
開発者やAI愛好家は、莫大なリソースを要求せずに優れたパフォーマンスを発揮する効率的なモデルを常に求めています。Googleは、2億7000万のパラメータを持つコンパクトな言語モデル、Gemma 3 270Mを発表しました。このモデルはGemma 3ファミリーで最小であり、オンデバイスのタスクに最適化されています。テキスト生成、質問応答、要約、推論といった機能がすべてローカルで実行可能です。
Gemma 3 270Mは32,000トークンのコンテキスト長をサポートしており、大量の入力を効果的に処理できます。さらに、Q4_0 Quantization Aware Training (QAT) のような量子化技術を組み込むことで、品質を犠牲にすることなくリソース要件を削減しています。その結果、フルプレシジョンモデルに近いパフォーマンスを、より少ないメモリと計算量で実現します。
しかし、Gemma 3 270Mを特に魅力的にしているのは、そのアクセシビリティにあります。ラップトップやモバイルデバイスを含む標準的なハードウェアで実行でき、プライバシーと低遅延のアプリケーションを促進します。次に、このモデルが、効率がイノベーションを推進する広範なAI開発トレンドにどのように適合するかを検討します。
Gemma 3 270Mのアーキテクチャを理解する
Googleは、埋め込み用に256,000トークンの語彙を持つ1億7000万のパラメータと、トランスフォーマーブロック用に1億のパラメータを特徴とするトランスフォーマーベースのアーキテクチャ上にGemma 3 270Mを構築しています。この設定により、多言語サポートとニッチなタスク処理が可能になります。INT4量子化、ロータリー位置埋め込み、グループクエリ注意などの技術から恩恵を受け、推論速度と軽量性が向上します。
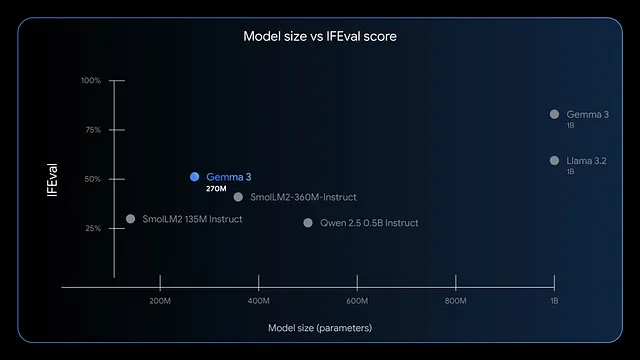
さらに、このモデルは命令追従とデータ抽出に優れています。ベンチマークではIFEvalで高いF1スコアを示しており、評価タスクでの強力なパフォーマンスを示しています。GPT-4やPhi-3 Miniのようなより大規模なモデルと比較して、Gemma 3 270Mは効率性を優先し、AppleのM4 Maxのようなデバイスで4ビットモードで200MB未満しか使用しません。
その結果、リアルタイムの感情分析や医療エンティティ抽出など、迅速な応答が求められるシナリオに展開できます。しかし、その小さなサイズは創造性を制限しません。クリエイティブライティングや金融コンプライアンスチェックにも適用できます。次に、このモデルをローカルで実行する利点を評価します。
Gemma 3 270Mをローカルで実行する利点
データをデバイス上に保持することでプライバシーを強化し、情報漏洩のリスクがあるクラウド送信を回避できます。Gemma 3 270Mはレイテンシを削減し、数秒ではなくミリ秒単位で応答を返します。さらに、クラウドベースのAPIのサブスクリプション料金を回避できるため、コストも削減できます。
さらに、このモデルのエネルギー効率は際立っています。INT4量子化モードで25回の会話を行った場合でも、Pixel 9 Proのバッテリーのわずか0.75%しか消費しません。この特性は、電力が重要なモバイルコンピューティングやエッジコンピューティングに適しています。また、LoRAのようなツールを使ったファインチューニングにより、最小限のデータでモデルを簡単にカスタマイズできます。
