
Alibabaが提供するオープン基盤モデルイニシアチブであるQwenは、迅速な反復とリリースを通じて、常に人工知能の限界を押し広げています。Qwenモデルはしばしば性能と汎用性の新たな標準を確立するため、開発者や研究者は各アップデートを心待ちにしています。最近、Qwenは3つの革新的なモデル、Qwen-Image-Edit-2509、Qwen3-TTS-Flash、Qwen3-Omniを発表しました。これらのリリースは、それぞれ画像編集、テキスト読み上げ合成、オムニモーダル処理の機能を強化します。
さらに、これらのモデルはAI開発の極めて重要な時期に登場しました。この時期には、マルチモーダル統合が実用的なアプリケーションにとって不可欠となります。Qwen-Image-Edit-2509は正確な視覚操作の需要に応え、Qwen3-TTS-Flashは音声生成における遅延の問題に対処します。一方、Qwen3-Omniは多様な入力をまとまりのあるフレームワークに統合します。これらはQwenがアクセス可能で高性能なAIに注力していることを示しています。しかし、その技術的基盤を理解するには、より詳細な検討が必要です。この記事では、各モデルを分析し、その機能、アーキテクチャ、ベンチマーク、および潜在的な影響を強調します。
Qwen-Image-Edit-2509: 画像編集の精度を向上させる
Qwen-Image-Edit-2509は、AI駆動の画像操作における大きな進歩を意味します。Qwenのエンジニアは、視覚コンテンツに対するきめ細かな制御を必要とするクリエイター、デザイナー、開発者に対応するためにこのモデルを再構築しました。以前のイテレーションとは異なり、このバージョンは複数画像編集をサポートしており、ユーザーは人物と製品、またはシーンなどの要素を簡単に組み合わせることができます。その結果、不一致なブレンドなどの一般的なアーティファクトを排除し、一貫性のある出力を生成します。

このモデルは、単一画像の整合性に優れています。ポーズ、スタイル、フィルター全体で顔の識別を維持し、広告やパーソナライゼーションのアプリケーションにとって非常に貴重です。製品画像の場合、Qwen-Image-Edit-2509はオブジェクトの整合性を維持し、編集が主要な属性を歪めないようにします。さらに、テキスト要素を包括的に処理し、コンテンツ、フォント、色、さらにはテクスチャの変更を可能にします。この汎用性は、深度マップ、エッジ検出、キーポイントを組み込んで正確なガイダンスを提供する統合されたControlNetメカニズムに由来します。
技術的には、Qwen-Image-Edit-2509は基盤となるQwen-Imageアーキテクチャに基づいていますが、高度なトレーニング技術を組み込んでいます。開発者は、複数画像の入力を容易にするために、画像連結方法を使用してこれをトレーニングしました。例えば、「人物 + 人物」または「人物 + シーン」を組み合わせることで、連結されたデータストリームを活用し、異なる視覚要素を融合するモデルの能力を向上させます。さらに、このアーキテクチャは、ノイズが徐々に除去されて洗練された画像を生成する拡散ベースのプロセスを統合しています。安定拡散のバリアントで一般的なこのアプローチは、ユーザープロンプトに基づいた条件付き生成を可能にします。
