
Mistral 3 のような大規模言語モデルをローカルマシンで実行することで、開発者はデータのプライバシー、推論速度、およびカスタマイズにおいて比類ない制御を得ることができます。AI ワークロードがますます要求の厳しいものになるにつれて、プロトタイピング、テスト、およびオフラインでのアプリケーション展開にはローカル実行が不可欠になります。さらに、Ollama のようなツールはこのプロセスを簡素化し、デスクトップまたはサーバーから Mistral 3 の機能を直接活用できるようにします。
このガイドでは、Mistral 3 のバリアントをローカルでインストールして実行するための詳細な手順を説明します。私たちは、エッジ展開に優れたオープンソースの Ministral 3 シリーズに焦点を当てています。最終的には、実際のタスクに合わせてパフォーマンスを最適化し、低遅延の応答とリソース効率を確保できるようになります。
Mistral 3 を理解する:AI におけるオープンソースの原動力
Mistral AI は、最新リリースであるMistral 3で境界を押し広げ続けています。開発者や研究者は、このモデルファミリーが精度、効率、アクセシビリティのバランスを取っていることを高く評価しています。独自の巨大モデルとは異なり、Mistral 3 はオープンソースの原則を受け入れ、Apache 2.0 ライセンスの下でリリースされています。この動きにより、コミュニティは制限なく修正、配布、革新を行うことができます。
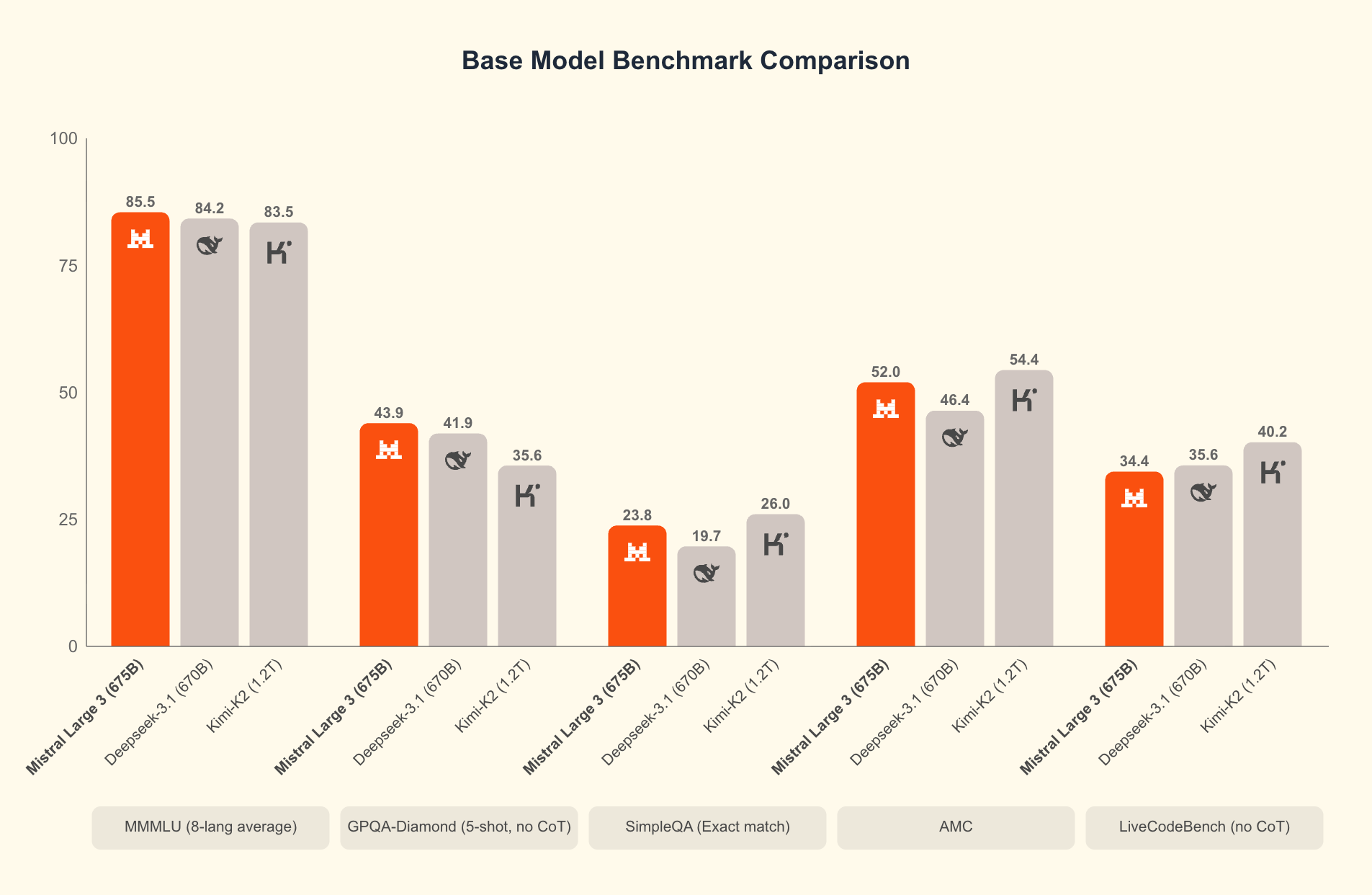
Mistral 3 の核となるのは、コンパクトな Ministral 3 シリーズと大規模な Mistral Large 3 の 2 つの主要なブランチです。Ministral 3 モデル(3B、8B、14B のパラメーターサイズで利用可能)は、リソースが制約された環境を対象としています。エンジニアは、これらのモデルを、すべてのワットとコアが重要となるローカルおよびエッジのユースケース向けに設計しています。たとえば、3B バリアントは、控えめな GPU を搭載したラップトップに快適に収まり、14B は、速度を犠牲にすることなく、マルチ GPU セットアップでその限界を押し広げます。
一方、Mistral Large 3 は、41B のアクティブなパラメーターと合計 675B のスパースな混合エキスパートアーキテクチャを採用しています。この設計により、クエリごとに適切なエキスパートのみが活性化され、計算オーバーヘッドが大幅に削減されます。開発者は、コーディング支援、ドキュメント要約、多言語翻訳などのタスク向けにインストラクションチューニングされたバージョンにアクセスできます。このモデルは 40 以上の言語をネイティブにサポートしており、非英語の対話で他のモデルを凌駕しています。
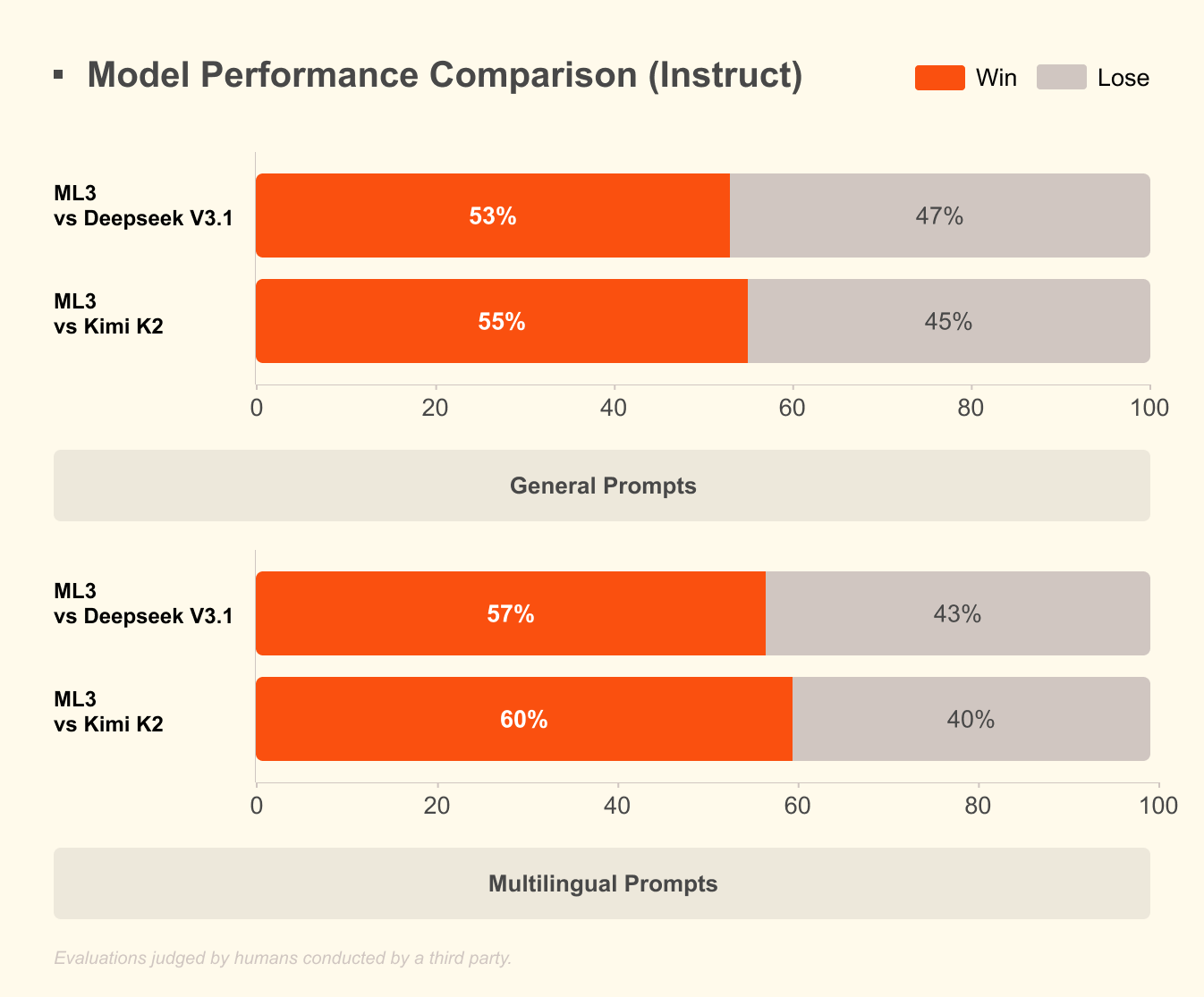
