
AlibabaのQwenシリーズは、大規模言語モデルの限界を押し広げ続けており、Qwen3-Next-80B-A3Bは、効率性と高性能が両立した最高の例として際立っています。エンジニアや開発者は、計算コストの高い巨大モデルの負担なしに、堅牢な推論を提供するモデルを求めています。このモデルはその要求に正面から応え、800億のパラメータを持ちながら、トークンあたりわずか30億しかアクティブにしません。その結果、チームはより速い推論速度と削減されたトレーニング費用を実現し、実際のデプロイメントに理想的です。
ボタン
この投稿では、Qwen3-Next-80B-A3Bの主要コンポーネントを探求し、その革新的なアーキテクチャを分析し、経験的なパフォーマンスデータを確認し、実践的な手順を通じてそのAPIを習得します。さらに、Apidogのようなツールを統合してワークフローを強化します。最終的には、このモデルをアプリケーションに効果的にデプロイするための知識を身につけることができます。
Qwen3-Next-80B-A3Bを定義するものとは?コア機能とイノベーション
Qwen3-Next-80B-A3Bは、AlibabaのQwenファミリーから、速度と能力の両方に最適化された疎な専門家混合(MoE)モデルとして登場しました。開発者は推論時にそのパラメータのごく一部のみをアクティブにするため、大幅なリソース節約につながります。具体的には、このモデルは512の専門家を持つ超疎なMoE設定を採用し、トークンあたり10の専門家と1つの共有専門家をルーティングします。その結果、Qwen3-32Bのようなより密なモデルのパフォーマンスに匹敵しながら、はるかに少ない電力を消費します。
さらに、このモデルはマルチトークン予測をサポートしており、これは投機的デコーディングを加速する技術です。この機能により、モデルは複数のトークンを同時に生成できるため、デコーディング段階でのスループットが向上します。チャットボットやリアルタイム分析ツールなど、迅速な応答を必要とするアプリケーションにとって、この機能は開発者にとって非常に価値があります。
このシリーズには、特定のニーズに合わせて調整されたバリアントが含まれています。一般的な事前学習用のベースモデル、微調整された会話タスク用のインストラクトバージョン、高度な推論チェーン用の思考バリアントです。例えば、Qwen3-Next-80B-A3B-Thinkingは複雑な問題解決に優れており、ベンチマークでGemini-2.5-Flash-Thinkingのようなモデルを上回っています。さらに、119の言語に対応しており、再トレーニングなしで多言語展開を可能にします。
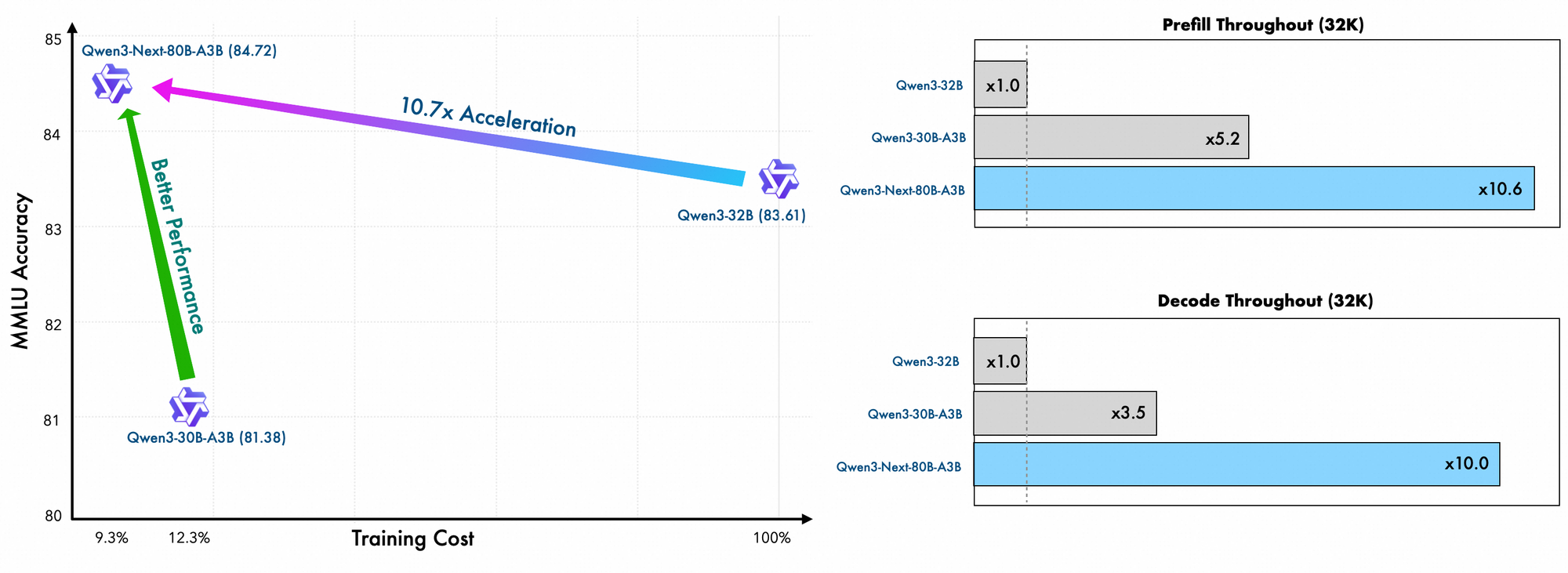