それにもかかわらず、ローカル実行は小規模チームや個人開発者に力を与えます。eコマースのクエリルーティングや法律文書の構造化などのアプリケーションを自由に試行錯誤できます。次に進む前に、システムが要件を満たしているか確認してください。
Gemma 3 270M推論のシステム要件
Gemma 3 270Mは控えめなハードウェア要件で、アクセスしやすいです。CPUのみの推論では、最低4GBのRAMとIntel Core i5または同等の最新プロセッサが必要です。ただし、GPUアクセラレーションは速度を向上させます。量子化バージョンでは、2GB VRAMのNVIDIAカードで十分です。
具体的には、4ビットモードではモデルが200MBのメモリに収まるため、リソースが限られたデバイスでも実行できます。AppleシリコンユーザーはMLX-LMの恩恵を受け、M4 Maxで毎秒650トークン以上を達成できます。ファインチューニングには、小さなデータセットを効率的に処理するために、8GBのRAMと4GB VRAMのGPUを割り当ててください。
重要な点として、Windows、macOS、Linuxなどのオペレーティングシステムで動作しますが、ライブラリの互換性のためにPython 3.10+を確保してください。ストレージはモデルファイルに約1GB必要です。これらが揃っていれば、問題なくインストールして実行できます。次に、インストール方法を探ってみましょう。
Gemma 3 270Mをローカルで実行するための適切なツールの選択
いくつかのフレームワークがGemma 3 270Mをサポートしており、それぞれ独自の強みを持っています。Hugging Face Transformersは、Pythonスクリプトと統合のための柔軟性を提供します。LM Studioは、モデル管理のためのユーザーフレンドリーなインターフェースを提供します。
さらに、llama.cppは効率的なC++ベースの推論を可能にし、低レベルの最適化に最適です。Appleデバイスの場合、MLXはMシリーズチップでのパフォーマンスを最適化します。あなたの専門知識に基づいて選択してください。初心者はLM Studioを好み、開発者はTransformersを選ぶ傾向があります。
このように、これらのツールはアクセスを民主化します。以下のセクションでは、一般的な方法のステップバイステップガイドに従ってください。
ステップバイステップガイド:Hugging Face TransformersでGemma 3 270Mを実行する
まず、必要なライブラリをインストールします。ターミナルを開いて実行します。
pip install transformers torch
このコマンドはTransformersとPyTorchを取得します。次に、Pythonスクリプトでコンポーネントをインポートします。
from transformers import AutoTokenizer, AutoModelForCausalLM
モデルとトークナイザーをロードします。
model_name = "google/gemma-3-270m"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto")
device_map="auto"は、利用可能な場合にモデルをGPUに配置します。入力を準備します。
input_text = "Explain quantum computing in simple terms."
