
Alibabaは、人工知能の能力の限界を押し広げるフラッグシップ大規模言語モデル「Qwen3-Max」をリリースしました。このモデルは、汎用人工知能を目標とするオープン基盤モデルの進歩で知られるQwenシリーズから登場しました。開発者や研究者は、コーディングの課題から多面的な推論まで、複雑なタスクに優れたツールにアクセスできるようになりました。チームがQwen3-MaxをAPI経由で実世界のアプリケーションに統合するにつれて、効率的なテストが不可欠になります。
Qwen3-Maxは、Qwen2.5の2倍にあたる36兆トークンでトレーニングされ、1兆を超えるパラメーターにスケールします。エージェントタスクを処理し、指示に正確に従います。明示的な思考モードなしで開始されますが、今後の機能で推論の強化が追加される予定です。
このモデルは100以上の言語をサポートし、グローバルな利用を拡大します。Alibabaはクラウド上でAPIアクセスを提供し、デプロイメントを簡素化します。
Qwen3-Maxの技術仕様
Alibabaは、スケーラビリティと効率性に焦点を当ててQwen3-Maxを設計しました。このモデルは1兆を超えるパラメーターを誇り、APIを通じて利用可能な最大のAIモデルの1つとして位置付けられています。この膨大なサイズにより、システムは事前トレーニング中に大量のデータを処理でき、堅牢なパターン認識および生成能力をもたらします。エンジニアは、Qwen2.5のような以前の世代で使用された量の2倍にあたる36兆トークンを超えるデータセットでQwen3-Maxをトレーニングしています。

Qwen3-Maxは、262,144トークンのコンテキストウィンドウを備え、最大入力は258,048トークン、最大出力は65,536トークンです。この広範なコンテキストにより、モデルは一貫性を失うことなく、長文ドキュメント、拡張された会話、複雑な問題解決シーケンスを処理できます。開発者は、ドキュメント分析や多ターン対話などのアプリケーションでこの恩恵を受けます。ただし、チャットインターフェースでは明らかな制限があるように見えるかもしれませんが、基盤となるモデルはAPI呼び出しを通じて完全な容量をサポートしています。
