
大規模言語モデル(LLM)の風景は急速に進化しています。モデルはより強力で、能力が高まり、重要なことに、よりアクセス可能になっています。Qwenチームは最近、最新世代のLLMであるQwen3を発表し、コーディング、数学、一般的な推論などのさまざまなベンチマークで印象的なパフォーマンスを誇っています。Mixture-of-Experts(MoE)であるQwen3-235B-A22Bのようなフラグシップモデルは、確立された巨人に匹敵し、Qwen3-4Bのようなより小さな密モデルは、前世代の72Bパラメータモデルと競争しています。Qwen3は大きな前進を示しています。
このリリースの重要な側面は、2つのMoEバリアント(Qwen3-235B-A22BとQwen3-30B-A3B)および0.6Bから32Bパラメータの6つの密モデルを含むいくつかのモデルのオープンウェイト化です。このオープン性は、開発者、研究者、愛好者がこれらの強力なツールを探求し、利用し、構築することを奨励します。クラウドベースのAPIは便利ですが、プライバシー、コスト管理、カスタマイズ、オフラインアクセスなどのニーズにより、これらの高度なモデルをローカルで実行する欲求が高まっています。
幸いにも、ローカルLLM実行のためのツールエコシステムは大幅に進化しています。このプロセスを簡素化する際立ったプラットフォームはOllamaとvLLMです。Ollamaはさまざまなモデルを簡単に使い始める方法を提供し、vLLMはスループットと効率のために最適化された高性能サービングソリューションを提供し、特に大きなモデル向けです。この記事では、Qwen3を理解し、OllamaとvLLMを使ってローカルマシンにこれらの強力なモデルをセットアップする方法を案内します。
最大の生産性で開発チームが協力できる統合型のオールインワンプラットフォームが必要ですか?
Apidogはすべての要求に応え、Postmanをより手頃な価格で置き換えます!
Qwen 3とは何か、そしてベンチマーク
Qwen3は、Qwenチームによって開発された大規模言語モデル(LLM)の第3世代を表し、2025年4月にリリースされました。このイテレーションは、前のバージョンよりも大幅な進歩を意味し、推論能力の向上、Mixture-of-Experts(MoE)のようなアーキテクチャの革新による効率、多言語サポートの拡大、さまざまなベンチマークでのパフォーマンスの向上に焦点を当てています。このリリースには、Apache 2.0ライセンスの下でいくつかのモデルのオープンウェイト化が含まれ、研究開発のためのアクセス性が促進されました。
Qwen 3のモデルアーキテクチャとバリアントの説明
Qwen3ファミリーは、伝統的な密モデルとスパースMoEアーキテクチャの両方を含み、多様な計算予算とパフォーマンス要件に対応しています。
密モデル:これらのモデルは推論中にすべてのパラメータを利用します。主なアーキテクチャの詳細は以下の通りです:
| モデル | 層数 | アテンションヘッド(クエリ / キー-バリュー) | 単語埋め込みの結びつき | 最大コンテキスト長 |
|---|---|---|---|---|
| Qwen3-0.6B | 28 | 16 / 8 | はい | 32,768トークン(32K) |
| Qwen3-1.7B | 28 | 16 / 8 | はい | 32,768トークン(32K) |
| Qwen3-4B | 36 | 32 / 8 | はい | 32,768トークン(32K) |
| Qwen3-8B | 36 | 32 / 8 | いいえ | 131,072トークン(128K) |
