
Qwen-Imageは、Alibaba CloudのQwenチームが開発した最先端の20B MMDiT画像基盤モデルであり、AI駆動のビジュアル作成の可能性を再定義します。2025年8月4日にリリースされたこのモデルは、高品質な画像の生成、複雑な多言語テキストのレンダリング、正確な画像編集において比類のない機能を提供します。ダイナミックなマーケティングビジュアルを作成する場合でも、複雑な画像データを分析する場合でも、Qwen-Imageは開発者がアイデアを具現化するための堅牢なツールを提供します。
Qwen-Imageとは?技術的概要
Qwen-Imageは、Alibaba CloudのQwenシリーズの一部であり、画像生成と編集の両方のために設計された200億パラメータを持つマルチモーダル拡散トランスフォーマー(MMDiT)モデルです。視覚的な生成のみに焦点を当てた従来のモデルとは異なり、Qwen-Imageは高度なテキストレンダリングと画像理解を統合しており、創造的および分析的タスクのための多用途ツールとなっています。Apache 2.0ライセンスの下でオープンソース化されたこのモデルは、GitHub、Hugging Face、ModelScopeなどのプラットフォームからアクセスでき、開発者は多様なワークフローに統合できます。

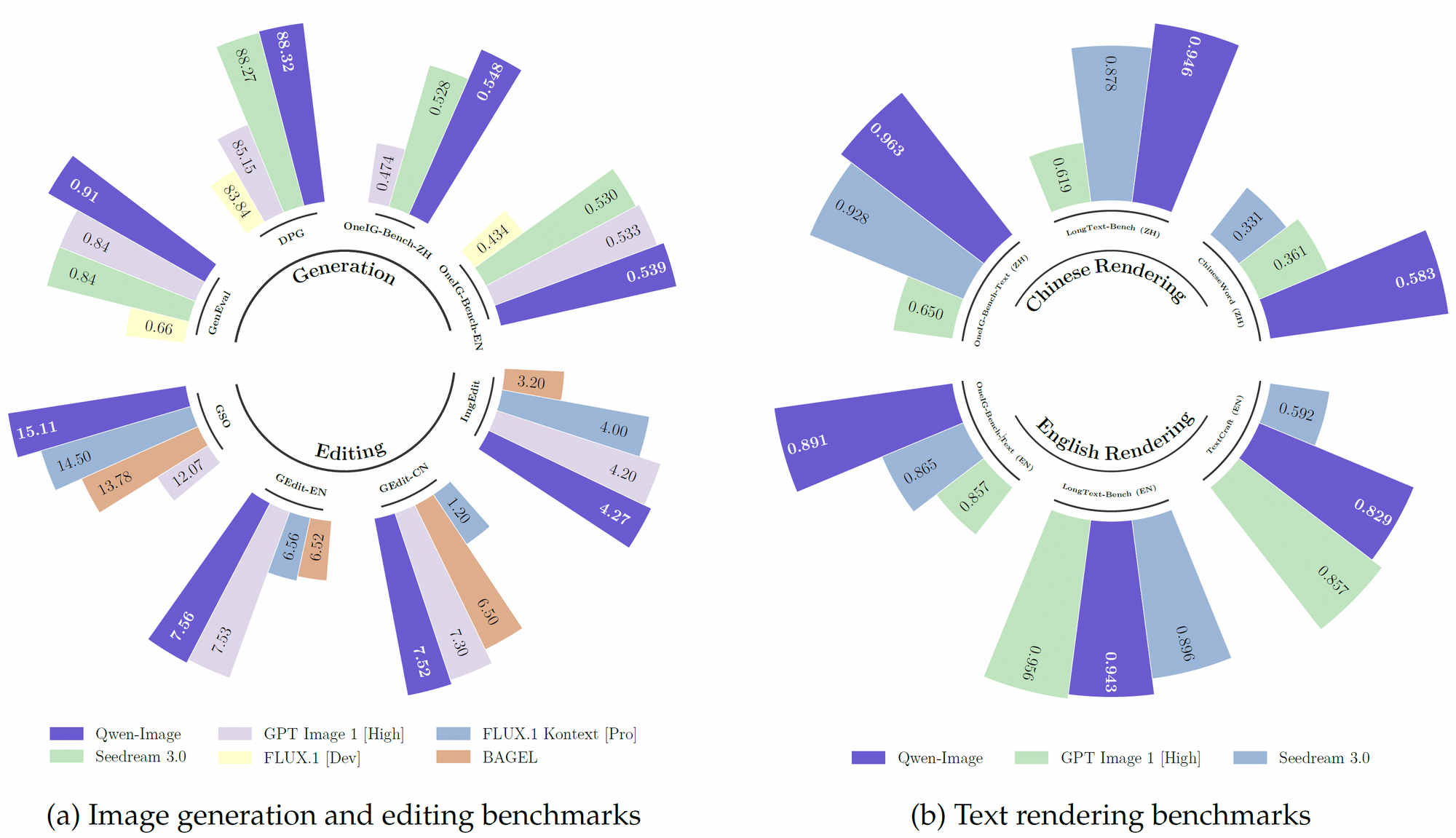
さらに、Qwen-Imageは、中国語と英語を中心に、119の言語にわたる30兆以上のトークンを組み込んだ堅牢な事前学習データセットを活用しています。この広範なデータセットは、強化学習技術と組み合わされることで、多言語テキストレンダリングや正確なオブジェクト操作などの複雑なタスクを処理することを可能にします。その結果、GenEval、DPG、LongText-Benchなどのベンチマークで多くの既存モデルを上回る性能を発揮します。
Qwen-Imageの主要機能
多言語ビジュアルのための優れたテキストレンダリング
Qwen-Imageは、画像内の複雑なテキストのレンダリングに優れており、競合他社とは一線を画しています。アルファベット言語(例:英語)と表意文字スクリプト(例:中国語)の両方をサポートし、高忠実度のテキスト統合を保証します。例えば、このモデルは、「Imagination Unleashed」のようなタイトルや複数の行のサブタイトルなど、正確なテキストレイアウトで映画のポスターを生成し、タイポグラフィの一貫性を維持できます。この機能は、LongText-BenchやChineseWordなどの多様なデータセットでのトレーニングに由来しており、そこで最先端のパフォーマンスを達成しています。
さらに、Qwen-Imageは、複数行のレイアウトと段落レベルのセマンティクスを驚くべき精度で処理します。テストシナリオでは、画像内の黄ばんだ紙に手書きの詩が、テキストが視覚空間の10分の1未満を占めているにもかかわらず、正確にレンダリングされました。この精度により、デジタルサイネージ、ポスターデザイン、ドキュメントの視覚化などのアプリケーションに最適です。
