
開発者は、AI駆動型アプリケーションにリアルタイムのウェブ検索機能を組み込むための堅牢なツールをますます求めています。Perplexity Search APIは、高い精度と速度で広範なウェブコンテンツのインデックスへのアクセスを提供する強力なソリューションとして際立っています。このAPIにより、主要な回答エンジンに匹敵する検索機能をシームレスに統合でき、複雑なインフラストラクチャを管理することなく洗練されたシステムを構築できます。
さらに、Perplexity Search APIを理解するには、認証から高度なクエリまで、そのコアコンポーネントを把握する必要があります。エンジニアは、関連性と効率性を優先するそのAIファーストな設計を高く評価しています。したがって、このガイドでは、公式ドキュメントと技術的洞察に基づいて、段階的なアプローチを提供します。効果的に実装するための詳細な説明、コードスニペット、実用的なヒントが見つかるでしょう。ただし、進む前に、APIの進化を考慮してください。インターネット規模の知識へのアクセスを民主化するために立ち上げられたこのAPIは、AI互換性に焦点を当てることで、従来の検索APIのギャップを埋めています。
Perplexity Search APIとは?
Perplexity Search APIは、生のウェブ検索結果を提供し、開発者が意味理解と語彙マッチングを組み合わせたハイブリッド検索を実行できるようにします。数百億のウェブページを含むインデックスにアクセスし、毎秒数万件の更新を処理して鮮度を確保します。従来の検索ツールとは異なり、このAPIはAIワークロードを重視し、個別にスコア付けされたドキュメント単位を含む構造化された応答を提供することで、正確なスニペットランキングを実現します。
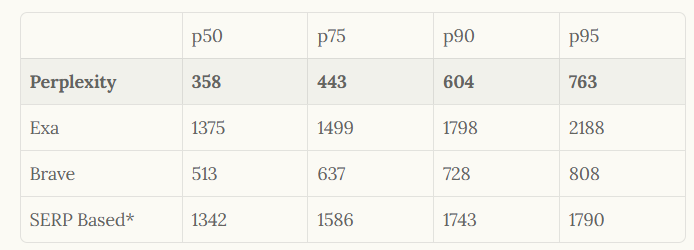
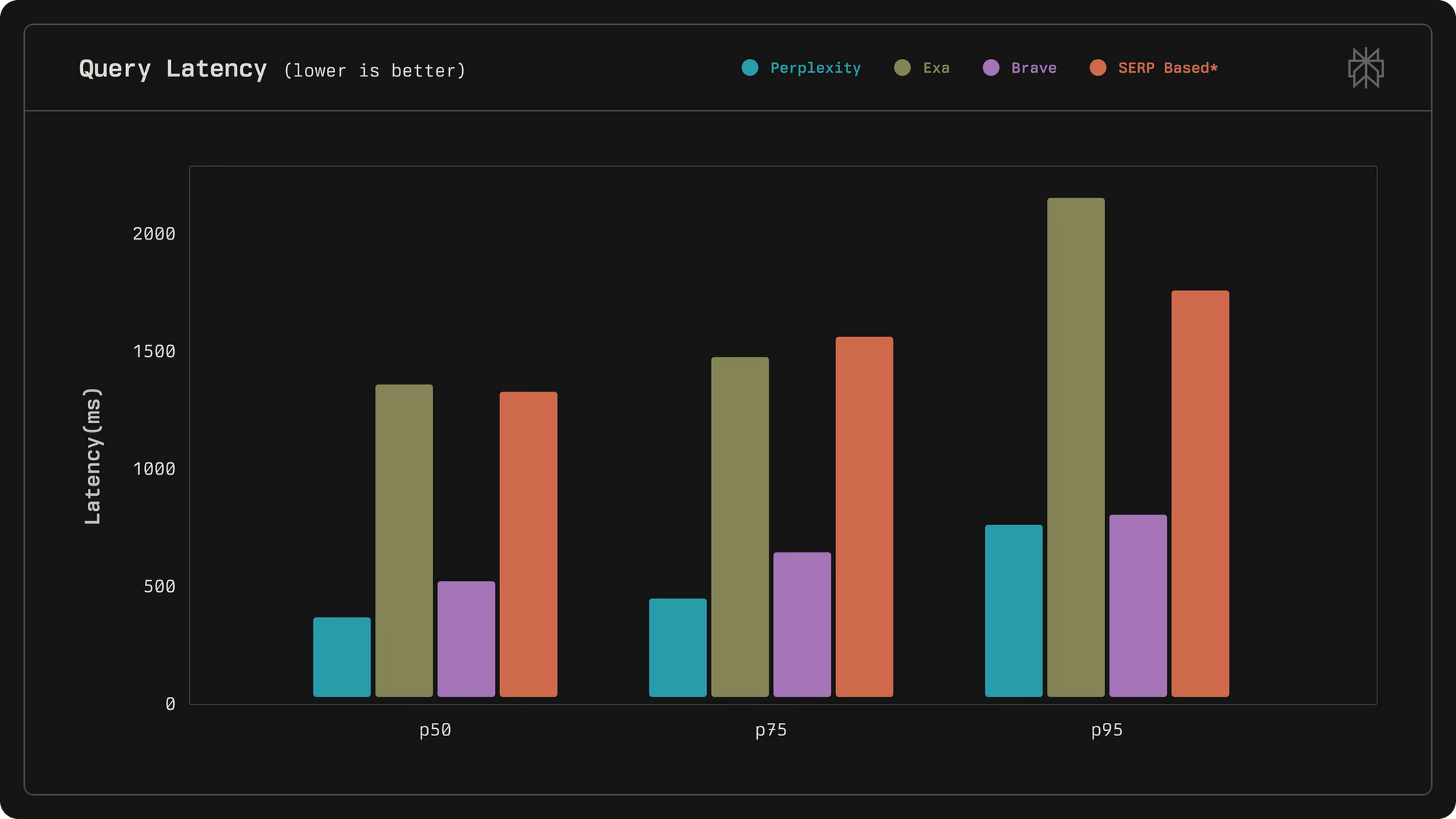
Perplexityのエンジニアは、関連性と速度の最前線に立つようにAPIを設計し、レイテンシと品質の指標において競合他社を凌駕しています。例えば、中央値レイテンシは358ミリ秒を達成しており、Exaの1375ミリ秒といった代替案をはるかに下回っています。さらに、このAPIは人間のフィードバックループとLLMランキングを組み込んで結果を洗練させ、信頼性の高い情報検索を必要とするアプリケーションに最適です。
