
おそらく、OpenAIの最新の革新やエージェント構築のための新しいツールについて聞いたことがあるでしょう。これらのツールは、OpenAI APIによって動かされており、開発者が知的で応答性のあるシステムを構築する方法を革新しています。熟練のコーダーでも、始めたばかりでも、このブログ記事では、OpenAIの提供を活用して自分のエージェントを構築するために知っておくべきことを紹介します。
なぜOpenAIのエージェント構築に関する新しいツールがゲームチェンジャーなのか
OpenAIは、OpenAI APIへのウェブ検索機能の統合を発表しました。この更新により、高速で最新の回答が関連するウェブソースへのリンクと共に提供され、すべてはChatGPT検索の背後にある同じモデルによって動かされています。これは、複雑なタスクを処理し、リアルタイムデータを取得し、ユーザーとシームレスにインタラクションできるAIアシスタントのようなエージェントシステムを構築しようとする開発者にとっての大きな飛躍です。
OpenAIは、Responses API、ウェブ検索機能、ファイル検索ツール、コンピュータ使用機能、そしてAgents SDKを導入しました。これらはすべて合わせて、これまで以上に賢く自律的に感じるエージェントを構築するための強力なフレームワークを形成します。新しいツールは、開発者が安全で、効率的で、強力なエージェントを作成するのを助けるように設計されています。
エージェントとは何か?簡単な復習
AIの文脈におけるエージェントとは、環境を認識し、決定を下し、特定の目標を達成するために行動を取ることができる自律システムまたはプログラムです。それを質問に答えたり、タスクを実行したり、さらにはインタラクションから学習したりすることができるデジタルのお供と考えてください。
OpenAIの新しいツールは、開発者がOpenAI APIを使用してこれらのエージェントを構築できるようにしており、エージェントをより賢く、迅速に、そしてウェブとより多く接続できるようにします。
始めるために:OpenAIのResponses APIの理解
Responses APIは、OpenAIのChat CompletionsおよびAssistants APIの最高の機能を組み合わせたゲームチェンジャーで、よりシンプルで強力なツールです。OpenAIの以前のAPIに詳しい方は、このプロセスがどれほどエージェント構築を簡素化するかを理解できるでしょう。
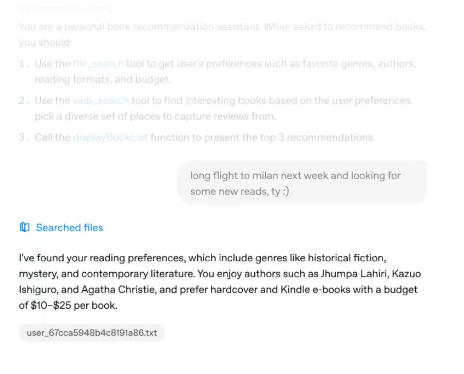
始めるには、OpenAIの開発者向けドキュメントにアクセスしてください。Responses APIを使用すると、複数のツールやモデルを統合して複雑なタスクを実行できるため、質問に答えることから多段階のワークフローを調整することまで、AIエージェントを作成するのに最適です。
以下は、どのように始められるかです:
OpenAI APIは、テキスト生成、自然言語処理、コンピュータビジョンなどの最先端AI モデルに対して簡単なインターフェースを提供します。この例は、プロンプトからテキスト出力を生成します。これは、ChatGPTを使用するのと同じように行います。
import OpenAI from "openai";
const client = new OpenAI();
const response = await client.responses.create({
model: "gpt-4o",
input: "ユニコーンについての一文のベッドタイムストーリーを書いてください。"
});