トレーニングの詳細からは、さらなる効率性が明らかになります。Alibabaのエンジニアは、このモデルをスケーリング効率の高い方法で事前学習しており、Qwen3-32Bと比較してコストはわずか10%に抑えられています。彼らは48層にわたるハイブリッドレイアウトと2048の隠れ次元を活用し、バランスの取れた計算分散を確保しています。その結果、このモデルは優れた長文コンテキスト理解を示し、他のモデルが性能低下する32Kトークンを超えても精度を維持します。
実際には、これらの機能により、開発者はAIソリューションを費用対効果の高い方法でスケールできるようになります。エンタープライズ検索エンジンを構築する場合でも、自動コンテンツ生成ツールを構築する場合でも、Qwen3-Next-80B-A3Bは革新的なアプリケーションの基盤を提供します。この基盤の上に、次のセクションでは、このような効率性を可能にするアーキテクチャ要素を検証します。
Qwen3-Next-80B-A3Bのアーキテクチャを解剖する:技術的な設計図
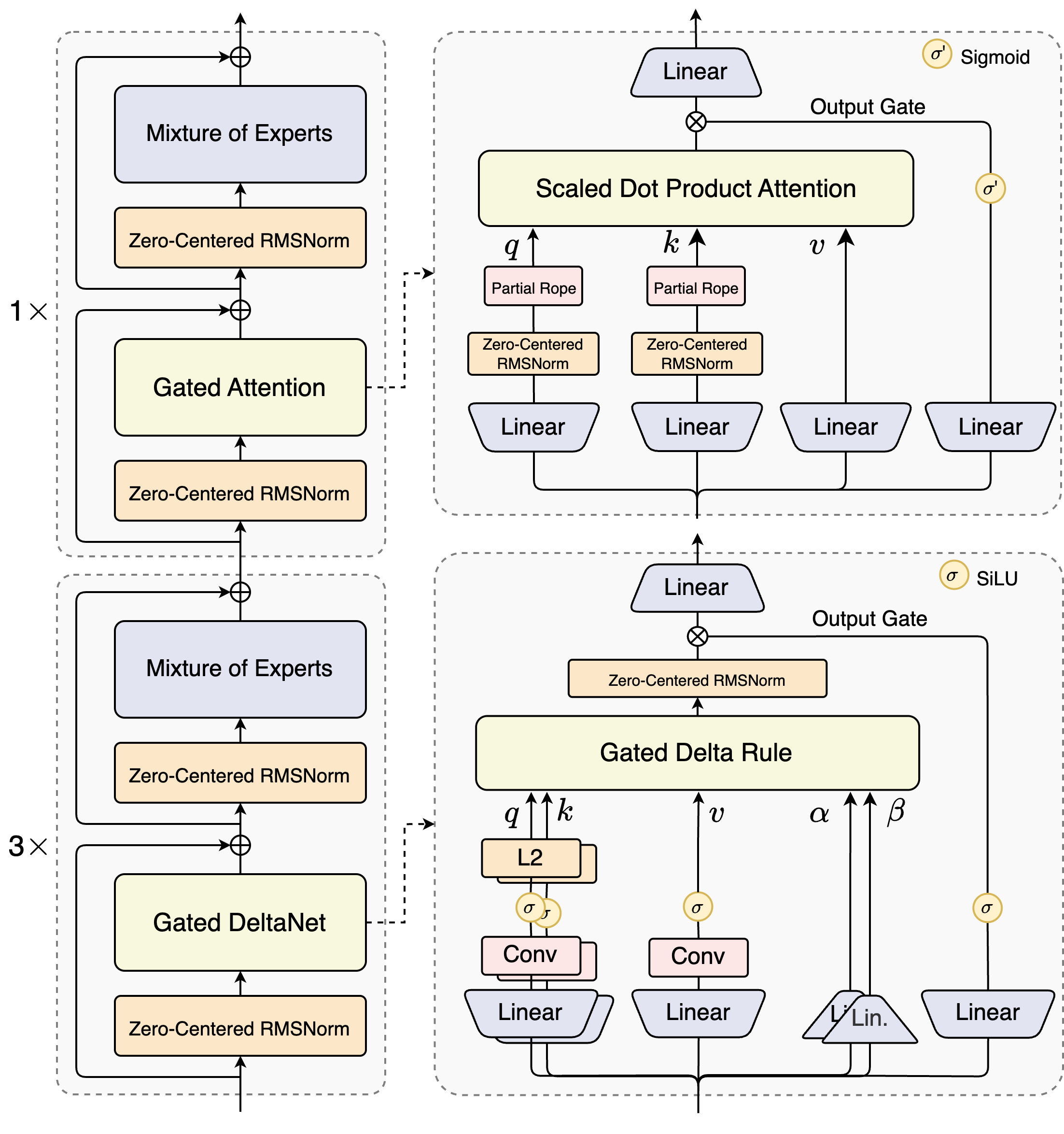
Qwen3-Next-80B-A3Bの設計者は、ゲーテッドメカニズムと高度な正規化技術を組み合わせたハイブリッド設計を導入しています。その核心には、専門家が異なる計算パスに特化する専門家混合(MoE)層があります。モデルは入力を動的にルーティングし、オーバーヘッドを最小限に抑えるために一部をアクティブにします。例えば、ゲーテッドアテンションブロックは、部分的なRoPE埋め込みとゼロ中心のRMSNorm層を介してクエリ、キー、値を処理し、長いシーケンスでの安定性を向上させます。
スケールされたドット積アテンションモジュールを考えてみましょう。これは、線形射影に続いてシグモイド活性化によって変調される出力ゲートを統合しています。この設定により、情報フローを正確に制御し、高次元空間での希釈を防ぐことができます。さらに、ゼロ中心のRMSNormがこれらの操作の前後に適用され、活性化をゼロ中心にすることで、トレーニング中の勾配問題を軽減します。
この図は2つの主要なブロックを示しています。上部はスケールされたドット積アテンションを伴うゲーテッドアテンションに焦点を当て、下部はゲーテッドDeltaNetを強調しています。アテンションパス(1倍拡張)では、入力はゼロ中心のRMSNormを通過し、ゲーテッドアテンションコアに入ります。ここでは、クエリ(q)、キー(k)、値(v)の射影は位置エンコーディングに部分的なRoPEを使用します。アテンション後、別のRMSNormと線形層がMoEに供給され、MoEはシグモイドゲート付き出力を使用します。