さらに、Perplexity Search APIは、プライバシーへのコミットメント(ユーザーデータが基盤となるLLMを学習しないこと)と、検索リクエストに対する優れた価格設定によって際立っています。開発者は、シンプルなQ&Aボットから複雑な研究エージェントまで、多様なシナリオでこれを利用しています。したがって、ウェブ全体で深い調査を行うAIエージェントを構築するための基盤となるレイヤーとして機能します。
Perplexity Search APIの主要機能と利点
Perplexity Search APIは、技術的な実装におけるその有用性を高めるいくつかの際立った機能を誇っています。まず、きめ細かなコンテンツ理解を提供し、ドキュメントをサブユニットに分割してターゲットを絞った検索を可能にします。このアプローチにより、前処理の必要性が減り、AIパイプラインへの統合が加速されます。さらに、このAPIは高度なフィルタリングをサポートしており、リアルタイムデータのパラメータを指定したり、無関係なコンテンツを除外したりできます。
もう1つの重要な機能は、語彙的信号と意味的信号を統合して包括的な候補セットを生成するハイブリッド検索システムです。エンジニアは、これが低レイテンシを維持しながら完全性を保証するため、高く評価しています。さらに、このAPIは、スコア付きスニペットや引用を含む構造化された出力を提供し、結果への信頼を育みます。
その利点は技術的な優位性にとどまりません。開発者は、生の検索に対して1,000リクエストあたり5ドルという価格モデルでコストを節約でき、競合他社よりも経済的です。さらに、パフォーマンスを損なうことなく、1日あたり最大2億件のクエリを処理できるため、簡単にスケーリングできます。その結果、スタートアップ企業も大企業も同様にこれを採用し、関連するSDKを使用して1時間以内に製品をプロトタイプ作成するなど、迅速なイノベーションを実現しています。
しかし、真の利点はその継続的な改善にあります。Perplexityは何百万ものインタラクションからのユーザー信号を統合してAPIを繰り返し強化し、ウェブコンテンツのダイナミクスとともに進化することを保証しています。その結果、現在のニーズを満たすだけでなく、AI検索における将来の需要を予測するツールにアクセスできるようになります。
Perplexity Search APIのアーキテクチャを理解する
Perplexityは、スケーラビリティとインテリジェンスに焦点を当ててSearch APIを設計しています。その核となるのは、400ペタバイトを超えるホットストレージを含む多層ストレージ設定を採用し、数十億のドキュメントを効率的に管理することです。機械学習モデルは、更新頻度などの要因に基づいてURLの重要性を予測し、クロールとインデックス作成を優先します。