console.log(response.output_text);画像入力を分析する
モデルには画像入力を提供することもできます。レシートをスキャンしたり、スクリーンショットを分析したり、コンピュータビジョンを使用してリアルワールドのオブジェクトを見つけたりできます。
import OpenAI from "openai";
const client = new OpenAI();
const response = await client.responses.create({
model: "gpt-4o",
input: [
{ role: "user", content: "この写真でプレイしている2つのチームは何ですか?" },
{
role: "user",
content: [
{
type: "input_image",
image_url: "https://upload.wikimedia.org/wikipedia/commons/3/3b/LeBron_James_Layup_%28Cleveland_vs_Brooklyn_2018%29.jpg",
}
],
},
],
});
console.log(response.output_text);ツールでモデルを拡張する
ツールを使用してモデルに新しいデータと機能へのアクセスを提供します。自分のカスタムコードを呼び出すか、OpenAIの強力な組み込みツールのいずれかを使用できます。この例では、ウェブ検索を使用して、モデルがインターネット上の最新情報にアクセスできるようにします。
import OpenAI from "openai";
const client = new OpenAI();
const response = await client.responses.create({
model: "gpt-4o",
tools: [ { type: "web_search_preview" } ],
input: "今日のポジティブなニュースストーリーは何でしたか?",
});
console.log(response.output_text);迅速なAI体験を提供する
新しいリアルタイムAPIまたはサーバー送信のストリーミングイベントを使用して、ユーザーのために高性能で低遅延の体験を構築できます。
import { OpenAI } from "openai";
const client = new OpenAI();
const stream = await client.responses.create({
model: "gpt-4o",
input: [
{
role: "user",
content: "‘ダブルバブルバス’を10回速く言って。",
},
],
stream: true,
});
for await (const event of stream) {
console.log(event);
}エージェントを構築する
OpenAIプラットフォームを使用して、ユーザーの代理で行動を起こすことができるエージェントを構築します。バックエンドで調整ロジックを作成するためにPython用Agent SDKを使用します。
from agents import Agent, Runner
import asyncio
spanish_agent = Agent(
name="スペイン語エージェント",
instructions="あなたはスペイン語だけを話します。",
)
english_agent = Agent(
name="英語エージェント",