| Qwen3-14B | 40 | 40 / 8 | いいえ | 131,072トークン(128K) |
| Qwen3-32B | 64 | 64 / 8 | いいえ | 131,072トークン(128K) |
注:Grouped-Query Attention(GQA)はすべてのモデルで使用されており、クエリとキー-バリューのヘッドの数が異なることで示されています。
Mixture-of-Experts(MoE)モデル:これらのモデルは、推論中に各トークンについて「専門家」であるフィードフォワードネットワーク(FFN)のサブセットのみを活性化することによりスパース性を活用します。これにより、総パラメータ数を大きく保ちながら、計算コストを小さな密モデルに近づけることができます。
| モデル | 層数 | アテンションヘッド(クエリ / キー-バリュー) | 専門家の数(総数 / 活性化された数) | 最大コンテキスト長 |
|---|---|---|---|---|
| Qwen3-30B-A3B | 48 | 32 / 4 | 128 / 8 | 131,072トークン(128K) |
| Qwen3-235B-A22B | 94 | 64 / 4 | 128 / 8 | 131,072トークン(128K) |
注:両方のMoEモデルは128の専門家を利用しますが、トークンごとに8のみを活性化し、同等のサイズの密モデルと比較して計算負荷を大幅に軽減します。
Qwen 3の主要な技術的特徴
ハイブリッド思考モード:Qwen3の特徴的な機能は、ユーザーによって制御可能な2つの異なるモードで動作できることです:
- 思考モード(デフォルト):モデルは内部で段階的な推論を行い(Chain-of-Thoughtスタイル)、最終的な応答を生成します。この潜在的な思考過程はカプセル化されており、特定のフレームワークの構成を使用している場合、最終的な回答の前に
<think>...</think>といった特別なトークンで示されることがよくあります。このモードは、論理的な推論、数学的推論、または計画を必要とする複雑なタスクにおけるパフォーマンスを向上させます。これは、割り当てられた計算推論予算に直接相関したスケーラブルな性能向上を可能にします。 - 非思考モード:モデルは明示的な内部推論フェーズなしで直接的な応答を生成し、単純なクエリに対して速度と計算コストを最適化します。
ユーザーは、フレームワークが許可する場合、プロンプト内の/thinkや/no_thinkのようなタグを使用して、ターンごとにこれらのモードを動的に切り替えることができ、レイテンシ/コストと推論の深さの間のトレードオフを細かく制御できます。
広範な多言語サポート:Qwen3モデルは多様なコーパスで事前学習されており、主要な言語ファミリー(インド・ヨーロッパ語、シノ・チベット語、アフロ・アジア語、オーストロネシア語、ドラビダ語、突厥語など)にわたる119の言語と方言をサポートしており、さまざまなグローバルアプリケーションに適しています。
高度なトレーニング方法論:
- 事前トレーニング:モデルは、数兆トークンからなる大規模データセットで事前学習されました。最終的な事前トレーニング段階では、高品質の長文データを使用して、最初は32Kトークンまで有効なコンテキストウィンドウを拡張し、さらに大きなモデルのために128Kへと拡張しました。
- 後トレーニング:モデルに指示に従う能力、推論スキル、ハイブリッド思考メカニズムを注入するために、洗練された4段階のパイプラインが使用されました:
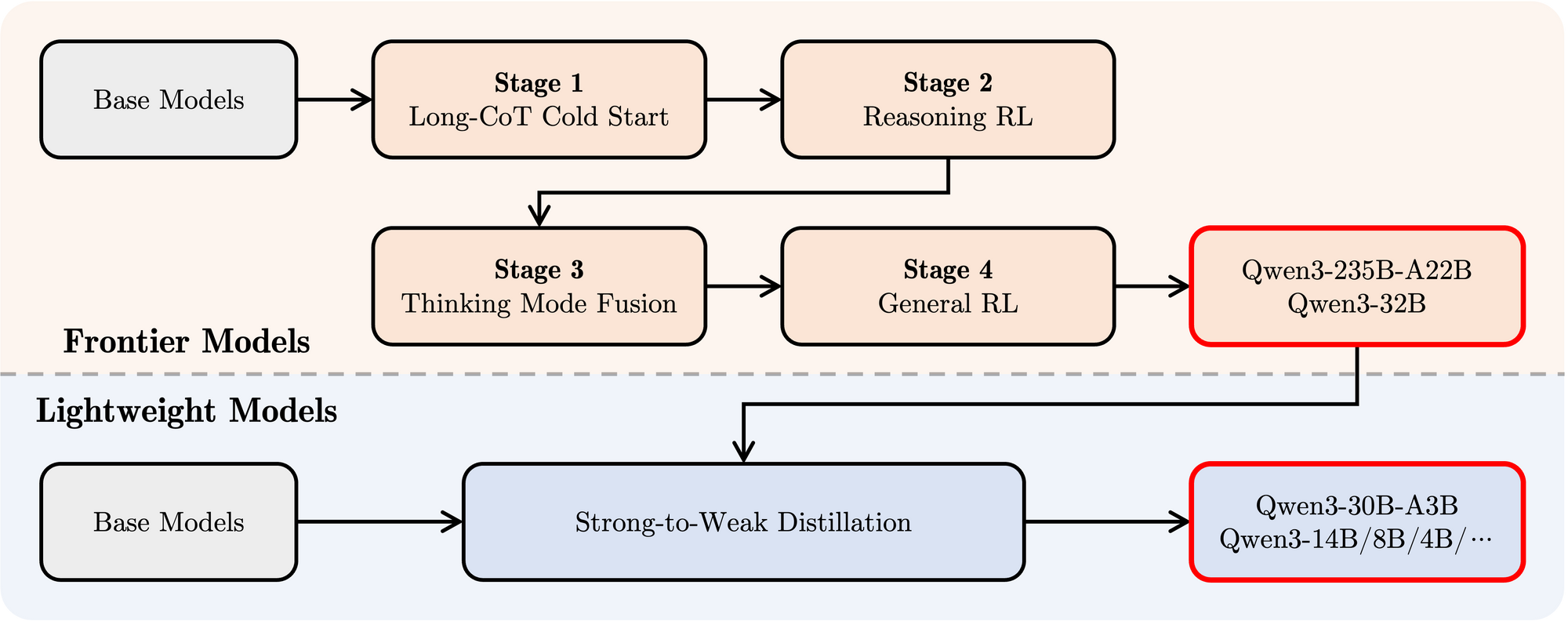
- 長いCoTコールドスタート:数学、コーディング、論理的推論、STEMなどにわたる多様な長いChain-of-Thought(CoT)データに対する監視付きファインチューニング(SFT)を行い、基盤となる推論能力を構築します。
- 推論ベースの強化学習(RL):推論タスクの探索と利用を強化するために、ルールベースの報酬を使用してRLの計算リソースをスケールアップします。
- 思考モードの融合:長いCoTデータと標準の指示調整データを用いて、推論を強化したモデルをファインチューニングすることにより、非思考機能を統合します。これにより、迅速な応答生成と深い推論が融合します。
- 一般RL:さまざまな一般ドメインタスク(指示に従うこと、形式の遵守、エージェントの能力)にRLを適用して、全体的な行動を洗練し、望ましくない出力を軽減します。
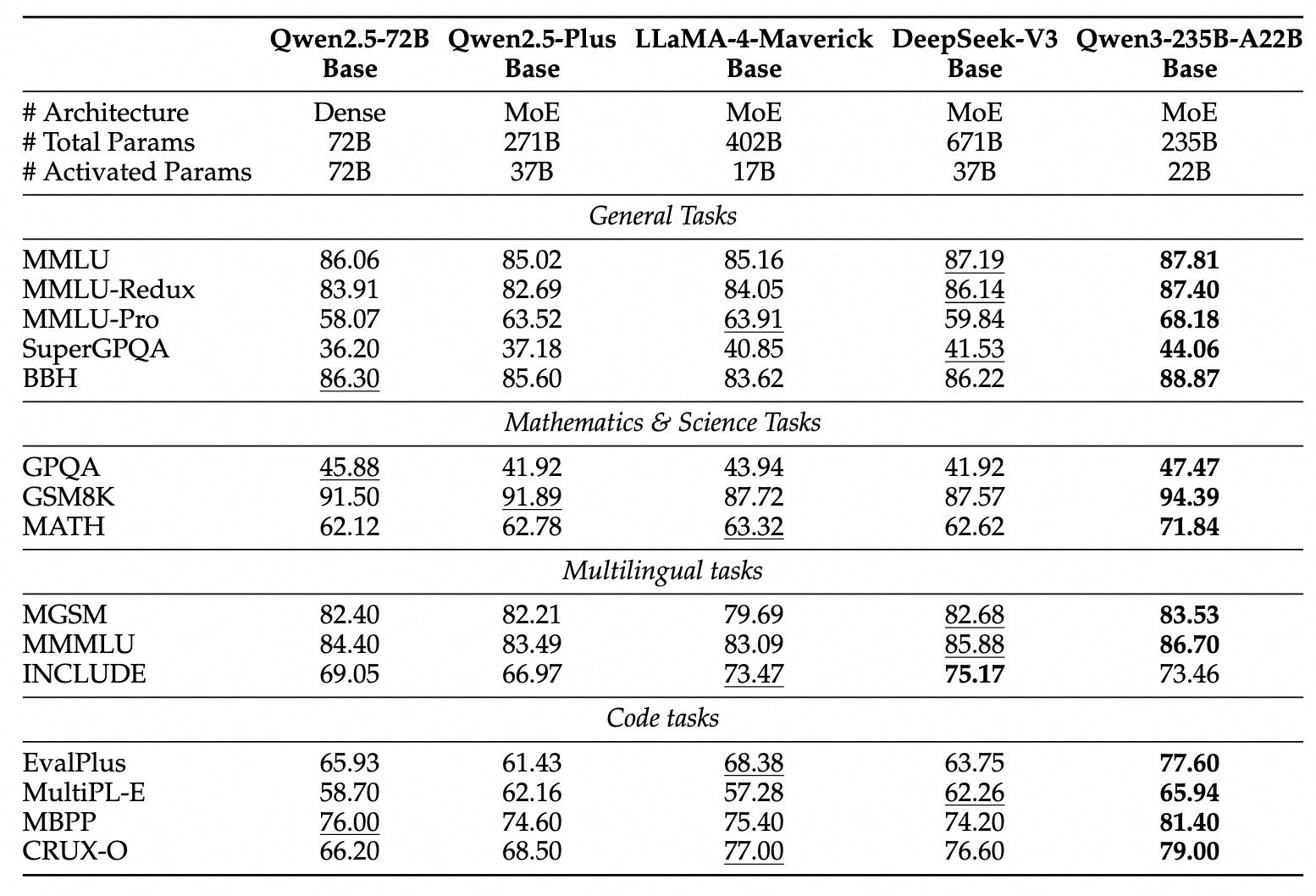
Qwen 3のベンチマークパフォーマンス
Qwen3は他の先進的なモデルに対して非常に競争力のあるパフォーマンスを示しています:
フラグシップMoE:モデルQwen3-235B-A22Bは、コーディング、数学、一般能力を評価するさまざまなベンチマークで、DeepSeek-R1、Googleのo1およびo3-mini、Grok-3、Gemini-2.5-Proなどのトップモデルと比較可能な結果を達成しています。
小型MoE:モデルQwen3-30B-A3Bは、推論中にパラメータのごく一部(3B対32B)しか活性化しなかったにもかかわらず、QwQ-32Bのようなモデルを大幅に上回り、MoEアーキテクチャの効率を強調しています。
密モデル:アーキテクチャとトレーニングの進展により、Qwen3の密モデルは一般的により大きなQwen2.5の密モデルと同等かそれ以上のパフォーマンスを発揮します。例として:
Qwen3-1.7B≈Qwen2.5-3BQwen3-4B≈Qwen2.5-7B(一部の側面でQwen2.5-72B-Instructに匹敵)Qwen3-8B≈Qwen2.5-14BQwen3-14B≈Qwen2.5-32BQwen3-32B≈Qwen2.5-72B
特に、Qwen3の密基本モデルは、STEM、コーディング、推論タスクで前任者に比べて特に強力なパフォーマンス向上を示しています。
MoEの効率:Qwen3のMoE基本モデルは、パラメータの約10%のみを活性化しながら、はるかに大きなQwen2.5の密モデルと同等のパフォーマンスを達成し、トレーニングと推論の計算を大幅に節約します。
これらのベンチマーク結果は、Qwen3が高いパフォーマンスを提供する最新のモデルファミリーとしての地位を強調し、特にMoEバリアントにおいて、計算効率を向上させています。これらのモデルは、Hugging Face、ModelScope、Kaggleなどの標準プラットフォームを通じて利用可能であり、Ollama、vLLM、SGLang、LMStudio、llama.cppなどの人気のデプロイメントフレームワークによってサポートされ、さまざまなワークフローやアプリケーションに統合することができ、ローカル実行も含まれています。
OllamaでQwen 3をローカルで実行する方法
Ollamaは、LLMをローカルでダウンロード、管理、実行するためのシンプルさで非常に人気があります。大部分の複雑さを抽象化し、コマンドラインインターフェースとAPIサーバーを提供します。
1. インストール:
Ollamaのインストールは通常簡単です。公式Ollamaウェブサイト(ollama.com)にアクセスし、オペレーティングシステム(macOS、Linux、Windows)に対するダウンロード手順をフォローします。
2. Qwen3モデルのプル:
Ollamaは、すぐに利用できるモデルのライブラリを維持しています。特定のQwen3モデルを実行するには、ollama runコマンドを使用します。モデルがローカルに存在しない場合、Ollamaは自動的にそれをダウンロードします。Qwenチームは、Ollamaライブラリに直接利用できるいくつかのQwen3バリアントを提供しています。
利用可能なQwen3タグは、OllamaのウェブサイトのQwen3ページ(例:ollama.com/library/qwen3)で確認できます。一般的なタグには以下が含まれます:
qwen3:0.6bqwen3:1.7bqwen3:4bqwen3:8bqwen3:14bqwen3:32bqwen3:30b-a3b(小型MoEモデル)
たとえば、4Bパラメータモデルを実行するには、ターミナルを開いて次のように入力します:
ollama run qwen3:4b
このコマンドは、モデルをダウンロード(必要なら)し、インタラクティブなチャットセッションを開始します。
3. モデルとのインタラクション:ollama runコマンドがアクティブになったら、プロンプトを直接ターミナルに入力できます。Ollamaはまた、ローカルサーバー(通常はhttp://localhost:11434)を起動し、OpenAI標準に対応したAPIを公開します。curlやPython、JavaScriptなどのさまざまなクライアントライブラリを使って、プログラムでこのAPIと対話することができます。
4. ハードウェアの考慮事項:
ローカルでLLMを実行するには substantial resources が必要です。
- RAM:小型モデル(0.6B、1.7B)でも数ギガバイトのRAMが必要です。より大きなモデル(8B、14B、32B、30B-A3B)ではかなりの量が必要で、多くの場合は16GB、32GB、または64GB以上が求められます。これはOllamaが使用する量子化レベルによります。
- VRAM(GPU):適切なパフォーマンスを得るためには、十分なVRAMを備えた専用GPUが強く推奨されます。Ollamaは互換性のあるGPU(NVIDIA、Apple Silicon)を自動的に利用します。VRAMの量は、GPU上で快適に完全に実行できる最大モデルを決定し、推論の速度を大幅に向上させます。
- CPU:OllamaはCPU上でもモデルを実行できますが、GPU上でのパフォーマンスよりかなり遅くなります。
Ollamaは、迅速に始めるため、ローカル開発、実験、特にコンシューマグレードのハードウェア(制限内)での単一ユーザーのチャットアプリケーションに適しています。
vLLMでOllamaをローカルで実行する方法
vLLMは、高スループットLLM提供ライブラリで、PagedAttentionのような最適化を用いて推論速度とメモリ効率を大幅に改善し、要求の厳しいアプリケーションや大きなモデルの提供に理想的です。vLLMチームは、新しいアーキテクチャへの優れたサポートを提供しており、Qwen3のリリース時にはDay 0サポートがあります。
1. インストール:
pipを使用してvLLMをインストールします。一般的には、仮想環境を使用することをお勧めします:
pip install -U vllm