さらに、コンテンツ理解モジュールは、フロンティアLLMによって強化された動的な解析ロジックを使用して、多様なウェブサイトのレイアウトに適応します。このモジュールは毎時数百万のクエリを処理し、評価ループを通じて自己改善することで、完全性と品質を最適化します。エンジニアはドキュメントをサブユニットに分割し、AIモデルにおけるコンテキストの制限に対処し、正確なランキングを可能にします。
検索パイプラインは多段階プロセスに従います。最初のハイブリッド検索で候補を生成し、事前フィルタリングでノイズを除去し、段階的なランキングで語彙ベース、埋め込みベース、およびクロスエンコーダーモデルを適用します。この設計は、トレーニングのためにライブシグナルを活用し、Perplexityの製品と共同開発されて精度を高めています。
このアーキテクチャにおける課題には、予算の制約の下で鮮度と完全性のバランスを取ることが含まれます。Perplexityは、ML駆動型の優先順位付けと水平スケーリングによってこれらを解決しています。ベストプラクティスとして、チームはハイブリッドシグナルと、オープンソースフレームワークであるsearch_evalsを使用した厳格な評価を推奨しています。
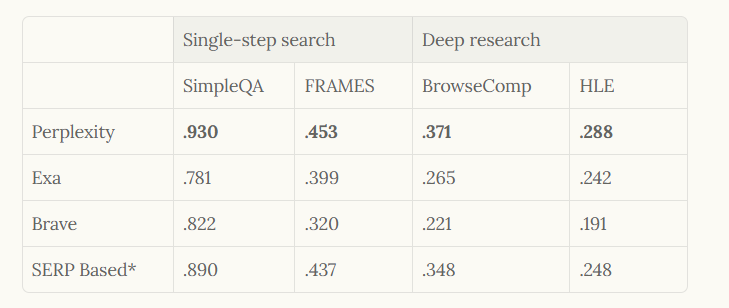
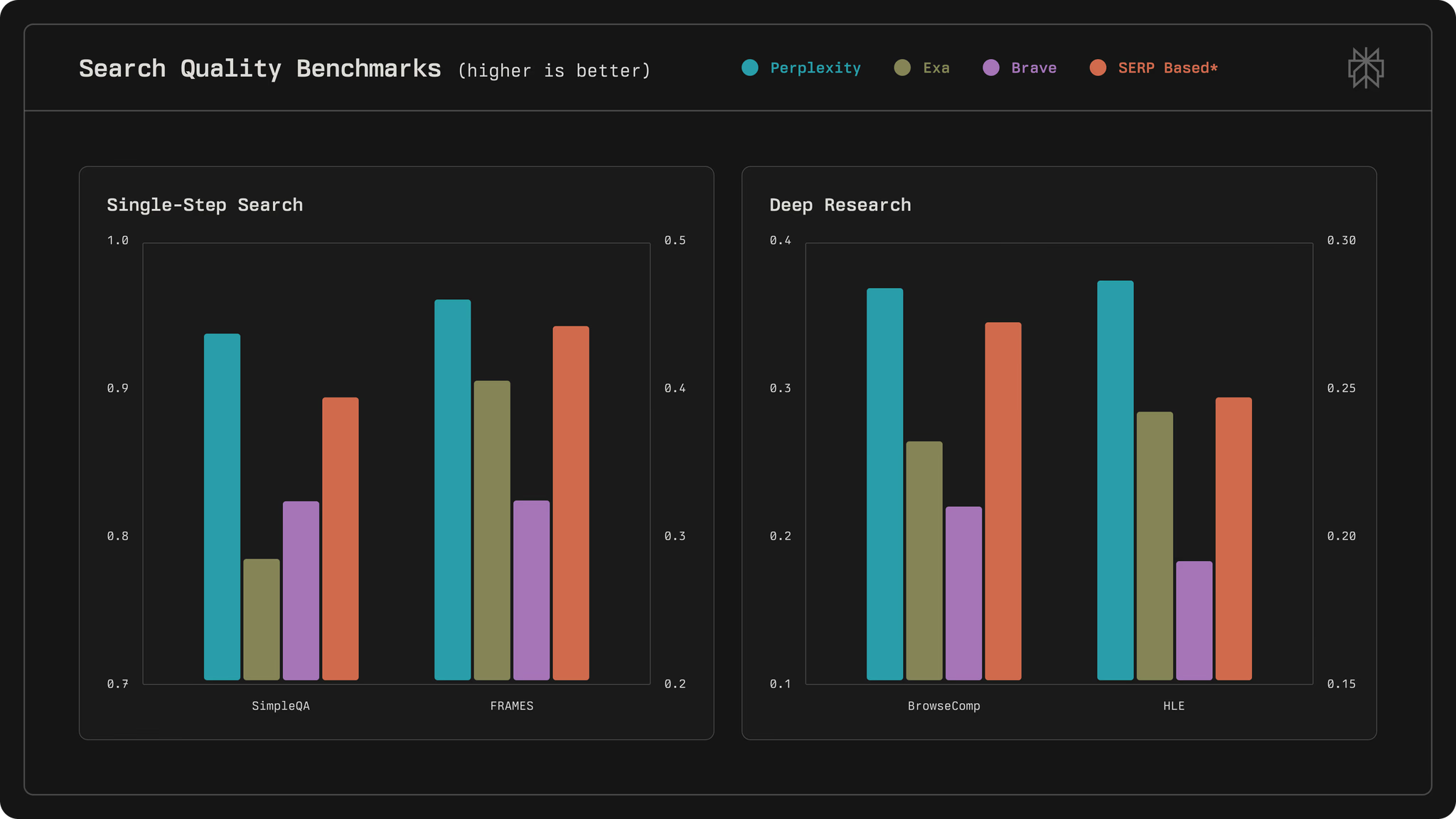
評価において、Perplexityは単一ステップ検索にはSimpleQA、深層研究にはBrowseCompなどのベンチマークを採用し、SimpleQAで0.930といった最高スコアを達成しています。したがって、このアーキテクチャは大量の使用をサポートするだけでなく、AIファーストな検索システムの標準を確立しています。
Perplexity Search APIの料金とサブスクリプションプラン
Perplexityは、手頃な価格と透明性を優先してSearch APIの料金体系を構築しています。生のウェブ検索結果の基本費用は1,000リクエストあたり5ドルで、このエンドポイントには追加のトークンベースの料金はありません。このモデルは、複雑な請求なしで簡単な検索統合を必要とする開発者に適しています。
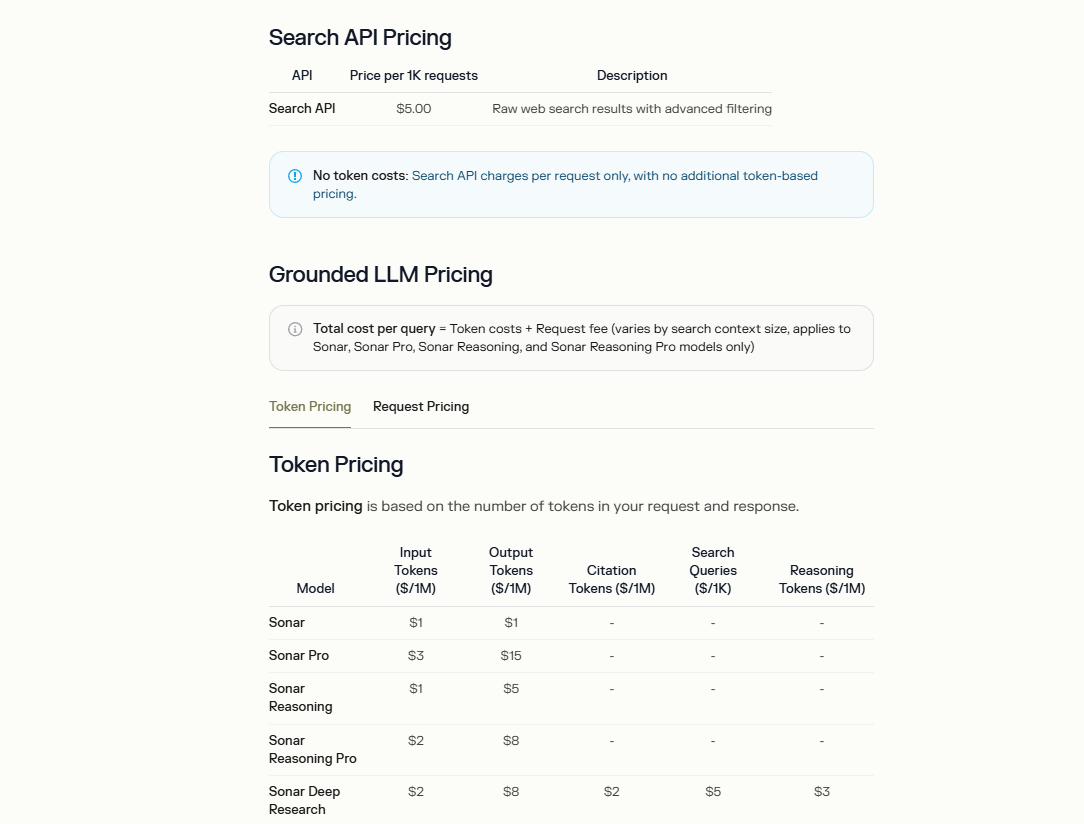
