
オーディオ処理は人工知能において急速に重要性を増しており、バーチャルアシスタント、文字起こしツール、音声主導のインターフェースなどのアプリケーションを支えています。AIイノベーションの先駆者であるOpenAIは、最近次世代のオーディオモデルを発表し、音声認識と音声合成の新しい基準を打ち立てました。具体的には、gpt-4o-transcribe、gpt-4o-mini-transcribe、およびgpt-4o-mini-ttsと呼ばれるこれらのモデルは、卓越したパフォーマンスを提供し、開発者がより正確で応答性の高い音声ベースのソリューションを作成することを可能にします。このブログポストでは、OpenAIのAPIを通じてこれらのモデルにアクセスする方法について、詳細で技術的なロードマップを提供します。
これらの新しいモデルが提供するものを探っていきましょう。
OpenAIの新しいオーディオモデルとは何か?
OpenAIの最新のオーディオモデルは、ノイズの多い環境や多様な話し方など、実際のオーディオ処理における課題に取り組んでいます。APIを効果的に使用するためには、各モデルの能力をまず理解する必要があります。

以下はその概要です。
Gpt-4o-transcribe: 高精度音声認識
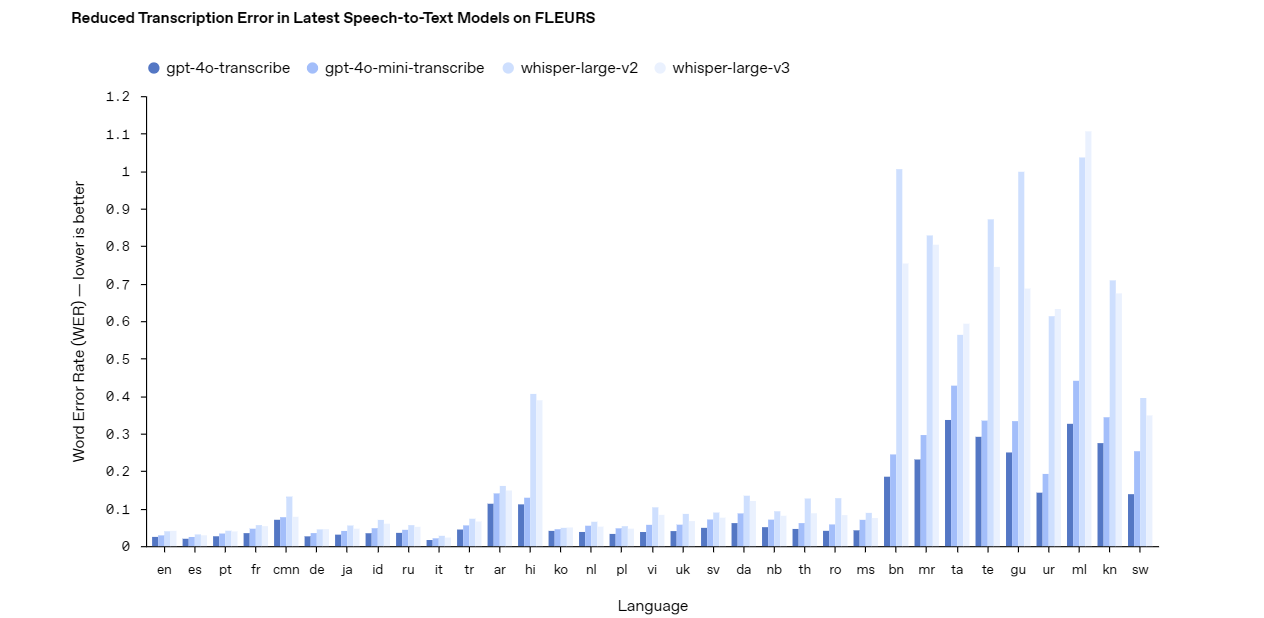
gpt-4o-transcribeモデルは、堅実な音声認識ソリューションとして優れています。バックグラウンドノイズや速い話し方などの厳しい条件でも高い精度を提供します。このモデルは、ライブキャプション、音声コマンドシステム、オーディオ分析ツールなど、正確な文字起こしを必要とするアプリケーションに信頼できる選択肢です。その高度な設計により、複雑で重要なプロジェクトに最適な選択肢となっています。
Gpt-4o-mini-transcribe: 軽量文字起こし
一方、gpt-4o-mini-transcribeモデルは、より軽量で効率的な代替手段を提供します。gpt-4o-transcribeと比較するといくらかの精度を犠牲にしますが、リソースの消費が少ないため、より簡単なタスクに最適です。このモデルは、カジュアルなボイスメモや基本的なコマンド認識など、スピードと効率が完璧な精度よりも重要なアプリケーションに使用することができます。

Gpt-4o-mini-tts: カスタマイズ可能な音声合成
音声合成に移ると、gpt-4o-mini-ttsモデルはその自然な音声出力で際立っています。従来の音声合成システムとは異なり、このモデルではトーン、スタイル、感情のカスタマイズが指示によって可能です。この柔軟性は、パーソナライズされた音声エージェント、オーディオブックのナレーション、またはカスタマーサービスボットなど、カスタマイズされた音声体験が必要なプロジェクトに適しています。
これらのモデルを念頭に置いて、それらを<強>API経由でアクセスする前に、料金体系を理解しておきましょう。
OpenAIのオーディオモデルAPIの料金
OpenAIのオーディオモデルをプロジェクトに統合する前に、関連するコストを理解することが重要です。OpenAIは、そのオーディオAPIに対して使用量に基づく料金モデルを提供しています。この料金は、特定のモデルや使用量に応じて異なります。以下に、gpt-4o-transcribe、gpt-4o-mini-transcribe、およびgpt-4o-mini-ttsの主な価格詳細を示します。
音声認識モデル:gpt-4o-transcribeとgpt-4o-mini-transcribe
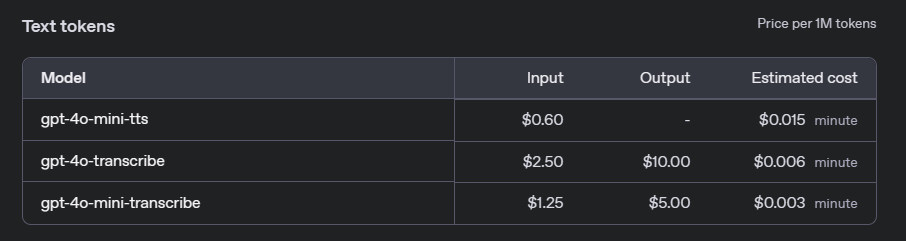
音声認識サービスに対して、OpenAIは処理された音声の持続時間に基づいて料金を請求します。フルgpt-4o-transcribeモデルと軽量のgpt-4o-mini-transcribeモデルでは料金が異なります:
- gpt-4o-transcribe: 音声1分あたり$0.006。
- gpt-4o-mini-transcribe: 音声1分あたり$0.003。
これらの料金により、gpt-4o-mini-transcribeは極端な正確性が求められないアプリケーションにとってコスト効率の良い選択肢となり、gpt-4o-transcribeは高精度なタスクに適しています。