DeltaNetパス(3倍拡張)に移行すると、このアーキテクチャは洗練された予測のためにゲーテッドデルタルールを採用しています。qとkに対するL2正規化、局所特徴抽出のための畳み込み層、非線形性のためのSiLU活性化が特徴です。出力ゲートは線形射影と組み合わされ、一貫したマルチトークン出力を保証します。このブロックの設計は、モデルの投機的デコーディングをサポートしており、後続のパスで検証されるように、いくつかのトークンを先行して予測します。
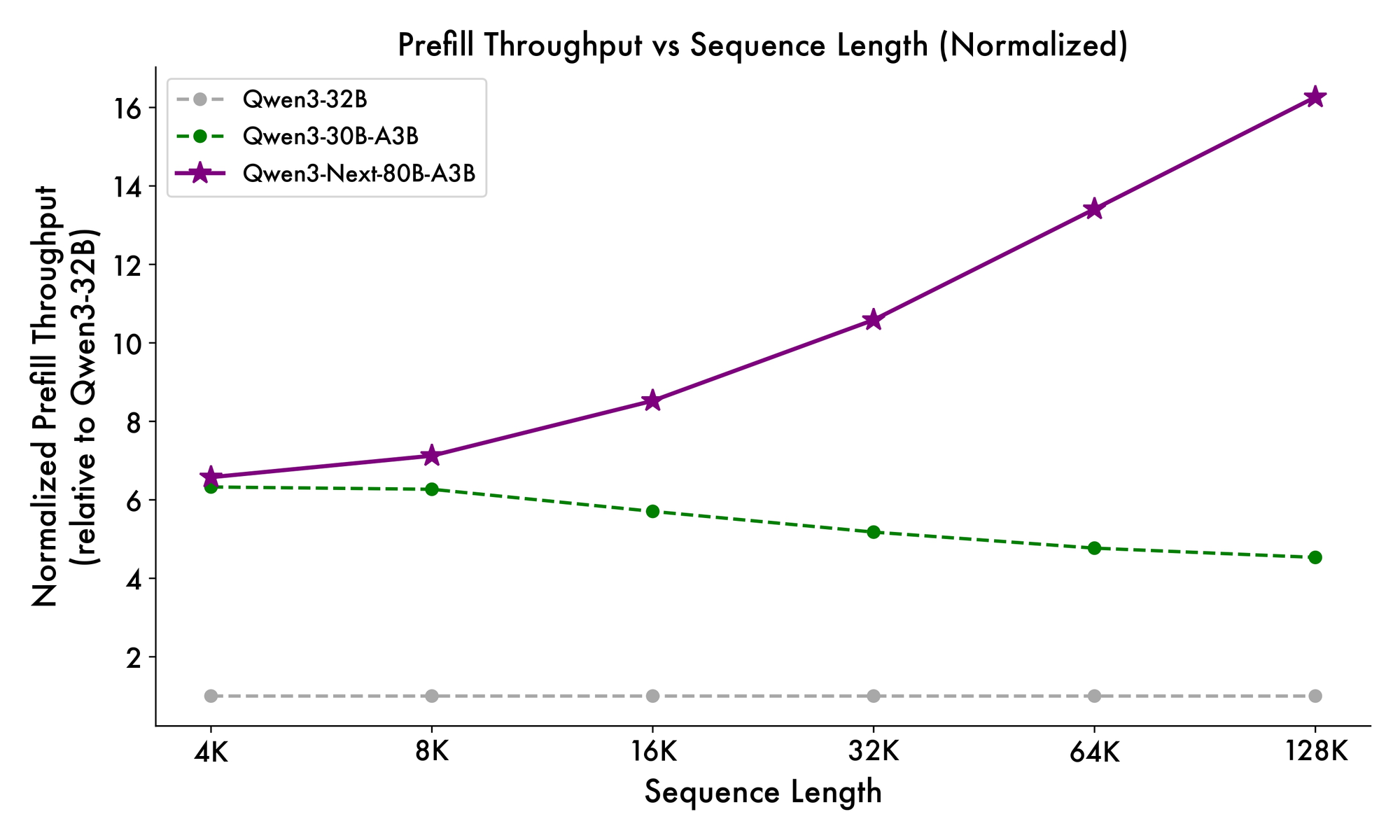
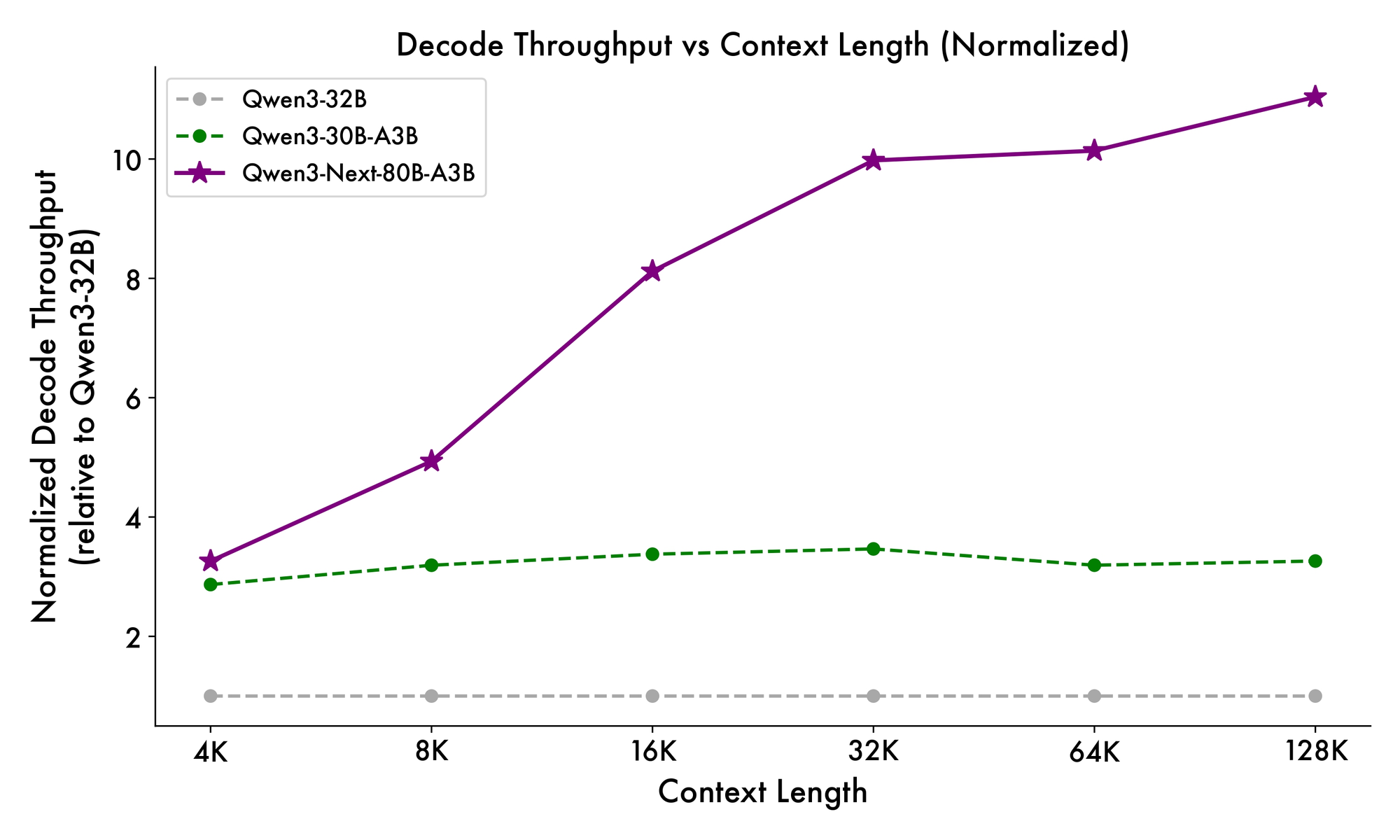
さらに、全体構造は、トークン間の共通パターンを処理するためにMoEに共有エキスパートを組み込み、冗長性を低減しています。射影における部分的なRoPE埋め込みは、拡張されたコンテキストに対して回転不変性を保持します。ベンチマークで示されているように、この構成はQwen3-32Bと比較して、4Kコンテキスト長でほぼ7倍高いスループットをもたらします。32Kトークンを超えると、速度は10倍を超え、ドキュメント分析やコード生成タスクに適しています。
開発者は、ファインチューニング時にこのモジュール性から恩恵を受けます。専門家を交換したり、ルーティングのしきい値を調整したりして、金融やヘルスケアなどのドメインにモデルを特化させることができます。本質的に、このアーキテクチャは計算を最適化するだけでなく、適応性も促進します。これらの洞察を得て、次にこれらの要素がどのように測定可能なパフォーマンス向上につながるかを見ていきましょう。
Qwen3-Next-80B-A3Bのベンチマーク:重要なパフォーマンス指標
経験的評価により、Qwen3-Next-80B-A3Bは効率重視のAIのリーダーとして位置づけられています。MMLUやHumanEvalのような標準ベンチマークでは、アクティブパラメータが10分の1であるにもかかわらず、ベースモデルはQwen3-32Bを上回ります。具体的には、一般的な知識に関するMMLUで78.5%を達成し、推論サブセットでは競合他社を2〜3ポイント上回っています。
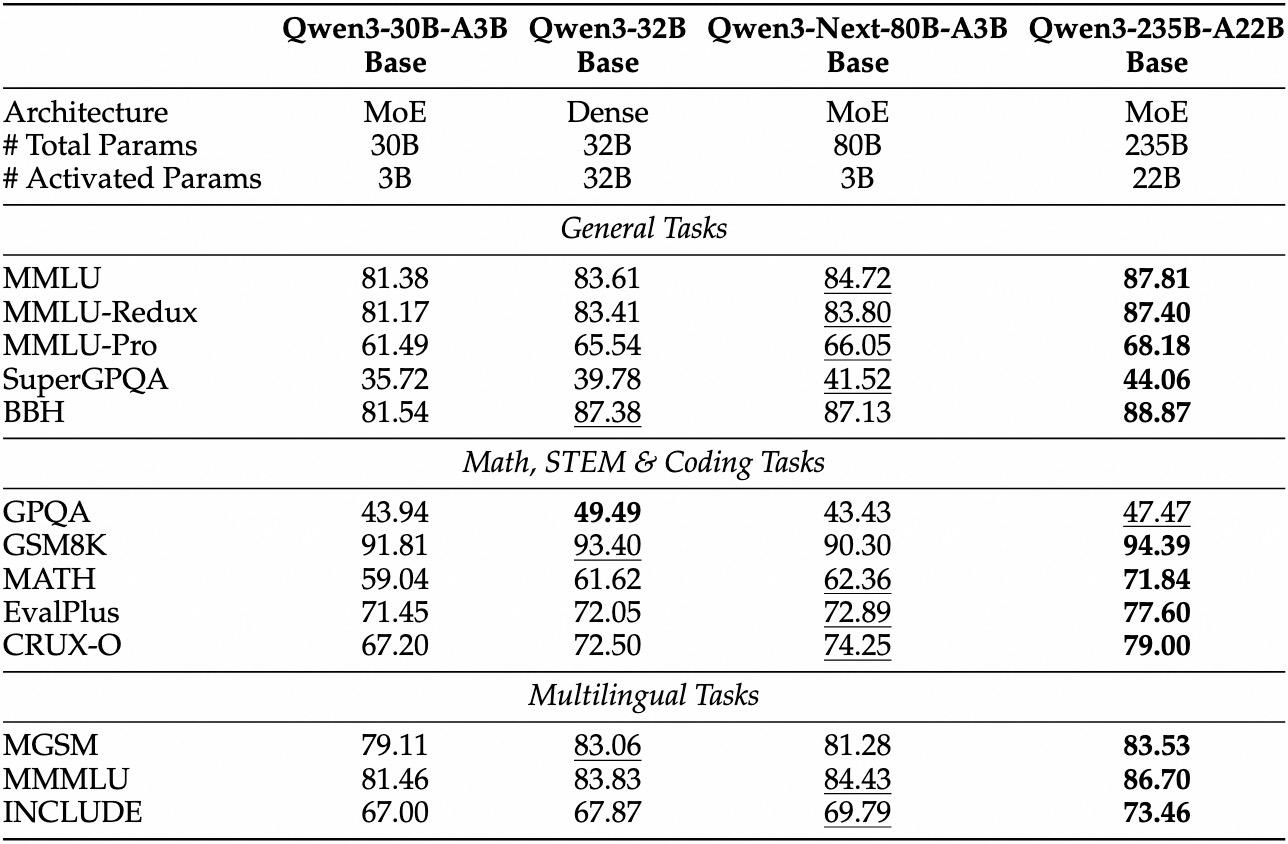
インストラクトバリアントでは、会話タスクにおいて指示に従う能力の強みが明らかになりました。MT-Benchで85%を記録し、一貫した複数ターン対話を示しています。一方、思考モデルは思考連鎖シナリオで輝きを放ち、数学の問題に関するGSM8Kで92%を達成し、Qwen3-30B-A3B-Thinkingを4%上回っています。