グラウンデッドLLM統合の場合、料金にはトークン費用とリクエスト料金が含まれ、モデルによって異なります。例えば、Sonarモデルは入力トークン100万個あたり1ドル、出力トークン100万個あたり1ドルを請求します。Sonar Proのような高度なバリアントでは、入力100万個あたり3ドル、出力100万個あたり15ドルに上昇します。さらに、Sonar Deep Researchには、引用トークン(100万個あたり2ドル)、検索クエリ(1,000個あたり5ドル)、推論トークン(100万個あたり3ドル)の料金が含まれます。
使用制限はこれらの指標に直接関連しており、1トークンは英語テキストの約4文字に相当します。開発者は、請求と支払いを処理するAPIポータルの管理セクションを通じて消費量を監視します。ただし、ドキュメントにはSearch APIの無料枠は記載されておらず、本番環境での使用には有料アクセスが強調されています。
したがって、この価格設定により、スケーラブルな導入が可能になります。小規模チームは基本的な検索から始め、企業は包括的なアプリケーションのために高度なモデルを活用します。プロジェクトの予算と一致させるために、常に公式ポータルの最新の詳細を確認してください。
はじめに:サインアップとAPIキーの取得
Perplexity Search APIの使用を開始するには、APIプラットフォームにアクセスしてください。アカウントをお持ちでない場合は作成し、APIキーのタブにアクセスして新しいキーを生成します。このキーはすべてのリクエストを認証するため、安全に保管してください。
次に、キーを環境変数として設定します。Windowsでは、setx PERPLEXITY_API_KEY "your_api_key_here" コマンドを使用します。他のシステムでは、シェルでエクスポートします。この設定により、SDKクライアントはキーを自動的に検出し、認証を簡素化します。
さらに、開発環境でシークレットを管理するために、python-dotenvのようなツールを使用することを検討してください。機密情報をハードコードしないように、コードで.envファイルをロードします。設定が完了すれば、PythonまたはNode.jsでクライアントをシームレスにインスタンス化できます。
ただし、テストリクエストを作成して設定を確認してください。問題が発生した場合は、トラブルシューティングのためにコミュニティフォーラムまたはドキュメントを参照してください。この最初のステップは、実装へのスムーズな進行を保証します。
PythonおよびNode.js用Perplexity SDKのインストール
