
大規模言語モデル(LLM)をローカルで実行することは、かつては熱心なCLIユーザーやシステムいじりの専門分野でした。しかし、それは急速に変化しています。ローカルマシンでオープンソースLLMを実行するためのシンプルなコマンドラインインターフェースで知られるOllamaが、macOSおよびWindows用のネイティブデスクトップアプリをリリースしました。
そして、それらは単なる基本的なラッパーではありません。これらのアプリは、モデルとのチャット、ドキュメント分析、ドキュメント作成、さらには画像との連携を開発者にとって劇的に容易にする強力な機能をもたらします。
この記事では、新しいデスクトップエクスペリエンスが開発者のワークフローをどのように改善するか、どのような機能が際立っているか、そしてこれらのツールが日常のコーディング生活で実際にどこで輝くかを探ります。
ローカルLLMが依然として重要である理由
ChatGPT、Claude、Geminiのようなクラウドベースのツールが話題を独占する一方で、ローカルファーストのAI開発への動きが広まっています。開発者は次のようなツールを求めています。
- プライベート - コードとドキュメントはマシン上に留まります。
- カスタマイズ可能 - モデル、メモリ制限、ハードウェアを選択できます。
- オフライン対応 - 外部APIや稼働時間に依存しません。
- 高速 - ネットワーク遅延やサーバーのボトルネックがありません。
Ollamaはこのトレンドに直接対応し、LLaMA、Mistral、Gemma、Codellama、Mixtralなどのモデルをマシン上でネイティブに実行できるようにします。そして、はるかにスムーズな体験を提供します。
ステップ1:デスクトップ版Ollamaをダウンロードする
ollama.comにアクセスし、お使いのシステム用の最新バージョンをダウンロードしてください。
- macOS (Apple SiliconまたはIntel)
- Windows 10/11 (x64)
通常のデスクトップアプリと同様にインストールしてください。開始するためにコマンドラインの設定は必要ありません。
ステップ2:起動してモデルを選択する
インストール後、Ollamaデスクトップアプリを開きます。インターフェースはすっきりとしており、シンプルなチャットウィンドウのように見えます。
ダウンロードして実行するモデルを選択するよう促されます。いくつかのオプションは次のとおりです。
llama3– 汎用アシスタントcodellama– コード生成とリファクタリングに最適mistral– 高速、小型、高精度gemma– Googleが支援するオープンウェイトモデル
1つを選択すると、アプリが自動的にダウンロードしてロードします。
開発者向けのスムーズなオンボーディング - モデルとチャットするより簡単な方法
