
AlibabaのQwenチームは、Qwen2.5-VL-32B-Instructモデルのリリースで人工知能の限界を再び押し広げました。これは、よりスマートで軽量の画期的なビジョン・ランゲージモデル(VLM)です。
2025年3月24日に発表されたこの320億パラメータのモデルは、性能と効率の最適なバランスを実現しており、開発者や研究者にとって理想的な選択肢となっています。Qwen2.5-VLシリーズの成功を基に、この新しいバージョンでは数学的推論、人間の好みに合わせた整合性、視覚タスクにおける重要な進展が紹介されており、ローカルデプロイメントのための扱いやすいサイズを維持しています。
この強力なモデルをプロジェクトに統合したい開発者のために、堅牢なAPIツールを探索することが重要です。だからこそ、私たちは無料でApidogをダウンロードすることをお勧めします。Apidogは、Qwenのようなモデルをアプリケーションにテストし統合を簡素化するユーザーフレンドリーなAPI開発プラットフォームです。Apidogを使用すると、Qwen APIとのシームレスなやり取りが可能になり、ワークフローが効率化され、この革新的なVLMの可能性を最大限に引き出すことができます。今日、Apidogをダウンロードして、よりスマートなアプリケーションの構築を始めましょう!
このAPIツールを使用すると、モデルのエンドポイントを簡単にテストおよびデバッグできます。今日、無料でApidogをダウンロードし、Mistral Small 3.1の機能を探索しながらワークフローを効率化しましょう!
Qwen2.5-VL-32B: よりスマートなビジョン・ランゲージモデル
Qwen2.5-VL-32Bの独自性とは?
Qwen2.5-VL-32Bは、Qwenファミリーの大きなモデルと小さなモデルの制限に対処するために設計された320億パラメータのビジョン・ランゲージモデルです。72億パラメータのモデルであるQwen2.5-VL-72Bは強力な能力を提供しますが、しばしば多くの計算リソースを必要とし、ローカルでのデプロイメントには不向きです。対照的に、70億パラメータのモデルは軽量ですが、複雑なタスクに必要な深みが欠けている場合があります。Qwen2.5-VL-32Bは、高性能を維持しつつ、より管理しやすいフットプリントでこのギャップを埋めます。
このモデルは、マルチモーダル能力で広く評価されたQwen2.5-VLシリーズを基にしています。しかし、Qwen2.5-VL-32Bは、強化学習(RL)を通じた最適化などの重要な改善をもたらします。このアプローチは、モデルの人間の好みに対する整合性を向上させ、より詳細かつユーザーフレンドリーな出力を確保します。さらに、このモデルは優れた数学的推論能力を示し、複雑な問題解決やデータ分析を伴うタスクにとって不可欠な特徴となっています。

主要な技術的改善点
Qwen2.5-VL-32Bは、強化学習を活用して出力スタイルを洗練させ、応答がより一貫性があり、詳細で、より良い人間とのインタラクション用にフォーマットされます。さらに、数学的推論能力は大幅に改善されており、MathVistaやMMMUのようなベンチマークでのパフォーマンスが証明しています。これらの改善は、特にテキストと視覚データが交差するマルチモーダルコンテキストにおける正確性と論理的推論を最優先する微調整されたトレーニングプロセスから生じています。
このモデルはまた、細かい画像理解と推論に優れており、グラフ、チャート、ドキュメントなどの視覚コンテンツの正確な分析を可能にします。この機能により、Qwen2.5-VL-32Bは、先進的な視覚論理推論とコンテンツ認識を必要とするアプリケーションのトップ候補となっています。
Qwen2.5-VL-32Bの性能ベンチマーク:大規模モデルを超えて
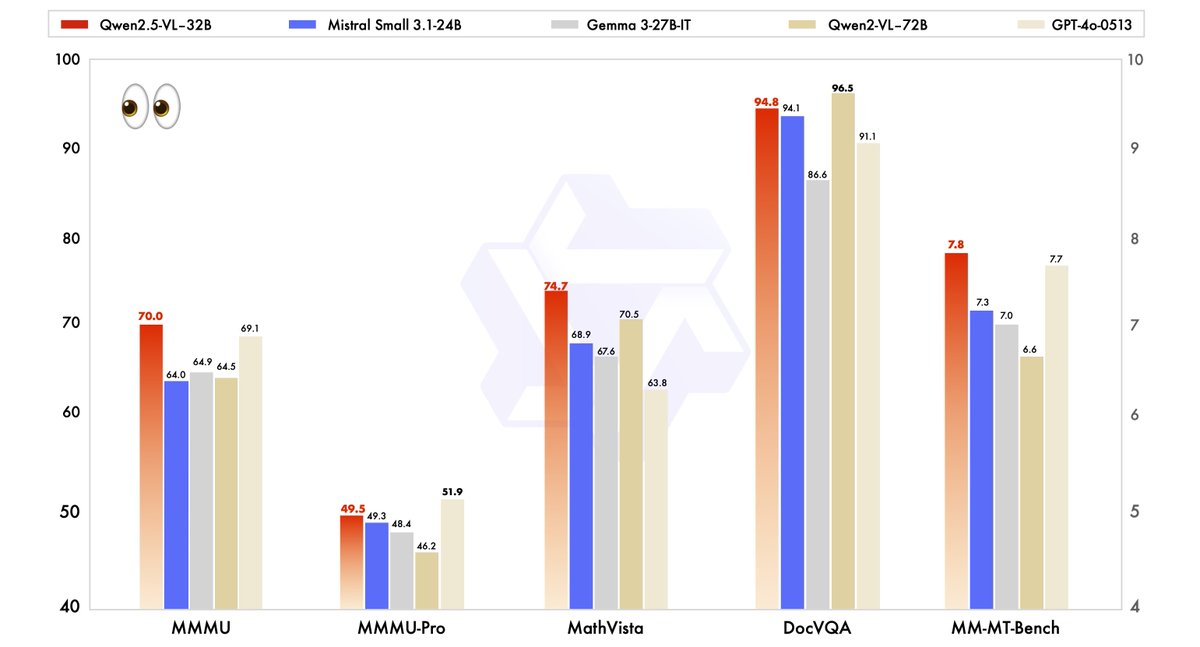
Qwen2.5-VL-32Bの性能は、Qwen2.5-VL-72Bなどの最先端モデルや、Mistral-Small-3.1–24BやGemma-3–27B-ITなどの競合と厳密に評価されました。結果は、いくつかの重要な分野でのモデルの優位性を浮き彫りにしています。