Perplexity SDKは、Python 3.8+およびNode.jsでのSearch APIとのインタラクションを容易にします。Pythonの場合、pip経由でインストールします: pip install perplexityai。このコマンドは、パラメータと応答の型定義を含むパッケージを取得します。
Node.jsでは、具体的なインストール詳細は異なりますが、通常はnpmまたはyarnを使用してパッケージを追加します。SDKは同期および非同期操作をサポートしており、異なるアプリケーションアーキテクチャに対する柔軟性を高めます。
インストール後、ライブラリをインポートします。Pythonでは、from perplexity import Perplexity を使用し、クライアントを作成します: client = Perplexity()。このクライアントは、環境変数からAPIキーを自動的に取得します。
さらに、SDKはすべてのAPIエンドポイントに対して包括的なサポートを提供し、リクエストを効率的に処理できるようにします。エラーなしでインポートできることを確認してインストールをテストし、コーディングの準備が整っていることを確認します。
Perplexity Search APIで最初の検索リクエストを行う
SDKがインストールされたら、最初の検索リクエストを開始します。Pythonでは、クエリパラメータを指定してクライアントの検索メソッドを使用します。例:
import os
from perplexity import Perplexity
client = Perplexity()
response = client.search("example query")
print(response)
このコードは基本的な検索を送信し、結果とスコアを含む構造化された応答を出力します。
さらに、日付範囲やドメインなどのフィルターを追加してリクエストをカスタマイズし、出力を洗練させることができます。APIは、ドキュメント単位、スニペット、関連性スコアを含むJSONを返し、アプリケーションでの解析に利用できます。
ただし、エラーは適切に処理してください。認証の問題やレート制限を捕捉するために、try-exceptブロックを実装します。実験する際には、応答をログに記録して出力形式を深く理解してください。
したがって、このシンプルなリクエストはAPIの使いやすさを示しており、より複雑な統合への道を開きます。
高度な使用法:パラメータ、フィルタリング、カスタマイズ