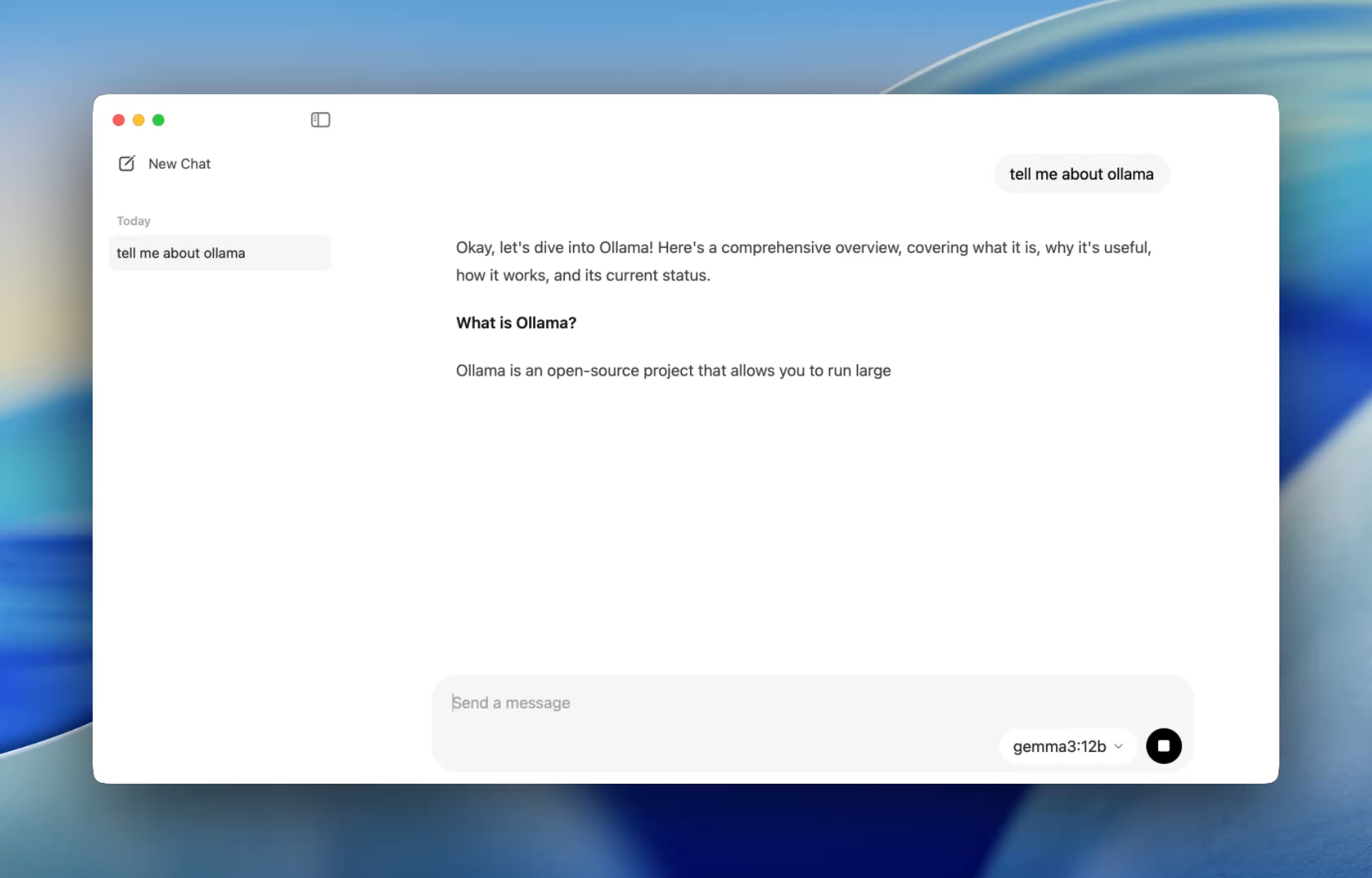
以前は、Ollamaを使用するにはターミナルを起動し、ollama runコマンドを発行してモデルセッションを開始する必要がありました。しかし今では、デスクトップアプリは他のネイティブアプリケーションと同様に開き、シンプルでクリーンなチャットインターフェースを提供します。
ChatGPTと同じようにモデルと会話できるようになりました。しかも完全にオフラインで。これは次のような場合に最適です。
- コードレビューの支援
- テスト生成
- リファクタリングのヒント
- 新しいAPIや言語の学習
このアプリは、簡単なインストール以外に設定不要で、codellamaやmistralのようなローカルモデルにすぐにアクセスできるようにします。
そして、カスタマイズを好む開発者向けには、必要に応じてターミナル経由でコンテキスト長、システムプロンプト、モデルバージョンを切り替えることができるCLIが舞台裏で機能し続けています。
ドラッグ、ドロップ、質問:
ファイルとチャット
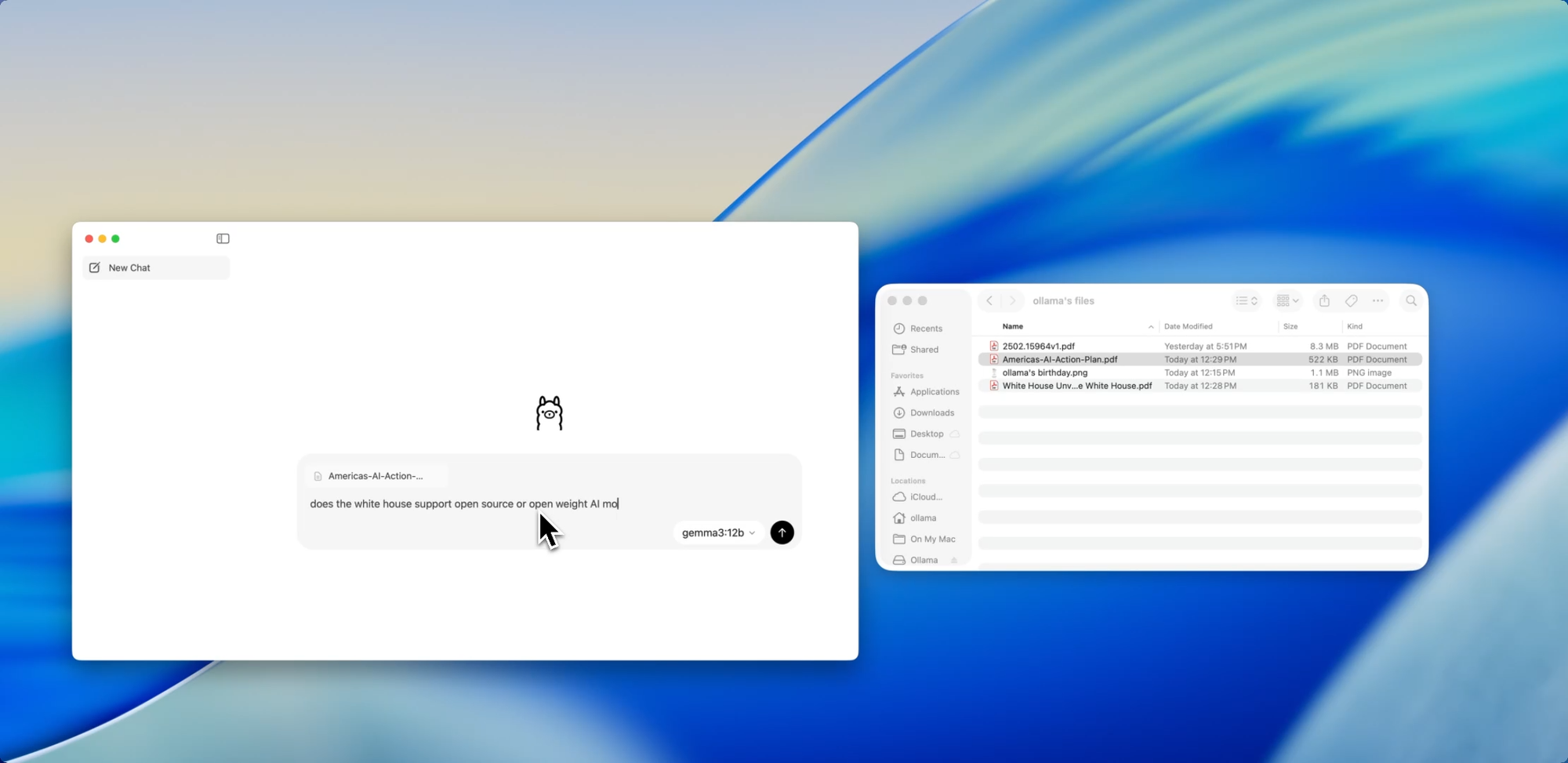
新しいアプリで最も開発者に優しい機能の1つは、ファイル取り込みです。.pdf、.md、.txtのいずれであっても、ファイルをチャットウィンドウにドラッグするだけで、モデルがその内容を読み取ります。