ベンチマークに関して、Qwen-Image-Edit-2509は一貫性指標において優れた性能を示します。内部評価では、顔の保存において競合他社を上回り、多様な編集全体で類似度スコアが95%を超えています。製品の一貫性ベンチマークでは、歪みが最小限であることが明らかになり、eコマースに最適です。しかし、最近のリリースであるため、外部ソースからの定量的データは限られています。それにもかかわらず、Hugging Faceのようなプラットフォームでのユーザーデモンストレーションは、多要素ブレンドにおいてStable Diffusion XLのようなモデルに対する優位性を強調しています。
Qwen-Image-Edit-2509には多くのアプリケーションがあります。マーケターは、製品の配置をシームレスに編集することで、カスタマイズされた広告を作成するためにこれを利用します。デザイナーは、手動でのレタッチなしでシーンを変更する迅速なプロトタイピングにこれを使用します。さらに、ゲームでは動的なアセット生成を促進します。具体的な例として、人物の服装の変換があります。カジュアルな服装の女性の入力画像と黒いドレスの参照画像を組み合わせると、ドレスが自然にフィットし、姿勢と照明を維持した出力が得られます。この機能は、視覚的なデモで示されているように、その実用的な有用性を強調しています。


実装に移ると、開発者はQwen-Image-Edit-2509にGitHubリポジトリとHugging Faceスペースを介してアクセスします。インストールは通常、リポジトリをクローンし、PyTorchのような依存関係を設定することを含みます。基本的な使用スクリプトは次のようになります。
import torch
from qwen_image_edit import QwenImageEdit
model = QwenImageEdit.from_pretrained("Qwen/Qwen-Image-Edit-2509")
input_image = load_image("person.jpg")
reference_image = load_image("dress.jpg")
output = model.edit_multi(input_image, reference_image, prompt="Apply the black dress to the person")
output.save("edited.jpg")
このようなコードは迅速なイテレーションを可能にします。しかし、推論は最適な速度のためにGPUアクセラレーションを必要とするため、ユーザーは計算要件を考慮する必要があります。
