
Ollamaを使用してローカルでGemma 3を実行すると、クラウドサービスに依存することなく、AI環境を完全に制御できます。このガイドでは、Ollamaのセットアップ方法、Gemma 3のダウンロード、マシンでの実行方法について説明します。
なぜOllamaでGemma 3をローカルで実行するのか?
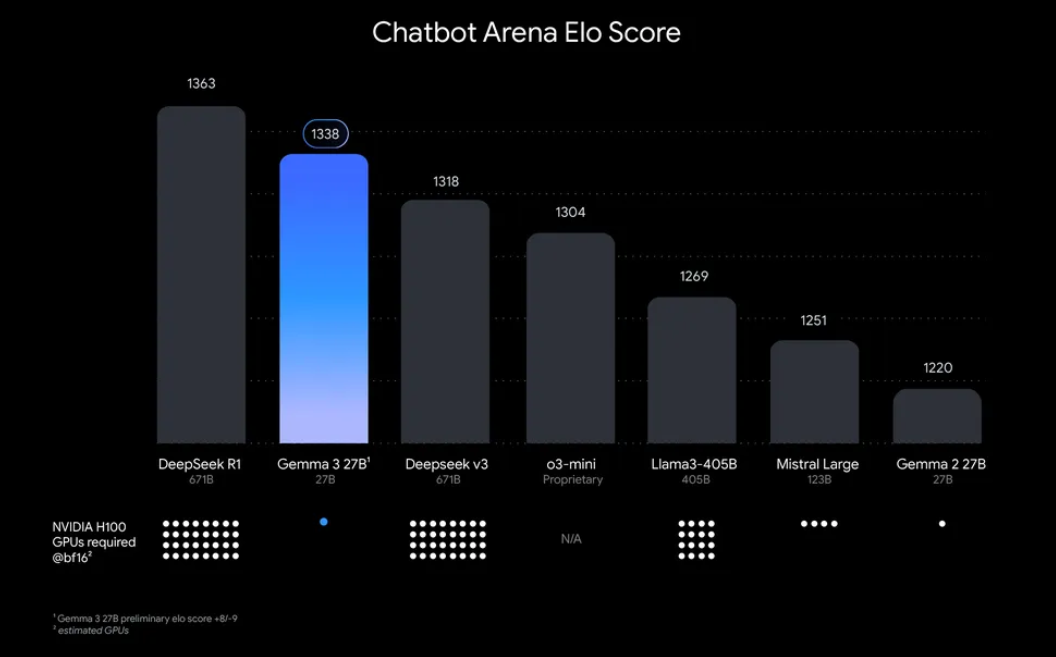
「なぜGemma 3をローカルで実行する必要があるのか?」そうですね、いくつかの説得力のある理由があります。第一に、ローカルデプロイメントはデータとプライバシーを完全に制御できるため、機密情報をクラウドに送信する必要がありません。さらに、継続的なAPI使用料金を回避できるため、コスト効率も良いです。また、Gemma 3の効率性により、27Bモデルでも単一のGPUで実行可能なので、控えめなハードウェアを持つ開発者にもアクセスしやすくなっています。
Ollamaは、大規模言語モデル(LLM)をローカルで実行するための軽量プラットフォームであり、このプロセスを簡素化します。モデルの重み、設定、依存関係を使いやすい形式にパッケージしています。このGemma 3とOllamaの組み合わせは、自己調整やアプリケーション構築、マシン上でのAIワークフローのテストに最適です。それでは、袖をまくって始めましょう!