推論速度はその魅力の要です。4Kコンテキストでは、デコードスループットはQwen3-32Bの4倍に達し、より長いコンテキストでは10倍にスケールします。プロンプト処理に不可欠なプリフィル段階では、疎なMoEのおかげで7倍の改善が見られます。電力消費もそれに伴って減少し、トレーニングコストはより密なモデルの10%に抑えられています。
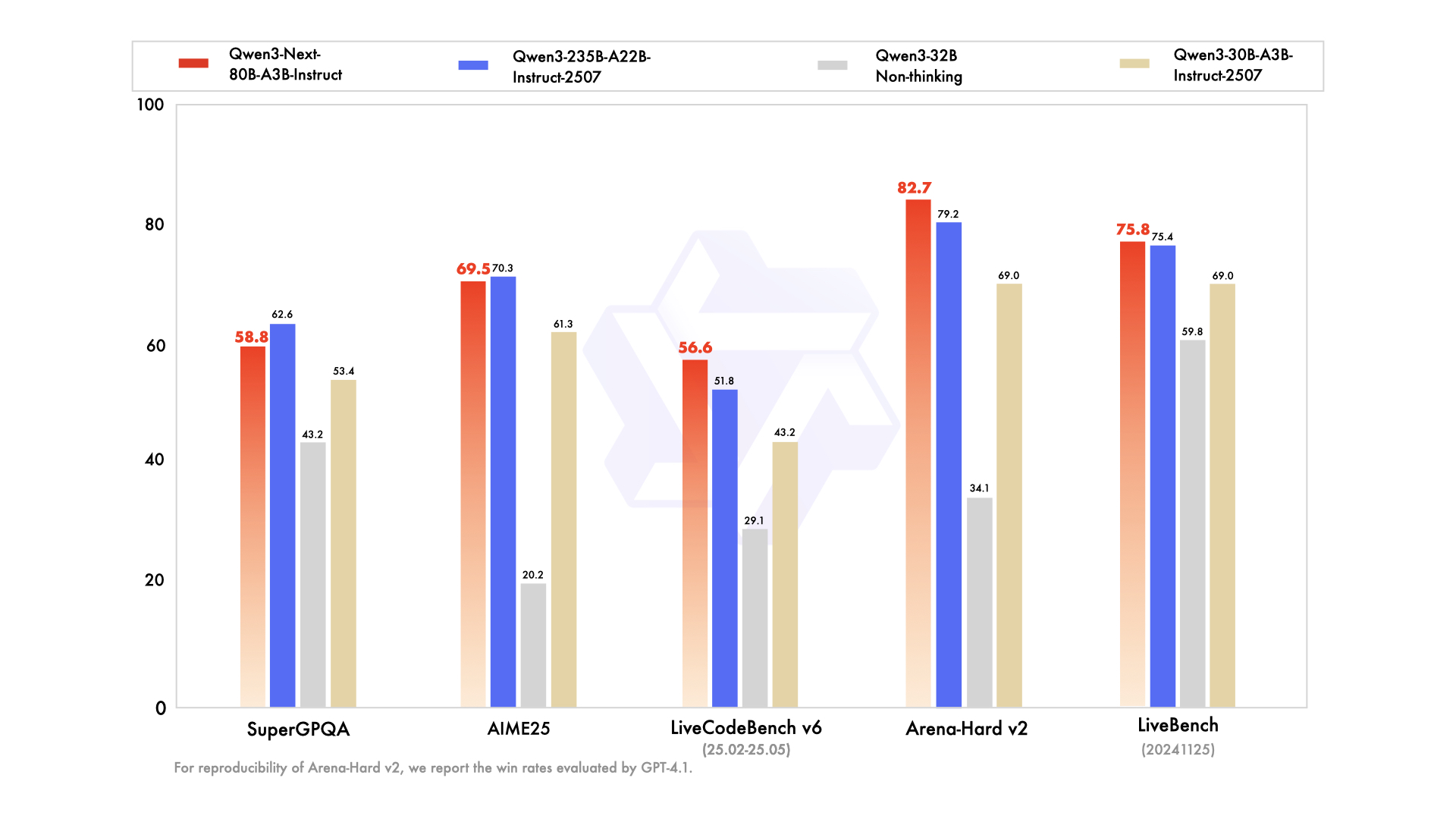
競合他社との比較では、その優位性が際立っています。Llama 3.1-70Bと比較して、Qwen3-Next-80B-A3B-ThinkingはRULER(長文コンテキスト想起)で15%リードし、128Kトークンからの詳細を正確に想起します。DeepSeek-V2と比較しても、速度を犠牲にすることなく、より優れた多言語サポートを提供します。

| ベンチマーク | Qwen3-Next-80B-A3B-Base | Qwen3-32B-Base | Llama 3.1-70B |
|---|---|---|---|
| MMLU | 78.5% | 76.2% | 77.8% |
| HumanEval | 82.1% | 79.5% | 81.2% |
| GSM8K | 91.2% | 88.7% | 90.1% |
| MT-Bench | 84.3% (Instruct) | 81.9% | 83.5% |
この表は、一貫した優れたパフォーマンスを強調しています。その結果、組織は品質とコストのバランスを取りながら、本番環境での採用を進めています。理論から実践へと移行し、これでAPIアクセスツールを身につけることになります。
Qwen3-Next-80B-A3B APIへのアクセス設定:前提条件と認証
Alibabaは、クラウドプラットフォームであるDashScopeを通じてQwen APIを提供しており、シームレスな統合を保証しています。まず、Alibaba Cloudアカウントを作成し、Model Studioコンソールに移動します。モデルリストからQwen3-Next-80B-A3Bを選択します(ベース、インストラクト、思考モードで利用可能)。
ダッシュボードの「API Keys」からAPIキーを取得します。このキーはリクエストを認証し、レート制限はティアに基づきます(無料ティアでは月100万トークンを提供)。OpenAI互換の呼び出しの場合、ベースURLをhttps://dashscope.aliyuncs.com/compatible-mode/v1に設定します。ネイティブのDashScopeエンドポイントはhttps://dashscope.aliyuncs.com/api/v1/services/aigc/text-generation/generationを使用します。
