
正規表現、通常はregexまたはregexpと略されるものは、Rubyにおいてテキストパターンを扱うための強力なツールです。これにより、特定のパターンに基づいて文字列を検索し、一致させ、抽出し、操作することができます。ユーザー入力のバリデーション、データのパース、複雑なテキスト処理を行う際には、Rubyの正規表現が簡潔で柔軟な解決策を提供します。
このチュートリアルでは、Rubyの正規表現の基本から応用技術までを導いていきます。
APIテストのワークフローを効率化したいRuby開発者は、主要な側面でPostmanを上回る強力な代替手段であるApidogを検討すべきです。
Apidogは、API文書、デバッグ、自動テスト、モックを1つの統合プラットフォームに組み合わせており、Postmanの断片的なアプローチよりもより統合された体験を提供します。

直感的なインターフェース、組み込みのスキーマバリデーション、および包括的なチームコラボレーション機能を備えたApidogは、複雑なAPIプロジェクトの管理を大幅に容易にします。

Ruby開発者は、コマンドラインインターフェースを介した自動化の堅牢なサポート、バージョン管理のためのシームレスなGit統合、および正確な文書をRubyアプリケーションとともに維持するために不可欠な優れたOpenAPI/Swagger互換性をAPIDOGから大いに評価するでしょう。
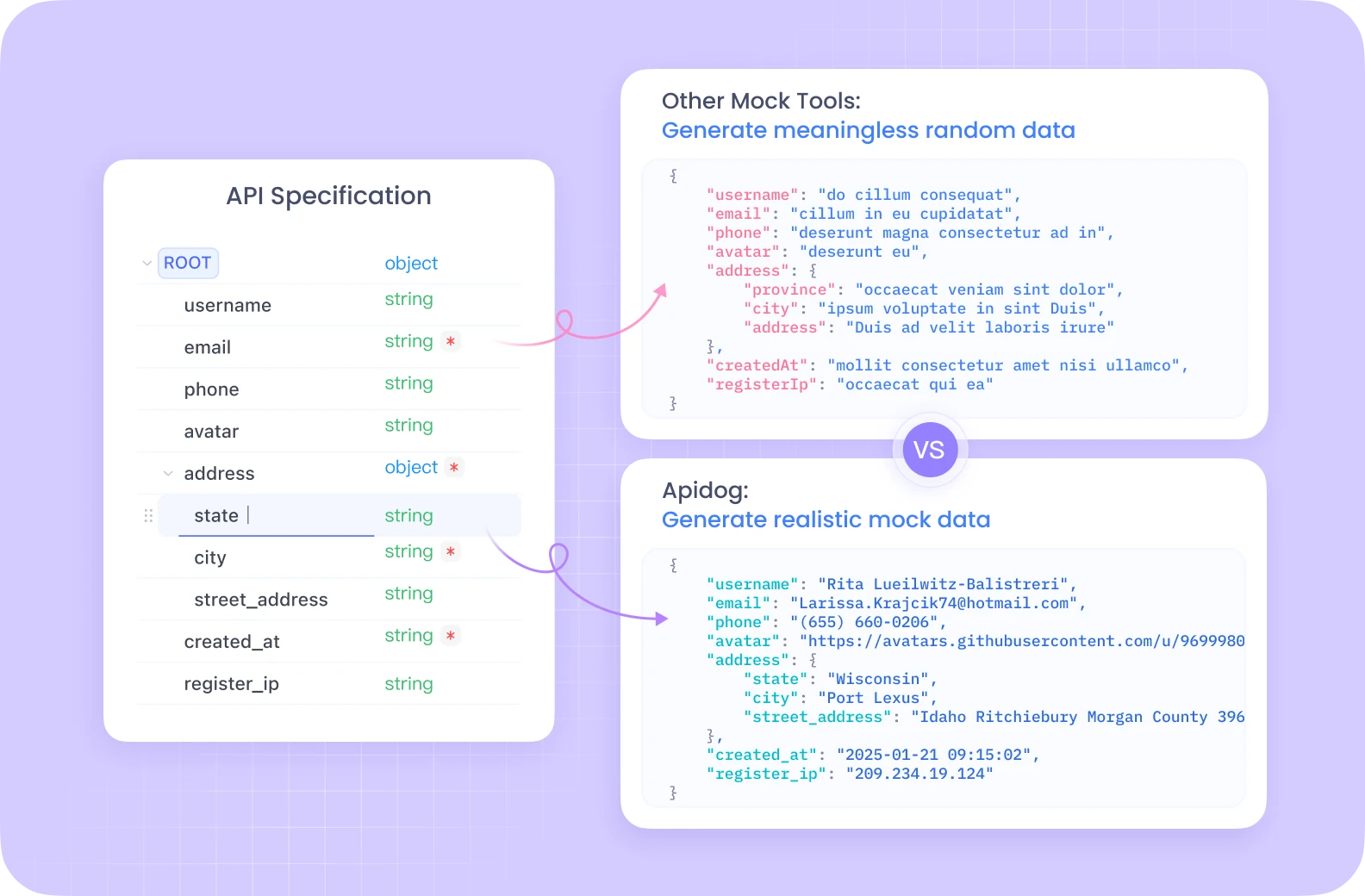
RailsでRESTfulサービスを構築する場合でも、Sinatraでマイクロサービスを作成する場合でも、ApidogのオールインワンツールキットはPostmanユーザーが悩まされるコンテキスト切り替えを排除し、最も重要なこと、すなわち素晴らしいRubyコードを書くことに集中できるようにします。
Rubyの正規表現の作成
Rubyでは、正規表現を作成する方法がいくつかあります:
方法1:Rubyの正規表現でスラッシュを使用
Rubyで正規表現を作成する最も一般的な方法は、パターンをスラッシュで囲むことです:
/Ruby/ # "Ruby"に一致する正規表現を作成
方法2:Rubyの正規表現でパーセント記法を使用
%rインジケータを使ってパーセント記法を使用することもできます:
%r(Ruby) # /Ruby/と同じ
これは、パターンに多くのスラッシュが含まれている場合に特に便利で、過剰なエスケープを回避するのに役立ちます。
方法3:Rubyの正規表現のためのRegexpクラスの使用
もう1つのアプローチは、Regexp.newコンストラクタを使用することです:
Regexp.new("Ruby") # /Ruby/と同じ
すべての方法がRegexpクラスのインスタンスを作成します。
基本的なRubyの正規表現シンボル
Rubyの正規表現は、異なるパターンを表現するために特別なシンボルを使用します。基本的なものは以下の通りです:
| シンボル | 説明 | 例 | 一致 |
|---|---|---|---|
. |
任意の1文字に一致 | /a.b/ |
"axb", "a2b", "a b" |
* |
前の要素の0回以上の繰り返しに一致 | /ab*c/ |
"ac", "abc", "abbc" |
+ |
前の要素の1回以上の繰り返しに一致 | /ab+c/ |
"abc", "abbc", "abbbc" |
? |
前の要素の0回または1回の繰り返しに一致 | /ab?c/ |
"ac", "abc" |
\| |
選択(OR) | /cat\|dog/ |
"cat", "dog" |
[] |
文字クラス - 列挙された任意の1文字に一致 | /[aeiou]/ |
