DeepSeek-R1-Distill-Qwen-7B
- テンソルタイプ:BF16
- 特化分野:数学的推論
- 主要パフォーマンス:
- AIME24:69.8(Avg@32)
- AIME25:52.3(Avg@32)
- LiveCodeBench:43.6(Avg@4)
このモデルは数学タスクにおいて基本モデルであるDeepSeek-R1-Distill-Qwen-7Bを大幅に上回っています(AIME24:69.8対55.5、AIME25:52.3対39.2)。これは特化トレーニングアプローチの有効性を示しています。
Skywork-OR1-7B-Preview
- パラメータ数:7.62億
- 基本モデル:DeepSeek-R1-Distill-Qwen-7B
- テンソルタイプ:BF16
- 特化分野:汎用推論
- 主要パフォーマンス:
- AIME24:63.6(Avg@32)
- AIME25:45.8(Avg@32)
- LiveCodeBench:43.9(Avg@4)
Math-7Bバリアントと比べて数学的特化度は低いですが、数学タスクとコーディングタスクの間でよりバランスの取れたパフォーマンスを提供します。
Skywork-OR1-32Bのトレーニングデータセット
Skywork-OR1のトレーニングデータセットには以下が含まれます:
- 検証可能で多様な数学問題110,000問
- コーディング問題14,000問
- すべてオープンソースデータセットから収集
データ処理パイプライン
- モデル対応難易度推定:各問題はモデルの現在の能力に対して難易度スコアリングされ、ターゲットを絞ったトレーニングが可能になります。
- 品質評価:トレーニング前に厳格なフィルタリングが適用され、データセットの品質が保証されます。
- オフラインおよびオンラインフィルタリング:2段階のフィルタリングプロセスが実装されています:
- トレーニング前に最適でない例を除去(オフライン)
- トレーニング中に問題選択を動的に調整(オンライン)
4. リジェクトサンプリング:この技術がトレーニング例の分布を制御するために採用され、最適な学習曲線を維持するのに役立ちます。
先進的な強化学習トレーニングパイプライン