その強みにもかかわらず、Qwen-Image-Edit-2509は課題に直面しています。高解像度編集はかなりのメモリを消費する可能性があり、複雑なプロンプトは時折一貫性の欠如につながります。それにもかかわらず、オープンソースチャネルを通じた継続的なコミュニティ貢献がこれらの問題を軽減しています。全体として、このモデルは精度とアクセシビリティを組み合わせることで、画像編集を再定義します。
Qwen3-TTS-Flash: テキスト読み上げ合成を加速する
Qwen3-TTS-Flashは、テキスト読み上げ(TTS)技術の強力な存在として登場し、速度と自然さを優先しています。Qwenのエンジニアは、リアルタイムアプリケーションのボトルネックに対処し、最小限の遅延で人間のような音声を生成するように設計しました。具体的には、シングルスレッド環境でわずか97msの初回パケット遅延を実現し、チャットボットやバーチャルアシスタントでの流動的なインタラクションを可能にします。
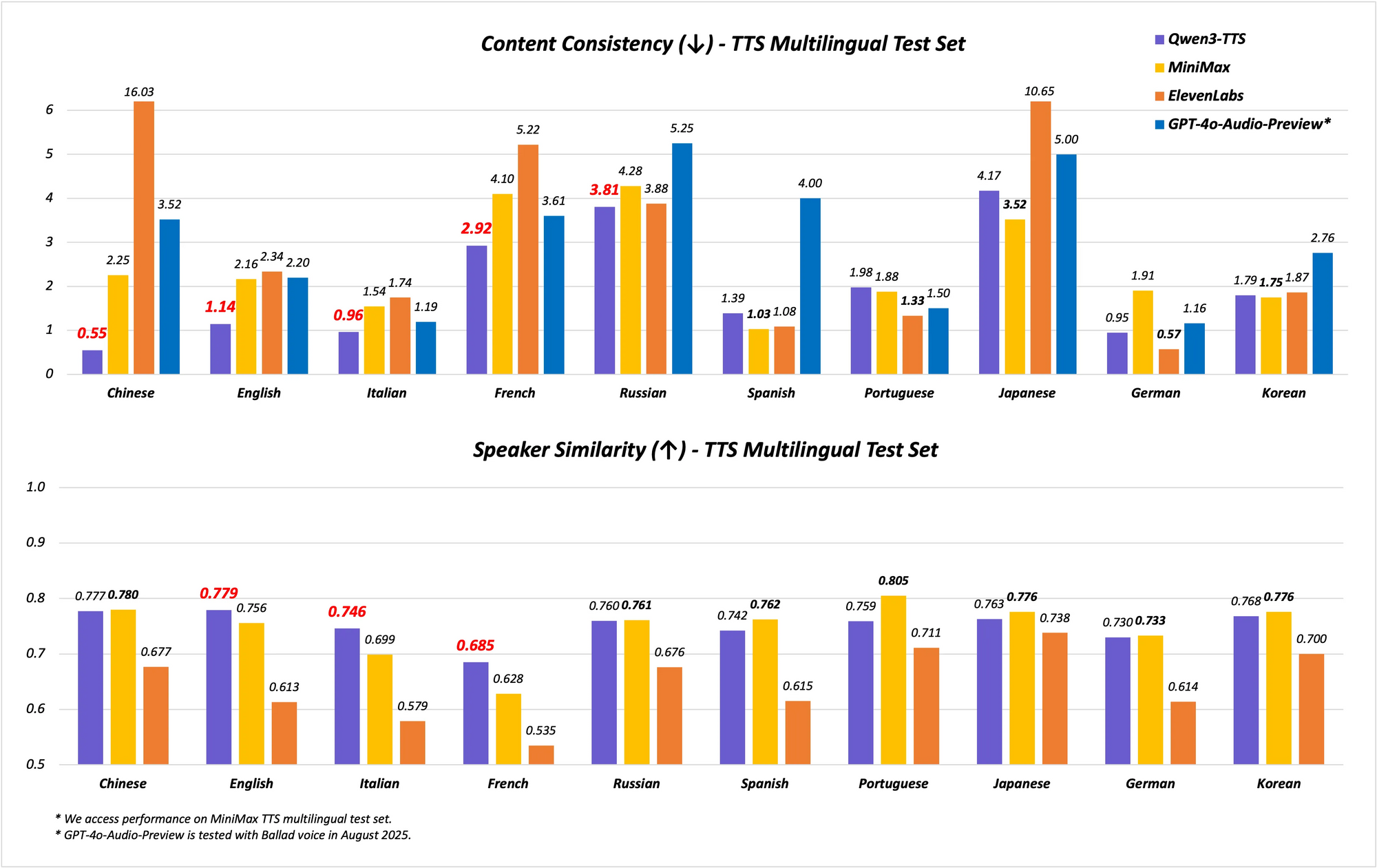
このモデルは、多言語および多方言機能をサポートしており、10言語で17の表現豊かな音声をカバーしています。中国語と英語の安定性に優れており、Seed-TTS-Evalテストセットのようなベンチマークで最先端(SOTA)の性能を達成しています。ここでは、安定性指標においてSeedTTS、MiniMax、GPT-4o-Audio-Previewなどのモデルを上回っています。さらに、MiniMax TTSテストセットでの多言語評価において、Qwen3-TTS-Flashは中国語、英語、イタリア語、フランス語で最低の単語誤り率(WER)を記録しています。
方言サポートがQwen3-TTS-Flashを際立たせています。広東語、福建語、四川語、北京語、南京語、天津語、陝西語を含む9つの中国語方言を処理します。この機能により、多様な市場で不可欠な文化的ニュアンスのあるスピーチが可能になります。さらに、このモデルは大規模なトレーニングデータから学習し、入力された感情に合わせてトーンを自動的に調整します。堅牢なテキスト処理により信頼性がさらに向上し、日付、数字、頭字語などの複雑な形式から重要な情報を抽出します。
アーキテクチャ的には、Qwen3-TTS-Flashは低遅延推論に最適化されたトランスフォーマーベースのエンコーダ・デコーダフレームワークを採用しています。表現力を向上させるため、より豊かな音声モデリングのためにマルチコードブック表現を使用しています。トレーニングには、テキスト用に119言語、音声理解用に19言語を網羅する膨大なデータセットが使用されましたが、出力は10言語に焦点を当てています。この設定により、ある言語での入力が別の言語でシームレスに出力を生成するクロスリンガル生成が可能になります。

ベンチマークはその実力を示しています。安定性テストでは、Qwen3-TTS-FlashはElevenLabsおよびGPT-4oと比較して、音色の類似性と自然さにおいて高いスコアを記録しています。例えば:
| ベンチマーク | Qwen3-TTS-Flash | MiniMax | GPT-4o-Audio-Preview |
|---|---|---|---|
