
Qwen3のような大規模言語モデル(LLM)は、コーディング、推論、自然言語理解における目覚ましい能力でAIの状況を革新しています。AlibabaのQwenチームによって開発されたQwen3は、効率的なローカルデプロイメントを可能にする量子化モデルを提供しており、開発者、研究者、愛好家がこれらの強力なモデルを自身のハードウェアで実行できるようにしています。Ollama、LM Studio、vLLMのいずれを使用する場合でも、このガイドではQwen3量子化モデルをローカルでセットアップおよび実行するプロセスを順を追って説明します。
このテクニカルガイドでは、セットアッププロセス、モデル選択、デプロイメント方法、およびAPI統合について探ります。始めましょう。
Qwen3量子化モデルとは?
Qwen3はAlibabaのLLMの最新世代であり、コーディング、数学、一般的な推論などのタスク全体で高性能を発揮するように設計されています。BF16、FP8、GGUF、AWQ、GPTQ形式などの量子化モデルは、計算およびメモリ要件を削減し、コンシューマーグレードのハードウェアでのローカルデプロイメントに最適です。
Qwen3ファミリーにはさまざまなモデルが含まれています。
- Qwen3-235B-A22B (MoE): BF16、FP8、GGUF、GPTQ-int4形式のMixture-of-Expertsモデル。
- Qwen3-30B-A3B (MoE): 同様の量子化オプションを持つ別のMoEバリアント。
- Qwen3-32B, 14B, 8B, 4B, 1.7B, 0.6B (Dense): BF16、FP8、GGUF、AWQ、GPTQ-int8形式で利用可能なDenseモデル。
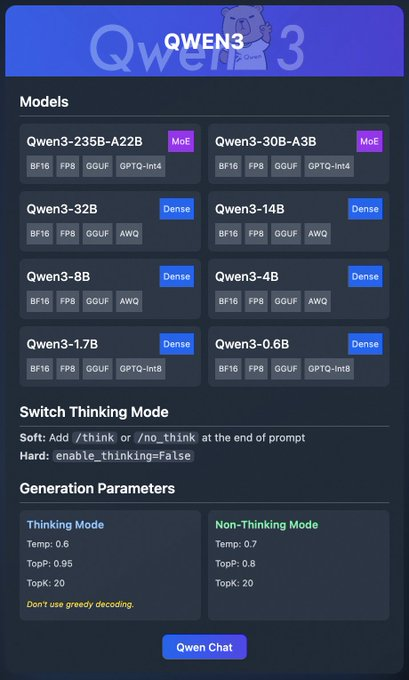
これらのモデルは、Ollama、LM Studio、vLLMなどのプラットフォームを通じて柔軟なデプロイメントをサポートしており、これについては詳しく説明します。さらに、Qwen3は、より良い推論のために切り替え可能な「思考モード」や、出力品質を微調整するための生成パラメーターなどの機能を提供します。
基本的な理解ができたところで、Qwen3をローカルで実行するための前提条件に進みましょう。
Qwen3をローカルで実行するための前提条件
Qwen3量子化モデルをデプロイする前に、システムが以下の要件を満たしていることを確認してください。
ハードウェア:
- 最新のCPUまたはGPU(vLLMにはNVIDIA GPUを推奨)。
- Qwen3-4Bのような小規模モデルには少なくとも16GBのRAM。Qwen3-32Bのような大規模モデルには32GB以上。
- 十分なストレージ(例:Qwen3-235B-A22B GGUFには約150GBが必要になる場合があります)。
ソフトウェア:
- 互換性のあるオペレーティングシステム(Windows、macOS、またはLinux)。
- vLLMおよびAPI操作のためのPython 3.8以降。
- Docker(オプション、vLLM用)。
- リポジトリのクローン作成のためのGit。
依存関係:
torch、transformers、vllm(vLLM用)などの必要なライブラリをインストールします。- OllamaまたはLM Studioのバイナリを公式サイトからダウンロードします。
これらの前提条件が整ったところで、Qwen3量子化モデルのダウンロードに進みましょう。
ステップ1:Qwen3量子化モデルをダウンロードする
まず、信頼できるソースから量子化モデルをダウンロードする必要があります。Qwenチームは、Hugging FaceとModelScopeでQwen3モデルを提供しています。