"a", "e", "i", "o", "u" |
() |
キャプチャグループを作成 | /(abc)+/ |
"abc", "abcabc" |
^ |
文字列の開始に一致 | /^start/ |
"文字列の開始" |
$ |
文字列の終了に一致 | /end$/ |
"終了" |
\\\\ |
特殊文字をエスケープ | /\\\\\\\\/ |
"\" |
Rubyの正規表現の特殊文字
Rubyの正規表現には、パターンマッチングをより便利にするための事前定義された文字クラスが含まれています:
| シンボル | 説明 | 例 | 一致 |
|---|---|---|---|
\\\\d |
任意の数字(0-9)に一致 | /\\\\d+/ |
"123", "9" |
\\\\D |
任意の非数字に一致 | /\\\\D+/ |
"abc", "!@#" |
\\\\w |
任意の単語文字(英数字 + アンダースコア)に一致 | /\\\\w+/ |
"ruby123", "user_name" |
\\\\W |
任意の非単語文字に一致 | /\\\\W+/ |
"!@#", " " |
\\\\s |
任意の空白文字に一致 | /\\\\s+/ |
" ", "\t", "\n" |
\\\\S |
任意の非空白文字に一致 | /\\\\S+/ |
"hello", "123" |
\\\\A |
文字列の先頭に一致 | /\\\\AHello/ |
"Hello world" |
\\\\z |
文字列の末尾に一致 | /world\\\\z/ |
"Hello world" |
\\\\Z |
文字列の末尾または最終改行の前に一致 | /world\\\\Z/ |
"Hello world\n" |
Rubyの正規表現の量指定子
量指定子を使用すると、パターンが一致する回数を指定できます:
| 量指定子 | 説明 | 例 | 一致 |
|---|---|---|---|
* |
0回以上の繰り返し | /ab*c/ |
"ac", "abc", "abbc" |
+ |
1回以上の繰り返し | /ab+c/ |
"abc", "abbc" |
? |
0回または1回の繰り返し | /colou?r/ |
"color", "colour" |
{n} |
ちょうどn回の繰り返し | /a{3}/ |
"aaa" |
{n,} |
少なくともn回の繰り返し | /a{2,}/ |
"aa", "aaa", "aaaa" |
{n,m} |
n回以上m回以内の繰り返し | /a{2,4}/ |
"aa", "aaa", "aaaa" |
たとえば、「123-456-7890」のような電話番号形式に一致させるには、次のように使用できます:
/\\\\d{3}-\\\\d{3}-\\\\d{4}/
Rubyの正規表現を使用したパターンマッチング
Rubyの正規表現でマッチ演算子を使用
パターンが文字列に一致するかを確認する最も基本的な方法は、=~演算子を使用することです:
text = "The quick brown fox"
if /quick/ =~ text
puts "インデックス #{$~.begin(0)} で一致が見つかりました"
else
puts "一致が見つかりませんでした"
end
=~演算子は、最初の一致のインデックスを返すか、一致が見つからなければnilを返します。一致に成功した後は、Regexp.last_matchまたはグローバル変数$~を使用して、一致に関する情報にアクセスできます。
Rubyの正規表現でのキャプチャグループ
括弧を使ってキャプチャグループを作成し、一致の特定の部分を抽出することができます:
text = "Name: John, Age: 30"
if match_data = /Name: (\\\\w+), Age: (\\\\d+)/.match(text)
name = match_data[1] # 最初のキャプチャグループ
age = match_data[2] # 2番目のキャプチャグループ
puts "名前: #{name}, 年齢: #{age}"
end
Rubyの正規表現における一致した内容の抽出
パターンのすべての出現を抽出するには、scanメソッドを使用します:
text = "support@example.comまたはinfo@example.orgにご連絡ください"
emails = text.scan(/\\\\w+@\\\\w+\\\\.\\\\w+/)
puts emails.inspect # ["support@example.com", "info@example.org"]
実践におけるRubyの正規表現の使用
Rubyの正規表現による文字列の置換
gsubメソッドを使用すると、指定された文字列でパターンのすべての出現を置換できます:
text = "りんご バナナ りんご"
new_text = text.gsub(/りんご/, "オレンジ")
puts new_text # "オレンジ バナナ オレンジ"
より複雑な置換のためにブロックを使用することもできます:
text = "価格は$10です"
new_text = text.gsub(/\\\\$(\\\\d+)/) do |match|
"$#{$1.to_i * 1.1}" # 価格を10%増加
end
puts new_text # "価格は$11です"
Rubyの正規表現での選択
パイプシンボル(|)を使用すると、一方のパターンまたは他方のパターンに一致させることができます:
/cat|dog/.match("私は猫を飼っています") # "cat"に一致
/cat|dog/.match("私は犬を飼っています") # "dog"に一致
括弧を使用して選択肢をグループ化することができます:
/(リンゴ|バナナ) パイ/.match("私はリンゴパイが大好きです") # "リンゴパイ"に一致
Rubyの正規表現での文字クラス
文字クラスを使用すると、セットから任意の1文字に一致させることができます:
/[aeiou]/.match("こんにちは") # "い"に一致
/[0-9]/.match("エージェント007") # "0"に一致
文字クラスを否定することもできます:
/[^0-9]/.match("エージェント007") # "a"に一致
Rubyの正規表現による文字列操作
Rubyの正規表現での開始および終了の一致
Rubyは、文字列が特定のパターンで開始または終了するかを確認する便利なメソッドを提供します:
"こんにちは、世界!".start_with?("こんにちは") # true
"こんにちは、世界!".end_with?("世界!") # true
これらのメソッドは正規表現ベースではありませんが、文字列操作のタスクで正規表現と一緒に使用されることがよくあります。
Rubyの正規表現のグローバル変数
一致に成功すると、Rubyはいくつかのグローバル変数を設定します:
$&- 一致した完全なテキスト$`- 一致する前の文字列の部分$'- 一致する後の文字列の部分
/bb/ =~ "aabbcc"
puts $` # "aa"
puts $& # "bb"
puts $' # "cc"
Rubyの正規表現の修飾子
Rubyの正規表現は、パターンの解釈を変更するさまざまな修飾子をサポートしています:
| 修飾子 | 説明 | 例 |