高度な画像編集機能
テキストレンダリングに加えて、Qwen-Imageは高度な画像編集機能を提供します。スタイル転送、オブジェクト挿入、詳細強化、人間のポーズ操作などの操作をサポートしています。例えば、ユーザーはモデルに「この画像に晴れた空を追加して」とか「この絵をゴッホ風に変えて」と指示することができ、Qwen-Imageは一貫性のある結果を提供します。強化されたマルチタスクトレーニングパラダイムにより、編集が意味的意味と視覚的リアリズムを維持することが保証されます。
さらに、画像内のテキストを編集するモデルの機能は特に注目に値します。開発者は、周囲の視覚的コンテキストを損なうことなく、看板やポスターのテキストを変更できます。これは、広告やコンテンツ作成に役立つ機能です。これらの機能は、Qwen-Imageの深い視覚理解によってサポートされており、画像要素を正確に解釈および操作できます。
包括的な視覚理解
Qwen-Imageは、単に作成したり編集したりするだけでなく、理解します。このモデルは、オブジェクト検出、セマンティックセグメンテーション、深度推定、エッジ検出(Canny)、新規ビュー合成、超解像度など、一連の画像理解タスクをサポートしています。これらのタスクは、高解像度入力を処理し、きめ細かい詳細を抽出する機能によって強化されています。例えば、Qwen-Imageは、「地下鉄のシーンでハスキー犬を検出する」など、自然言語で記述されたオブジェクトのバウンディングボックスを生成でき、視覚分析のための強力なツールとなります。
さらに、多言語サポートにより、グローバルなアプリケーションでの使いやすさが向上します。Qwen-Plus Prompt Enhancement Toolなどのツールと統合することで、開発者はより良い多言語パフォーマンスのためにプロンプトを最適化し、多様な言語コンテキストで正確な結果を保証できます。
クロスベンチマーク性能の優位性
Qwen-Imageは、GenEval、DPG、OneIG-Bench、GEdit、ImgEdit、GSOなど、複数の公開ベンチマークで競合他社を常に上回っています。特に中国語のテキストレンダリングにおけるその優れた性能は、TextCraftのようなベンチマークで顕著であり、既存の最先端モデルを凌駕しています。さらに、その一般的な画像生成機能は、フォトリアリスティックなシーンからアニメの美学まで、幅広い芸術スタイルをサポートしており、クリエイティブなプロフェッショナルにとって多用途な選択肢となっています。
Qwen-Imageの技術アーキテクチャ
マルチモーダル拡散トランスフォーマー(MMDiT)