inputs = tokenizer(input_text, return_tensors="pt").to(model.device)
出力を生成します。
outputs = model.generate(**inputs, max_new_tokens=200)
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(response)
これにより、一貫性のある説明が生成されます。最適化のために、量子化を追加します。
from transformers import BitsAndBytesConfig
quant_config = BitsAndBytesConfig(load_in_4bit=True)
model = AutoModelForCausalLM.from_pretrained(model_name, quantization_config=quant_config)
量子化はメモリ使用量を削減します。ゲート付きモデルの場合は、Hugging Faceへのログインを確実に行うことでエラーを処理します。
from huggingface_hub import login
login(token="your_hf_token")
トークンはHugging Faceアカウントから取得してください。この設定で、推論を繰り返し実行できます。ただし、Pythonユーザーでない場合は、次にLM Studioを検討してください。
ステップバイステップガイド:LM StudioでGemma 3 270Mを実行する
LM Studioは直感的なインターフェースを提供します。lmstudio.aiからダウンロードしてインストールしてください。
アプリを起動し、モデルハブで「gemma-3-270m」を検索します。
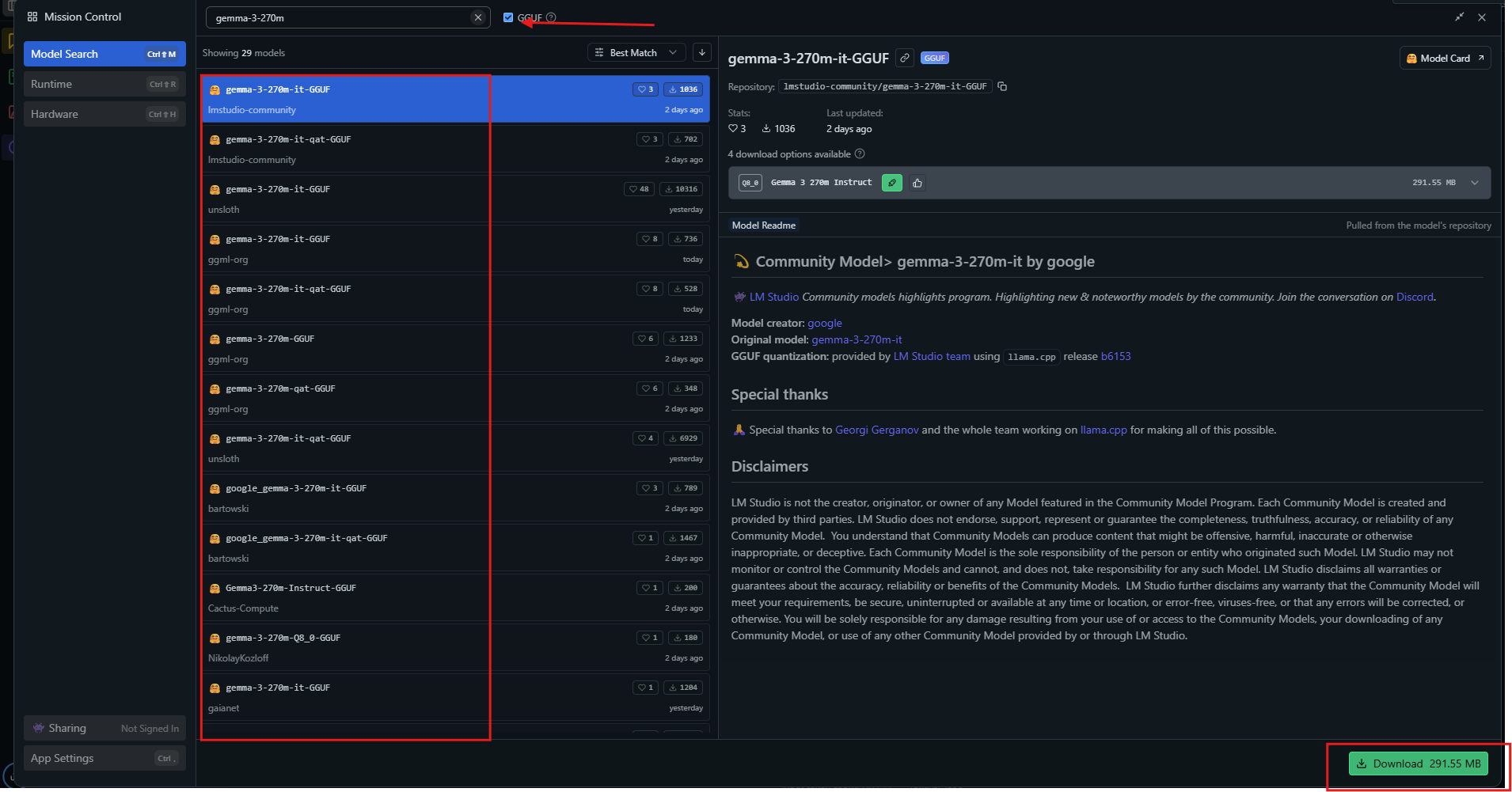
Q4_0のような量子化されたバリアントを選択してダウンロードします。準備ができたら、サイドバーからモデルをロードします。設定を調整します。コンテキストを32kに、温度を1.0に設定します。
チャットウィンドウにプロンプトを入力し、送信を押します。LM Studioはトークン速度とともに応答を表示します。統合されたツールを介してチャットをエクスポートしたり、ファインチューニングしたりできます。
高度な使用のために、設定でGPUオフロードを有効にします。LM Studioは自動的に最適なソースを選択し、互換性を確保します。この方法は視覚的な学習者に向いています。さらに、パフォーマンス調整のためにllama.cppを検討してください。
ステップバイステップガイド:llama.cppでGemma 3 270Mを実行する
llama.cppは高効率の推論を提供します。リポジトリをクローンします。
git clone https://github.com/ggerganov/llama.cpp
ビルドします。
make -j
Hugging FaceからGGUFファイルをダウンロードします。
huggingface-cli download unsloth/gemma-3-270m-it-GGUF --include "*.gguf"
推論を実行します。
./llama-cli -m gemma-3-270m-it-Q4_K_M.gguf -p "Build a simple AI app."
