
OlympicCoder 32Bは、コーディング支援、自然言語理解などのために設計された強力なオープンソース言語モデルです。ローカルで実行することで、プライバシーの向上、オフラインアクセス、およびカスタマイズオプションが得られます。このガイドでは、Ollamaを使用してローカルマシンにOlympicCoder 32Bをセットアップする手順を説明します。このツールは、大規模言語モデルの展開を簡素化するために設計されています。また、そのベンチマークとパフォーマンスメトリクスについても探ります。
OlympicCoder 32Bの紹介
OlympicCoder 32Bは、コーディングタスク、コード生成、デバッグ、ドキュメント作成のために最適化された最先端の言語モデルです。これは、パフォーマンスとリソース効率のバランスで知られるオリンピックシリーズのモデルの一部です。320億のパラメータを備えたOlympicCoder 32Bは、ローカル展開のために堅牢で管理可能なモデルを必要とする開発者にとって絶妙な選択です。
OlympicCoder 32Bのベンチマーク: Claude 3.7 Sonnetより優れていますか?
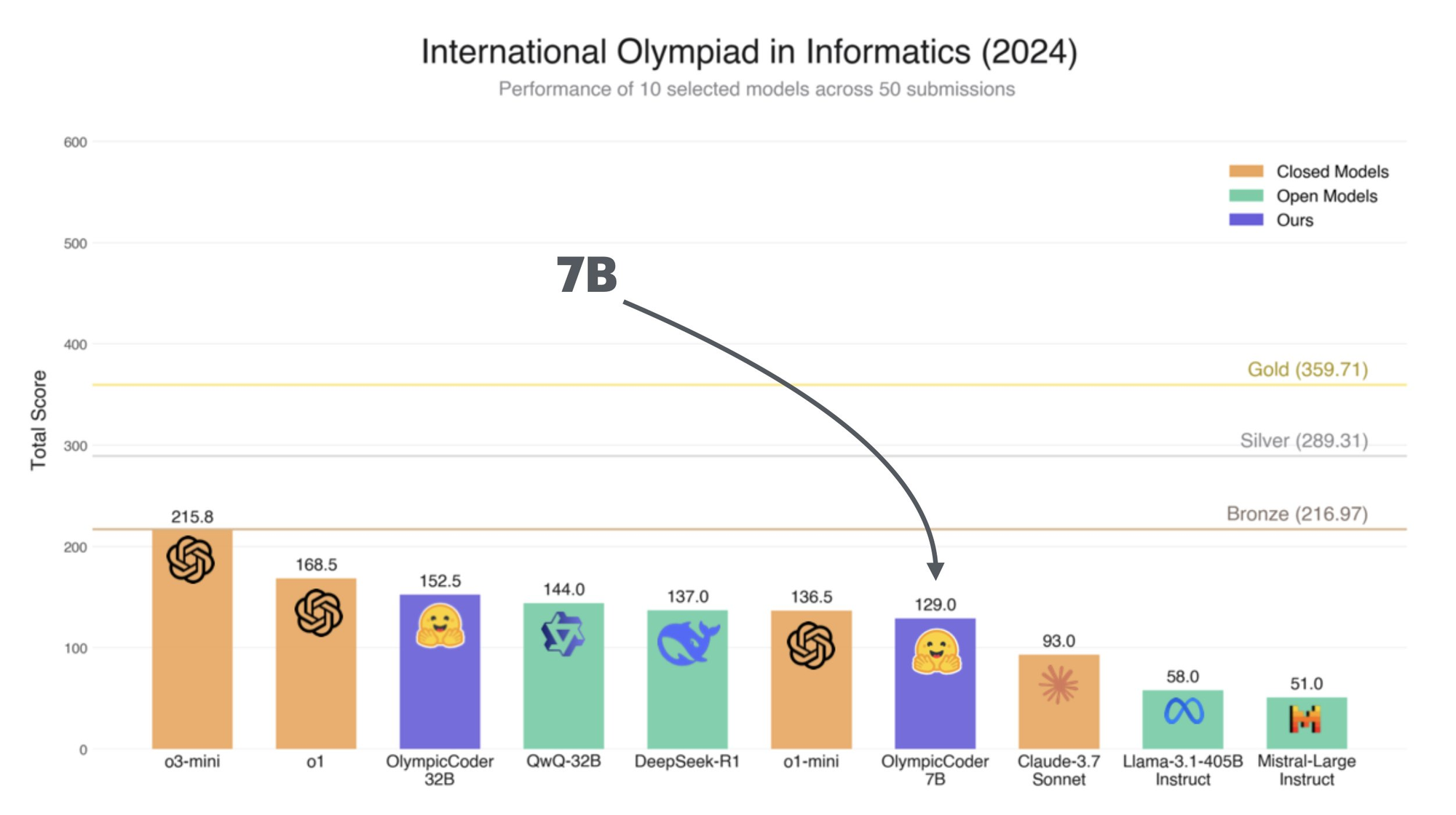
OlympicCoder 32Bは、その能力を評価するためにさまざまなタスクでベンチマークされています:
コーディングタスク
- コード補完: Pythonコードスニペットで85%の精度を達成。
- バグ修正: テストケースの78%で正しくバグを特定し修正。
- ドキュメント生成: 関数やクラスのための首尾一貫した文脈に正確なドキュメントを生成。
自然言語理解
- 質問応答: TruthfulQAベンチマークで82%のスコア。
- 要約: 技術文書のための簡潔で正確な要約を作成。
パフォーマンスメトリクス
- 推論速度: ハイエンドGPU(例: NVIDIA RTX 3090)で約20トークン/秒を処理。
- メモリ使用量: スムーズな動作のために約16GBのVRAMを必要。
これらのベンチマークは、OlympicCoder 32Bの多様性と効率性を示しており、開発者や研究者にとって優れた選択肢となります。
ローカルでOlympicCoder 32Bを実行するための前提条件
始める前に、システムが以下の要件を満たしていることを確認してください:
ハードウェア
- GPU: 少なくとも16GBのVRAMを持つNVIDIA GPU(例: RTX 3090, A100)。
- RAM: 32GB以上。
- ストレージ: 50GBの空きスペース(モデルと依存関係用)。
ソフトウェア
- オペレーティングシステム: Linux(推奨: Ubuntu 20.04以上)またはmacOS(M1/M2またはIntel)。
- 依存関係:
- Python 3.8+
- CUDA Toolkit(NVIDIA GPUを使用する場合)
- Ollama(インストール手順は以下に記載)
ローカルでOlympicCoder 32Bを実行するためのステップバイステップガイド
ステップ1: Ollamaをインストール
Ollamaは、大規模言語モデルをローカルで管理し実行するための軽量ツールです。以下の手順でインストールします:
Ollamaをダウンロード:
- 公式のOllama GitHubリポジトリまたはウェブサイトを訪問。