- MMMU(Massive Multitask Language Understanding): Qwen2.5-VL-32Bは70.0のスコアを達成し、Qwen2.5-VL-72Bの64.5を上回ります。このベンチマークは、さまざまなタスクにおける複雑で多段階の推論をテストし、モデルの認知能力の向上を示しています。
- MathVista: Qwen2.5-VL-32Bは74.7のスコアを持ち、Qwen2.5-VL-72Bの70.5を上回り、数学的および視覚的推論タスクにおける強みを強調しています。
- MM-MT-Bench: この主観的ユーザー体験評価ベンチマークは、Qwen2.5-VL-32Bが前のモデルよりも大きな差で優れていることを示しており、人間の好みの整合性が改善されていることを反映しています。
- テキストベースのタスク(例:MMLU、MATH、HumanEval): このモデルは、GPT-4o-Miniなどの大規模モデルと効果的に競争し、MMLUで78.4、MATHで82.2、HumanEvalで91.5のスコアを達成しています。これは、パラメータ数が少ないにもかかわらずの成果です。
これらのベンチマークは、Qwen2.5-VL-32Bが大規模モデルに匹敵するだけでなく、しばしばそれを超える性能を発揮することを示しており、すべてはより少ない計算リソースで実現しています。この力と効率のバランスは、限られたハードウェアで作業する開発者や研究者にとって魅力的な選択肢となります。
サイズが重要な理由:320億の利点
Qwen2.5-VL-32Bの320億パラメータのサイズは、ローカルデプロイメントにおいて理想的な位置を占めています。72Bモデルは広範なGPUリソースを要求しますが、この軽量モデルは、関連するWeb結果で指摘されているように、SGLangやvLLMなどの推論エンジンとシームレスに統合できます。この互換性は、迅速なデプロイメントと低いメモリ使用率を確保し、スタートアップから大企業まで幅広いユーザーがアクセスできるようにします。
さらに、このモデルのスピードと効率の最適化は、その能力を損なうものではありません。物体認識、チャートの分析、請求書や表のような構造化された出力の処理などのマルチモーダルタスクを処理する能力は依然として強力で、実世界のアプリケーションにとって多用途なツールとなっています。

MLXを使ってQwen2.5-VL-32Bをローカルで実行する
この強力なモデルをApple Siliconを搭載したMacでローカルに実行するには、以下の手順に従ってください:
システム要件
- Apple Siliconを搭載したMac(M1、M2、またはM3チップ)
- 最小32GBのRAM(64GB推奨)
- 60GB以上の空きストレージスペース
- macOS Sonomaまたはそれ以降
インストール手順
- Python依存関係をインストール
pip install mlx mlx-llm transformers pillow
- モデルをダウンロード
git lfs install
git clone https://huggingface.co/Qwen/Qwen2.5-VL-32B-Instruct
- モデルをMLX形式に変換する
python -m mlx_llm.convert --model-name Qwen/Qwen2.5-VL-32B-Instruct --mlx-path ./qwen2.5-vl-32b-mlx
- モデルとインタラクトする簡単なスクリプトを作成
import mlx.core as mx
from mlx_llm import load, generate
from PIL import Image
# モデルをロード
model, tokenizer = load("./qwen2.5-vl-32b-mlx")
# 画像をロード
image = Image.open("path/to/your/image.jpg")
# 画像を使ったプロンプトを作成
prompt = "この画像に何が見えますか?"