Mistral 3 を際立たせているのは何でしょうか?ベンチマークは、実際のシナリオにおけるその優位性を明らかにしています。科学的推論の厳密なテストである GPQA Diamond データセットでは、Mistral 3 のバリアントは、出力トークンが増加しても高い精度を維持します。たとえば、Ministral 3B Instruct モデルは、最大 20,000 トークンまで約 35-40% の精度を維持し、Gemma 2 9B のような大規模モデルに匹敵しながら、より少ないリソースを使用します。この効率は、NVFP4 圧縮などの高度な量子化技術に由来しており、出力品質を低下させることなくモデルサイズを削減します。
さらに、Mistral 3 はマルチモーダル機能を統合し、画像とテキストを並行して処理することで、視覚的質問応答やコンテンツ生成などのアプリケーションに対応します。これらのモデルをオープンソース化することで、迅速なイテレーションが促進されます。コミュニティはすでに、法律分析やクリエイティブライティングなどの専門分野向けにこれらのモデルをファインチューニングしています。その結果、Mistral 3 はフロンティア AI を民主化し、スタートアップや個々の開発者が大手テクノロジー企業と競合できるようにします。

理論から実践へと移行し、これらのモデルをローカルで実行することで、その可能性を最大限に引き出すことができます。クラウド API は遅延とコストを伴いますが、ローカル推論は数ミリ秒の応答を実現します。次に、これを実現するためのハードウェア要件を検討します。
なぜ Mistral 3 をローカルで実行するのか?開発者にとっての利点と効率向上
開発者がローカル実行を選択するのには、いくつかの説得力のある理由があります。まず、プライバシーが最優先されます。機密データは自分のマシンに残り、サードパーティのサーバーを介しません。医療や金融のような規制された業界では、このコンプライアンスの優位性は非常に貴重です。次に、コスト削減が迅速に蓄積されます。Mistral 3 の高い効率性により、トークンごとの料金が不要になり、大量のテストに最適です。
さらに、ローカル実行は実験を加速させます。プロンプトの反復、ハイパーパラメーターの微調整、モデルの連鎖をネットワーク遅延なしで行うことができます。ベンチマークでは、これが確認されています。コンシューマーハードウェアでは、Ministral 8B は 1 秒あたり 50〜60 トークンを達成し、クラウドセットアップに匹敵しながら、ダウンタイムはゼロです。
効率性は Mistral 3 の魅力の核心です。このモデルは低コストの推論に最適化されており、GPQA Diamond の結果が示すように、Ministral のバリアントは持続的な精度で Gemma 3 4B および 12B を上回っています。これは、長文コンテキストのタスクにとって重要です。出力が 20,000 トークンに延長されても、精度の低下は最小限に抑えられ、チャットボットやコードジェネレーターで信頼性の高いパフォーマンスを保証します。