必要な前提条件が整っていることを確認してください。通常は、互換性のあるNVIDIA GPUと適切なCUDAツールキットがインストールされています。特定の要件については、vLLMのドキュメントを参照してください。
2. Qwen3モデルの提供:
vLLMは、vllm serveコマンドを使用してモデルをロードし、OpenAI互換のAPIサーバーを開始します。QwenチームとvLLMのドキュメントが、Qwen3を実行する際のガイダンスを提供しています。
提供された情報と一般的なvLLMの使用に基づき、FP8量子化(メモリ使用量の削減)および4つのGPU間でテンソル並列性を使用して大規模なQwen3-235B MoEモデルを提供する方法は次のようになります:
vllm serve Qwen/Qwen3-235B-A22B-FP8 \
--enable-reasoning \
--reasoning-parser deepseek_r1 \
--tensor-parallel-size 4
このコマンドを分解してみましょう:
Qwen/Qwen3-235B-A22B-FP8:これはモデル識別子で、Hugging Faceリポジトリのロケーションを指している可能性が高いです。FP8は8ビット浮動小数点量子化を使用していることを示し、FP16やBF16と比較してモデルのメモリフットプリントを削減します。これはこのような大規模モデルには重要です。--enable-reasoning:このフラグは、vLLM内でQwen3のハイブリッド思考能力を有効にするための重要なものです。--reasoning-parser deepseek_r1:Qwen3の思考出力には特定の形式があります。vLLMはこれを処理するためのパーサーを必要とします。ブログ記事によると、vLLMにはdeepseek_r1パーサーを使用すべきであり(SGLangはqwen3パーサーを使用)、これによりvLLMが思考ステップを正しく解釈し、最終的な応答から分離できるようになります。--tensor-parallel-size 4:これはvLLMに対し、モデルの重みと計算を4つのGPUに分散させるよう指示します。テンソル並列性は、単一のGPUに収まらないほど大きなモデルを実行するために不可欠です。この数は使用可能なGPUに基づいて調整します。
このコマンドを他のQwen3モデル(例:Qwen/Qwen3-30B-A3BやQwen/Qwen3-32B)に適応させ、tensor-parallel-sizeのようなパラメータをハードウェアに基づいて調整することができます。
3. vLLMサーバーとのインタラクション:vllm serveが実行されているとき、OpenAI API仕様を反映したAPIサーバー(デフォルトはhttp://localhost:8000)をホストします。標準ツールを使用してインタラクションできます:
- curl:
curl http://localhost:8000/v1/completions \
-H "Content-Type: application/json" \
-d '{
"model": "Qwen/Qwen3-235B-A22B-FP8", # 提供したモデル名を使用
"prompt": "LLMのMixture-of-Expertsの概念を説明してください。",
"max_tokens": 150,
"temperature": 0.7
}'
- Python OpenAIクライアント:
from openai import OpenAI
# ローカルvLLMサーバーを指す
client = OpenAI(base_url="http://localhost:8000/v1", api_key="EMPTY")