instructions="あなたは英語だけを話します。",
)
triage_agent = Agent(
name="トリアージエージェント",
instructions="リクエストの言語に基づいて適切なエージェントにハンドオフします。",
handoffs=[spanish_agent, english_agent],
)
async def main():
result = await Runner.run(triage_agent, input="Hola, ¿cómo estás?")
print(result.final_output)
if __name__ == "__main__":
asyncio.run(main())
# ¡Hola! Estoy bien, gracias por preguntar. ¿Y tú, cómo estás?APIの組み込みツールは、これらのタスクをシームレスに実行し、時間と労力を節約します。さらに、安全性と信頼性が考慮されているため、開発者にとって大きな利点です。
スマートエージェントのためのウェブ検索
OpenAIのウェブ検索ツールは、GPT-4o検索やGPT-4oミニ検索のようなモデルによって動かされており、エージェントがインターネットから最新の情報を取得し、情報源を引用できるようにします。これは、正確でリアルタイムな回答を提供する必要のあるエージェントを構築するのに特に便利です。
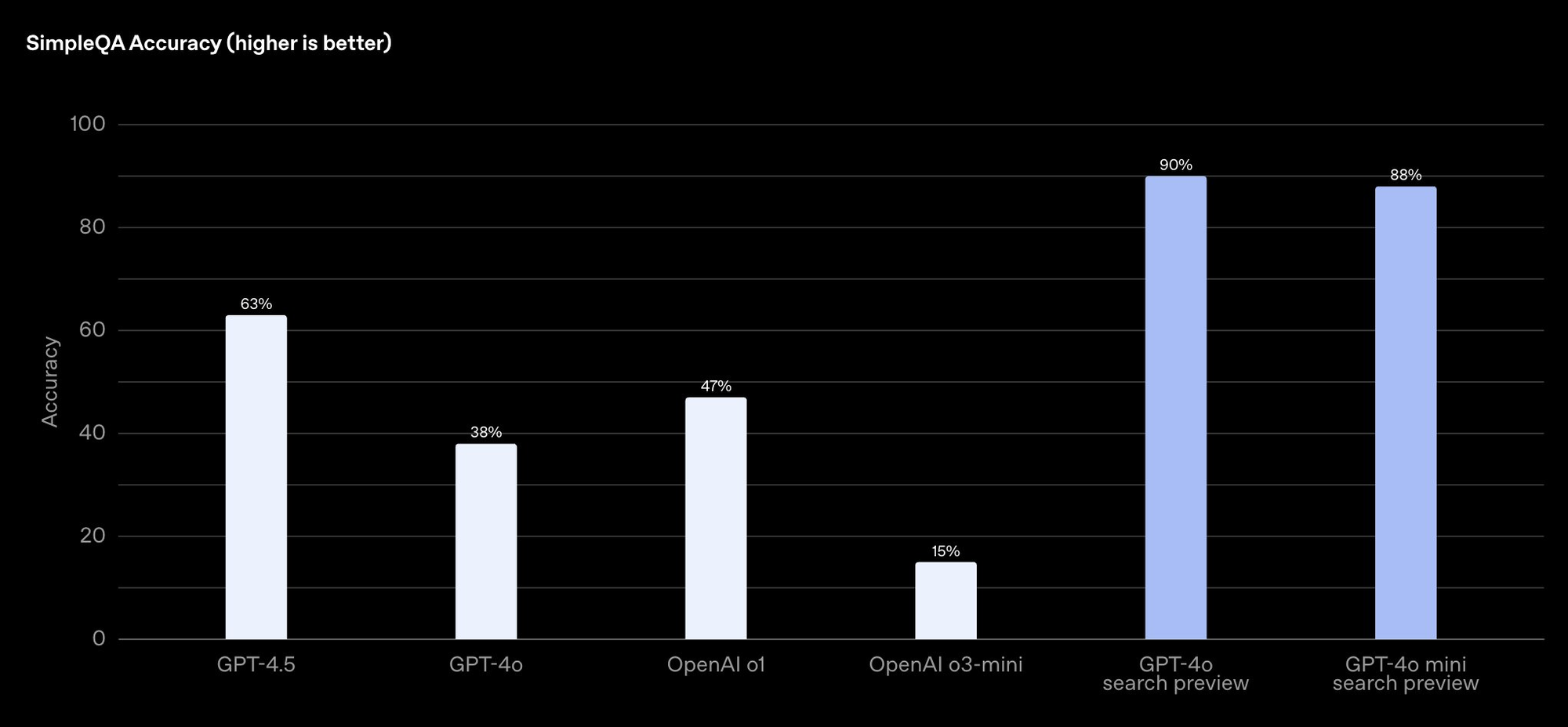
ウェブ検索ツールは、OpenAI APIを介してプレビューとして利用可能であり、驚くべき精度を誇ります。OpenAIのSimpleQAベンチマークでは、GPT-4o検索が90%、GPT-4oミニ検索が88%のスコアを獲得しています。それはかなりの精度です!
エージェントにウェブ検索を実装するには、OpenAIのガイドをチェックしてください。簡単な概要は以下の通りです:
- ツールを統合する: Responses APIを使用して、エージェントにウェブ検索機能を有効にします。
- クエリを作成する: エージェントがウェブ検索ツールに特定のクエリを送信するように設計し、関連する結果を取得します。
- 結果を表示する: エージェントがユーザーに結果を提示することができ、透明性のために情報源へのリンクも含めます。
製品の可用性や業界のトレンドに関する質問に答えるためにウェブ検索を使用するカスタマーサービスボットを構築することを想像してみてください。OpenAIのウェブ検索を使用すれば、エージェントはタイムリーで正確な応答を提供し、ユーザーの信頼と満足度を向上させることができます。
効率的なデータアクセスのためのファイル検索の習得
OpenAIのもう一つの強力なツールはファイル検索です。この機能を使用すると、AIエージェントが企業のデータベース内のファイルを迅速にスキャンして情報を取得できます。これは、エージェントが社内の文書、報告書、またはデータセットにアクセスする必要がある企業アプリケーションに最適です。
OpenAIは、これらのファイルでモデルを訓練しないことを強調しており、プライバシーとセキュリティが企業にとって重要な考慮事項であることを保証しています。ファイル検索については、ドキュメントで詳しく学ぶことができます。
エージェントにファイル検索を組み込む方法は以下の通りです:
- ファイルをアップロードする: OpenAI APIを使用して、ファイルをプラットフォームにアップロードします。
- エージェントを設定する: Responses API内でファイル検索ツールを使用するようにエージェントを設定します。