さらに、Hugging Face のようなプラットフォームを介したオープンソースアクセスにより、Apidog のようなツールとシームレスに統合して API のプロトタイピングを行うことができます。拡張する前に Mistral 3 エンドポイントをローカルでテストし、開発と本番環境の間のギャップを埋めることができます。
ただし、成功は適切なセットアップにかかっています。ハードウェアが整ったら、インストールに進みます。この準備により、スムーズな操作とスループットの最大化が保証されます。
ローカル Mistral 3 展開のためのハードウェアおよびソフトウェア要件
Mistral 3 を起動する前に、システムの機能を評価してください。最小仕様には、3B モデルの場合、16GB RAM を搭載した最新の CPU (Intel i7 または AMD Ryzen 7) が含まれます。8B および 14B バリアントの場合、32GB RAM と、少なくとも 8GB VRAM を搭載した NVIDIA GPU (RTX 3060 以降) を割り当ててください。Apple Silicon ユーザーはユニファイドメモリの恩恵を受けます。16GB の M1 Pro は 3B を難なく処理し、M3 Max は 14B で優れています。
ストレージ要件は異なります。3B モデルは量子化された状態で約 2GB を占有し、14B では約 9GB にスケールアップします。高速な読み込みには SSD を使用してください。オペレーティングシステムは、Linux (Ubuntu 22.04) が最高のパフォーマンスを提供し、次に macOS Ventura+ が続きます。Windows 11 は WSL2 経由で動作しますが、GPU パススルーには調整が必要です。
ソフトウェア面では、Python 3.10 以降が基盤となります。GPU アクセラレーションを有効にするには、NVIDIA カード用に CUDA 12.1 をインストールします。これは、100ms 未満のレイテンシには不可欠です。CPU のみの実行には、ONNX Runtime のようなライブラリを活用してください。
量子化はここで極めて重要な役割を果たします。Mistral 3 は 4 ビットおよび 8 ビット形式をサポートしており、メモリフットプリントを 75% 削減しながら、95% の精度を維持します。bitsandbytes のようなツールはこれを自動的に処理します。
準備が整えば、インストールは簡単な手順で進みます。Ollama はそのシンプルさから推奨されますが、代替手段も存在します。この選択によりプロセスが合理化され、主要なセットアップ手順へとつながります。
Ollama のインストール:労力をかけずにローカル AI を実現するゲートウェイ
Ollama は、Mistral 3 のようなオープンソースモデルをローカルで実行するための最高のツールとして際立っています。この軽量プラットフォームは複雑さを抽象化し、CLI と API サーバーを 1 つのパッケージで提供します。開発者はそのクロスプラットフォームサポートとゼロコンフィグ GPU 検出を高く評価しています。