モデルはGRPO(Generative Reinforcement via Policy Optimization)のカスタマイズ版を使用しており、いくつかの技術的強化が施されています:
- 多段階トレーニングパイプライン:トレーニングは明確な段階を経て進み、各段階で以前に獲得した能力を基盤とします。GitHubリポジトリには、トレーニングステップに対するAIME24スコアをプロットしたグラフが含まれており、各段階での明確なパフォーマンス向上が示されています。
- 適応エントロピー制御:この技術はトレーニング中の探索と活用のトレードオフを動的に調整し、収束安定性を維持しながら幅広い探索を促進します。
- VERLフレームワークのカスタムフォーク:モデルは推論タスクに特化して適応されたVERLプロジェクトの修正版を使用してトレーニングされています。
完全な論文はこちらで読むことができます。
Skywork-OR1-32Bベンチマーク
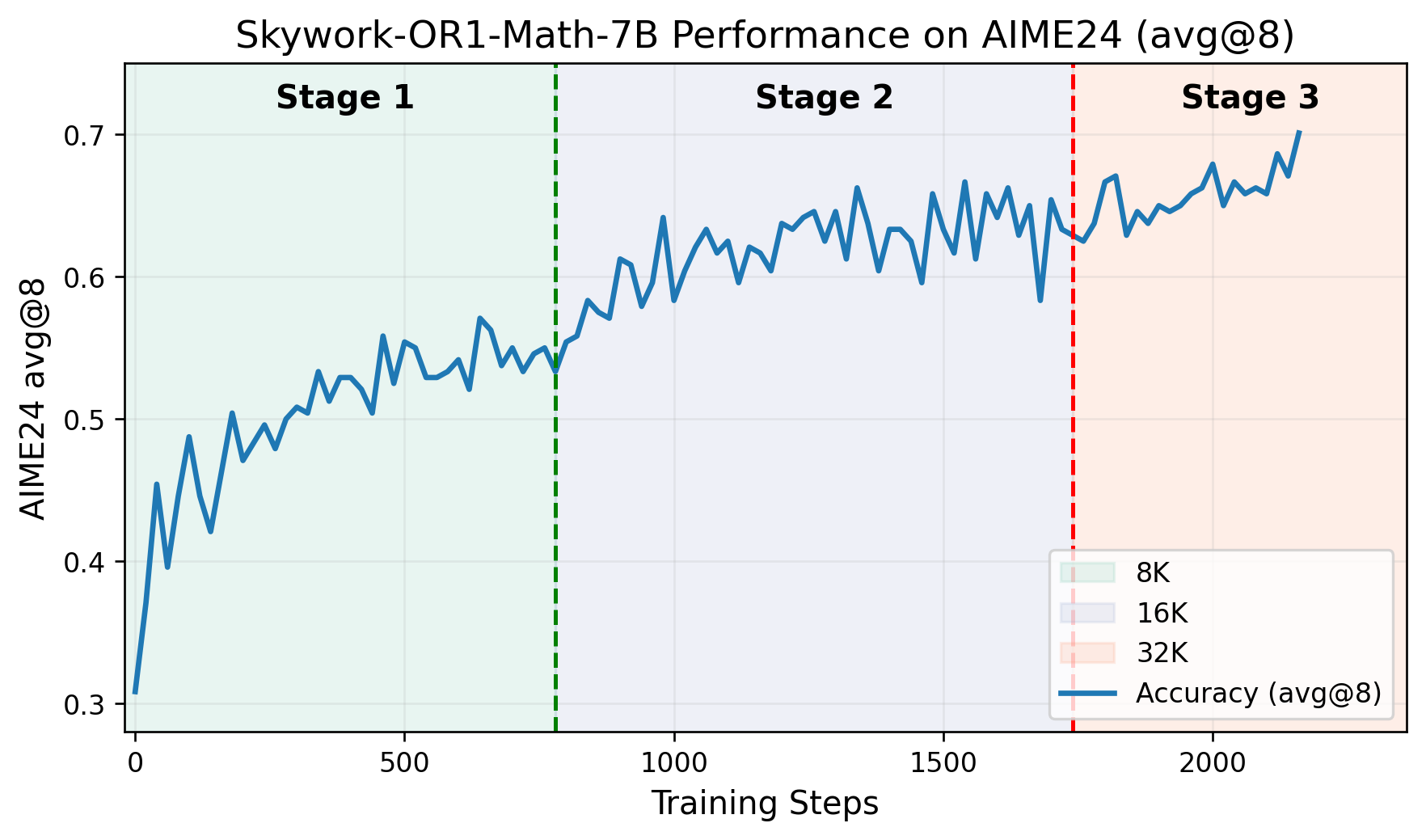
技術仕様:
- パラメータ数:328億
- テンソルタイプ:BF16
- モデル形式:Safetensors
- アーキテクチャファミリー:Qwen2
- 基本モデル:DeepSeek-R1-Distill-Qwen-32B
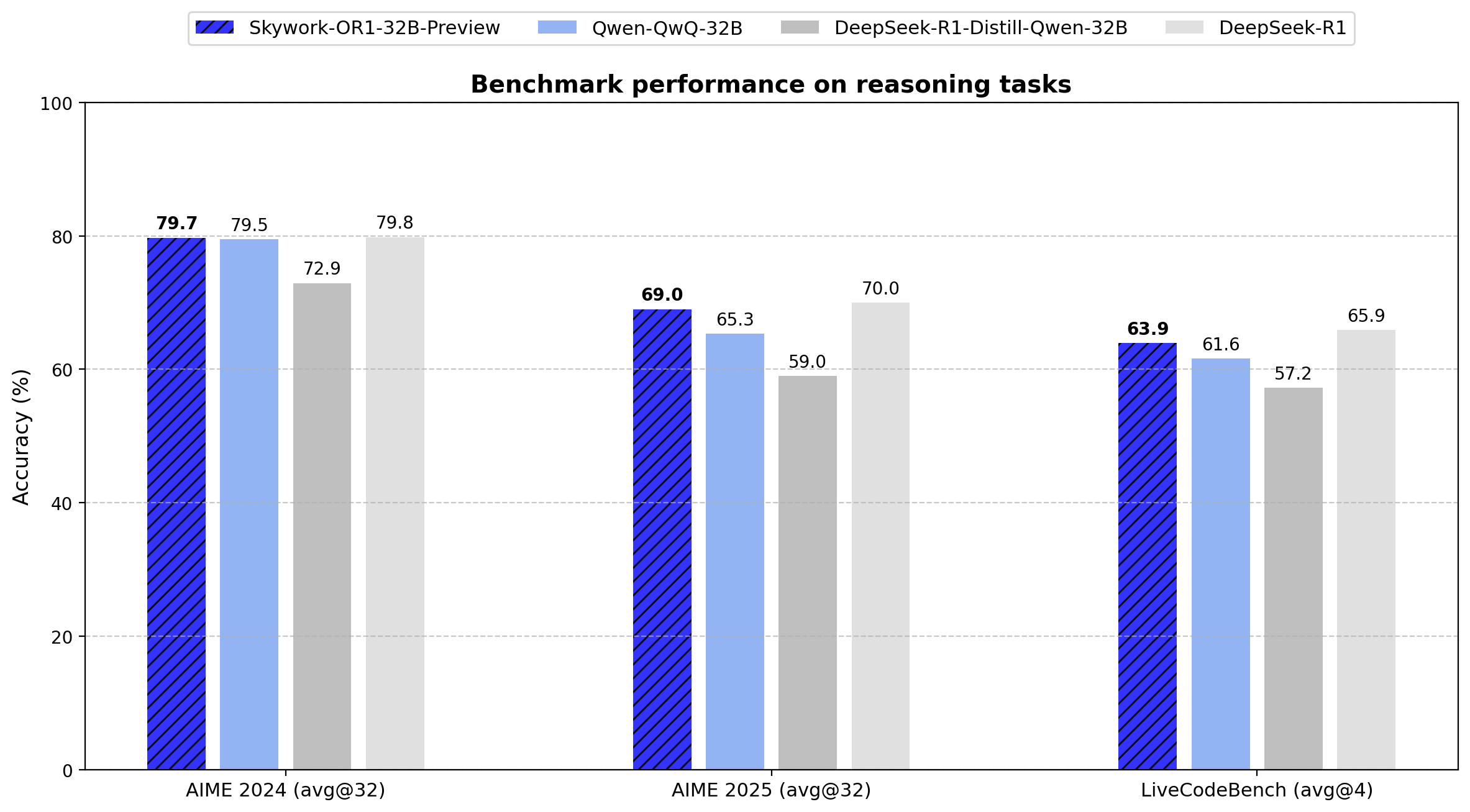
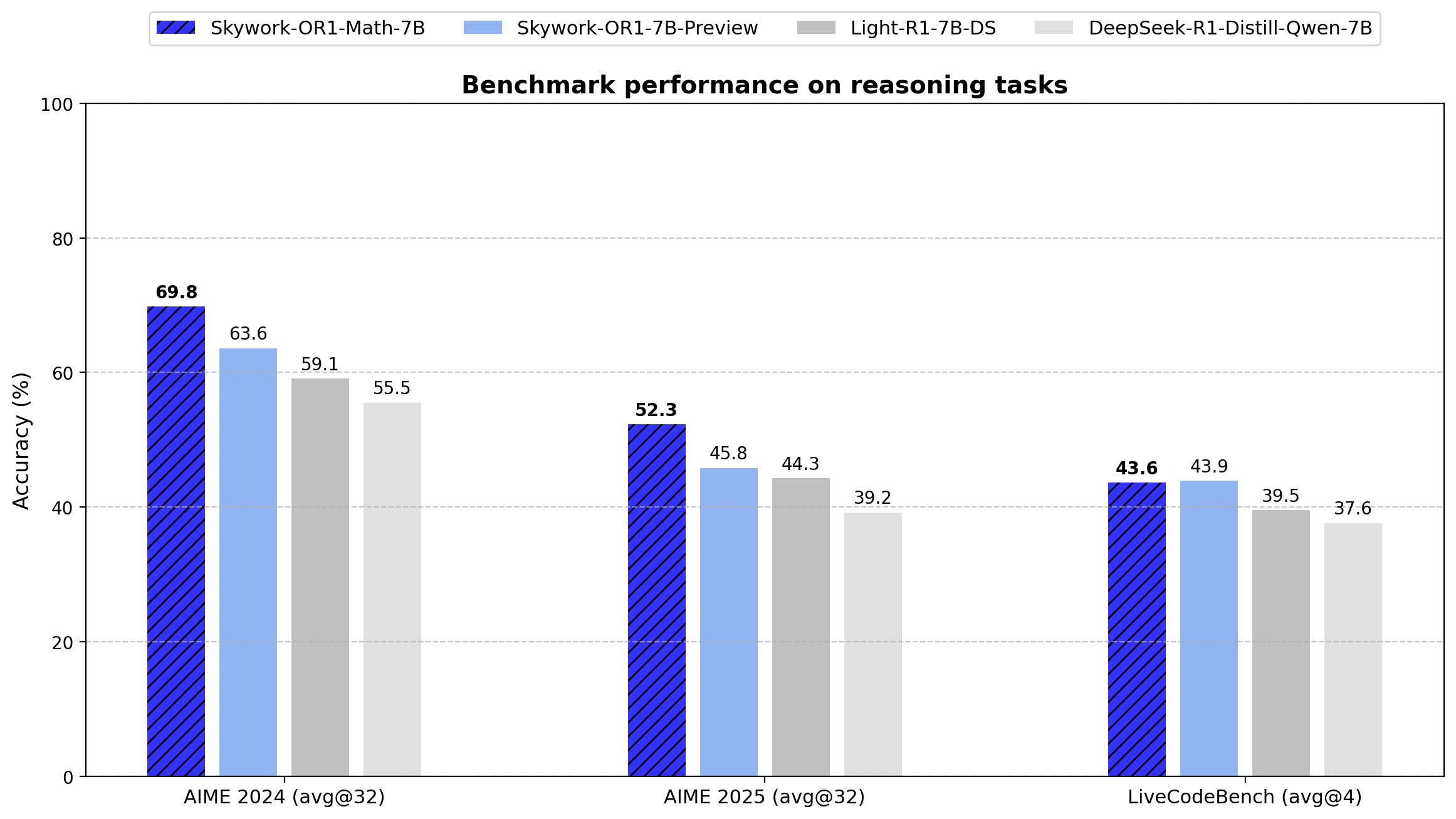
Skywork-OR1シリーズは、従来のPass@1ではなくAvg@Kを主要評価指標として導入しています。この指標は複数の独立した試行(AIMEテストでは32回、LiveCodeBenchでは4回)にわたる平均パフォーマンスを計算し、分散を減らして推論の一貫性をより信頼性高く測定します。
以下はシリーズ全モデルの正確なベンチマーク結果です:
データは、Skywork-OR1-32B-PreviewがDeepSeek-R1とほぼ同等のパフォーマンスを示していることを示しています(AIME24:79.7対79.8、AIME25:69.0対70.0、LiveCodeBench:63.9対65.9)。これは後者が20倍のパラメータ(671B対32.8B)を持っているにもかかわらずの結果です。
