Alibaba CloudのQwenチームは、大規模言語モデル(LLM)のラインナップに、Qwen3-4B-Instruct-2507とQwen3-4B-Thinking-2507という2つの強力なモデルを追加しました。これらのモデルは、推論、指示の理解、長文コンテキスト理解において大幅な進歩をもたらし、256Kトークンのコンテキスト長をネイティブでサポートしています。開発者、研究者、AI愛好家向けに設計されており、コーディングから複雑な問題解決まで、幅広いタスクに対応する堅牢な機能を提供します。さらに、無料のAPI管理プラットフォームであるApidogのようなツールは、これらのモデルのテストとアプリケーションへの統合を効率化できます。
Qwen3-4Bモデルの理解
Qwen3シリーズは、Alibaba Cloudの大規模言語モデルファミリーにおける最新の進化を表しており、Qwen2.5シリーズの後継です。具体的には、Qwen3-4B-Instruct-2507とQwen3-4B-Thinking-2507は、異なるユースケース向けに調整されています。前者は汎用的な対話と指示の理解に優れ、後者は複雑な推論タスクに最適化されています。どちらのモデルも262,144トークンのネイティブコンテキスト長をサポートしており、広範なデータセット、長文ドキュメント、または複数ターンの会話を容易に処理できます。さらに、Hugging Face Transformersのようなフレームワークや、Apidogのようなデプロイツールとの互換性により、ローカルおよびクラウドベースのアプリケーションの両方でアクセス可能です。
Qwen3-4B-Instruct-2507: 効率性への最適化
Qwen3-4B-Instruct-2507モデルは、非思考モードで動作し、汎用タスク向けの効率的で高品質な応答に焦点を当てています。このモデルは、指示の理解、論理的推論、テキスト理解、および多言語機能を強化するためにファインチューニングされています。特筆すべきは、<think></think>ブロックを生成しないため、段階的な推論よりも迅速で直接的な回答が求められるシナリオに最適です。
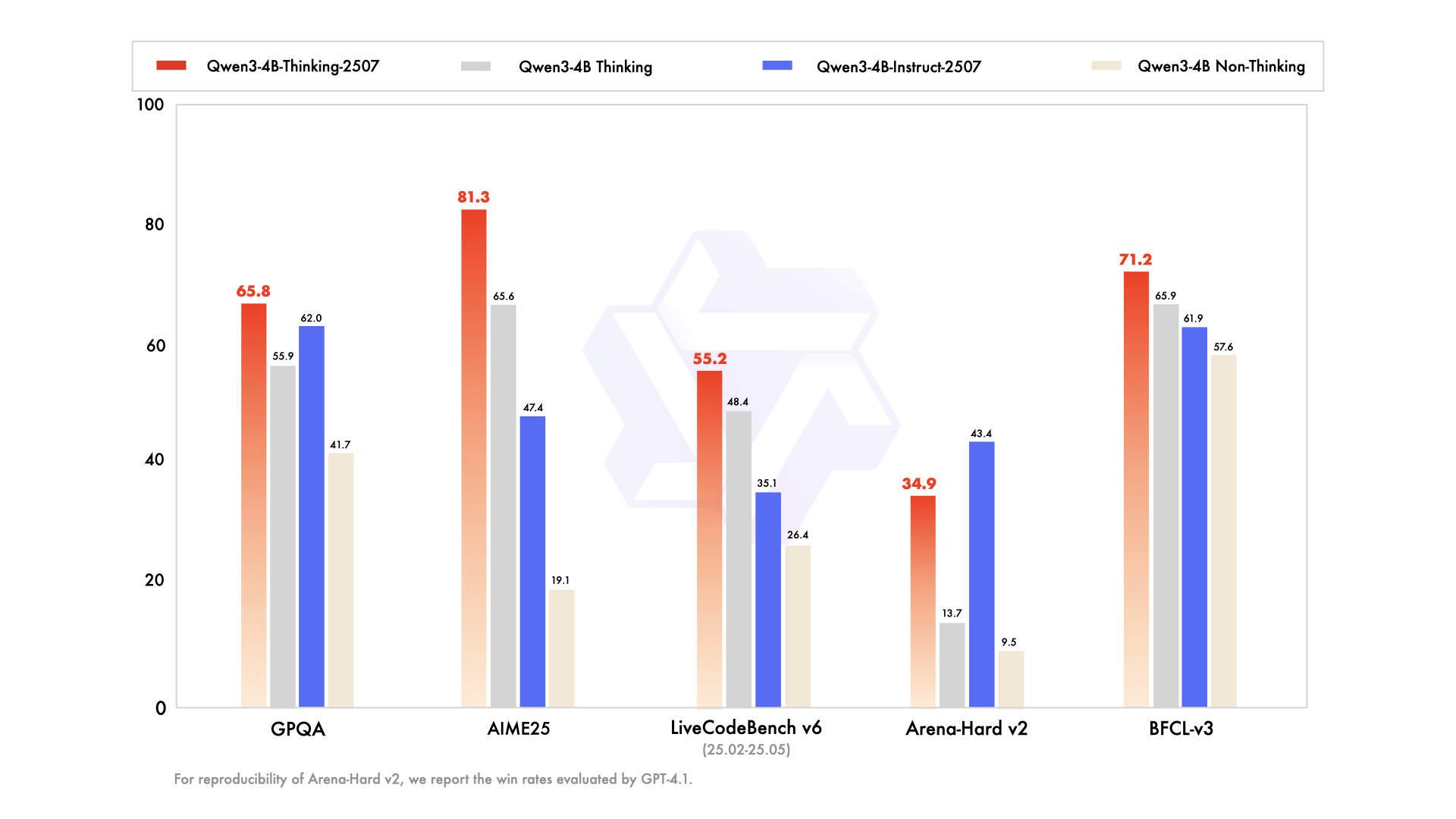
主な機能強化は以下の通りです。
- 汎用機能の向上: 数学、科学、コーディング、ツール使用において優れたパフォーマンスを発揮し、技術的なアプリケーションに多用途性をもたらします。
- 多言語サポート: 100以上の言語と方言に対応し、グローバルなアプリケーションで堅牢なパフォーマンスを保証します。
- 長文コンテキスト理解: 256Kトークンのコンテキスト長により、法的文書や長大なコードベースなどの拡張された入力を、切り捨てなしで処理します。
- ユーザーの好みに合わせた調整: より自然で魅力的な応答を提供し、クリエイティブライティングや複数ターンの対話に優れています。