pip経由でPython SDKをインストールします:pip install dashscope。このライブラリは、シリアル化、リトライ、エラー解析を処理します。または、カスタム実装のためにrequestsのようなHTTPクライアントを使用することもできます。
セキュリティのベストプラクティスでは、キーを環境変数に保存することが求められます:export DASHSCOPE_API_KEY='your_key_here'。その結果、コードは環境間で移植可能になります。セットアップが完了したら、最初のAPI呼び出しを作成します。
実践ガイド:PythonとDashScopeでQwen3-Next-80B-A3B APIを使用する
DashScopeは、Qwen3-Next-80B-A3Bとのやり取りを簡素化します。チャットのような応答には、インストラクトバリアントを使用した基本的な生成リクエストから始めます。
import os
from dashscope import Generation
os.environ['DASHSCOPE_API_KEY'] = 'your_api_key'
response = Generation.call(
model='qwen3-next-80b-a3b-instruct',
prompt='Explain the benefits of MoE architectures in LLMs.',
max_tokens=200,
temperature=0.7
)
if response.status_code == 200:
print(response.output['text'])
else:
print(f"Error: {response.message}")
このコードはプロンプトを送信し、最大200トークンを取得します。モデルは簡潔な説明で応答し、効率性の向上を強調します。思考モードの場合は、「qwen3-next-80b-a3b-thinking」に切り替え、「Think step-by-step before answering.」のような推論指示を追加します。
高度なパラメータは制御を強化します。核サンプリングにはtop_p=0.9を、ループを避けるにはrepetition_penalty=1.1を設定します。長いコンテキストの場合、モデルの128Kの能力を活用するためにmax_context_length=131072を指定します。
リアルタイムアプリのストリーミング処理:
from dashscope import Streaming
for response in Streaming.call(