| 中国語の安定性 | SOTA | 低い | 低い |
| 英語のWER | 最低 | 高い | 高い |
| 多言語の音色類似性 | SOTA | 低い | 低い |
これらの結果は厳格な評価に由来しており、TTSのリーダーとしての地位を確立しています。
デモンストレーションでは、Qwen3-TTS-Flashは「ハニーラベンダーラテ」を熱意を込めて説明したり、方言で対話したりするなど、表現豊かな音声を生成します。ビデオのトランスクリプトは、「今日は本当に嬉しい。あの中国出身の女の子を知っているんだ」といった混合言語の入力を、アクセントのある音声で処理する能力を示しています。アプリケーションには、対話型音声応答(IVR)システム、ゲームのNPC、コンテンツ作成などがあり、低遅延により効率が倍増します。
実装には、APIまたはHugging Faceデモを介してモデルにアクセスする必要があります。Python呼び出しの例:
from qwen_tts import QwenTTSFlash
model = QwenTTSFlash.from_pretrained("Qwen/Qwen3-TTS-Flash")
audio = model.synthesize(text="Hello, world!", voice="expressive_english", dialect="sichuanese")
audio.save("output.wav")
この簡潔さが開発を加速します。しかし、方言の精度はまれな入力によって異なる場合があり、ファインチューニングが必要となります。
Qwen3-TTS-Flashは、速度、品質、多様性のバランスをとることでTTSを変革し、現代のAIシステムにとって不可欠なものとなっています。
Qwen3-Omniの紹介:統合されたマルチモーダルの中核
Qwen3-Omniの紹介は、マルチモーダルAIにおける画期的な出来事であり、Qwenがテキスト、画像、音声、ビデオを単一のエンドツーエンドモデルに統合しました。このネイティブな統合により、モダリティ間のトレードオフが回避され、より深いクロスモーダル推論が可能になります。このモデルは、テキスト用に119言語、音声入力用に19言語、音声出力用に10言語を処理し、応答の遅延は驚異的な211msです。
主要な機能には、36の音声および視聴覚ベンチマークのうち22でSOTA性能、カスタマイズ可能なシステムプロンプト、組み込みのツール呼び出し、低幻覚率のオープンソースキャプションモデルが含まれます。Qwenは、指示追従のためのQwen3-Omni-30B-A3B-Instructや、推論強化のためのQwen3-Omni-30B-A3B-Thinkingのようなバリアントをオープンソース化しました。
このアーキテクチャは、Qwen2.5-OmniのThinker-Talkerフレームワークに基づいており、WhisperオーディオエンコーダをAudio Transformer(AuT)に置き換えて表現を向上させるなどのアップグレードが施されています。マルチコードブック音声処理は音声出力を豊かにし、拡張されたコンテキストは30分以上の音声をサポートします。これにより、ビデオ入力が音声応答に影響を与えるフルモダリティ推論が可能になります。