- Hugging Face: Qwen3 Collection
- ModelScope: Qwen3 Collection
Hugging Faceからのダウンロード方法
- Hugging FaceのQwen3コレクションにアクセスします。
- 軽量デプロイメントのために、GGUF形式のQwen3-4Bなどのモデルを選択します。
- 「Download」ボタンをクリックするか、
git cloneコマンドを使用してモデルファイルをフェッチします。
git clone https://huggingface.co/Qwen/Qwen3-4B-GGUF
- モデルファイルを
/models/qwen3-4b-ggufなどのディレクトリに保存します。
ModelScopeからのダウンロード方法
- ModelScopeのQwen3コレクションに移動します。
- 希望するモデルと量子化形式(例:AWQまたはGPTQ)を選択します。
- ファイルを手動でダウンロードするか、APIを使用してプログラムでアクセスします。
モデルがダウンロードされたら、Ollamaを使用してそれらをデプロイする方法を探りましょう。
ステップ2:Ollamaを使用してQwen3をデプロイする
Ollamaは、最小限のセットアップでLLMをローカルで実行するためのユーザーフレンドリーな方法を提供します。Qwen3のGGUF形式をサポートしており、初心者にとって理想的です。
Ollamaのインストール
- Ollamaの公式サイトにアクセスし、オペレーティングシステム用のバイナリをダウンロードします。
- インストーラーを実行するか、コマンドラインの指示に従ってOllamaをインストールします。
curl -fsSL https://ollama.com/install.sh | sh
- インストールを確認します。
ollama --version
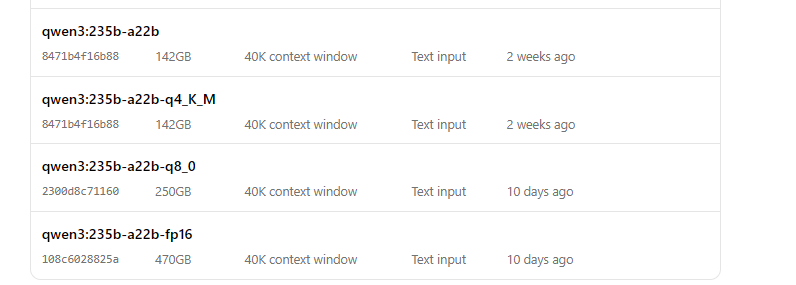
OllamaでQwen3を実行する
- モデルを起動します。
ollama run qwen3:235b-a22b-q8_0- モデルが実行されたら、コマンドラインから操作できます。
>>> Hello, how can I assist you today?
Ollamaは、プログラムによるアクセスのためのローカルAPIエンドポイント(通常http://localhost:11434)も提供しており、これは後でApidogを使用してテストします。
次に、Qwen3を実行するためにLM Studioを使用する方法を探りましょう。
ステップ3:LM Studioを使用してQwen3をデプロイする
LM Studioは、LLMをローカルで実行するためのもう1つの人気ツールであり、モデル管理のためのグラフィカルインターフェイスを提供します。
LM Studioのインストール
- LM Studioを公式サイトからダウンロードします。
- 画面の指示に従ってアプリケーションをインストールします。
- LM Studioを起動し、実行されていることを確認します。
LM StudioでQwen3をロードする
LM Studioで、「Local Models」セクションに移動します。
「Add Model」をクリックし、モデルを検索してダウンロードします。
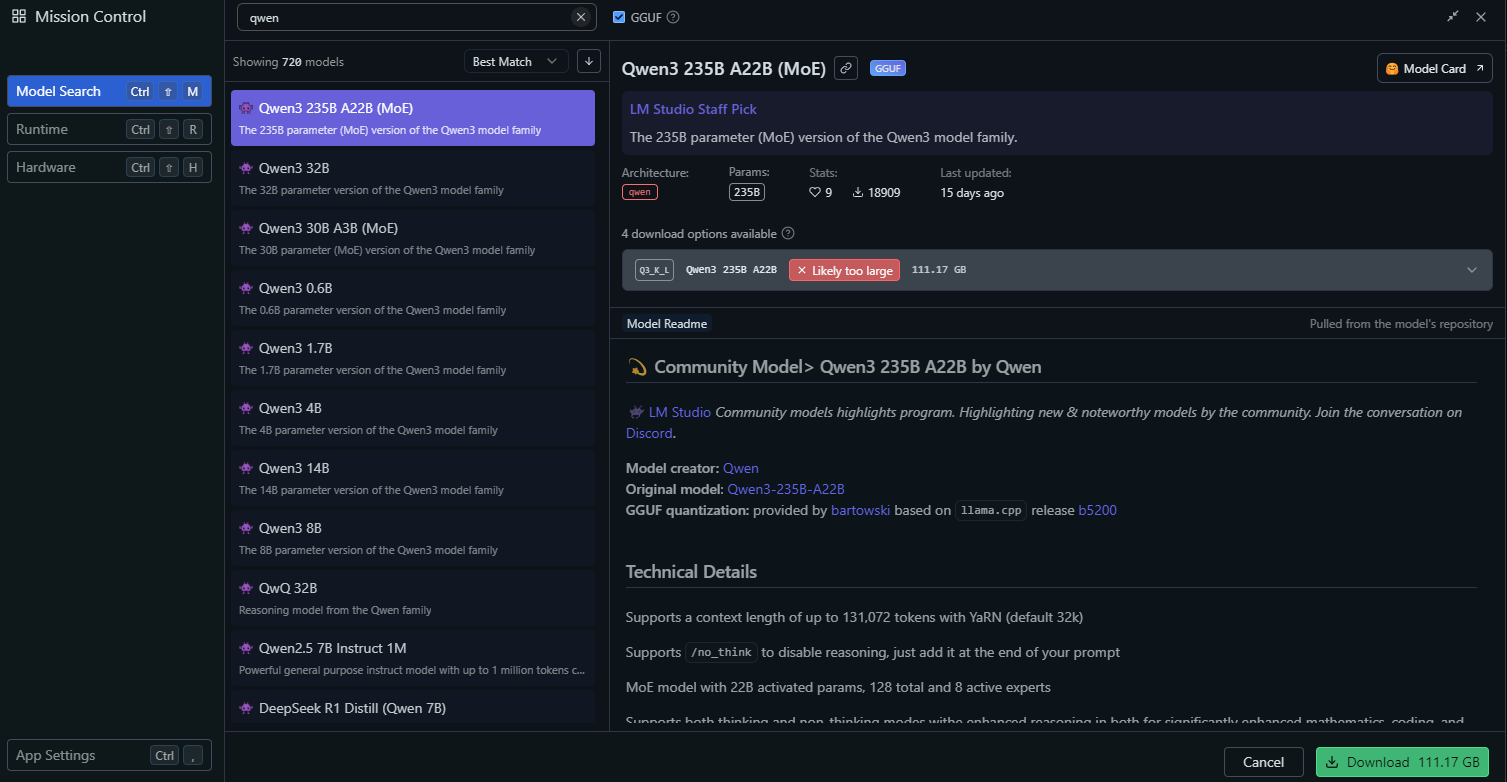
モデル設定を構成します。
- Temperature: 0.6
- Top-P: 0.95
- Top-K: 20
これらの設定は、Qwen3の推奨される思考モードパラメーターと一致します。