60ページの設計ドキュメントを理解する必要がありますか?乱雑なREADMEからTODOを抽出したいですか?それともクライアントの製品概要を要約したいですか?ファイルをドロップして、次のような自然言語の質問をしてください。
- 「このドキュメントで議論されている主な機能は何ですか?」
- 「これを1つの段落で要約してください。」
- 「欠落しているセクションや矛盾はありますか?」
この機能は、ドキュメントのスキャン、仕様のレビュー、新しいプロジェクトへのオンボーディングにかかる時間を劇的に短縮できます。
テキストを超えて
マルチモーダル対応
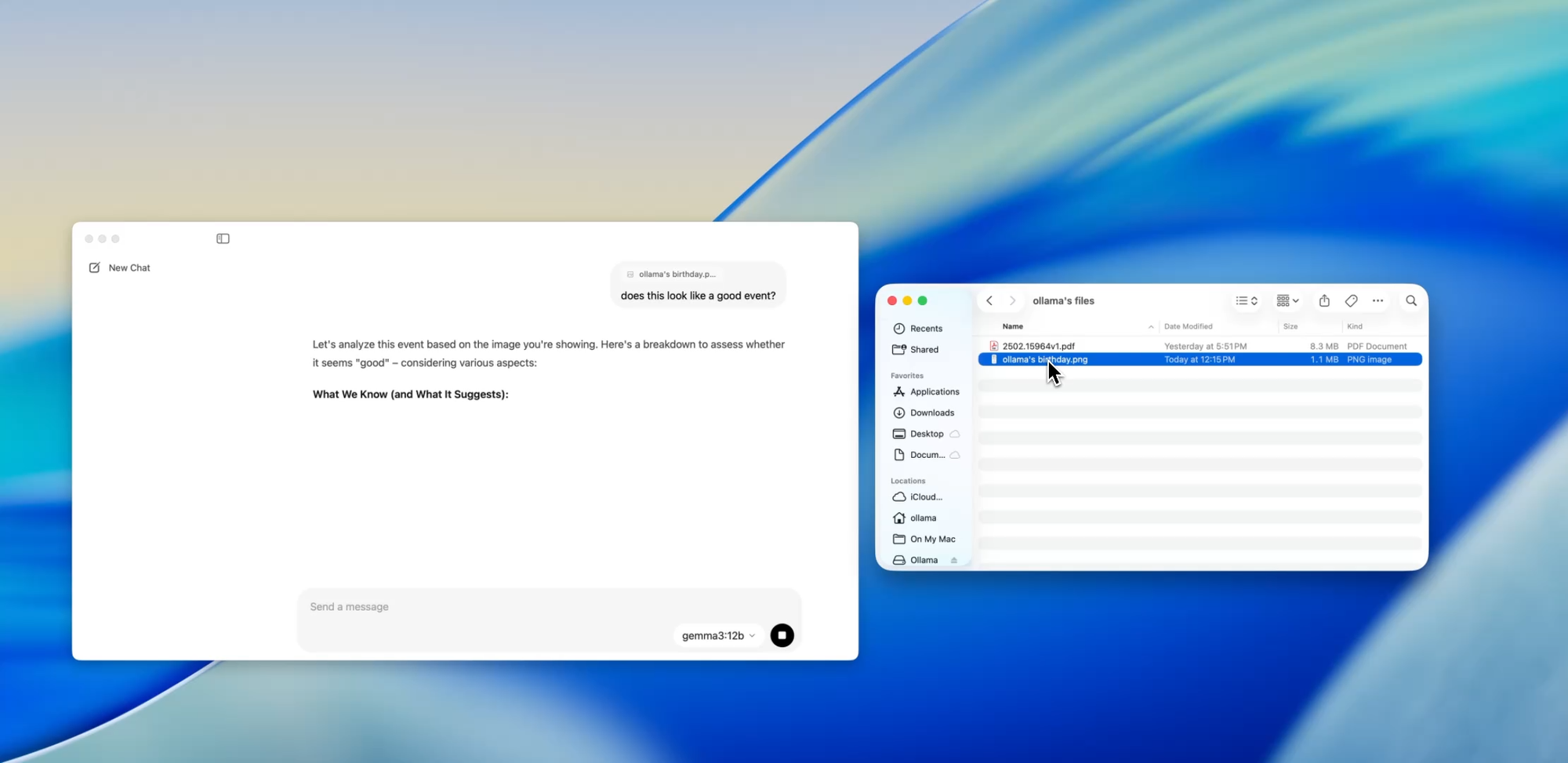
Ollama内の特定のモデル(Llavaベースのモデルなど)は、現在画像入力をサポートしています。つまり、画像をアップロードすると、モデルがそれを解釈して応答します。
いくつかのユースケースは次のとおりです。
- スクリーンショットから図やグラフを読み取る
- UIモックアップを記述する
- スキャンされた手書きメモを確認する
- シンプルなインフォグラフィックを分析する
GPT-4 Visionのようなツールと比較するとまだ初期段階ですが、ローカルファーストのアプリにマルチモーダルサポートが組み込まれていることは、マルチ入力システムを構築したりAIインターフェースをテストしたりする開発者にとって大きな一歩です。