Gemma 3をOllamaで実行するために必要なもの
セットアップに入る前に、以下の前提条件を確認してください。
- 互換性のあるマシン: 最適なパフォーマンスにはNVIDIAを推奨するGPUを搭載したコンピュータ、または強力なCPUが必要です。27Bモデルには相当なリソースが必要ですが、1Bや4Bのような小さいバージョンはあまり強力でないハードウェアでも実行可能です。
- Ollamaをインストール: MacOS、Windows、Linux用のOllamaをダウンロードしてインストールします。ollama.comから入手できます。
- 基本的なコマンドラインスキル: ターミナルまたはコマンドプロンプトを使用してOllamaと対話します。
- インターネット接続: 最初にGemma 3モデルをダウンロードする必要がありますが、一度ダウンロードすればオフラインで実行できます。
- オプション: APIテスト用のApidog: Gemma 3をAPIと統合する予定がある場合、またはその応答をプログラム的にテストしたい場合は、Apidogの直感的なインターフェースで時間と労力を節約できます。
準備が整ったら、インストールとセットアッププロセスに入りましょう。
ステップバイステップガイド: OllamaのインストールとGemma 3のダウンロード
1. マシンにOllamaをインストール
OllamaはローカルLLMデプロイを簡単にします。インストールは簡単です。やり方は次のとおりです。
- MacOS/Windowsの場合: ollama.comにアクセスして、オペレーティングシステム用のインストーラーをダウンロードします。画面の指示に従ってインストールを完了してください。
- Linux(例: Ubuntu)の場合: ターミナルを開き、次のコマンドを実行します。
curl -fsSL https://ollama.com/install.sh | sh
このスクリプトは、ハードウェア(GPUを含む)を自動的に検出し、Ollamaをインストールします。
インストール後、次のコマンドを実行してインストールを確認します。
ollama --version

現在のバージョン番号が表示され、Ollamaが使用可能であることが確認できます。
2. Ollamaを使用してGemma 3モデルを取得
Ollamaのモデルライブラリには、Hugging FaceやGoogleのAIソリューションとの統合のおかげでGemma 3が含まれています。Gemma 3をダウンロードするには、ollama pullコマンドを使用します。
ollama pull gemma3

小さなモデルについては、次のコマンドを使用できます。
ollama pull gemma3:12bollama pull gemma3:4bollama pull gemma3:1b
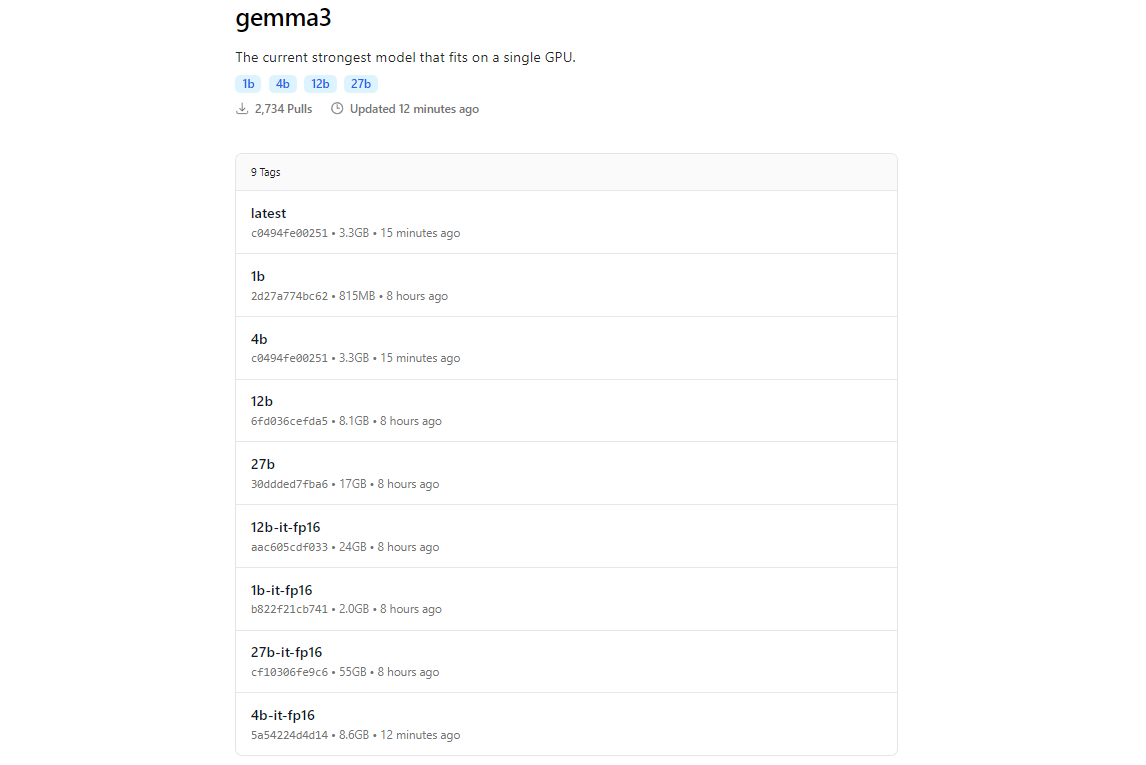
ダウンロードサイズはモデルによって異なります。27Bモデルは数ギガバイトになると予想されるため、十分なストレージを確保してください。Gemma 3モデルは効率のために最適化されていますが、大きなバリエーションにはそれなりのハードウェアが必要です。
3. インストールの確認
ダウンロードが完了したら、すべてのモデルをリストアップしてモデルが利用可能か確認します。
ollama list

リストにgemma3(または選択したサイズ)が表示されているはずです。そこにあれば、Gemma 3をローカルで実行する準備が整っています!