- データをクエリする: エージェントがファイル内の特定の情報を検索し、関連する結果を返すことができます。
例えば、従業員の記録を検索して給与詳細や休暇残高を提供するHRエージェントを構築することができます。この程度の自動化は、手動作業の何時間も節約し、部門全体の効率を向上させる可能性があります。
コンピュータ使用機能によるタスクの自動化
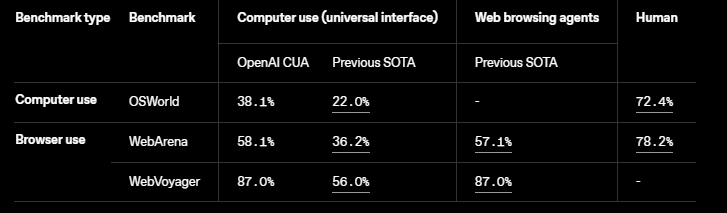
OpenAIのコンピュータ使用エージェント(CUA)モデルは、Operator製品を支えるもので、エージェントがマウスやキーボードのアクションを生成できるようにします。これにより、データエントリやアプリのワークフロー、ウェブサイトのナビゲーションのようなタスクを自動化できます。
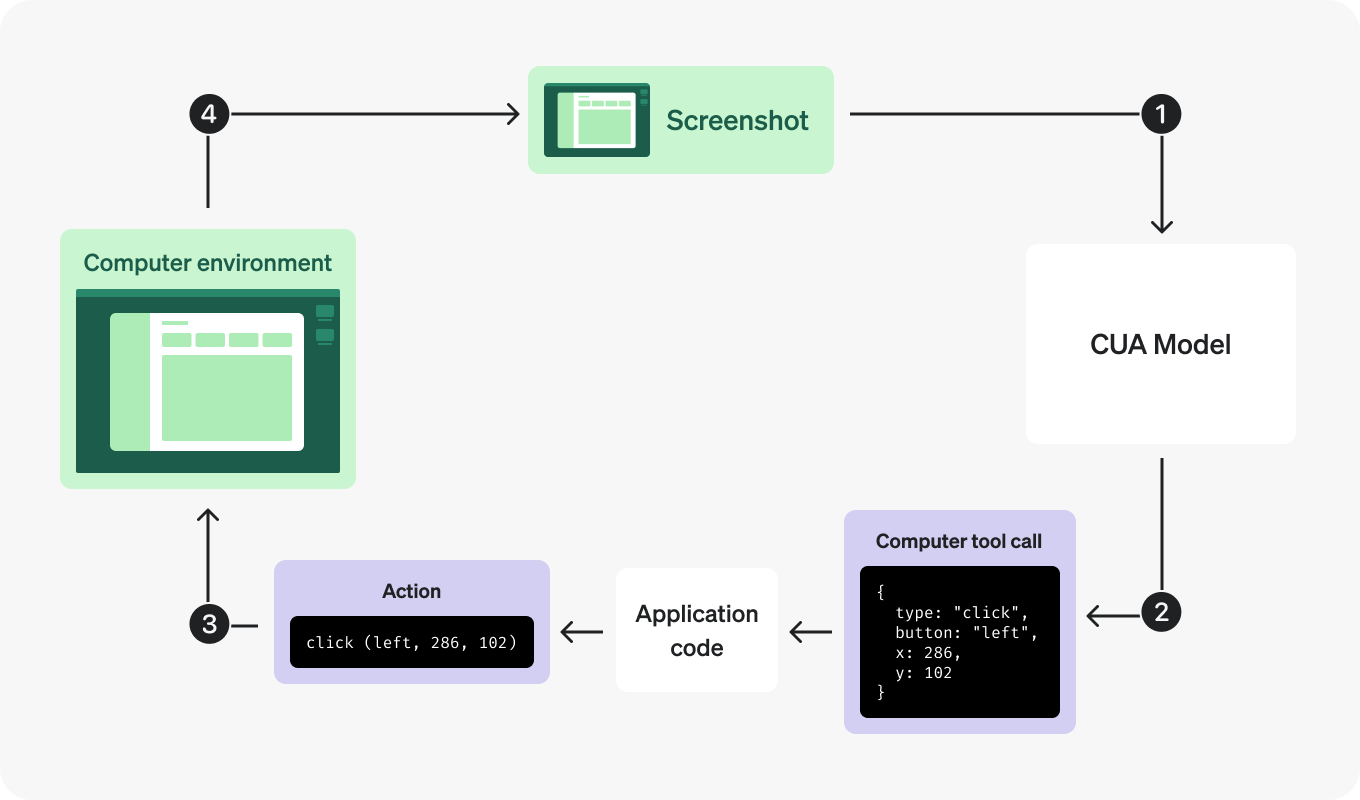
このツールは現在リサーチプレビュー中ですが、開発者にとってはすでに有望です。ドキュメントでその機能を探ることができます。Operatorで利用可能なCUAの消費者版はウェブベースのアクションに焦点を当てていますが、企業はより広範なアプリケーションのためにローカルで実行できます。
始めるための手順は以下の通りです:
- プレビューにアクセスする: CUAモデルをテストするためにリサーチプレビューにサインアップします。
- タスクを定義する: エージェントに特定のコンピュータタスク、例えばフォームを記入したりボタンをクリックしたりするようにプログラムします。
- パフォーマンスを監視する: OpenAIのツールを使用して、エージェントのアクションをデバッグし最適化します。
反復的な事務作業、たとえばスプレッドシートの更新や会議のスケジュールを自動化するエージェントを構築することを想像してみてください。コンピュータ使用機能を使用すれば、エージェントはこれらのタスクを自律的に処理し、人間の労働者をよりクリエイティブな仕事に解放することができます。
1. モデルにリクエストを送信する
まず、OpenAIキーを設定する必要があるかもしれません。
import openai
import os
# APIキーを設定
openai.api_key = os.environ.get("OPENAI_API_KEY")
コンピュータ使用プレビュー モデルを使って、環境に関する詳細と初期入力プロンプトを含めたResponseを作成するリクエストを送信します。
オプションで、環境の初期状態のスクリーンショットを含めることもできます。
computer_use_previewツールを使用するには、truncationパラメーターを"auto"に設定する必要があります(デフォルトではトランケーションは無効です)。
from openai import OpenAI
client = OpenAI()
response = client.responses.create(
model="computer-use-preview",
tools=[{
"type": "computer_use_preview",
"display_width": 1024,
"display_height": 768,
"environment": "browser" # 他の可能な値: "mac", "windows", "ubuntu"
}],
input=[
{
"role": "user",
"content": "bing.comで最新のOpenAIニュースをチェックしてください。"
}