Qwen3-Maxは、初期リリースでは非思考型の指示モデルとして動作し、直接的な応答生成を優先します。Alibabaは、ツール使用やヘビーモード展開を含む推論機能の導入を計画しており、これによりほぼ完璧なベンチマークスコアが期待されます。アーキテクチャはQwen3シリーズから派生しており、指示追従の改善、幻覚の低減、多言語サポートの強化が組み込まれています。デプロイメントには、vLLMやSGLangなどのフレームワークが効率的なサービス提供を容易にし、複数のGPUにわたるテンソル並列処理をサポートします。
ハードウェア要件に関しては、Qwen3-Maxはかなりの計算リソースを必要とします。ローカルで実行するにはハイエンドなセットアップが必要ですが、APIアクセスによりAlibabaのクラウドインフラストラクチャを活用することでこれを軽減します。料金はトークン量に基づいた段階的な構造に従います。0~32Kトークンの場合、入力は100万トークンあたり1.2ドル、出力は100万トークンあたり6ドル。32K~128Kの場合、2.4ドルと12ドル。128K~252Kの場合、3ドルと15ドルです。新規ユーザーは90日間有効な100万トークンの無料枠を受け取ることができ、実験を奨励しています。
さらに、Qwen3-MaxはOpenAI互換APIと統合されており、他のプロバイダーからの移行を簡素化します。この互換性はコンテキストキャッシングにも及び、繰り返しのクエリを最適化し、本番環境でのコストを削減します。それにもかかわらず、安定した運用のためには、ユーザーは最新バージョンとスナップショットバージョンを選択して、レート制限を効果的に管理します。
ベンチマーク性能分析
Qwen3-Maxは複数のベンチマークで卓越した結果を示し、AI性能のリーダーとしての地位を確固たるものにしています。Alibabaは、コーディング、数学、および一般的な推論に焦点を当てた厳格なテストでモデルを評価しています。たとえば、SuperGPQAでは、Qwen3-Max-Instructが65.1を記録し、Claude Opus 4の56.5、DeepSeek-V3.1の43.9を上回っています。
さらに、難易度の高い数学ベンチマークであるAIME25では、Qwen3-Maxが81.6を達成し、Qwen3-235B-A22Bの70.3などを大きく上回っています。これは、精度と論理的推論が重要となる高度な数学的問題を解決する上でのその卓越した能力を際立たせています。コーディング評価に移行すると、LiveCodeBench v6ではQwen3-Maxが74.8のスコアを出し、Non-thinkingの52.3などの競合他社を上回っています。