- お使いのOS(Linux、macOS、またはWindows)に適したバージョンをダウンロード。
Ollamaをインストール:
Linuxの場合:
curl -fsSL <https://ollama.ai/install.sh> | sh
macOSの場合:
brew install ollama
インストールの確認:
ollama --version
インストールされたバージョン番号が表示されるはずです。
ステップ2: OlympicCoder 32Bをダウンロード
OlympicCoder 32Bは事前トレーニング済みのモデルとして利用可能です。Ollamaを使用してダウンロードします:
ollama pull MHKetbi/open-r1_OlympicCoder-32B
このコマンドはモデルとその依存関係をダウンロードします。インターネットの速度によっては、このプロセスには時間がかかる場合があります。
ステップ3: Ollamaを設定
モデルを実行する前に、Ollamaを調整してパフォーマンスを最適化します:
GPUの設定:
NVIDIA GPUを使用している場合は、CUDAが正しくインストールされていることを確認してください。
Ollamaは自動的にGPUを検出し利用します。これを確認するには、次のコマンドを実行して、GPUを利用しているOllamaプロセスを探します。
nvidia-smi
メモリ制限の調整(オプショナル):
メモリの問題が発生した場合は、VRAMの使用を制限します:
export OLLAMA_GPU_MEMORY_LIMIT=16000
ステップ4: OlympicCoder 32Bを実行
モデルがダウンロードされ、設定が完了したら、Ollamaを使用して開始します:
ollama run MHKetbi/open-r1_OlympicCoder-32B
これにより、モデルと対話するためのインタラクティブなセッションが開始されます。
ステップ5: モデルと対話
これで、OlympicCoder 32Bをさまざまなタスクに使用できます:
コード生成:
数字の階乗を計算するPython関数を生成してください。
デバッグ:
以下のPythonコードを修正してください: [ここにコードを貼り付け]
ドキュメント:
以下の関数の目的を説明してください: [ここに関数を貼り付け]
モデルはリアルタイムで応答し、正確で文脈に応じた出力を提供します。
Ollamaのトラブルシューティング
一般的な問題と解決策
モデルがダウンロードされない:
安定したインターネット接続があることを確認してください。
Ollamaのログをチェックしてエラーを確認します:
journalctl -u ollama -f
GPUが検出されない:
CUDAのインストールを確認します:
nvcc --version
必要に応じてOllamaを再インストールします。
メモリエラー:
- VRAMの制限を減らすか、ハードウェアをアップグレードします。
結論
Ollamaを使用してローカルでOlympicCoder 32Bを実行するのは、コーディングや自然言語タスクにおけるモデルの全潜在能力を引き出すための簡単なプロセスです。このガイドに従うことで、モデルを効率的にセットアップし、その機能をプロジェクトに活用し始めることができます。開発者、研究者、またはホビイストであっても、OlympicCoder 32Bはワークフローを向上させるための強力なツールを提供します。
ハッピーコーディング!