このモデルをAPIに統合する開発者向けに、ApidogはAPIエンドポイントをテストおよび管理するための使いやすいインターフェースを提供し、シームレスなデプロイを保証します。この効率性により、Qwen3-4B-Instruct-2507は、迅速で正確な応答を必要とするアプリケーションにとって最適な選択肢となります。
Qwen3-4B-Thinking-2507: 深い推論のために構築
対照的に、Qwen3-4B-Thinking-2507は、論理的な問題解決、数学、学術的なベンチマークなど、集中的な推論を必要とするタスク向けに設計されています。このモデルは思考モードでのみ動作し、複雑な問題を分解するために思考連鎖(CoT)プロセスを自動的に組み込みます。デフォルトのチャットテンプレートが思考動作を埋め込んでいるため、その出力には開始<think>タグなしで終了</think>タグが含まれる場合があります。
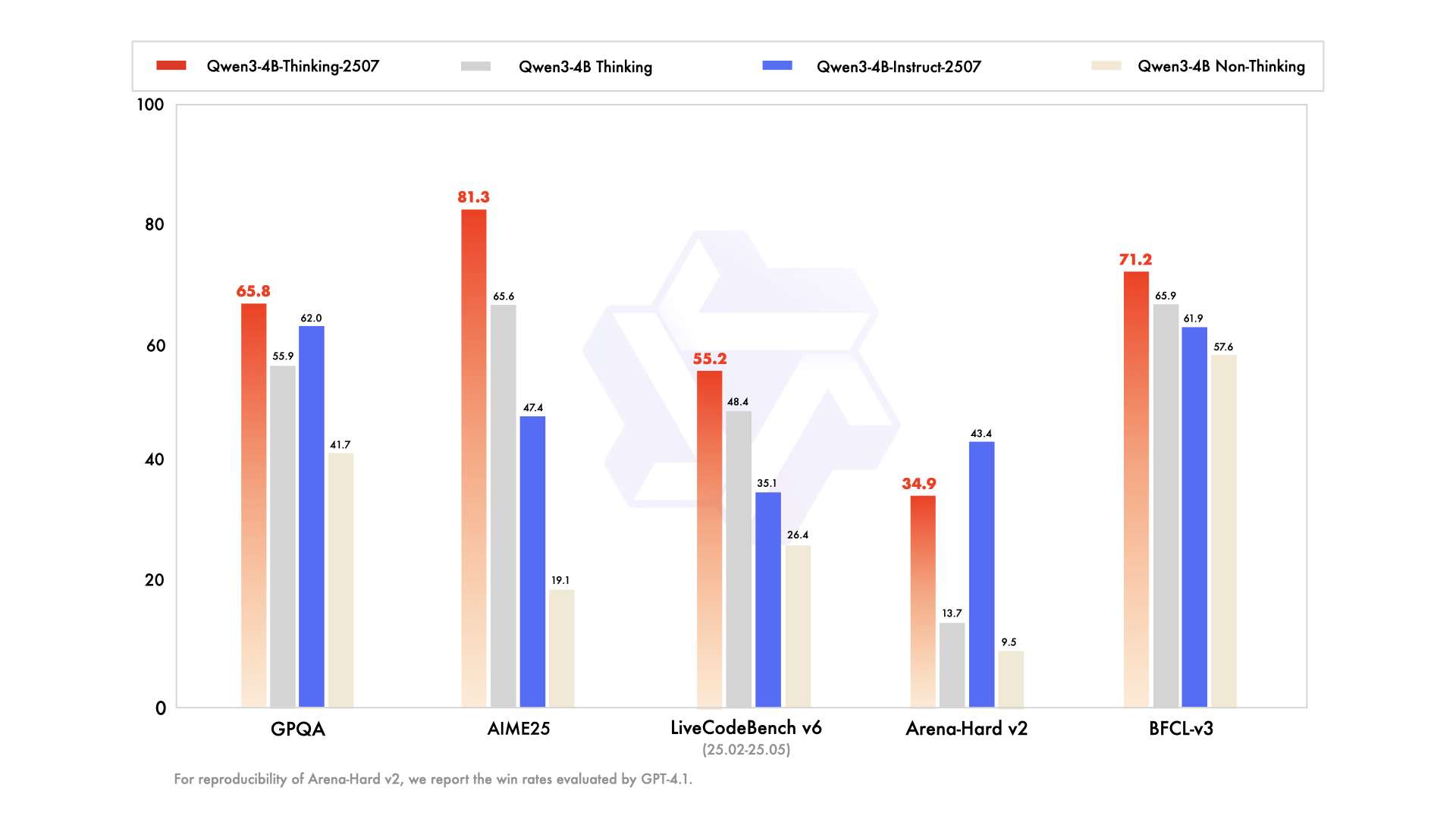
主な機能強化は以下の通りです。
- 高度な推論機能: 特にSTEM分野やコーディングにおいて、オープンソースの思考モデルの中で最先端の結果を達成します。
- 思考の深さの増加: 人間エキスパートレベルの推論を必要とするタスクに優れており、徹底的な分析のための拡張された思考長を備えています。
- 256Kコンテキスト長: Instruct版と同様に、大規模なデータセットや複雑なクエリの処理に理想的な、巨大なコンテキストウィンドウをサポートします。
- ツール統合: Qwen-Agentのようなツールを活用して、エージェントワークフローを効率化し、自動化されたシステムでの有用性を高めます。
推論集約型アプリケーションに取り組む開発者向けに、ApidogはAPIテストを容易にし、モデルの出力が期待される結果と一致することを保証します。このモデルは、特に研究環境や複雑な問題解決シナリオに適しています。
技術仕様とアーキテクチャ
Qwen3-4BモデルはどちらもQwen3ファミリーの一部であり、密結合(Dense)およびエキスパート混合(MoE)アーキテクチャを含みます。4Bという名称は、40億のパラメータを指し、計算効率とパフォーマンスのバランスを取っています。その結果、これらのモデルは、Qwen3-235B-A22Bのような大規模なモデルとは異なり、消費者向けハードウェアでアクセス可能です。
アーキテクチャのハイライト
- 密結合モデル設計: MoEモデルとは異なり、Qwen3-4Bモデルは密結合アーキテクチャを使用しており、選択的なパラメータ活性化の必要なしに、タスク全体で一貫したパフォーマンスを保証します。
- コンテキスト拡張のためのYaRN: モデルはYaRNを活用して、コンテキスト長を32,768トークンから262,144トークンに拡張し、パフォーマンスを大幅に低下させることなく長文コンテキスト処理を可能にします。