さらに、Tau2-Bench (Verified) ではQwen3-Maxが69.6、SWE-Bench Verifiedでは72.5を記録し、いずれもトップを走っています。これらのスコアは、モデルがGitHubリポジトリからの問題を効果的に解決する、実世界のコーディング課題に由来しています。Alibabaはこれを、絶え間ない計算スケーリングと膨大な事前トレーニングデータによるものとしています。
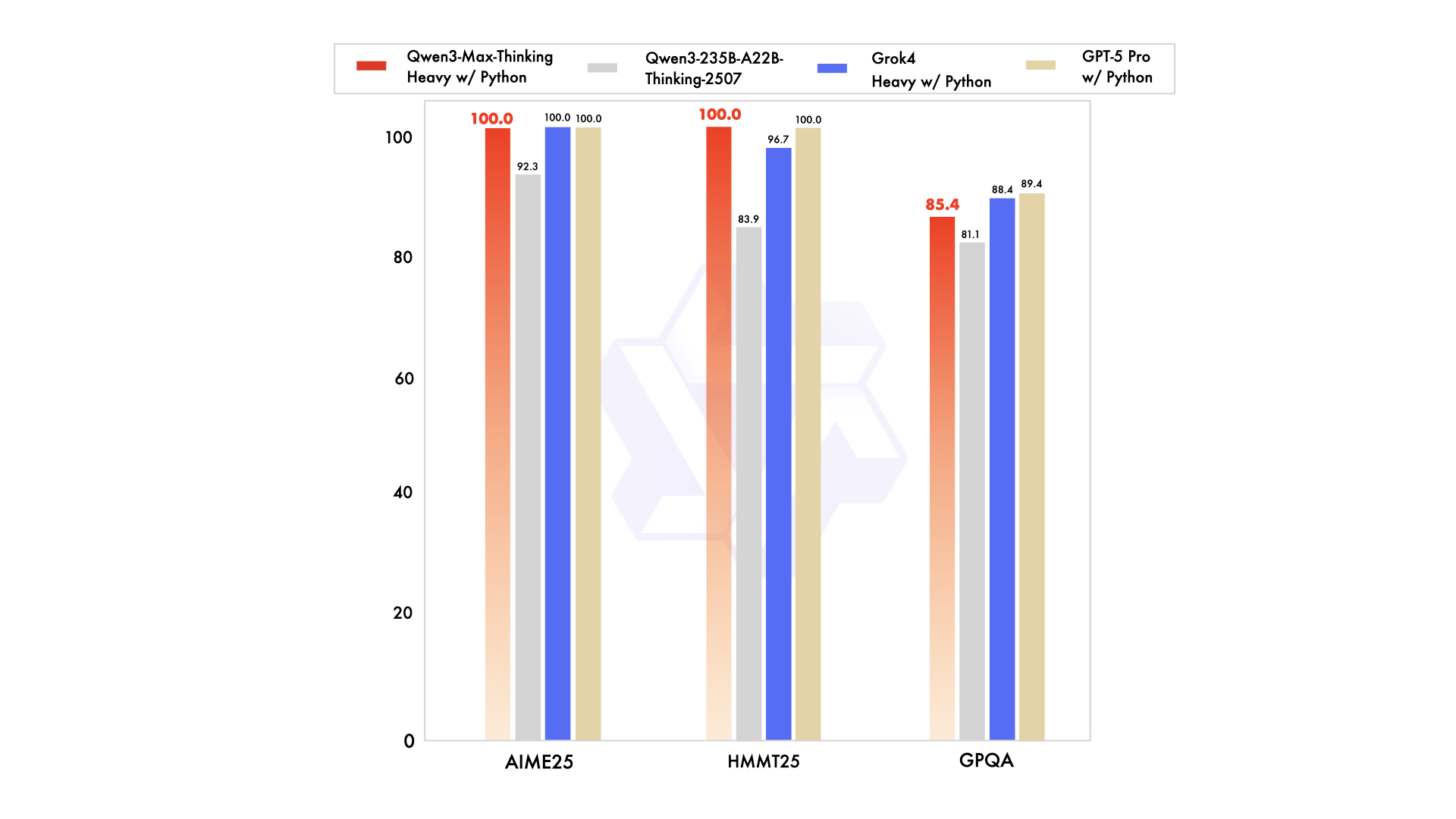
さらに、Qwen3-MaxはArena-Hard v2やLiveBenchなどのエージェントベンチマークで優れており、Claude Opus 4やDeepSeek-V3.1を常に上回る順位を記録しています。コミュニティテストでは、その非推論ベースにもかかわらず、より困難なタスクで推論のような振る舞いを示すという逸話的な証拠が明らかになっています。しかし、正式なベンチマークでは、幻覚、一般知識、倫理などの分野で100%の成功率を達成し、その信頼性が確認されています。
アナリストは、思考予算を有効にすると、数学、コーディング、科学の分野でパフォーマンスが向上すると指摘しています。Qwenアプリでアクセスできるこのユーザー制御機能は、推論の深さをきめ細かく制御できます。全体として、これらの指標はQwen3-Maxの効率性を示しており、速度で同業他社の中で63パーセンタイル、価格で34パーセンタイルにランク付けされています。
主要なAIモデルとの比較
Qwen3-Maxは、GPT-5、Claude 4 Opus、DeepSeek-V3.1などのトップモデルと直接競合します。コーディングタスクでは、Qwen3-Maxはフロントエンド開発とJava変換でDeepSeek-V3.1を上回りますが、Pythonの改善は控えめです。Redditのようなプラットフォームでのコミュニティのフィードバックは、年末までにGPT-5 Proに匹敵するかそれを超える可能性を強調しています。
さらに、Claude Opus 4に対して、Qwen3-MaxはSuperGPQAとAIME25でリードし、より強力な数学的および一般的な能力を示しています。このモデルの1兆パラメーター規模は、ロングテール知識のカバー範囲において優位性をもたらし、先行モデルと比較して幻覚を低減します。しかし、Claudeの推論モードは特定のシナリオで利点を提供しており、Qwen3-Maxは今後のアップデートでこれに対応します。