# オプション:環境の初期状態のスクリーンショットを含める
# {
# type: "input_image",
# image_url: f"data:image/png;base64,{screenshot_base64}"
# }
],
truncation="auto"
)
print(response.output)2. 提案されたアクションを受け取る
モデルは、会話の状態に応じて、computer_callアイテム、ただのテキスト、または他のツール呼び出しを含む出力を返します。
computer_callアイテムの例は、クリック、スクロール、キー入力、またはAPIリファレンスで定義された他のイベントです。この例では、アイテムはクリックアクションです:
"output": [
{
"type": "reasoning",
"id": "rs_67cc...",
"content": []
},
{
"type": "computer_call",
"id": "cu_67cc...",
"call_id": "call_zw3...",
"action": {
"type": "click",
"button": "left",
"x": 156,
"y": 50
},
"pending_safety_checks": [],
"status": "completed"
}
]モデルは、一部のアクションについてレスポンス出力にreasoningアイテムを返すことがあります。もしそうした場合、次のリクエストをCUAモデルに送信する際には、常に推論アイテムを含めるべきです。
推論アイテムは、それを生成したモデルとだけ互換性があります。複数のモデルを同じ会話履歴で使用するフローを実装する場合は、他のモデルに送信する入力配列からこれらの推論アイテムをフィルタリングする必要があります。
3. 環境内でアクションを実行する
コンピュータまたはブラウザ上で対応するアクションを実行します。コンピュータ呼び出しをコードを通じてアクションにマッピングする方法は、環境に依存します。このコードは、最も一般的なコンピュータアクションの例を示しています。
def handle_model_action(page, action):
"""
与えられたコンピュータアクション(例:クリック、ダブルクリック、スクロールなど)に対して、
Playwrightページ上で対応する操作を実行します。
"""
action_type = action.type
try:
match action_type:
case "click":
x, y = action.x, action.y
button = action.button
print(f"アクション: ({x}, {y})でボタン'{button}'でクリック")
# 中クリックなどの処理を行っていません。
if button != "left" and button != "right":
button = "left"
page.mouse.click(x, y, button=button)
case "scroll":
x, y = action.x, action.y
scroll_x, scroll_y = action.scroll_x, action.scroll_y
print(f"アクション: ({x}, {y})でスクロール(スクロールオフセット: scroll_x={scroll_x}, scroll_y={scroll_y})")
page.mouse.move(x, y)
page.evaluate(f"window.scrollBy({scroll_x}, {scroll_y})")