ベンチマークはその優位性を裏付けています。32のベンチマークで全体的にSOTAを達成し、音声理解と生成に優れています。例えば、視聴覚タスクでは、GPT-4oのようなモデルを遅延と精度で上回ります。比較表:
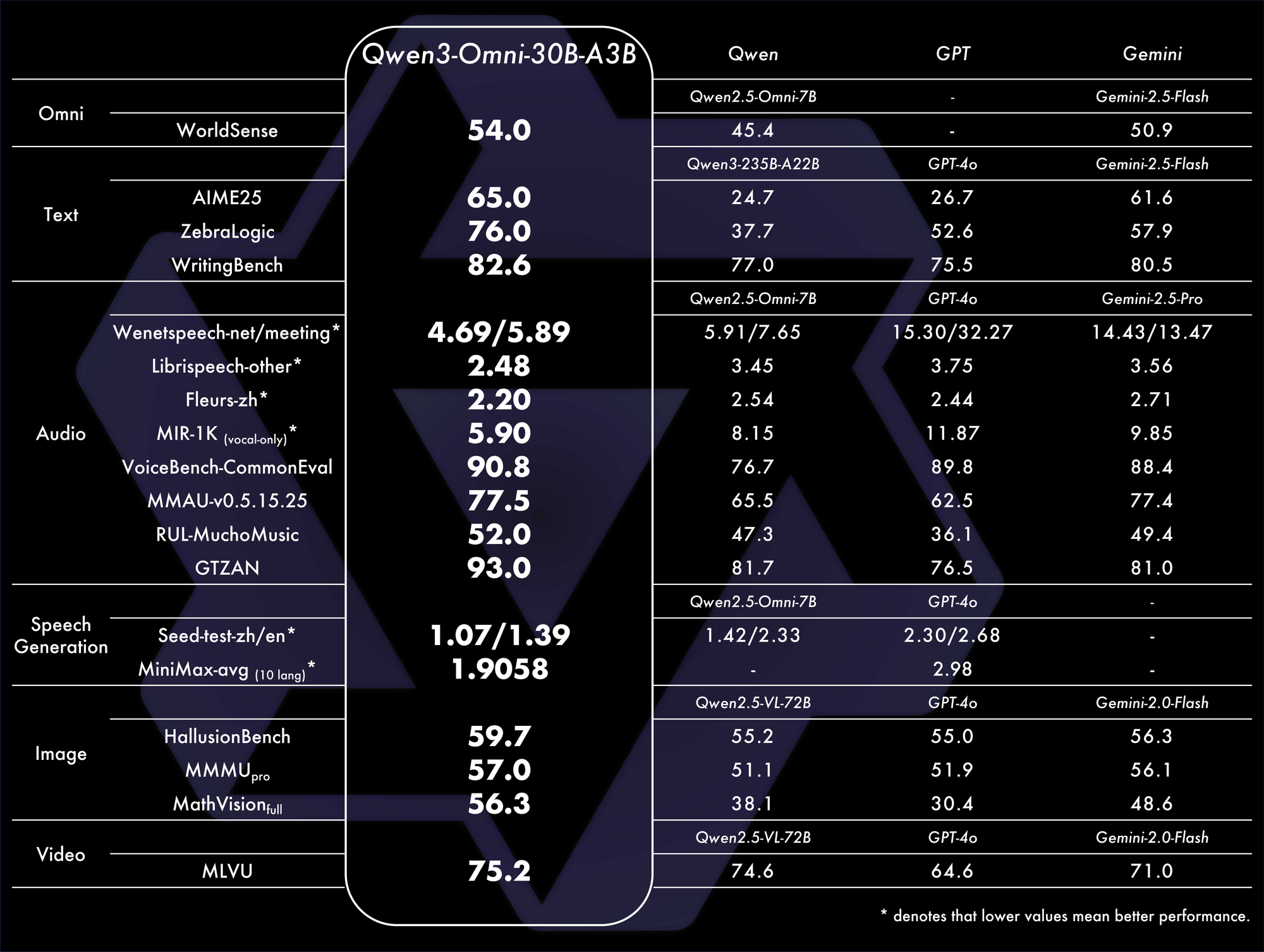
これらの指標は、実際のシナリオにおけるその効率性を強調しています。
アプリケーションは、音声チャット、ビデオ分析、マルチモーダルエージェントにわたります。例えば、ビデオクリップを分析し、音声による要約を生成するため、アクセシビリティツールに最適です。Qwen Chatのデモでは、ユーザーが画像や音声を口頭で問い合わせる音声およびビデオインタラクションが紹介されています。
GitHubのREADMEには、多様な入力からのリアルタイム音声生成が可能であると記載されています。セットアップは次のとおりです。
from qwen_omni import Qwen3Omni
model = Qwen3Omni.from_pretrained("Qwen/Qwen3-Omni-30B-A3B-Instruct")
response = model.process(inputs={"text": "Describe this", "image": "img.jpg", "audio": "clip.wav"})
print(response.text)
response.audio.save("reply.wav")
このモジュール化されたアプローチは、カスタマイズを容易にします。課題には、ビデオ処理に対する高い計算要件が含まれますが、量子化などの最適化が役立ちます。
Qwen3-Omniの導入は、モダリティを統合し、革新的なAIエコシステムを育成します。
Qwenの新しいモデル間の相乗効果と将来の示唆
Qwen-Image-Edit-2509、Qwen3-TTS-Flash、Qwen3-Omniは互いに補完し合い、エンドツーエンドのワークフローを可能にします。例えば、Qwen-Image-Edit-2509で画像を編集し、Qwen3-Omniを介してそれを記述し、Qwen3-TTS-Flashで出力を音声化することができます。この統合は、コンテンツ作成と自動化における有用性を高めます。
さらに、そのオープンソースの性質はコミュニティによる機能強化を促します。Apidogを使用する開発者は、APIを効率的にテストし、堅牢な統合を保証できます。
しかし、ディープフェイクでの悪用など、倫理的な問題が生じます。Qwenは、セーフガードを通じてこれを軽減します。
結論として、QwenのリリースはAIの展望を再定義します。技術的なフロンティアを進歩させることで、ユーザーはより多くのことを達成できるようになります。採用が進むにつれて、これらのモデルは次のイノベーションの波を牽引するでしょう。