
急速に進化する人工知能の世界で、Qwen 2.5 Omni 7Bのリリースにより新たなマイルストーンが到達しました。このAlibaba Cloudの革命的なモデルは、複数の形式の入力を処理し理解しながら、テキストと音声の出力を生成するマルチモーダルAIにおいて重要な飛躍を表しています。このモデルが本当に特別であり、AIの能力に対する私たちの理解をどのように再形成しているのかを探ってみましょう。
Qwen 2.5 Omni 7Bにおける「Omni」の真の意味
Qwen 2.5 Omni 7Bにおける「Omni」という用語は、単なる巧妙なブランディングではなく、モデルの能力を根本的に説明しています。一部のモーダルモデルが1つまたは2つのデータタイプで優れているのとは異なり、Qwen 2.5 Omni 7Bは、以下のことを認識して理解するためにゼロから設計されています:
- テキスト(書かれた言語)
- 画像(視覚情報)
- 音声(音や話し言葉)
- 動画(時間的次元を持つ動く視覚コンテンツ)
音声チャット + ビデオチャット!ちょうどQwenチャットで(https://t.co/FmQ0B9tiE7)!今、電話をかけるようにQwenとチャットできる!デモをhttps://t.co/42iDe4j1Hsで確認してください。
— Qwen (@Alibaba_Qwen) 2025年3月26日
さらに、私たちはすべての背後にあるモデル、Qwen2.5-Omni-7Bをオープンソースにしました… pic.twitter.com/LHQOQrl9Ha
さらに印象的なのは、このモデルがこれらの多様な入力を受け取るだけでなく、ストリーミング方式でテキストと自然言語で応答できることです。この「任意から任意」機能は、より自然で人間らしいAIとの対話に向けた大きな進展を表しています。
Qwen 2.5 Omni 7Bの革新なアーキテクチャ:解説
Thinker-Talker:新しいパラダイム
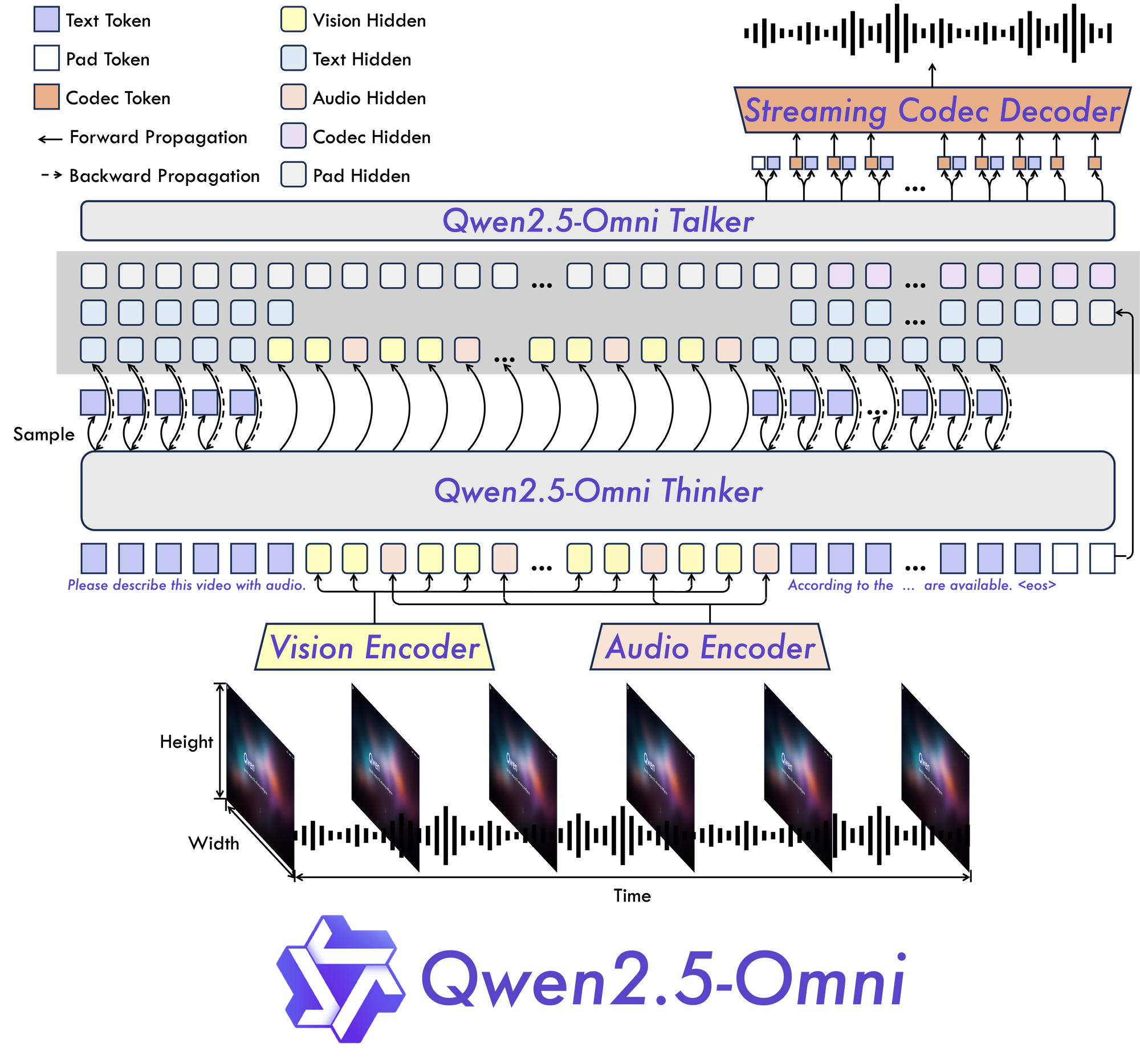
Qwen 2.5 Omni 7Bの核心には、その基盤となる「Thinker-Talker」アーキテクチャがあります。この新しい設計は、情報処理を思考(考えること)から出力生成(話すこと)に切り離すことで、マルチモーダルデータの固有の複雑さを効果的に管理し、複数の形式で適切な応答を生成できるモデルを特別に構築しています。
TMRoPE:時間的整合性の課題を解決する
Qwen 2.5 Omni 7Bの最も重要な革新の1つは、その時間整合性マルチモーダルRoPE(TMRoPE)メカニズムです。このブレークスルーは、異なるソースからの時間的データを同期させるという、マルチモーダルAIの最も挑戦的な側面の1つに取り組んでいます。