Skywork-OR1モデルは以下の技術仕様で実装できます:
Skywork-OR1モデルのテスト方法
以下はSkywork-OR1-32B、Skywork-OR1-7B、Skywork-OR1-Math-7BのHugging Faceモデルカードです:



評価スクリプトを実行するには、以下の手順を踏んでください。まず:
Docker環境:
docker pull whatcanyousee/verl:vemlp-th2.4.0-cu124-vllm0.6.3-ray2.10-te2.0-megatron0.11.0-v0.0.6
docker run --runtime=nvidia -it --rm --shm-size=10g --cap-add=SYS_ADMIN -v <path>:<path> image:tag
Conda環境セットアップ:
conda create -n verl python==3.10
conda activate verl
pip3 install torch==2.4.0 --index-url <https://download.pytorch.org/whl/cu124>
pip3 install flash-attn --no-build-isolation
git clone <https://github.com/SkyworkAI/Skywork-OR1.git>
cd Skywork-OR1
pip3 install -e .
AIME24評価の再現:
MODEL_PATH=Skywork/Skywork-OR1-32B-Preview \\\\
DATA_PATH=or1_data/eval/aime24.parquet \\\\
SAMPLES=32 \\\\
TASK_NAME=Aime24_Avg-Skywork_OR1_Math_7B \\\\
bash ./or1_script/eval/eval_32b.sh
AIME25評価:
MODEL_PATH=Skywork/Skywork-OR1-Math-7B \\\\
DATA_PATH=or1_data/eval/aime25.parquet \\\\
SAMPLES=32 \\\\
TASK_NAME=Aime25_Avg-Skywork_OR1_Math_7B \\\\