まず、公式サイト (ollama.com) から Ollama をダウンロードします。Linux の場合、以下を実行します。
curl -fsSL https://ollama.com/install.sh | sh
このスクリプトはバイナリをインストールし、サービスをセットアップします。`ollama --version` で確認してください。「ollama version 0.3.0」のような出力が期待されます。macOS の場合、DMG インストーラーが ARM 上の Intel エミュレーション用の Rosetta を含む依存関係を処理します。
Windows ユーザーは GitHub のリリースから EXE を取得します。インストール後、PowerShell 経由で起動します: `ollama serve`。Ollama はバックグラウンドでデーモン化され、ポート 11434 で REST API を公開します。
なぜ Ollama なのでしょうか?Ministral 3 を含むモデルをレジストリからプルし、組み込みの量子化機能を提供します。手動で Hugging Face をクローンする必要はありません。さらに、カスタムのファインチューニング用に Modelfiles をサポートしており、Mistral 3 のオープンソースの精神と一致しています。
Ollama の準備が整ったら、次にモデルをプルして実行します。この手順で、セットアップは機能的な AI ワークステーションへと変貌します。
Ollama を使用して Ministral 3 モデルをプルして実行する
Ollama のライブラリは Ministral 3 のバリアントをホストしています。
まず、利用可能なタグをリストアップします。
ollama list
3B モデルをダウンロードするには:
ollama pull ministral:3b-instruct-q4_0
このコマンドは、約 2GB をフェッチし、ハッシュによって整合性を検証します。プログレスバーがダウンロードを追跡し、通常、ブロードバンドでは数分で完了します。
インタラクティブセッションを起動します。
ollama run ministral-3
Ollama はモデルをメモリにロードし、後続のクエリのためにキャッシュをウォームアップします。プロンプトを直接入力します。たとえば、
>> 量子もつれを簡単に説明してください。

モデルは、インストラクションチューニングを活用して、リアルタイムで一貫性のある出力を生成します。`/bye` で終了します。
一般的な問題のトラブルシューティングですか?GPU の利用率が低い場合は、環境変数 `OLLAMA_NUM_GPU=999` を設定します。OOM エラーが発生した場合は、q3_K_M のように量子化レベルを下げます。