- トレーニングパイプライン: Qwenチームは、長思考連鎖コールドスタート、推論ベースの強化学習、思考モード融合、汎用強化学習を含む4段階のトレーニングプロセスを採用しました。このアプローチは、推論と対話の両方の機能を強化します。
- 量子化サポート: 両モデルはFP8量子化をサポートしており、精度を維持しながらメモリ要件を削減します。例えば、Qwen3-4B-Thinking-2507-FP8は、リソースが制約された環境で利用可能です。
ハードウェア要件
これらのモデルを効率的に実行するには、以下を考慮してください。
- GPUメモリ: FP8量子化モデルには最低8GBのVRAMが推奨されますが、bfloat16モデルには16GB以上が必要な場合があります。
- RAM: 最適なパフォーマンスのために、ほとんどのタスクでは16GBの統合メモリ(VRAM + RAM)で十分です。
- 推論フレームワーク: 両モデルはHugging Face Transformers(バージョン≥4.51.0)、vLLM(≥0.8.5)、およびSGLang(≥0.4.6.post1)と互換性があります。OllamaやLMStudioのようなローカルツールもQwen3をサポートしています。
これらのモデルをデプロイする開発者向けに、ApidogはAPIパフォーマンスを監視およびテストするツールを提供することでプロセスを簡素化し、推論フレームワークとの効率的な統合を保証します。
Hugging FaceおよびModelScopeとの統合
Qwen3-4BモデルはHugging FaceとModelScopeの両方で利用可能であり、開発者に柔軟性を提供します。以下に、Hugging Face TransformersでQwen3-4B-Instruct-2507を使用する方法を示すコードスニペットを提供します。

from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen3-4B-Instruct-2507"tokenizer = AutoTokenizer.from_pretrained(model_name)model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype="auto", device_map="auto")
prompt = "Write a Python function to calculate Fibonacci numbers."messages = [{"role": "user", "content": prompt}]text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(**model_inputs, max_new_tokens=16384)output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()content = tokenizer.decode(output_ids, skip_special_tokens=True)print("Generated Code:\n", content)Qwen3-4B-Thinking-2507の場合、思考コンテンツを処理するために追加の解析が必要です。