Qwen-Imageは、その核となる部分で、拡散モデルとトランスフォーマーの強みを組み合わせたマルチモーダル拡散トランスフォーマー(MMDiT)アーキテクチャを採用しています。このハイブリッドアプローチにより、モデルは視覚入力とテキスト入力の両方を効率的に処理できます。拡散プロセスは、ノイズの多い入力を一貫性のある画像に繰り返し洗練し、トランスフォーマーコンポーネントはテキストと視覚要素間の複雑な関係を処理します。
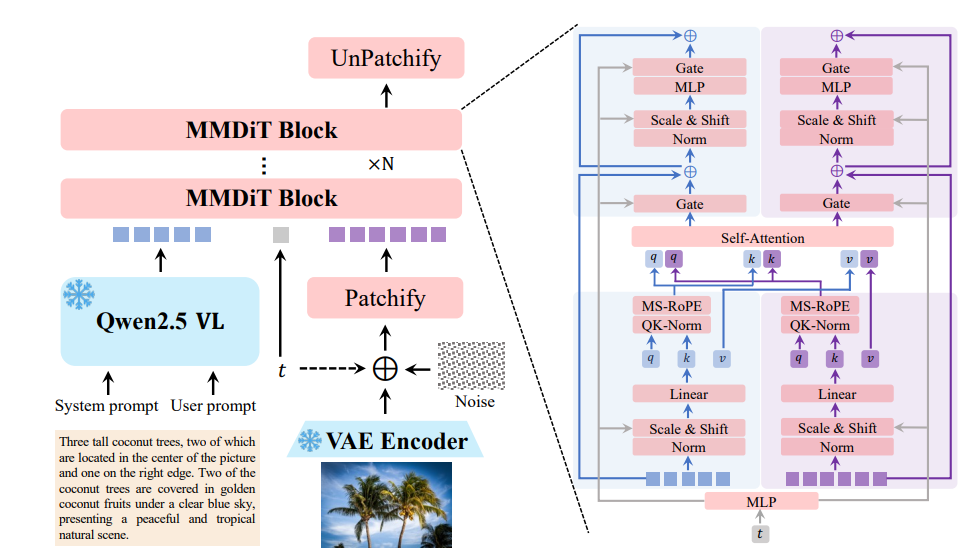
モデルの200億のパラメータは効率のために最適化されており、FP8量子化やレイヤーごとのオフロードなどの技術を使用すると、わずか4GBのVRAMで消費者向けハードウェアでも実行できます。このアクセシビリティにより、Qwen-Imageは企業開発者と個人開発者の両方に適しています。
事前学習とファインチューニング
Qwen-Imageの事前学習データセットは、そのパフォーマンスの礎石です。30兆以上のトークンに及ぶこのデータセットには、ウェブデータ、PDFのようなドキュメント、Qwen2.5-VLやQwen2.5-Coderなどのモデルによって生成された合成データが含まれています。事前学習プロセスは3つの段階で行われます。

- ステージ1(S1):モデルは、4Kトークンのコンテキスト長を持つ30兆トークンで事前学習され、基本的な言語と視覚スキルを確立します。
- ステージ2:強化学習により、モデルの推論能力とタスク固有の能力が向上します。
- ステージ3:厳選されたデータセットによるファインチューニングにより、ユーザーの好みやテキストレンダリング、画像編集などの特定のタスクとの整合性が向上します。
この多段階アプローチにより、Qwen-Imageは堅牢で適応性があり、高精度で多様なタスクを処理できます。
開発ツールとの統合
Qwen-Imageは、DiffusersやDiffSynth-Studioなどの人気のある開発フレームワークとシームレスに統合します。例えば、開発者は次のPythonコードを使用してQwen-Imageで画像を生成できます。
from diffusers import DiffusionPipeline
import torch
model_name = "Qwen/Qwen-Image"
torch_dtype = torch.bfloat16 if torch.cuda.is_available() else torch.float32
device = "cuda" if torch.cuda.is_available() else "cpu"
pipe = DiffusionPipeline.from_pretrained(model_name, torch_dtype=torch_dtype)
pipe = pipe.to(device)
prompt = "A coffee shop entrance with a chalkboard sign reading 'Qwen Coffee 😊 $2 per cup.'"