基本を超えて、Ollama の API はプログラムによるアクセスを可能にします。補完を curl で取得します。
curl http://localhost:11434/api/generate -d '{
"model": "ministral:3b-instruct-q4_0",
"prompt": "リストをソートする Python 関数を記述してください。",
"stream": false
}'
この JSON レスポンスには生成されたテキストが含まれており、API 開発中に Apidog と統合するのに最適です。
モデルの実行は始まりに過ぎません。最適化によってパフォーマンスが向上します。したがって、ハードウェアからあらゆる効率を引き出す技術について説明します。
Mistral 3 推論の最適化:速度、メモリ、精度のトレードオフ
効率性は、ローカル AI の成功を左右します。Mistral 3 の設計はここで輝きを放ちますが、調整によってさらに性能が向上します。まず、量子化から始めましょう。Ollama はデフォルトで Q4_0 を使用しており、サイズと忠実度のバランスが取れています。超低リソースの場合は、Q2_K を試してみてください。これは、パープレキシティコストを 10% 増加させる代わりに、メモリを半分にします。
GPU オーケストレーションは重要です。`OLLAMA_FLASH_ATTENTION=1` を介してフラッシュアテンションを有効にすると、長いコンテキストで 2 倍の速度向上が得られます。Mistral 3 は最大 128K トークンをサポートしており、GPQA スタイルのプロンプトで持続的な精度を検証してください。
バッチ処理はスループットを向上させます。Ollama の `/api/generate` を使用して複数のプロンプトを並行して処理し、非同期 Python クライアントを活用します。たとえば、ループをスクリプト化します。
import requests
import json
model = "ministral:8b-instruct-q4_0"
url = "http://localhost:11434/api/generate"
prompts = ["プロンプト 1", "プロンプト 2"]
for p in prompts:
response = requests.post(url, json={"model": model, "prompt": p})
print(json.loads(response.text)["response"])
これにより、マルチコアセットアップで 1 秒あたり 10 以上のクエリが処理されます。
メモリ管理はスワップを防ぎます。`nvidia-smi` で監視し、VRAM が上限に達した場合はレイヤーを CPU にオフロードします。vLLM のようなライブラリは Ollama と統合して継続的なバッチ処理を行い、A100s で 100 トークン/秒を維持します。