動画と音声を同時に処理する場合、モデルは視覚的イベントが対応する音やスピーチとどのように整合するかを理解する必要があります。例えば、人の口の動きをその発話と一致させるには、正確な時間の整合が必要です。TMRoPEはこの同期を実現するための高度なフレームワークを提供し、モデルが時間を超えて展開するマルチモーダル入力を一貫して理解できるようにします。
リアルタイムインタラクションのために設計された
Qwen 2.5 Omni 7Bは、リアルタイムアプリケーションを念頭に置いて構築されています。このアーキテクチャは低遅延ストリーミングをサポートしており、チャンク化された入力処理と即時出力生成を可能にします。これにより、音声アシスタント、ライブ動画分析、またはリアルタイム翻訳サービスなど、応答性の高いインタラクションが要求されるアプリケーションに最適です。
Qwen 2.5 Omni 7Bのパフォーマンス:ベンチマークが物語る
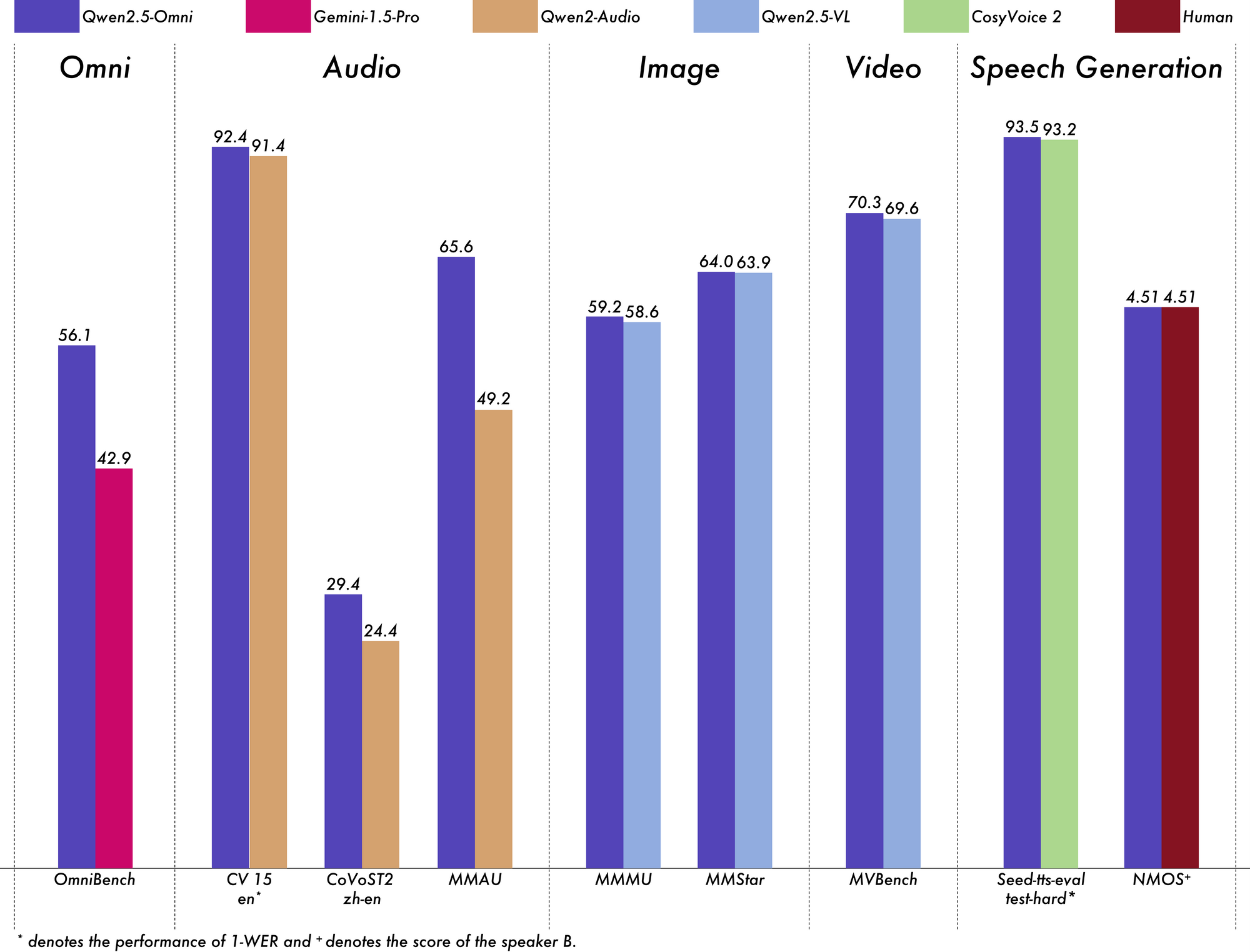
AIモデルの真のテストは、厳格なベンチマークにおけるパフォーマンスであり、Qwen 2.5 Omni 7Bは全体的に印象的な結果を提供します。
マルチモーダル理解でのリーディング
一般的なマルチモーダル理解のためのOmniBenchベンチマークでは、Qwen 2.5 Omni 7Bは平均スコア56.13%を達成しています。これは、Gemini-1.5-Pro(42.91%)やMIO-Instruct(33.80%)の他のモデルを大きく上回ります。特定のOmniBenchカテゴリでのその優れたパフォーマンスは特に注目に値します:
- 音声タスク:55.25%
- サウンドイベントタスク:60.00%
- 音楽タスク:52.83%
この包括的なパフォーマンスは、モデルが複数のモーダルを効果的に統合し、推論する能力を示しています。
音声処理での優れた成果
音声からテキストのタスクにおいて、Qwen 2.5 Omni 7Bは自動音声認識(ASR)でほぼ最先端の結果を示しています。Librispeechデータセットで、ワードエラーレート(WER)が1.6%から3.5%の範囲に達し、Whisper-large-v3のような専門モデルと同等です。
Meldデータセットにおける音声イベント認識では、スコア0.570で業界トップクラスのパフォーマンスを達成しています。モデルは音楽理解でも優れた成果を上げており、GiantSteps Tempoベンチマークで0.88のスコアを得ています。
強力な画像理解