「Start Server」をクリックしてモデルサーバーを起動します。LM StudioはローカルAPIエンドポイント(例:http://localhost:1234)を提供します。
LM StudioでQwen3を操作する
- LM Studioの組み込みチャットインターフェイスを使用してモデルをテストします。
- または、APIテストセクションで探るように、APIエンドポイント経由でモデルにアクセスします。
LM Studioのセットアップが完了したところで、vLLMを使用したより高度なデプロイメント方法に進みましょう。
ステップ4:vLLMを使用してQwen3をデプロイする
vLLMは、LLM向けに最適化された高性能サービングソリューションであり、Qwen3のFP8およびAWQ量子化モデルをサポートしています。堅牢なアプリケーションを構築する開発者にとって理想的です。
vLLMのインストール
- システムにPython 3.8以降がインストールされていることを確認します。
- pipを使用してvLLMをインストールします。
pip install vllm
- インストールを確認します。
python -c "import vllm; print(vllm.__version__)"
vLLMでQwen3を実行する
Qwen3モデルを使用してvLLMサーバーを起動します。
# Load and run the model:
vllm serve "Qwen/Qwen3-235B-A22B"--enable-thinking=FalseフラグはQwen3の思考モードを無効にします。
サーバーが起動すると、http://localhost:8000にAPIエンドポイントが提供されます。
最適なパフォーマンスのためのvLLMの構成
vLLMは、次のような高度な構成をサポートしています。
- Tensor Parallelism: GPUセットアップに基づいて
--tensor-parallel-sizeを調整します。 - Context Length: Qwen3は最大32,768トークンをサポートしており、これは
--max-model-len 32768で設定できます。 - Generation Parameters: APIを使用して
temperature、top_p、top_kを設定します(例:思考モード以外の場合は0.7、0.8、20)。
vLLMが実行されている状態で、Apidogを使用してAPIエンドポイントをテストしましょう。
ステップ5:ApidogでQwen3 APIをテストする
Apidogは、APIエンドポイントをテストするための強力なツールであり、ローカルにデプロイされたQwen3モデルとの連携に最適です。
Apidogのセットアップ
- 公式サイトからApidogをダウンロードしてインストールします。
- Apidogを起動し、新しいプロジェクトを作成します。
Ollama APIのテスト
- Apidogで新しいAPIリクエストを作成します。
- エンドポイントを
http://localhost:11434/api/generateに設定します。 - リクエストを構成します。
- Method: POST
- Body (JSON):
{
"model": "qwen3-4b",
"prompt": "Hello, how can I assist you today?",
"temperature": 0.6,
"top_p": 0.95,
"top_k": 20
}
- リクエストを送信し、レスポンスを確認します。
vLLM APIのテスト
- Apidogで別のAPIリクエストを作成します。
- エンドポイントを