精度調整はどうでしょうか?ドメインデータで LoRA アダプターを使用してファインチューニングします。Hugging Face の PEFT ライブラリはこれを Ministral 3 に適用し、約 1GB の追加スペースが必要です。ファインチューニング後、`ollama create` を介して Ollama 形式にエクスポートします。
GPQA Diamond に対してセットアップをベンチマークします。精度とトークン数をグラフ化する評価スクリプトを作成し、Mistral のチャートを再現します。Ministral 8B のような高効率バリアントは 50%+ のスコアを維持し、Qwen 2.5 VL に対する優位性を強調しています。
これらの最適化は、高度なアプリケーションに備えるものです。そこで、Mistral 3 の適用範囲を広げる統合について検討します。
Mistral 3 を開発ツール、API などと統合する
ローカル Mistral 3 はエコシステムで繁栄します。Apidog と組み合わせて、AI を活用した API をモックアップします。Ollama にクエリを送信するエンドポイントを設計し、ペイロードをテストし、応答を検証します。すべてオフラインで実行できます。
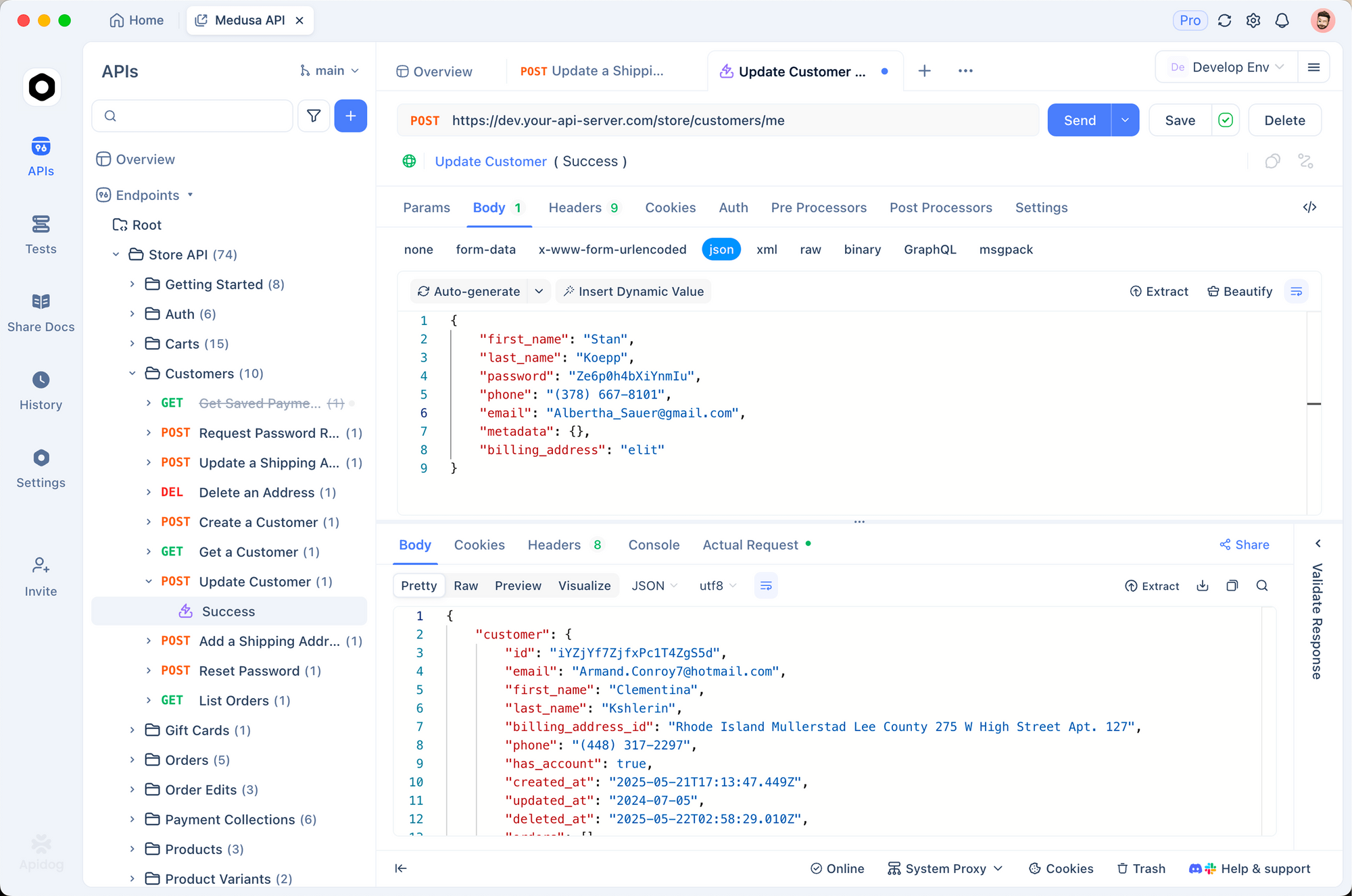
たとえば、Apidog で POST /generate ルートを作成し、Ollama の API に転送します。プロンプトテンプレートのコレクションをインポートし、Mistral 3 が多言語リクエストを完璧に処理できるようにします。
LangChain ユーザーは Mistral 3 をツールとチェーン接続します。
from langchain_ollama import OllamaLLM
from langchain_core.prompts import PromptTemplate
llm = OllamaLLM(model="ministral:3b-instruct-q4_0")
prompt = PromptTemplate.from_template("{text}をフランス語に翻訳してください。")
chain = prompt | llm
print(chain.invoke({"text": "こんにちは世界"}))
この設定は 1 分あたり 50 クエリを処理し、RAG パイプラインに最適です。
Streamlit ダッシュボードは出力を視覚化します。Ollama 呼び出しをアプリに埋め込み、Mistral 3 の推論を活用して動的な Q&A を提供するインタラクティブなチャットを可能にします。
セキュリティ上の考慮事項は?Nginx プロキシの背後で Ollama を実行し、エンドポイントのレート制限を行います。本番環境では、Docker でコンテナ化します。
FROM ollama/ollama
COPY Modelfile .
RUN ollama create mistral-local -f Modelfile
これにより環境が分離され、Kubernetes にスケールアウトできます。