outputs = generate(model, tokenizer, prompt=prompt, image=image, max_tokens=512)
print(outputs)
実用的なアプリケーション:Qwen2.5-VL-32Bを活用する
ビジョンタスクのその先へ
Qwen2.5-VL-32Bの高度な視覚能力は、さまざまなアプリケーションの扉を開きます。例えば、視覚エージェントとして機能し、コンピュータや電話のインターフェースと動的に対話し、ナビゲーションやデータ抽出などのタスクを実行できます。最大1時間までの長いビデオを理解し、関連セグメントを特定する能力は、ビデオ分析や時間的ローカライズにもさらなる利便性をもたらします。
ドキュメント解析においても、このモデルは多シーン、多言語コンテンツ、手書きのテキスト、表、チャート、化学式を処理するのに優れています。これにより、構造化データの正確な抽出が重要な金融、教育、医療などの業界にとって不可欠なツールとなります。
テキストおよび数学的推論
視覚タスクを越えて、Qwen2.5-VL-32Bは特に数学的推論やコーディングを含むテキストベースのアプリケーションで光ります。MATHやHumanEvalなどのベンチマークでの高得点は、複雑な代数問題の解決、関数グラフの解釈、および正確なコードスニペットの生成における能力を示しています。この視覚とテキストの両方での能力は、Qwen2.5-VL-32BをマルチモーダルAIの課題に対する包括的なソリューションとして位置付けています。

Qwen2.5-VL-32Bの使用場所
オープンソースおよびAPIアクセス
Qwen2.5-VL-32BはApache 2.0ライセンスの下で利用可能であり、世界中の開発者にとってオープンソースでアクセス可能です。このモデルにはいくつかのプラットフォームを通じてアクセスできます:
- Hugging Face: このモデルはHugging Faceにホストされており、ローカルで使用するためにダウンロードするか、Transformersライブラリを通じて統合できます。
- ModelScope: AlibabaのModelScopeプラットフォームは、モデルへのアクセスとデプロイの別の手段を提供します。
スムーズな統合のために、開発者はQwen APIを使用できます。これはモデルとのインタラクションを簡素化します。カスタムアプリケーションを構築する場合でも、マルチモーダルタスクを試す場合でも、Qwen APIは効率的な接続と robustパフォーマンスを確保します。
推論エンジンを使用したデプロイ
Qwen2.5-VL-32BはSGLangやvLLMなどの推論エンジンでのデプロイをサポートしています。これらのツールは、モデルを迅速に推論できるように最適化し、レイテンシとメモリ使用量を削減します。これらのエンジンを活用することで、開発者は特定のユースケースに合わせてローカルハードウェアやクラウドプラットフォームでモデルをデプロイできます。
開始するには、必要なライブラリ(例:transformers、vllm)をインストールし、QwenのGitHubページまたはHugging Faceのドキュメントに従ってください。このプロセスにより、スムーズな統合が保証され、モデルの可能性を最大限に活用できます。
ローカルパフォーマンスの最適化
ローカルでQwen2.5-VL-32Bを実行する際は、次の最適化ヒントを考慮してください:
- 量子化: メモリ要求を削減するために、変換中に
--quantizeフラグを追加します。 - コンテキスト長を管理: より迅速な応答のために入力トークンを制限します。
- リソースを多く消費するアプリケーションを終了してからモデルを実行します。
- バッチ処理: 複数の画像を処理する場合は、個別ではなくバッチで処理します。
結論: なぜQwen2.5-VL-32Bが重要なのか
Qwen2.5-VL-32Bは、ビジョン・ランゲージモデルの進化における重要なマイルストーンを表しています。よりスマートな推論、軽量なリソース要件、堅牢なパフォーマンスを組み合わせたこの320億パラメータのモデルは、開発者や研究者のニーズに応えています。数学的推論、人間の好みの整合性、視覚タスクにおける進展は、ローカルデプロイメントや実世界のアプリケーションにおける最適な選択肢としています。
教育ツール、ビジネスインテリジェンスシステム、カスタマーサポートソリューションの構築に携わっている場合でも、Qwen2.5-VL-32Bは、必要な多様性と効率を提供します。オープンソースプラットフォームやQwen APIを通じてアクセス可能であるため、このモデルをプロジェクトに統合することはこれまで以上に簡単になっています。Qwenチームが革新を続ける中で、マルチモーダルAIの未来にますますエキサイティングな展開を期待しています。
このAPIツールを使用すると、モデルのエンドポイントを簡単にテストおよびデバッグできます。今日、無料でApidogをダウンロードし、Mistral Small 3.1の機能を探索しながらワークフローを効率化しましょう!