case "keypress":
keys = action.keys
for k in keys:
print(f"アクション: キー入力'{k}'")
# 一般的なキーのための簡単なマッピング; 必要に応じて拡張。
if k.lower() == "enter":
page.keyboard.press("Enter")
elif k.lower() == "space":
page.keyboard.press(" ")
else:
page.keyboard.press(k)
case "type":
text = action.text
print(f"アクション: テキストを入力: {text}")
page.keyboard.type(text)
case "wait":
print(f"アクション: 待機")
time.sleep(2)
case "screenshot":
# 各ターンでスクリーンショットが撮られるため、何もする必要はありません。
print(f"アクション: スクリーンショット")
# ここで他のアクションを処理
case _:
print(f"認識されないアクション: {action}")
except Exception as e:
print(f"アクション{action}の処理中にエラーが発生: {e}")4. 更新されたスクリーンショットをキャプチャする
アクションを実行した後、環境の更新された状態をスクリーンショットとしてキャプチャします。このステップは環境によって異なります。
def get_screenshot(page):
"""
Playwrightを使用してフルページのスクリーンショットを撮り、画像バイトを返します。
"""
return page.screenshot()5. 繰り返す
スクリーンショットを取得したら、それをcomputer_call_outputとしてモデルに返送し、次のアクションを取得できます。computer_callアイテムがレスポンスに含まれる限り、これらの手順を繰り返します。
import time
import base64
from openai import OpenAI
client = OpenAI()
def computer_use_loop(instance, response):
"""
'computer_call'が見つかるまでコンピュータアクションを実行するループを実行します。
"""
while True:
computer_calls = [item for item in response.output if item.type == "computer_call"]
if not computer_calls:
print("コンピュータ呼び出しが見つかりませんでした。モデルの出力:");
for item in response.output:
print(item)
break # コンピュータ呼び出しが発行されない場合、終了します。
# 当たり前のことですが、レスポンスごとに最大1つのコンピュータ呼び出しを期待します。
computer_call = computer_calls[0]
last_call_id = computer_call.call_id
action = computer_call.action
# アクションを実行する(ステップ3で定義の関数)
handle_model_action(instance, action)
time.sleep(1) # 変更が適用されるまで待機します。