アプリケーションが進化するにつれて、監視が重要になります。Prometheus のようなツールは遅延を追跡し、ベースライン効率からの逸脱をアラートします。
要約すると、これらの統合により、Mistral 3 はスタンドアロンモデルから多用途エンジンへと変貌します。しかし、課題も発生します。それらに対応することで、堅牢な展開が保証されます。
ローカル Mistral 3 実行における一般的な問題のトラブルシューティング
最適化されたセットアップでも障害に遭遇することはあります。CUDA の不一致がリストのトップです。`nvcc --version` でバージョンを確認してください。Mistral 3 は 11.8+ を許容するため、競合が発生した場合はダウングレードしてください。
モデルの読み込みに失敗しましたか?Ollama キャッシュをクリアします:`ollama rm ministral:3b-instruct-q4_0` を実行してから再プルします。破損したダウンロードはネットワークに起因する場合があります。`--insecure` は控えめに使用してください。
macOS では、Metal アクセラレーションは CUDA より遅れます。安定性のために CPU を強制するには:`OLLAMA_METAL=0` を設定します。Windows WSL ユーザーは `wsl --update` を介して NVIDIA ドライバーを有効にします。
過熱はラップトップを悩ませます。`nvidia-smi -pl 100` でスロットリングして電力を制限します。精度が低下した場合は、プロンプトを検査してください。Ministral 3 はインストラクト形式に優れています。
Reddit や Hugging Face のコミュニティフォーラムは、エッジケースの 90% を解決します。`OLLAMA_DEBUG=1` で診断のためにエラーをログに記録してください。
落とし穴を乗り越えれば、Mistral 3 は一貫した価値を提供します。最後に、そのより広範な影響について考察します。
結論:Mistral 3 をローカルで活用し、明日の AI イノベーションを実現
Mistral 3 は、パワーと実用性を兼ね備えることで、オープンソース AI を再定義します。Ollama を介してローカルで実行することで、開発者は他の方法では達成できない速度、プライバシー、コスト管理を実現します。モデルのプルから統合のファインチューニングまで、このガイドは実用的な手順を提供します。
大胆に実験しましょう。3B バリアントから始め、14B にスケールアップし、ベンチマークと比較して測定します。Mistral AI が進化するにつれて、ローカル実行はあなたを先行させます。
構築する準備はできましたか?Apidog を無料でダウンロードして、Mistral 3 セットアップを活用した API をプロトタイプ化しましょう。効率的な AI の未来はあなたのマシンから始まります。それを最大限に活用してください。