bash ./or1_script/eval/eval_7b.sh
LiveCodeBench評価:
MODEL_PATH=Skywork/Skywork-OR1-Math-7B \\DATA_PATH=or1_data/eval/livecodebench/livecodebench_2408_2502.parquet \\SAMPLES=4 \\TASK_NAME=LiveCodeBench_Avg-Skywork_OR1_Math_7B \\bash ./or1_script/eval/eval_7b.sh現在のSkywork-OR1モデルは「プレビュー」版としてラベル付けされており、最終リリースは最初の発表から2週間以内に利用可能になる予定です。開発者は以下の追加技術文書がリリースされることを示しています:
- トレーニング方法論を詳細に説明する包括的な技術レポート
- Skywork-OR1-RL-Dataデータセット
- 追加のトレーニングスクリプト
 SkyworkAI
SkyworkAI結論:Skywork-OR1-32Bの技術的評価
Skywork-OR1-32B-Previewモデルは、パラメータ効率の良い推論モデルにおいて重要な進歩を表しています。328億のパラメータで、複数のベンチマークにおいて6710億パラメータのDeepSeek-R1モデルとほぼ同一のパフォーマンス指標を達成しています。
まだ検証されていませんが、これらの結果は、高度な推論能力を必要とする実用的なアプリケーションにおいて、Skywork-OR1-32B-Previewが大幅に大きなモデルに対する実行可能な代替手段を提供し、計算要件を大幅に削減できることを示唆しています。
さらに、これらのモデルのオープンソース性、評価スクリプト、そして今後公開予定のトレーニングデータは、言語モデルの推論能力に取り組む研究者や実務者にとって貴重な技術リソースを提供します。
GitHubリポジトリには、トレーニングスクリプトが「現在整理中で1-2日以内に利用可能になる」と記載されています。
開発チームが最大の生産性で一緒に作業するための統合型オールインワンプラットフォームが欲しいですか?
Apidogはすべての要求を満たし、より手頃な価格でPostmanを置き換えます!