image = pipe(prompt).images[0]
image.save("qwen_coffee.png")
このコードスニペットは、開発者が最小限のセットアップでQwen-Imageの機能を活用して高品質のビジュアルを生成する方法を示しています。Apidogのようなツールは、API統合をさらに簡素化し、迅速なプロトタイピングとデプロイを可能にします。
Qwen-Imageの実用的なアプリケーション
クリエイティブコンテンツ生成
Qwen-Imageは、フォトリアリスティックなシーン、印象派の絵画、アニメスタイルのビジュアルを生成する能力により、アーティストやデザイナーにとって強力なツールとなります。例えば、グラフィックデザイナーは、Qwen-Imageが「Imagination Unleashed」のポスターを、未来的なコンピューターが奇妙な生き物を放出する様子で生成したテストケースで示されているように、ダイナミックなテキストレイアウトと鮮やかな画像で映画のポスターを作成できます。

広告とマーケティング
広告では、Qwen-Imageのテキストレンダリングと編集機能により、視覚的に魅力的なキャンペーンを作成できます。マーケターは、正確なテキスト配置でポスターを生成したり、既存のビジュアルを編集してプロモーションメッセージを更新したりして、ブランドの一貫性と視覚的整合性を確保できます。

視覚分析と自動化
Eコマースや自律システムなどの産業にとって、Qwen-Imageの画像理解タスク(オブジェクト検出やセマンティックセグメンテーションなど)は大きな価値を提供します。小売プラットフォームは、このモデルを使用して画像内の製品を自動的にタグ付けでき、自律走行車は、ナビゲーションのためにその深度推定を活用できます。
教育ツール
Qwen-Imageは、正確なテキスト注釈付きの図などの教育用ビジュアルを生成する能力により、eラーニングプラットフォームをサポートします。例えば、ラベル付きのコンポーネントを持つ科学的概念の詳細なイラストを作成でき、学生の関心と理解を深めることができます。

Qwen-Imageと競合他社の比較
DALL-E 3やStable Diffusionなどのモデルと比較すると、Qwen-Imageは多言語テキストレンダリングと高度な編集機能で際立っています。DALL-E 3はクリエイティブな画像生成に優れていますが、特に表意文字スクリプトの複雑なテキストレイアウトには苦戦します。Stable Diffusionは多用途ですが、Qwen-Imageが提供する一連の理解タスクによる深い視覚理解には欠けています。
さらに、Qwen-Imageのオープンソースの性質と低メモリハードウェアとの互換性は、リソースが限られている開発者にとって有利です。TextCraftやGEditなどのベンチマークでのそのパフォーマンスは、マルチモーダルAIにおける主要モデルとしての地位をさらに確固たるものにしています。
課題と制限
Qwen-Imageは、その強みにもかかわらず、課題に直面しています。モデルが大規模なデータセットに依存していることは、データプライバシーと倫理的なデータソースに関する懸念を引き起こしますが、Alibaba Cloudは厳格なガイドラインを遵守しています。さらに、このモデルは100以上の言語をサポートしていますが、表現の少ない方言ではパフォーマンスが異なる場合があり、さらなるファインチューニングが必要です。
さらに、200億パラメータモデルの計算要件は、FP8量子化のような最適化技術なしではかなりのものになる可能性があります。開発者は、Qwen-Imageを本番環境にデプロイする際に、パフォーマンスとリソースの制約のバランスを取る必要があります。
Qwen-Imageの将来展望
今後、Qwen-Imageはさらに進化する予定です。Qwenチームは、プロフェッショナルグレードのアプリケーション向けに機能を強化した、編集に特化したバージョンのモデルをリリースする計画です。vLLMのような新しいフレームワークとの統合、およびLoRAとファインチューニングワークフローの継続的なサポートにより、そのアクセシビリティが拡大されます。
さらに、Qwen3のようなモデルに見られる強化学習の進歩は、Qwen-Imageがより深い推論能力を組み込む可能性を示唆しており、より複雑な視覚推論タスクを可能にします。AIコミュニティがその開発に貢献し続けるにつれて、Qwen-Imageは視覚的な作成と理解を再定義する可能性を秘めています。
Qwen-Imageの利用開始
Qwen-Imageの使用を開始するには、開発者はGitHubまたはHugging Faceでモデルの重みにアクセスできます。qwenlm.github.ioの公式ブログでは、詳細なセットアップ手順と使用例が提供されています。実践的な体験をするには、Qwen Chatにアクセスし、「Image Generation」を選択してモデルの機能をテストしてください。
API統合については、Apidogのようなツールが、Qwen-Imageの機能をテストおよびデプロイするためのユーザーフレンドリーなインターフェースを提供することでプロセスを簡素化します。開発ワークフローを効率化するために、Apidogを無料でダウンロードしてください。
結論:Qwen-Imageが重要な理由
Qwen-Imageは、高度なテキストレンダリング、正確な画像編集、堅牢な視覚理解を組み合わせた、マルチモーダルAIにおける重要な進歩を表しています。そのオープンソースの利用可能性、広範な事前学習、および開発ツールとの互換性により、クリエイター、開発者、研究者にとって多用途な選択肢となっています。多言語サポートやリソース効率などの課題に対処することで、Qwen-ImageはAI駆動の視覚作成の新しい標準を設定します。
AIが進化し続けるにつれて、Qwen-Imageのようなモデルは、言語とイメージの間のギャップを埋める上で極めて重要な役割を果たし、創造的および分析的アプリケーションの新しい可能性を切り開くでしょう。マーケティングキャンペーンを構築している場合でも、視覚データを分析している場合でも、教育コンテンツを作成している場合でも、Qwen-Imageはあなたのビジョンを実現するためのツールを提供します。