画像からテキストのタスクにおいて、Qwen 2.5 Omni 7BはMMMUベンチマークで59.2のスコアを達成し、GPT-4o-miniの60.0に非常に近い結果を出しています。RefCOCO Groundingタスクでは90.5%の精度を達成し、Gemini 1.5 Proの73.2%を上回っています。
印象的な動画理解
字幕なしの動画からテキストへのタスクでは、モデルはVideo-MMEで64.3のスコアを獲得し、専門的な動画モデルのパフォーマンスにほぼ匹敵しています。字幕を追加すると、パフォーマンスが72.4に跳ね上がり、モデルが複数の情報源を効果的に統合する能力を示しています。
自然な音声生成
Qwen 2.5 Omni 7Bは、単に理解するだけでなく、話します。音声生成において、スピーカーの類似スコアは0.754から0.752の範囲にあり、Seed-TTS_RLのような専用のテキストから音声へのモデルと同等です。これは、元のスピーカーの声の特徴を保持しながら自然な音声を生成する能力を示しています。
強力なテキスト能力の維持
そのマルチモーダルな焦点にもかかわらず、Qwen 2.5 Omni 7Bはテキスト専用のタスクでも見事な結果を出しています。数学的推論(GSM8Kスコア:88.7%)やコード生成で強力な結果を達成しました。テキスト専用のQwen2.5-7Bモデル(GSM8Kで91.6%を獲得)に比べて若干のトレードオフがあるものの、このわずかな低下は包括的なマルチモーダル能力を得るための合理的な妥協と言えます。
Qwen 2.5 Omni 7Bの実世界での応用:
Qwen 2.5 Omniはすごい!
— Jeff Boudier 🤗 (@jeffboudier) 2025年3月26日
7Bモデルが
テキスト、画像、音声、動画を入力として受け取り
テキストと音声を出力として返し
これほどよく機能するとは信じられません!
オープンソースのApache 2.0
下のリンクでお試しください!
あなたは本当に素晴らしい仕事をしました @Alibaba_Qwen ! pic.twitter.com/pn0dnwOqjY
Qwen 2.5 Omni 7Bの多才さは、さまざまな分野での実践的な応用を広げます。
強化されたコミュニケーションインターフェース
その低遅延ストリーミング機能により、リアルタイムの音声およびビデオチャットアプリケーションに最適です。見る、聞く、話すことができるバーチャルアシスタントを想像してみてください。彼らは言語的および非言語的コミュニケーションのサインを理解し、自然な音声で応答します。
進んだコンテンツ分析