音声合成モデル:gpt-4o-mini-tts
音声合成の場合、料金は入力テキストの文字数に基づきます:
- gpt-4o-mini-tts: 文字1文字あたり$0.015。
この料金体系は、インタラクティブな音声応答やオーディオブック生成など、音声出力の長さが様々なアプリケーションに特に柔軟性を持たせています。
無料プランと使用制限
OpenAIは、開発者がオーディオモデルを有料使用する前に実験するための無料プランを提供しています。新しいユーザーは、任意のAPIサービス(オーディオモデルを含む)に適用できる$5の無料クレジットを受け取ります。さらに、使用は公平なアクセスを確保するためにレート制限が設けられています。例えば、音声認識APIには1分あたり100リクエストの制限があり、音声合成APIには1分あたり50リクエストまで許可されています。
これらのコストを理解することで、オーディオモデルをアプリケーションに統合する際の予算管理が効果的になります。それでは、APIを介してこれらのモデルにアクセスする方法について見ていきましょう。
OpenAIのオーディオモデルAPIにアクセスする方法:ステップバイステップ
OpenAIのAPIにアクセスするには、構造化されたアプローチが必要です。以下のステップに従って、オーディオモデルをプロジェクトに統合します。
ステップ1: APIキーを取得する
まず、OpenAIからAPIキーを取得します。OpenAIプラットフォームに訪れ、アカウントを作成していない場合は作成し、開発者ダッシュボードでキーを生成します。このキーは安全に保管してください。これはAPIへの入り口であり、機密を保持する必要があります。

ステップ2: OpenAI Pythonライブラリをインストールする
次に、APIとの対話を簡素化するために、OpenAI Pythonライブラリをインストールします。ターミナルを開いて、以下のコマンドを実行してください:
pip install openai
このライブラリは、リクエストを送信するためのクリーンなインターフェースを提供し、手動のHTTPコールを行う必要がないようにします。
ステップ3: APIキーを認証する
リクエストを送信する前に、スクリプトをAPIキーで認証する必要があります。Pythonファイルに以下のコードを追加してください:
import openai
openai.api_key = 'your-api-key-here'
'your-api-key-here'を実際のキーに置き換えてください。このステップにより、あなたのリクエストが認可されます。
ステップ4: オーディオモデルにリクエストを送信する
さて、オーディオモデルにリクエストを送信しましょう。各モデルは、特定のエンドポイントとパラメータを使用します。音声認識と音声合成の両方のサンプルを以下に示します。
gpt-4o-transcribeによる音声認識
gpt-4o-transcribeを使用して音声を文字起こしするには、オーディオファイルをAPIに送信します。以下はサンプルスクリプトです:
with open('audio_file.wav', 'rb') as audio_file:
response = openai.Audio.transcribe(
model="gpt-4o-transcribe",
file=audio_file
)
print(response['text'])
このコードはオーディオファイル(例:audio_file.wav)を開き、文字起こしされたテキストを印刷します。ファイルがWAVまたはMP3といったサポートされている形式であることを確認してください。
gpt-4o-mini-ttsによる音声合成
gpt-4o-mini-ttsを使用して音声合成を行うには、テキストとオプションの音声指示を提供します。こちらの例を試してみてください:
response = openai.Audio.synthesize(
model="gpt-4o-mini-tts",
text="私たちのサービスへようこそ!どのようにお手伝いできますか?",
voice_instructions="温かく、プロフェッショナルなトーンを使ってください。"
)
with open('output_audio.wav', 'wb') as audio_file:
audio_file.write(response['audio'])
これにより、カスタマイズされた声の音声ファイル(output_audio.wav)が生成されます。voice_instructionsを試して、出力を調整してください。
これらのステップが完了すると、モデルを実際のアプリケーションに統合する準備が整います。
OpenAIのオーディオモデルの実用的なアプリケーション
OpenAIのオーディオモデルは、無限の可能性を開きます。ここにいくつかの例をご紹介します。
音声アシスタント
自然に聞き、応答する音声アシスタントを構築します。gpt-4o-transcribeを使用してコマンド認識を行い、gpt-4o-mini-ttsを使用して応答を行い、シームレスなユーザー体験を創り出します。
文字起こしサービス
会議や講義のための文字起こしツールを開発します。gpt-4o-transcribeを使用して音声を高精度でテキストに変換し、その後ユーザーにダウンロード可能な文字起こしを提供します。
アクセシビリティソリューション
視覚障害者向けにテキストを音声に変換して、アクセシビリティを向上させます。gpt-4o-mini-ttsモデルのカスタマイズにより、魅力的で人間らしい読み上げ体験を提供します。
カスタマーサポートの自動化
AI駆動のサポートエージェントを作成します。gpt-4o-transcribeを使用して問い合わせを理解し、gpt-4o-mini-ttsを使用してブランドボイスで応答し、顧客満足度を向上させます。
これらの例はAPIの汎用性を強調しています。それでは、実装を最適化するためのベストプラクティスを考えてみましょう。
OpenAIのオーディオモデルAPIを使用するためのベストプラクティス
パフォーマンスを最大化するために、以下のガイドラインに従ってください。
オーディオ品質を最適化する
常に高品質のオーディオ入力を使用してください。バックグラウンドノイズを減らし、クリアなマイクを選択することで、gpt-4o-transcribeまたはgpt-4o-mini-transcribeによる文字起こしの精度を向上させます。
適切なモデルを選択する
ニーズに応じたモデルを選びましょう。正確性が重要な場合はgpt-4o-transcribeを選択し、軽量なタスクの場合はgpt-4o-mini-transcribeが適しています。決定する前にリソース制約を評価してください。
カスタマイズを活用する
gpt-4o-mini-ttsでは、音声指示を使って実験し、アプリケーションに合わせて出力をカスタマイズしてください。元気な挨拶でも、穏やかなナレーションでも、用途に応じて調整可能です。
徹底的にテストする
多様なオーディオサンプルで統合をテストしてください。gpt-4o-transcribeがアクセントやノイズを処理できるか確認し、gpt-4o-mini-ttsが一貫した音声品質を提供することを確認します。
APIテストにApidogを使用すべき理由
ツールについて言えば、Apidogにはもっと注目すべき点があります。このプラットフォームは、リクエストシミュレーション、応答検証、パフォーマンス監視などの機能を提供することで、API開発を効率化します。OpenAIのAPIで作業している際に、Apidogを使用すると、広範なコードを書くことなくgpt-4o-transcribeのエンドポイントをテストすることができます。その直感的なインターフェースは時間を節約し、デバッグよりも構築に集中することを可能にします。

結論
OpenAIの新しいオーディオモデルであるgpt-4o-transcribe、gpt-4o-mini-transcribe、およびgpt-4o-mini-ttsは、オーディオ処理技術の進歩を象徴しています。このガイドでは、APIを介してこれらにアクセスする方法を、キーの確保から実用的な例のコーディングまで示しました。アクセシビリティを向上させるにせよ、サポートを自動化するにせよ、これらのモデルは強力なソリューションを提供します。
あなたの旅をスムーズにするために、Apidogを利用しましょう。Apidogを無料でダウンロードしてAPIテストを簡単にし、統合が効果的に行えるようにしましょう。今日、OpenAIのオーディオモデルで実験を始め、そのフルポテンシャルを解き放ちましょう。