completion = client.completions.create(
model="Qwen/Qwen3-235B-A22B-FP8", # 提供したモデル名を使用
prompt="音楽を発見するロボットについての短いストーリーを書いてください。",
max_tokens=200
)
print(completion.choices[0].text)
4. パフォーマンスとユースケース:
vLLMは高いスループット(秒あたりの多くのリクエスト)と低レイテンシを必要とするシナリオで輝きます。その最適化により、以下のような用途に適しています:
- ローカルLLMを活用したアプリケーションの構築。
- 同時に複数のユーザーにモデルを提供。
- マルチGPU構成を必要とする大規模モデルのデプロイ。
- パフォーマンスが重要なプロダクション環境。
Apidogを使用したOllamaローカルAPIのテスト
Apidogは、OllamaのAPIモードと相性の良いAPIテストツールです。リクエストを送信し、応答を確認し、Qwen 3のセットアップを効率的にデバッグできます。
以下は、OllamaでApidogを使用する方法です:
- 新しいAPIリクエストを作成します:
- エンドポイント:
http://localhost:11434/api/generate - リクエストを送信し、Apidogのリアルタイムタイムラインで応答を監視します。
- ApidogのJSONPath抽出を使用して応答を自動的に解析します。この機能はPostmanのようなツールよりも優れています。


ストリーミング応答:
- リアルタイムアプリケーションのために、ストリーミングを有効にします:
- 強化されたストリーミング機能により、ストリーミングメッセージが統合され、デバッグが簡素化されます。
curl http://localhost:11434/api/generate -d '{"model": "gemma3:4b-it-qat", "prompt": "AIについての詩を書いてください。", "stream": true}'

このプロセスは、モデルが期待通りに機能していることを確認し、Apidogが貴重な追加となることを保証します。
結論
強力で多様なQwen3モデルファミリーのリリースと、OllamaやvLLMのような成熟したローカル実行ツールの組み合わせは、AI実践者にとってエキサイティングな時期を示しています。Ollamaのプラグアンドプレイのシンプルさを個人使用や実験に優先するか、堅牢なアプリケーション構築のための高性能サービング機能を求めるかに関係なく、最先端のLLMをローカルで実行することはこれまでになく実現可能です。
Qwen3-30B-A3Bやより大きな密バリアントのようなモデルを自分のハードウェアに持ち込むことで、前例のない制御、プライバシー、コスト効率を得ることができます。ハイブリッド思考や広範な多言語サポートなどの高度な機能を革新的なプロジェクトに活用できます。ハードウェアとソフトウェアのエコシステムが進化し続けることで、大規模言語モデルの力はますます民主化され、遠くのクラウドサーバーから私たちのローカルマシンにまで移行していくことでしょう。OllamaとvLLMを使用してQwen3を試し、このローカルAI革命の最前線を体験してください。
最大の生産性で開発チームが協力できる統合型のオールインワンプラットフォームが必要ですか?
Apidogはすべての要求に応え、Postmanをより手頃な価格で置き換えます!