model='qwen3-next-80b-a3b-instruct',
prompt='Generate a Python function for sentiment analysis.',
max_tokens=500,
incremental_output=True
):
if response.status_code == 200:
print(response.output['text_delta'], end='', flush=True)
else:
print(f"Error: {response.message}")
break
これにより、トークンごとの出力が得られ、UI統合に最適です。エラー処理には、クォータの問題(例:残高不足の場合は10402)に対するresponse.codeの確認が含まれます。
さらに、関数呼び出しはユーティリティを拡張します。JSONスキーマでツールを定義します:
tools = [{
"type": "function",
"function": {
"name": "get_weather",
"description": "Get current weather",
"parameters": {
"type": "object",
"properties": {"city": {"type": "string"}}
}
}
}]
response = Generation.call(
model='qwen3-next-80b-a3b-instruct',
prompt='What\'s the weather in Beijing?',
tools=tools,
tool_choice='auto'
)
モデルは意図を解析し、外部で実行するツール呼び出しを返します。このパターンはエージェントワークフローを強化します。これらの例により、堅牢なパイプラインを構築できます。次に、毎回コーディングすることなくこれらの呼び出しをテストおよび改良するためにApidogを組み込みます。
ワークフローの強化:Qwen3-Next-80B-A3B APIテストのためのApidog統合
Apidogは、API開発を効率的なプロセスへと変革します。特にQwen3-Next-80B-A3BのようなAIエンドポイントに威力を発揮します。このプラットフォームは、設計、モック、テスト、ドキュメント作成を1つのインターフェースに統合し、AIによるインテリジェントな自動化を可能にします。
ボタン
まず、DashScopeスキーマをApidogにインポートします。新しいプロジェクトを作成し、エンドポイントPOST https://dashscope.aliyuncs.com/api/v1/services/aigc/text-generation/generationを追加し、APIキーをヘッダーとして貼り付けます:X-DashScope-API-Key: your_key。