モデルの多様なモーダルを処理し理解する能力は、包括的なコンテンツ分析のための強力なツールとして位置づけられています。テキスト、画像、音声、動画から同時に重要な情報を自動的に特定できます。
アクセス可能な音声インターフェース
エンドツーエンドの音声指示における強力なパフォーマンスにより、Qwen 2.5 Omni 7Bはテクノロジーとのより自然で真のハンズフリーインタラクションを可能にします。これは、障害のあるユーザーやハンズフリー操作が必要な状況において、アクセシビリティ機能を革命的に変えることができます。
クリエイティブなコンテンツ生成
テキストと自然な音声の両方を生成できるモデルの能力は、コンテンツ創出の新しい可能性を開きます。動画のナレーションを自動生成することから、学生の質問に対して適切な説明を返すインタラクティブな教育教材を作成することまで、応用は無限大です。
マルチモーダルカスタマーサービス
企業はQwen 2.5 Omni 7Bを導入して、音声通話、ビデオチャット、書かれたメッセージなどの複数のチャネルから顧客の問い合わせを分析し、自然で適切に応答できるカスタマーサービスシステムを構築することができます。
実用的な考慮事項と制限
Qwen 2.5 Omni 7BはマルチモーダルAIにおける重要な進展を示していますが、これを扱う際にはいくつかの実用的な考慮事項を留意する必要があります。
ハードウェア要件
モデルの包括的な機能は、相当な計算要求を伴います。FP32の精度で比較的短い15秒の動画を処理するには、約93.56GBのGPUメモリが必要です。BF16の精度でも、60秒の動画には約60.19GBが必要です。
これらの要件は高性能のハードウェアにアクセスできないユーザーのアクセスを制限する可能性があります。ただし、このモデルは、互換性のあるハードウェアでのパフォーマンスを向上させるためのFlash Attention 2など、さまざまな最適化をサポートしています。
音声タイプのカスタマイズ
興味深いことに、Qwen 2.5 Omni 7Bは音声出力用に複数の音声タイプをサポートしています。現在、以下の2つの音声オプションがあります:
- チェルシー:ハニード(甘美)、ベルベットのような女性の声で「穏やかな温かみと明るい明瞭さ」との評価
- イーサン:明るく元気な男性の声で「感染力のあるエネルギーと温かく親しみやすい雰囲気」との評価
このカスタマイズは、モデルの実用的な応用における柔軟性に新たな次元を追加します。
技術的統合の考慮事項
Qwen 2.5 Omni 7Bを実装する際には、いくつかの技術的詳細に注意を払う必要があります:
- モデルは、音声出力に特定のプロンプティングパターンが必要です。
- 適切なマルチラウンド会話のためには、