http://localhost:8000/v1/completionsに設定します。 - リクエストを構成します。
- Method: POST
- Body (JSON):
{
"model": "qwen3-4b-awq",
"prompt": "Write a Python script to calculate factorial.",
"max_tokens": 512,
"temperature": 0.7,
"top_p": 0.8,
"top_k": 20
}
- リクエストを送信し、出力を確認します。
Apidogを使用すると、Qwen3のデプロイメントを簡単に検証し、APIが正しく機能していることを確認できます。次に、モデルのパフォーマンスを微調整しましょう。
ステップ6:Qwen3のパフォーマンスを微調整する
Qwen3のパフォーマンスを最適化するには、ユースケースに基づいて以下の設定を調整します。
思考モード
Qwen3は、Xの投稿画像で強調されているように、推論を強化するための「思考モード」をサポートしています。これを制御するには2つの方法があります。
- ソフトスイッチ: プロンプトに
/thinkまたは/no_thinkを追加します。
- 例:
Solve this math problem /think。
- ハードスイッチ: vLLMで
--enable-thinking=Falseを使用して思考を完全に無効にします。
生成パラメーター
より良い出力品質のために生成パラメーターを微調整します。
- Temperature: 思考モードの場合は0.6、思考モード以外の場合は0.7を使用します。
- Top-P: 0.95(思考)または0.8(思考以外)に設定します。
- Top-K: 両方のモードで20を使用します。
- Qwenチームの推奨に従い、貪欲なデコーディングは避けてください。
これらの設定を試して、創造性と正確さの間の望ましいバランスを達成してください。
一般的な問題のトラブルシューティング
Qwen3をデプロイする際に、いくつかの問題に遭遇する可能性があります。一般的な問題に対する解決策を以下に示します。
Ollamaでモデルがロードされない:
Modelfile内のGGUFファイルパスが正しいことを確認します。- モデルをロードするための十分なメモリがシステムにあるか確認します。
vLLM Tensor Parallelismエラー:
- 「output_size is not divisible by weight quantization block_n」のようなエラーが表示された場合は、
--tensor-parallel-sizeを減らします(例:4に)。
ApidogでAPIリクエストが失敗する:
- サーバー(Ollama、LM Studio、またはvLLM)が実行されていることを確認します。
- エンドポイントURLとリクエストペイロードを再確認します。
これらの問題に対処することで、スムーズなデプロイメント体験を確保できます。
結論
Qwen3量子化モデルをローカルで実行することは、Ollama、LM Studio、vLLMなどのツールを使用すれば簡単なプロセスです。アプリケーションを構築する開発者であっても、LLMを実験する研究者であっても、Qwen3は必要な柔軟性とパフォーマンスを提供します。このガイドに従うことで、Hugging FaceとModelScopeからモデルをダウンロードし、さまざまなフレームワークを使用してそれらをデプロイし、Apidogを使用してそれらのAPIエンドポイントをテストする方法を学びました。
今日からQwen3の探索を開始し、プロジェクトでローカルLLMの力を解き放ちましょう!