OllamaでGemma 3を実行する: インタラクティブモードとAPI統合
インタラクティブモード: Gemma 3と会話する
Ollamaのインタラクティブモードを使用すると、ターミナルから直接Gemma 3と会話できます。開始するには次のコマンドを実行します。
ollama run gemma3
クエリを入力できるプロンプトが表示されます。例えば、次のように試してください。
Gemma 3の主な機能は何ですか?
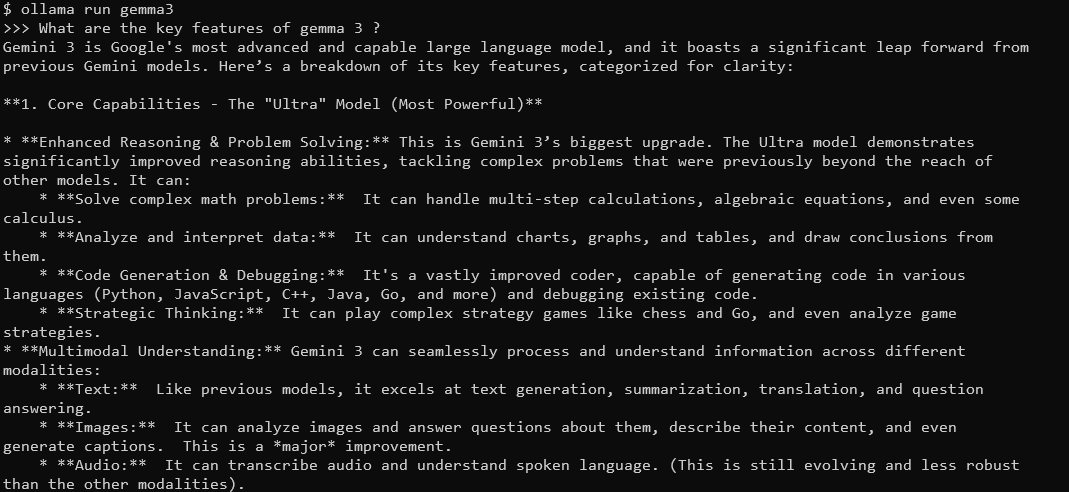
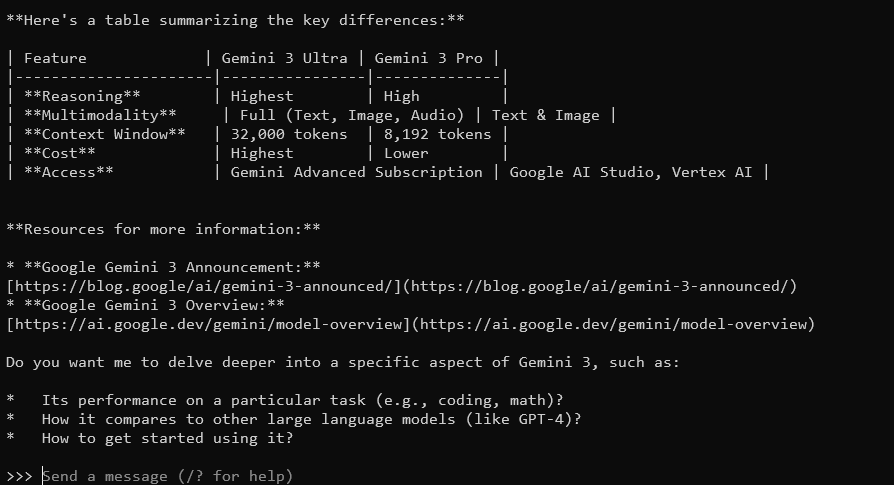
Gemma 3は、128Kのコンテキストウィンドウとマルチモーダル機能を備え、詳細でコンテキストを考慮した回答を返します。140以上の言語をサポートし、テキスト、画像、さらには(特定のサイズの)ビデオ入力を処理できます。
終了するには、Ctrl+Dまたは/byeと入力します。
Gemma 3とOllama APIの統合
アプリケーションを構築したりインタラクションを自動化したりしたい場合、Ollamaには使用できるAPIが用意されています。ここで、Apidogがその役に立つのです。ユーザーフレンドリーなインターフェースがAPIリクエストを効率的にテストおよび管理する手助けをします。始め方は次の通りです。