リクエストを視覚的に設計します。モデルパラメータを「qwen3-next-80b-a3b-instruct」に設定し、JSON形式で本文にプロンプトを入力します:{"input": {"messages": [{"role": "user", "content": "ここにプロンプトを入力"}]}}。ApidogのAIは、エッジケースのプロンプトや高温サンプルなどのバリエーションを生成し、テストケースを提案します。
テストコレクションを順次実行します。例えば、温度ごとのレイテンシをベンチマークします:
- テスト1:温度0.1、プロンプト長100トークン。
- テスト2:温度1.0、コンテキスト10Kトークン。
このツールは、応答時間、トークン使用量、エラー率などのメトリクスを追跡し、ダッシュボードで傾向を視覚化します。オフライン開発用のモックレスポンス:Apidogは履歴データに基づいてQwenの出力をシミュレートし、フロントエンドの構築を加速します。
ドキュメントはコレクションから自動的に生成されます。MoEルーティングの注意点など、Qwen3-Next-80B-A3Bの具体的な情報を含むOpenAPI仕様を例とともにエクスポートできます。コラボレーション機能により、チームは環境を共有し、一貫したテストを保証できます。
あるシナリオでは、開発者が多言語プロンプトをテストします。ApidogのAIは不整合を検出し、言語ヒントの追加などの修正を提案します。その結果、ユーザー報告によると統合時間が40%短縮されます。AIに特化したテストでは、そのインテリジェントなデータ生成を活用します。スキーマを入力すると、本番トラフィックを模倣した現実的なプロンプトが作成されます。
さらに、ApidogはCI/CDフックをサポートしており、パイプラインでAPIテストを実行します。デプロイ後の自動検証のためにGitHub Actionsと接続できます。このクローズドループアプローチにより、Qwenを利用したアプリのバグを最小限に抑えます。
高度な戦略:本番環境向けQwen3-Next-80B-A3B API呼び出しの最適化
最適化により、基本的な使用法がエンタープライズレベルの信頼性に向上します。まず、可能な場合はリクエストをバッチ処理します。DashScopeは1回の呼び出しで最大10のプロンプトをサポートしており、要約ファームのような並列タスクのオーバーヘッドを削減します。