多言語タスクでは、Qwen3-Maxは100以上の言語をサポートし、Gemini-2.5-ProやGrok-3と競合します。ベンチマークでは、特に指示追従とツール使用において、これらのモデルに対して競争力のある結果を示しています。価格面では、Qwen3-Maxはより費用対効果が高く、OpenAIやAnthropicのプレミアムオプションを下回る段階的な料金設定となっています。
さらに、Qwen3-235B-A22Bのようなオープンウェイトモデルと比較して、Maxバリアントは深い思考なしにエージェントスキルを強化し、SWE-BenchおよびTau2-Benchでより高いスコアを達成しています。これは、オープンソースとクローズドソースの強みの中間的な位置付けとなりますが、そのクローズドソースの性質はアクセシビリティに関する議論を引き起こします。
主要な機能と能力
Qwen3-Maxはチャットボットや執筆における指示追従に優れています。幻覚の低減は、分類や倫理における信頼性を保証します。
エージェント機能は、Qwen-Agentツール呼び出しを介して多段階プロセスを処理します。高速な応答はリアルタイムアプリに適しています。
OpenAI互換の関数呼び出しをサポートしています。長いコンテキストはデータ分析を助け、パラメーターは創造性を高めます。
非推論型であるため、構造化された思考に適応します。将来の思考予算はドメインパフォーマンスを調整します。
ApidogとのAPI統合と利用
開発者は主にAlibaba CloudのAPIを通じてQwen3-Maxにアクセスします。このAPIはOpenAI互換のエンドポイントをサポートしています。この設定により、標準ライブラリを使用してアプリケーションへの簡単な統合が可能になります。たとえば、ユーザーは「なぜ空は青いのですか?」のようなプロンプトでAPIを呼び出し、応答を生成できます。
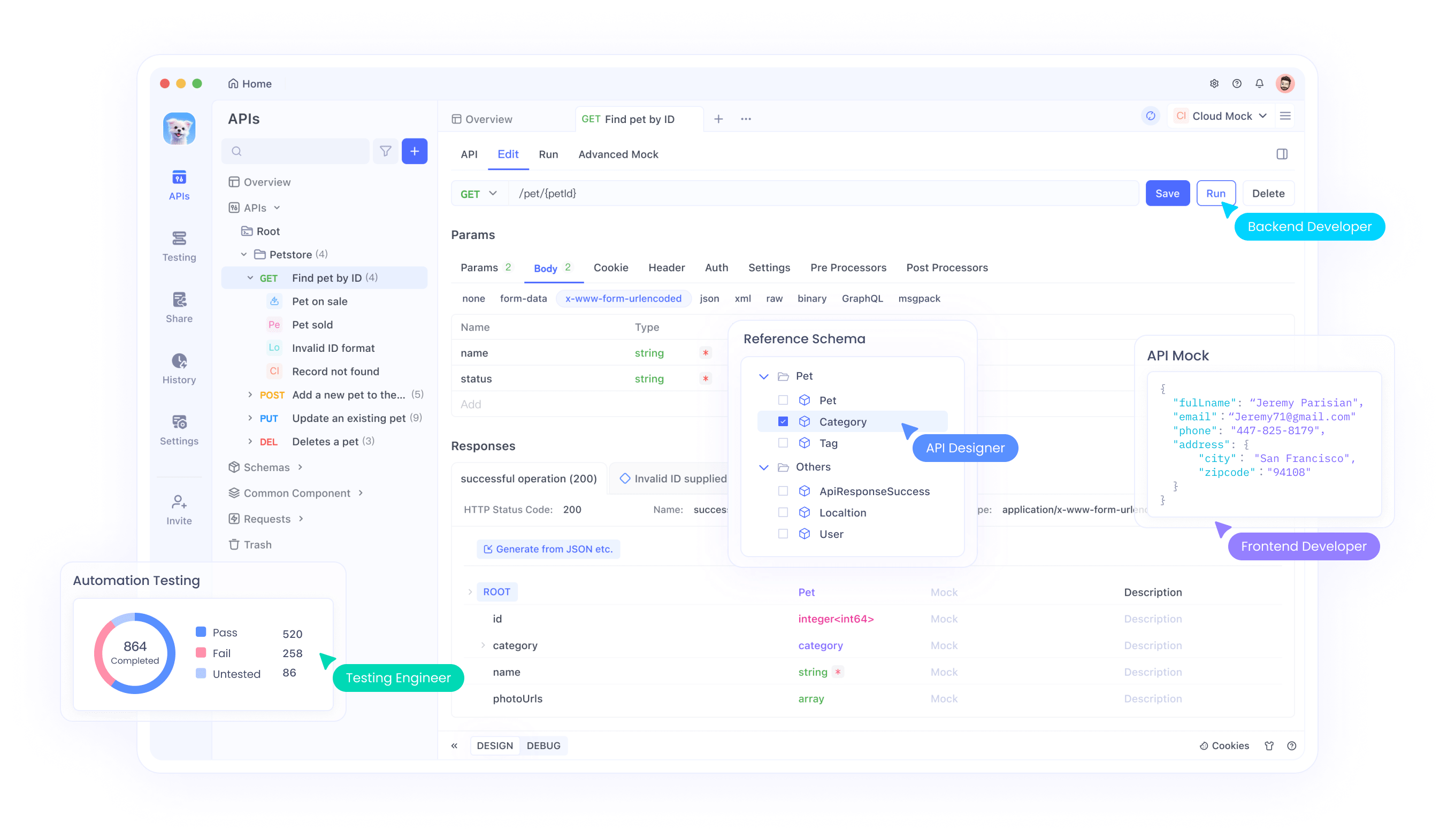
Apidogはここで重要な役割を果たし、APIテストと管理のための直感的なプラットフォームを提供します。エンジニアはApidogを使用して、リクエストのシミュレーション、応答の監視、Qwen3-Maxとの統合のデバッグを行います。リクエストチェーンや環境変数などのツールの機能は、大量のトークンを処理する際のワークフローを合理化します。