Ollamaサーバーを起動: 次のコマンドを実行してOllamaのAPIサーバーを起動します。
ollama serve
これにより、デフォルトでlocalhost:11434にサーバーが起動します。
APIリクエストを行う: HTTPリクエストを通じてGemma 3と対話できます。例えば、curlを使用してプロンプトを送信します。
curl http://localhost:11434/api/generate -d '{"model": "gemma3", "prompt": "フランスの首都はどこですか?"}'
応答にはGemma 3の出力がJSON形式で含まれます。
テストにApidogを使用: Apidogを無料でダウンロードし、Gemma 3の応答をテストするためのAPIリクエストを作成します。Apidogのビジュアルインターフェースを使うと、エンドポイント(http://localhost:11434/api/generate)を入力し、JSONペイロードを設定し、複雑なコードを書くことなく応答を分析できます。これは、統合のデバッグや最適化に特に役立ちます。
ApidogでのSSEテストの使用に関するステップバイステップガイド
最適化されたSSEテスト機能を使用するプロセスを、Auto-Merge機能の向上を伴って進めていきましょう。リアルタイムのデバッグ体験を最大化するために、以下の手順に従って設定してください。
ステップ1: 新しいAPIリクエストを作成
Apidogで新しいHTTPプロジェクトを開始します。新しいエンドポイントを追加し、APIまたはAIモデルのエンドポイントのURLを入力します。これはリアルタイムデータストリームをテストおよびデバッグするための出発点です。
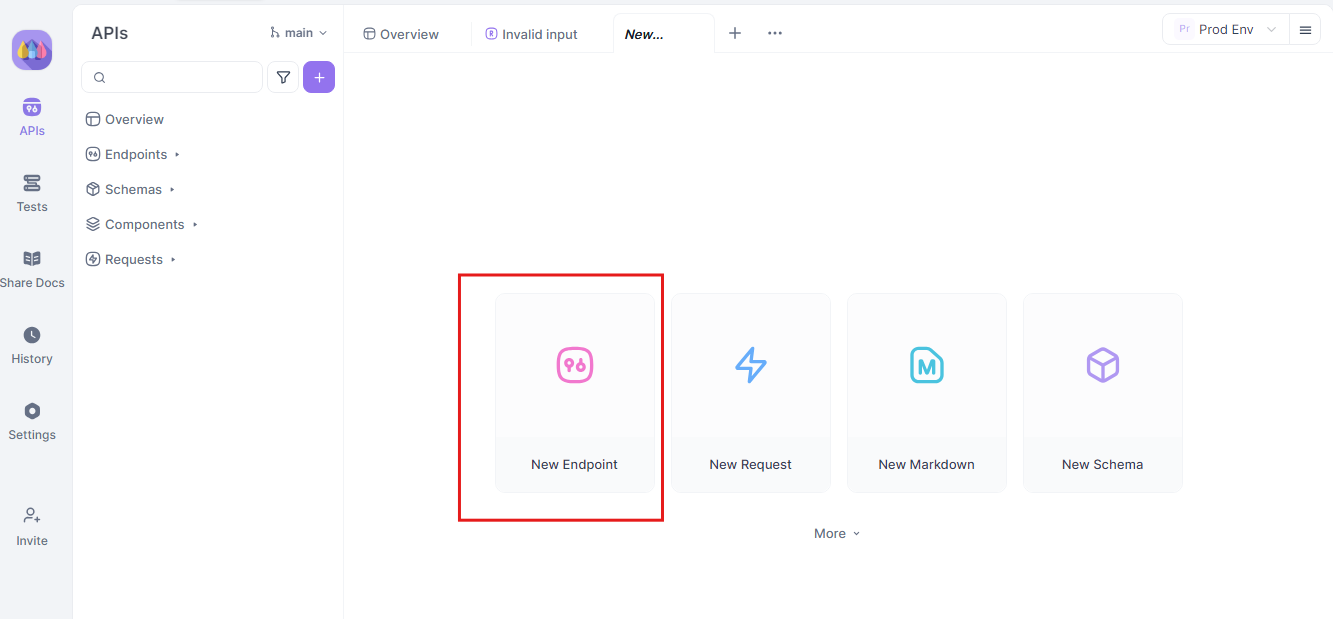
ステップ2: リクエストの送信
エンドポイントの設定が完了したら、APIリクエストを送信します。応答ヘッダーを注意深く観察してください。ヘッダーにContent-Type: text/event-streamが含まれている場合、Apidogは自動的に応答をSSEストリームとして認識し解釈します。この検出は、後続の自動マージプロセスに重要です。

ステップ3: リアルタイムタイムラインの監視
SSE接続が確立されると、Apidogはすべての受信SSEイベントがリアルタイムで表示される専用タイムラインビューを開きます。このタイムラインは新しいデータが到着するたびに更新され、データの流れを正確に監視できるようになります。タイムラインは生データの単なるダンプではなく、データがいつどのように送信されたのかを正確に把握できるように構造化された視覚化です。
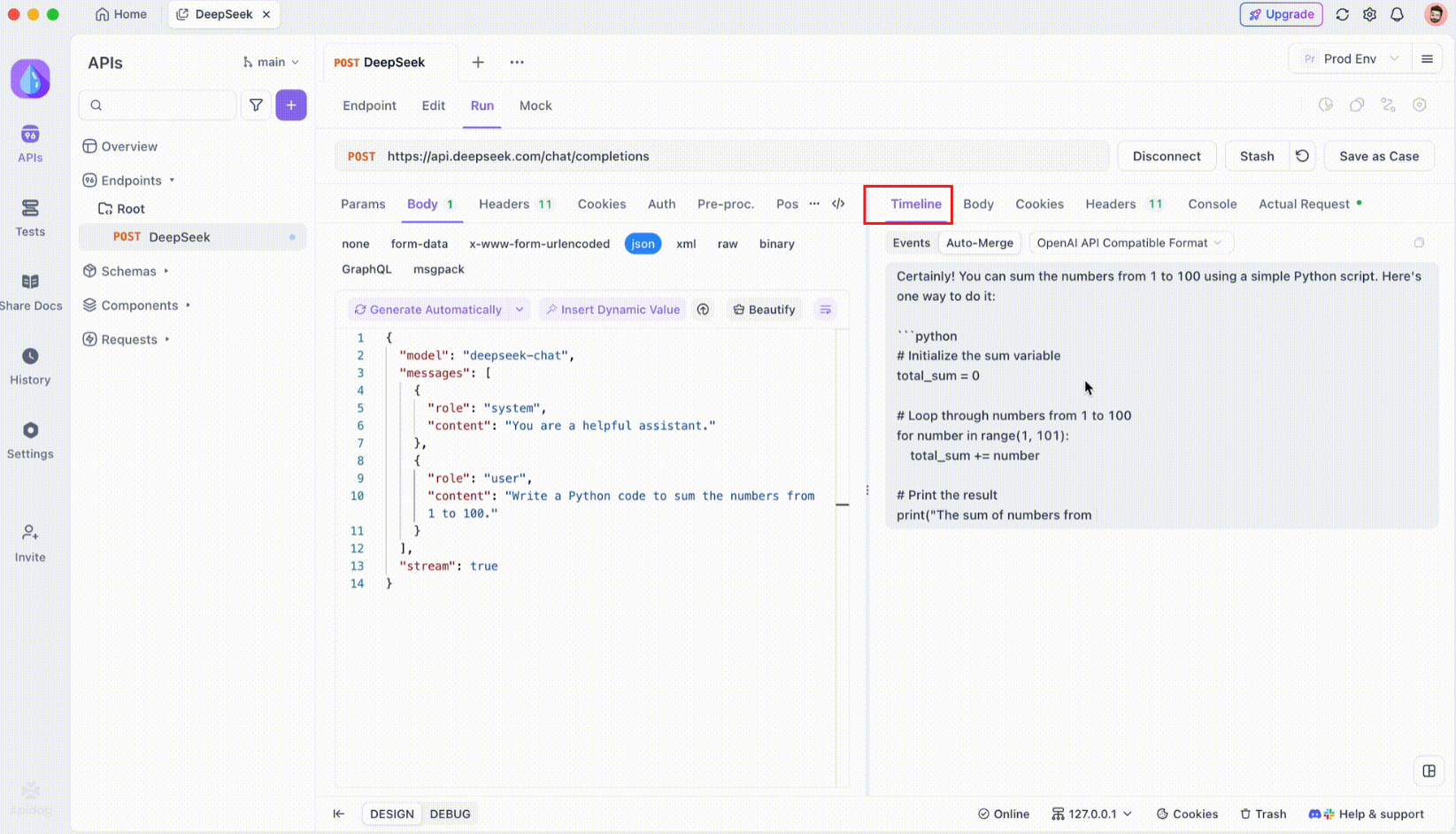
ステップ4: 自動マージメッセージ