# アクション後のスクリーンショットを撮ります(ステップ4で定義の関数)
screenshot_bytes = get_screenshot(instance)
screenshot_base64 = base64.b64encode(screenshot_bytes).decode("utf-8")
# スクリーンショットをコンピュータ呼び出し出力として返送します。
response = client.responses.create(
model="computer-use-preview",
previous_response_id=response.id,
tools=[
{
"type": "computer_use_preview",
"display_width": 1024,
"display_height": 768,
"environment": "browser"
}
],
input=[
{
"call_id": last_call_id,
"type": "computer_call_output",
"output": {
"type": "input_image",
"image_url": f"data:image/png;base64,{screenshot_base64}"
}
}
],
truncation="auto"
)
return responseエージェントSDKを使用したエージェントの調整
OpenAIのマルチエージェントワークフローを構築および管理するためのオープンソースツールキット。このSDKは、OpenAIの以前のフレームワークSwarmを基に構築されており、モデルを統合し、セーフガードを実装し、エージェントの活動を監視するための無料ツールを開発者に提供します。
Agents SDKは、Pythonを優先的に使用し、組み込みのエージェントループや安全チェックなどの機能を含んでいます。複数のエージェントが一緒に問題を解決するような複雑なシステムを作成するのに最適です。
Agents SDKの使用方法は以下の通りです:
- SDKをダウンロードする: OpenAIのGitHubリポジトリからオープンソースコードにアクセスします。
- マルチエージェントワークフローを設定: SDKを使用してエージェント間のタスクを調整し、各エージェントの能力に応じて委任します。
- セーフガードを追加: エージェントが責任を持って信頼性高く動作することを保証するために、安全チェックを実装します。
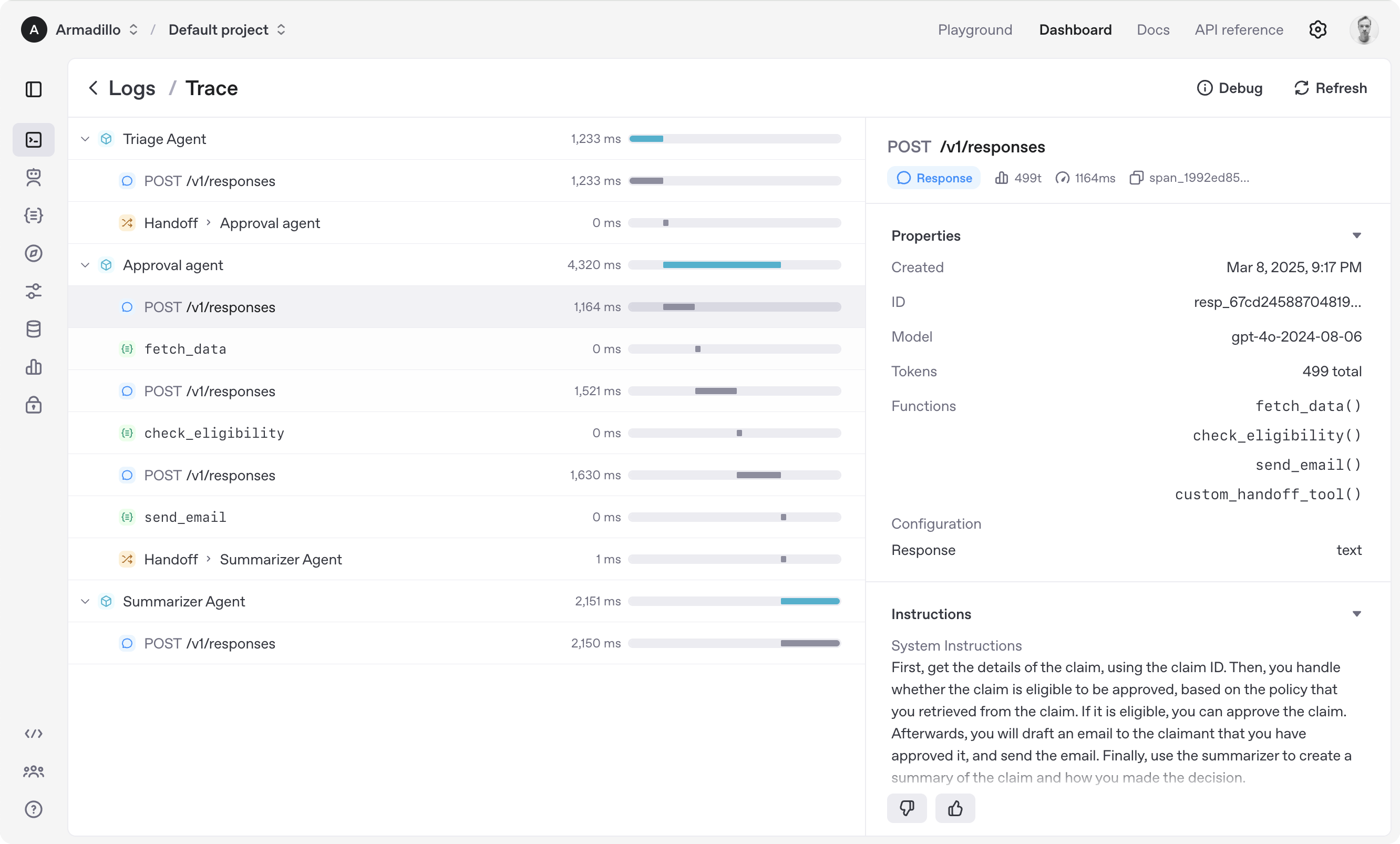
たとえば、1つのエージェントがウェブリサーチを行い、別のエージェントがファイルを管理し、3つ目がコンピュータタスクを自動化するAIエージェントの営業チームを構築することができます。Agents SDKはそれらを結びつけ、シームレスで効率的なシステムを作り出します。
結論
Responses APIからウェブ検索、ファイル検索、コンピュータ使用、Agents SDKまで、OpenAIは開発者に自律的な知的システムを構築するために必要なすべてのツールを提供しています。ビジネスタスクの自動化、カスタマーサービスの強化、または新しい研究のフロンティアを探求するにあたって、これらのツールは可能性の広がりを開きます。
さあ、何を待っていますか?OpenAI APIに飛び込み、彼らの新しいツールを試し、ユーザーを驚かせるエージェントの構築を始めましょう。そして、API開発をスムーズにするために、無料でApidogをダウンロードするのを忘れないでください!