Perplexity Search APIは、カスタマイズされた検索のための広範なパラメータをサポートしています。主要な入力としてqueryを指定し、メディアタイプにはfilterを、時間ベースの制限にはsince/untilを追加します。例えば、位置情報固有の結果にはgeocodeを含めますが、ジオタグの制限があるため控えめに使用してください。
さらに、正確なフレーズや除外などの高度な演算子を活用して精度を高めます。ハイブリッドシステムはセマンティックランキングを自動的に適用しますが、グラウンデッドコールでのモデル選択を通じてこれを影響させることができます。
コードでは、基本的なリクエストを拡張します。
response = client.search(
query="AI search APIs",
filter="news",
since="2025-01-01"
)
これにより、関連性スコア付きの最新ニュース記事が取得されます。
さらに、深層研究のためにSonar Deep Researchモデルと統合すると、追加のトークンコストが発生しますが、段階的な推論が可能になります。reasoning_effortを調整してクエリの深さを制御します。
したがって、これらのパラメータを習得することで、迅速な検索から徹底的な分析まで、特定のユースケースに合わせて最適化できます。
Perplexity Search APIをアプリケーションに統合する
開発者は、Perplexity Search APIをウェブアプリ、チャットボット、AIエージェントに簡単に統合できます。Node.jsバックエンドの場合、SDKを使用して非同期リクエストを処理し、結果をフロントエンドコンポーネントに供給します。
例えば、研究ツールでは、ユーザー入力に基づいてAPIをクエリし、応答を解析して引用されたスニペットを表示します。キャッシュまたはキューイングを実装することで、レート制限への準拠を確実にします。
さらに、他のサービスと組み合わせます。自然言語処理ライブラリと連携してクエリを前処理し、精度を高めます。
ただし、スケーラビリティを考慮してください。予算超過を避けるために使用状況を監視し、利用可能な場合はWebフックを使用して更新を行います。
その結果、この統合により、静的なアプリケーションが動的で知識駆動型のシステムに変革されます。
Apidogを使用したテストとデバッグ
Apidogは、API開発のためのオールインワンプラットフォームとして機能し、Perplexity Search APIのようなエンドポイントの設計、デバッグ、モック、テストを可能にします。現実世界のシナリオをシミュレートし、早期にバグを検出することで、ワークフローを効率化します。