use_audio_in_videoパラメータの一貫した設定が必要です。 - ビデオURLの互換性は特定のライブラリバージョンに依存します(HTTPSサポートのためのtorchvision ≥ 0.19.0)。
- モデルは、現在「任意から任意」モデルのサポートの制限によりHugging Face Inference APIを通じて利用できません。
マルチモーダルAIの未来
Qwen 2.5 Omni 7Bは、単なるAIモデル以上のものを表しています—それは人工知能の未来への一瞥です。複数の感覚モーダルを統一されたエンドツーエンドのアーキテクチャに統合することにより、私たちを人間と同様に世界を認識し、相互作用できるAIシステムに近づけています。
TMRoPEによる時間的整合性の統合は、マルチモーダル処理での根本的な課題を解決し、Thinker-Talkerアーキテクチャは多様な入力を効果的に結合し、適切な出力を生成するためのフレームワークを提供します。ベンチマーク全体での強力なパフォーマンスは、統一されたマルチモーダルモデルが特殊な単一モーダリティモデルに対抗できること、時にはそれを上回ることを示しています。
計算資源がよりアクセス可能になり、効率的なモデル展開の手法が向上するにつれて、Qwen 2.5 Omni 7Bのような真のマルチモーダルAIのより広範な採用が進むことが予想されます。その応用範囲は、ヘルスケアや教育からエンターテイメント、カスタマーサービスに至るまでほぼすべての業界にわたります。
結論
Qwen 2.5 Omni 7Bは、マルチモーダルAIの進化における顕著な成果です。その包括的な「Omni」能力、革新的なアーキテクチャ、印象的な跨モーダルパフォーマンスは、次世代の人工知能システムのリーディングエンジンとしての地位を確立しています。
見る、聞く、読む、話す能力を持つ単一の統一モデルを組み合わせることで、Qwen 2.5 Omni 7Bは異なるAI能力の間の伝統的な障壁を打破します。これは、人間と相互作用し、世界をより自然で直感的な方法で理解するAIシステムの創造へ向けた重要なステップを表しています。
ハードウェア要件に関する実用的な制限はありますが、モデルの成果は、私たちが住む豊かでマルチモーダルな世界をシームレスに処理し、応答できる未来を示唆しています。これらの技術が進化し、よりアクセス可能になるにつれて、私たちは無数のアプリケーションやドメインでテクノロジーとのインタラクションが変革されるのを期待できます。
Qwen 2.5 Omni 7Bは、単なる技術的成果ではなく、異なるコミュニケーション形式の境界が溶解し始める未来への一瞥です。人間とAIがより自然で直感的に相互作用できる方法を創出します。