トークンエコノミクスを監視します。モデルはアクティブなパラメータごとに課金されるため、簡潔なプロンプトはコスト削減につながります。構造化された出力にはAPIのresult_format='message'を使用し、JSONを直接解析することで後処理を避けます。
高可用性のためには、指数バックオフを伴うリトライを実装します:
import time
from dashscope import Generation
def call_with_retry(prompt, max_retries=3):
for attempt in range(max_retries):
response = Generation.call(model='qwen3-next-80b-a3b-instruct', prompt=prompt)
if response.status_code == 200:
return response
time.sleep(2 ** attempt)
raise Exception("Max retries exceeded")
これにより、429レート制限のような一時的なエラーが処理されます。地域間で呼び出しを分散することで水平にスケールします。DashScopeはシンガポールと米国のエンドポイントを提供しています。
セキュリティ上の考慮事項には、プロンプトインジェクションを防ぐための入力サニタイズが含まれます。APIに転送する前に、ユーザー入力をホワイトリストに対して検証します。さらに、監査のために応答を匿名化してログに記録し、GDPRに準拠します。
超長文コンテキストのようなエッジケースでは、入力をチャンクに分割し、予測を連結します。思考バリアントがここで役立ちます:「ステップ1:セクションAを分析する;ステップ2:Bと統合する」といったプロンプトを使用します。これにより、10万トークン以上でも一貫性が維持されます。
開発者はAlibabaのプラットフォーム経由でファインチューニングも検討しますが、APIユーザーはプロンプトエンジニアリングに限定されます。結果として、これらの戦術はスケーラブルで安全なデプロイメントを保証します。
まとめ:Qwen3-Next-80B-A3Bが注目に値する理由
Qwen3-Next-80B-A3Bは、疎なMoE、ハイブリッドゲート、優れたベンチマークにより、効率的なAIを再定義します。開発者はDashScope経由でそのAPIを活用し、Apidogのようなツールでテストの厳密性を高めながら、迅速なプロトタイピングを実現します。
これで、アーキテクチャの微妙な点から本番環境の最適化に至るまでの青写真を手に入れました。これらの洞察を実装して、より速く、よりスマートなシステムを構築しましょう。今日から実験を始めましょう。スケーラブルなインテリジェンスの未来が待っています。
ボタン