GPUをフル活用するために、--n-gpu-layers 999のようなパラメータを指定します。llama.cppは量子化レベルをサポートしており、速度と精度のバランスを取ります。NVIDIA GPU用にCUDAでコンパイルします。
make GGML_CUDA=1
これにより処理が高速化されます。llama.cppは組み込みシステムで優れています。次に、実際の例でモデルを適用します。
Gemma 3 270Mをローカルで使用する実践例
感情分析器を作成します。顧客のレビューを入力すると、モデルがそれらをポジティブまたはネガティブに分類します。Pythonでスクリプトを作成します。
prompt = "Classify: This product is amazing!"
inputs = tokenizer(prompt, return_tensors="pt")
outputs = model.generate(**inputs)
print(tokenizer.decode(outputs[0]))
Gemma 3 270Mは「Positive」と出力します。要約に拡張します。
text = "Long article here..."
prompt = f"Summarize: {text}"
# Generate summary
コンテンツを効果的に要約します。質問応答には、次のようにクエリを実行します。
「気候変動の原因は何ですか?」
モデルは温室効果ガスについて説明します。医療分野では、メモからエンティティを抽出します。これらの用途は汎用性を示しています。さらに、専門化のためにファインチューニングを行います。
Gemma 3 270Mをローカルでファインチューニングする
ファインチューニングはモデルを適応させます。Hugging FaceのPEFTライブラリを使用します。
pip install peft
LoRA設定でロードします。
from peft import LoraConfig, get_peft_model
lora_config = LoraConfig(r=16, lora_alpha=32, target_modules=["q_proj", "v_proj"])
model = get_peft_model(model, lora_config)
データセットを準備し、トレーニングします。
from transformers import Trainer, TrainingArguments
trainer = Trainer(model=model, args=TrainingArguments(output_dir="./results"))
trainer.train()
LoRAは少ないデータで済み、控えめなハードウェアでも迅速に完了します。アダプターを保存して再ロードします。これにより、チェスの動きの予測のようなカスタムタスクでのパフォーマンスが向上します。ただし、過学習には注意してください。
Gemma 3 270Mのパフォーマンス最適化のヒント
4ビットまたは8ビットに量子化することで速度を最大化します。複数の推論にはバッチ処理を使用します。推奨されるように、温度を1.0、top_k=64、top_p=0.95に設定します。
GPUでは、混合精度を有効にします。長いコンテキストの場合、KVキャッシュを慎重に管理します。nvidia-smiなどのツールでVRAMを監視します。最適化のためにライブラリを定期的に更新します。
その結果、これらの調整により、適切なハードウェアで毎秒130トークン以上を達成できます。プロンプト内の二重BOSトークンのような一般的な落とし穴を避けてください。実践を積むことで、効率的な実行を実現できます。
結論
これで、Gemma 3 270Mをローカルで実行するための知識が身につきました。セットアップから最適化まで、各ステップで能力が構築されます。その可能性を実現するために、実験し、ファインチューニングし、デプロイしてください。このような小さなモデルは、AIのアクセシビリティに大きな影響を与えます。