Perplexity Search APIでApidogを使用するには、API仕様をApidogのインターフェースにインポートします。さまざまなクエリのテストケースを作成し、期待される構造に対して応答を検証します。ApidogのAI機能はドキュメント作成とテストを自動化し、手作業を削減します。
さらに、オフライン開発のためにAPIをモックし、アプリケーションがエッジケースを処理できることを確認します。品質を維持するために参照資料とレポートを生成します。
したがって、Apidogはデバッグを加速させ、堅牢な統合に不可欠なものとなります。
パフォーマンス評価と最適化のためのベストプラクティス
Perplexity Search APIを評価するには、オープンソースのsearch_evalsフレームワークを使用し、FRAMESやHLEなどのスイートに対してベンチマークを行います。このツールは、レイテンシと品質を中立的に評価します。
バランスの取れた結果を得るために、パイプラインにハイブリッド検索を実装します。ウェブの変化に適応するために、解析ロジックを定期的に更新します。
さらに、Perplexityのアプローチを反映して、ユーザーフィードバックを取り入れてクエリを微調整します。
ただし、デフォルトに過度に依存せず、ドメインに合わせてパラメータをカスタマイズしてください。
したがって、これらのプラクティスは最適なパフォーマンスと信頼性を保証します。
一般的な課題とトラブルシューティングのヒント
ユーザーは認証エラーに遭遇することがあります。環境変数を再確認してください。レイテンシの問題については、クエリの複雑さを最適化してください。
さらに、コード内で指数関数的バックオフを使用してレート制限を処理します。
結果の関連性が低い場合は、フィルターを洗練するか、高度なモデルを使用してください。
その結果、積極的なトラブルシューティングによりスムーズな運用が維持されます。
今後の開発とコミュニティリソース
Perplexityは、研究主導のアップデートによりAPIの強化を続けています。洞察やイベントのために開発者コミュニティに参加してください。
さらに、オープンソースへの貢献を探求して、最先端を維持してください。
結論
Perplexity Search APIは、開発者がAIアプリケーションで高度な検索を活用できるようにします。このガイドに従うことで、Apidogのようなツールを活用して効率的に実装できます。その可能性を最大限に引き出すために、実験を続けてください。