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen3-4B-Thinking-2507"tokenizer = AutoTokenizer.from_pretrained(model_name)model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype="auto", device_map="auto")
prompt = "Solve the equation 2x^2 + 3x - 5 = 0."messages = [{"role": "user", "content": prompt}]text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(**model_inputs, max_new_tokens=32768)output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
try:index = len(output_ids) - output_ids[::-1].index(151668) # tokenexcept ValueError:index = 0thinking_content = tokenizer.decode(output_ids[:index], skip_special_tokens=True).strip("\n")content = tokenizer.decode(output_ids[index:], skip_special_tokens=True).strip("\n")print("Thinking Process:\n", thinking_content)print("Solution:\n", content)これらのスニペットは、QwenモデルをPythonワークフローに簡単に統合できることを示しています。APIベースのデプロイメントの場合、Apidogはこれらのエンドポイントをテストし、信頼性の高いパフォーマンスを保証するのに役立ちます。
パフォーマンスの最適化とベストプラクティス
Qwen3-4Bモデルのパフォーマンスを最大化するために、以下の推奨事項を考慮してください。
- サンプリングパラメータ: Qwen3-4B-Instruct-2507には、
temperature=0.7、top_p=0.8、top_k=20、min_p=0を使用します。Qwen3-4B-Thinking-2507には、temperature=0.6、top_p=0.95、top_k=20、min_p=0を使用します。パフォーマンスの低下を防ぐため、貪欲なデコーディングは避けてください。 - コンテキスト長管理: メモリ不足の問題が発生した場合は、コンテキスト長を32,768トークンに削減してください。ただし、推論タスクの場合、コンテキスト長は131,072トークン以上に維持してください。
- 存在ペナルティ: 繰り返しを減らすために
presence_penaltyを0から2の間に設定しますが、言語の混同を防ぐために高い値は避けてください。 - 推論フレームワーク: 高スループットの推論にはvLLMまたはSGLangを使用し、APIパフォーマンスの監視にはApidogを活用してください。
Qwen3-4B-Instruct-2507とQwen3-4B-Thinking-2507の比較
両モデルは同じ40億パラメータのアーキテクチャを共有していますが、その設計思想は異なります。
- Qwen3-4B-Instruct-2507: 速度と効率を優先し、チャットボット、カスタマーサポート、汎用アプリケーションに適しています。
- Qwen3-4B-Thinking-2507: 深い推論に焦点を当て、学術研究、複雑な問題解決、思考連鎖プロセスを必要とするタスクに理想的です。
開発者は、/thinkと/no_thinkプロンプトを使用してモードを切り替えることができ、タスク要件に基づいて柔軟性を持たせることができます。Apidogは、API駆動型アプリケーションでのこれらのモード切り替えのテストを支援できます。
コミュニティとエコシステムのサポート
Qwen3-4Bモデルは、Hugging Face、ModelScope、およびOllama、LMStudio、llama.cppのようなツールからのサポートを受けて、堅牢なエコシステムから恩恵を受けています。Apache 2.0ライセンスの下でのこれらのモデルのオープンソースの性質は、コミュニティの貢献とファインチューニングを奨励しています。例えば、UnslothはVRAMを70%削減して2倍高速なファインチューニングを可能にするツールを提供しており、これらのモデルをより幅広いユーザーが利用できるようにしています。
結論
Qwen3-4B-Instruct-2507およびQwen3-4B-Thinking-2507モデルは、Alibaba CloudのQwenシリーズにおける大きな飛躍を示しており、指示の理解、推論、長文コンテキスト処理において比類のない機能を提供します。256Kトークンのコンテキスト長、多言語サポート、およびApidogのようなツールとの互換性により、これらのモデルは開発者がインテリジェントでスケーラブルなアプリケーションを構築することを可能にします。コードの生成、方程式の解決、多言語チャットボットの作成など、これらのモデルは優れたパフォーマンスを発揮します。今日からその可能性を探り始め、Apidogを使用してAPI統合を効率化し、シームレスな開発体験を実現しましょう。