|---|---|---|
i |
大文字と小文字を区別しない一致 | /ruby/iは"Ruby"、"RUBY"、"rUbY"に一致 |
m |
複数行モード(ドットが改行に一致) | /./mは改行を含む任意の文字に一致 |
x |
拡張モード(コメントや空白を許可) | /pattern # コメント/x |
o |
#{ }の補完を1回のみ実行 | /#{pattern}/o |
u |
UTF-8エンコーディング | /\\\\u{1F600}/uは絵文字😀に一致 |
例:
/ruby/ =~ "RUBY" # nil (一致なし)
/ruby/i =~ "RUBY" # 0 (先頭で一致)
# 'm'修飾子なしの場合、ドットは改行に一致しない
/a.b/ =~ "a\\\\nb" # nil
# 'm'修飾子ありで、ドットも改行に一致
/a.b/m =~ "a\\\\nb" # 0
高度なRubyの正規表現技術
Rubyの正規表現での非キャプチャグループ
時には、一致したテキストをキャプチャせずにグループ化が必要なことがあります:
/(?:ab)+c/.match("ababc") # "ababc"に一致、"ab"はキャプチャしない
Rubyの正規表現での先読みと後読み
先読みのアサーションを使用すると、パターンが別のパターンの後に続く場合にのみ一致させることができます:
# 'apple'が'pie'の後に続く場合のみ一致
/apple(?= pie)/.match("apple pie") # "apple"に一致
/apple(?= pie)/.match("apple tart") # 一致なし
# 'apple'が'pie'の後に続かない場合にのみ一致
/apple(?! pie)/.match("apple tart") # "apple"に一致
後読みのアサーションは同様に機能しますが、前に何があるかを確認します:
# 'pie'が'apple'の前にある場合にのみ一致
/(?<=apple )pie/.match("apple pie") # "pie"に一致
/(?<=apple )pie/.match("cherry pie") # 一致なし
Rubyの正規表現に関するパフォーマンスのヒント
- 具体的であること: より具体的なパターンは、一般的なパターンよりもパフォーマンスが良好です。
- 過剰なバックトラッキングを避ける: 量指定子の数が多い複雑なパターンは、パフォーマンスの問題を引き起こす可能性があります。
- アンカーを使用する: 適切な場合は、
\\\\A、\\\\z、^および$を使用して、一致が発生できる場所を制限してください。 - 代替案を検討する: 簡単な場合は、
include?やstart_with?などのシンプルな文字列メソッドが正規表現よりも速いことがあります。
Rubyの正規表現に関する結論
Rubyの正規表現は、プログラミングツールキットの中で強力なツールです。簡潔な構文で複雑なテキスト処理を行うことができます。構文は最初は intimidating に感じるかもしれませんが、正規表現を習得することで、Rubyでのテキスト処理の生産性を大幅に向上させることができます。
正規表現に習熟するためには、練習が重要です。シンプルなパターンから始めて、基本に慣れたら徐々により複雑な機能を取り入れていきましょう。Rubular のような多くのオンラインツール(https://rubular.com/)は、正規表現をインタラクティブにテストし、デバッグするのに役立ちます。
このチュートリアルでカバーされた概念を理解することで、Rubyプロジェクトの文字列操作のさまざまな課題に取り組むための準備が整います。