ここで魔法が起こります。Auto-Merge機能を使用すると、Apidogは人気のAIモデル形式を自動的に認識し、断片化されたSSE応答を完全な応答にマージします。このステップには以下が含まれます。
- 自動認識: Apidogは、応答がサポートされている形式(OpenAI、Gemini、Claudeなど)であるかどうかを確認します。
- メッセージマージ: 形式が認識されると、プラットフォームはすべてのSSE断片を自動的に組み合わせ、シームレスで完全な応答を提供します。
- 視覚化の強化: DeepSeek R1などの特定のAIモデルの場合、タイムラインはモデルの思考プロセスも表示し、生成された応答の背後にある理由を説明する追加の層の洞察を提供します。
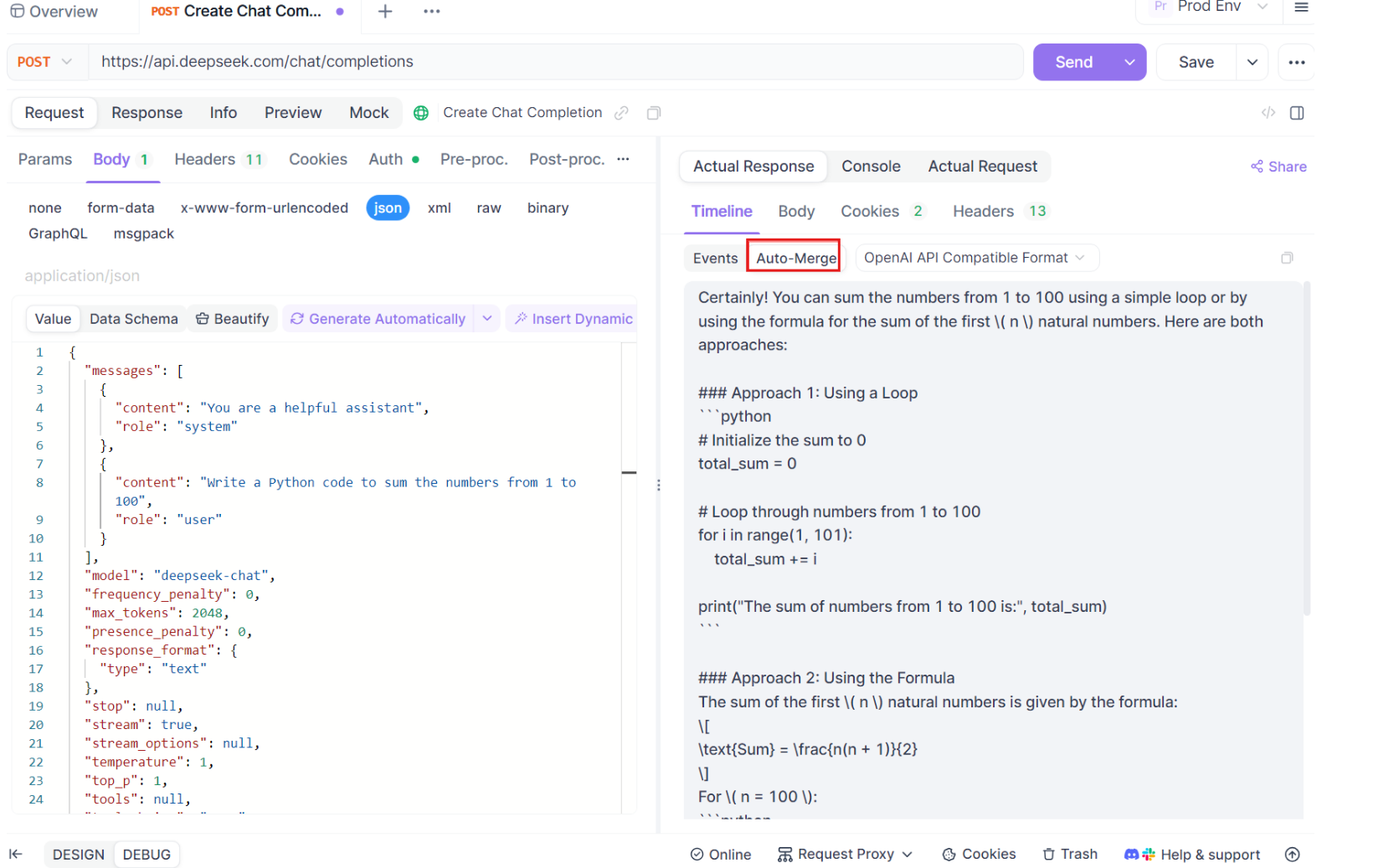
この機能は、AI駆動のアプリケーションを扱う際に特に便利で、応答のすべての部分が手動の介入なしに完全にキャプチャされ、提示されることを保証します。
ステップ5: JSONPath抽出ルールの設定
すべてのSSE応答が自動的に組み込み形式に準拠するわけではありません。カスタム抽出が必要なJSON応答を扱う場合、ApidogではJSONPathルールを設定できます。例えば、もし生SSE応答にJSONオブジェクトが含まれていて、contentフィールドを抽出する必要がある場合、以下のようにJSONPath設定を行うことができます。
- JSONPath:
$.choices[0].message.content - 説明:
$はJSONオブジェクトのルートを指します。choices[0]はchoices配列の最初の要素を選択します。message.contentはメッセージオブジェクト内のコンテンツフィールドを指定します。
この構成は、SSE応答から希望するデータを抽出する方法をApidogに指示し、非標準応答でも効果的に処理されることを保証します。
結論
Ollamaを使用してローカルでGemma 3を実行することは、マシンを離れることなくGoogleの高度なAI機能を活用する素晴らしい方法です。Ollamaのインストールからモデルのダウンロード、ターミナルまたはAPI経由での対話まで、このガイドではすべてのステップを説明しました。マルチモーダル機能、多言語サポート、そして印象的なパフォーマンスを備えたGemma 3は、開発者やAI愛好者にとって革命的な存在です。Apidogのようなツールを活用してシームレスなAPIテストと統合を行い、Gemma 3プロジェクトを強化するために今日中に無料でダウンロードしてください!
ノートパソコンで1Bモデルをいじっているときも、GPUリグで27Bモデルの限界を押し広げているときも、今や可能性を探求する準備が整いました。楽しいコーディングを!Gemma 3で素晴らしいものを構築するのを楽しみしています!