さらに、Apidogはコラボレーションをサポートしており、チームがQwen3-MaxプロジェクトのAPIコレクションを共有できます。開始するには、Apidogを無料でダウンロードし、AlibabaのドキュメントからQwen API仕様をインポートしてください。これにより、繰り返しタスクでのレイテンシを削減するコンテキストキャッシングなどの機能の効率的なテストが保証されます。
さらに、OpenRouterやVercel AI Gatewayなどのプロバイダーとの統合により、選択肢が広がります。Apidogはこれら間の切り替えを容易にし、エコシステム全体での互換性とパフォーマンス監視を保証します。
Qwen3-Maxのユースケース
組織は、Qwen3-Maxを多様なシナリオで適用し、その能力をイノベーションに活用しています。ソフトウェア開発では、このモデルはコード生成とデバッグを支援し、SWE-Benchで高い精度でGitHubの問題を解決します。開発者はAPIを介してこれを統合し、プルリクエストを自動化したり、レガシーコードをリファクタリングしたりします。
さらに、教育分野では、Qwen3-Maxが高度な数学の問題を解決し、AIME25ベンチマークからの概念を説明する上で講師を支援します。その多言語サポートにより、グローバルな学習プラットフォームは母国語でコンテンツを提供できます。
エンタープライズ環境では、エージェント機能がカスタマーサービス用のチャットボットやデータ分析パイプラインなどの自動化ツールを強化します。医療提供者は、倫理ベンチマークで完璧なスコアを達成していることから、倫理的な意思決定支援にこれを利用しています。
さらに、クリエイティブ産業では、Qwen3-Maxを執筆やコンテンツ生成に利用しており、幻覚の低減により高品質な出力が保証されます。Eコマースプラットフォームは、ユーザー履歴からの長いコンテキストを処理し、パーソナライズされたレコメンデーションのためにこれを統合しています。
しかし、研究分野では、科学者たちはシミュレーションや仮説検証におけるその推論の可能性を探っており、思考モードの強化を期待しています。
まとめ
Qwen3-Maxは、その1兆パラメーターの力とベンチマークでの優位性により、AIの状況を一変させます。開発者は、Apidogのようなツールによって強化されたAPIを通じてその力を活用し、効率的な統合を実現します。Alibabaがモデルを洗練させるにつれて、コーディング、推論、そしてそれ以外の分野でさらに大きな革新が期待されます。進化する分野で競争力を維持するために、チームは今日Qwen3-Maxを採用しています。