プライベートなローカルドキュメント — コマンド一つで
ドキュメント作成
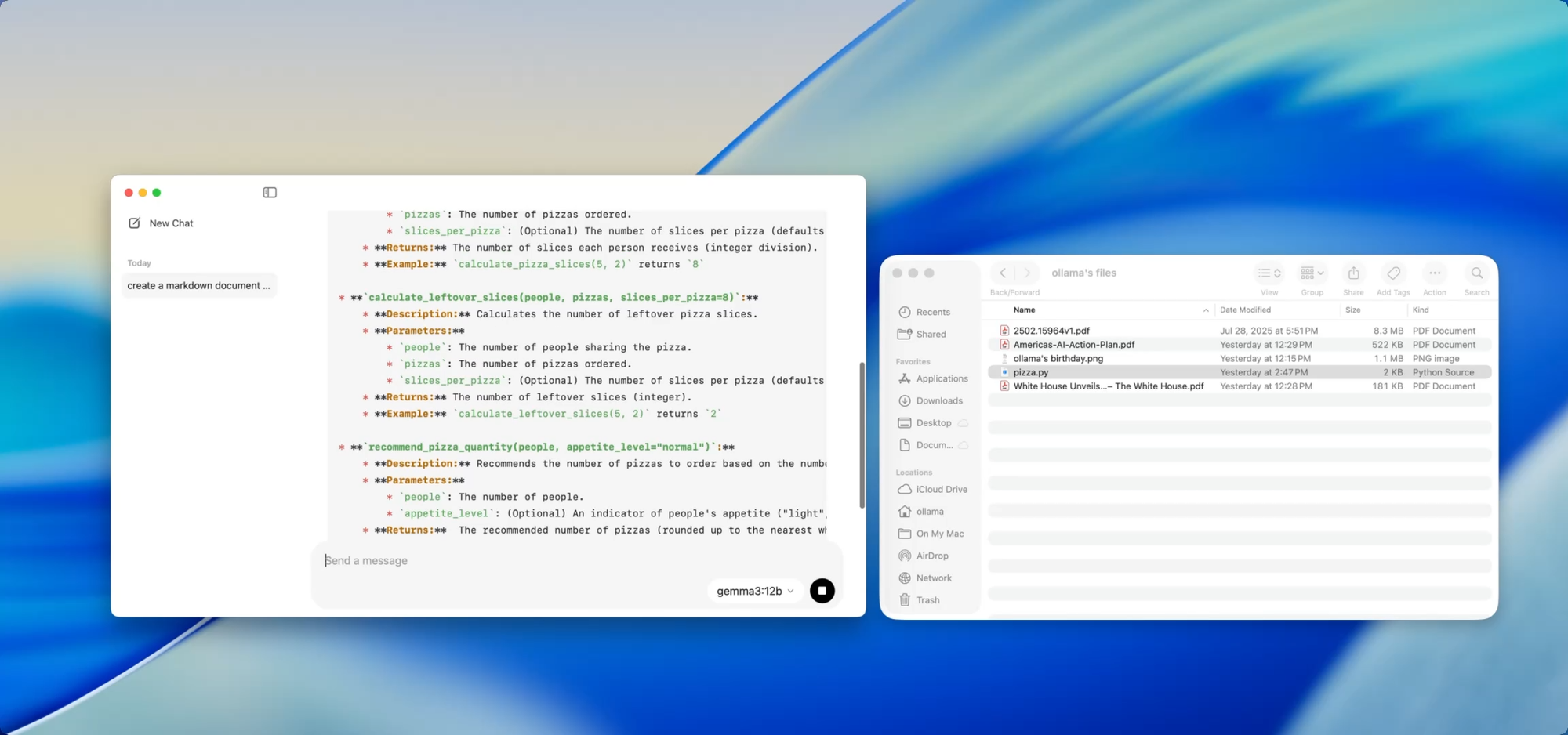
成長するコードベースを維持しているなら、ドキュメントの乖離の苦痛を知っているでしょう。Ollamaを使えば、機密性の高いコードをクラウドにプッシュすることなく、ローカルモデルを使用してドキュメントを生成または更新できます。
例えばutils.pyのようなファイルをアプリにドラッグして、次のように尋ねるだけです。
- 「これらの関数のdocstringを書いてください。」
- 「このファイルが何をするかのMarkdown概要を作成してください。」
- 「このモジュールはどの依存関係を使用していますか?」
これは、AIを使用してドキュメントワークフローを自動化する[Deepdocs]のようなツールと組み合わせると、さらに強力になります。プロジェクトのREADMEやスキーマファイルを事前にロードし、その後に質問をしたり、変更ログ、移行ノート、更新ガイドを生成したりできます — すべてローカルで。
内部でのパフォーマンスチューニング
この新しいリリースにより、Ollamaは全体的なパフォーマンスも向上させました。
- GPUアクセラレーションは、Apple Siliconおよび最新のNvidia/AMDカード向けに最適化されています。
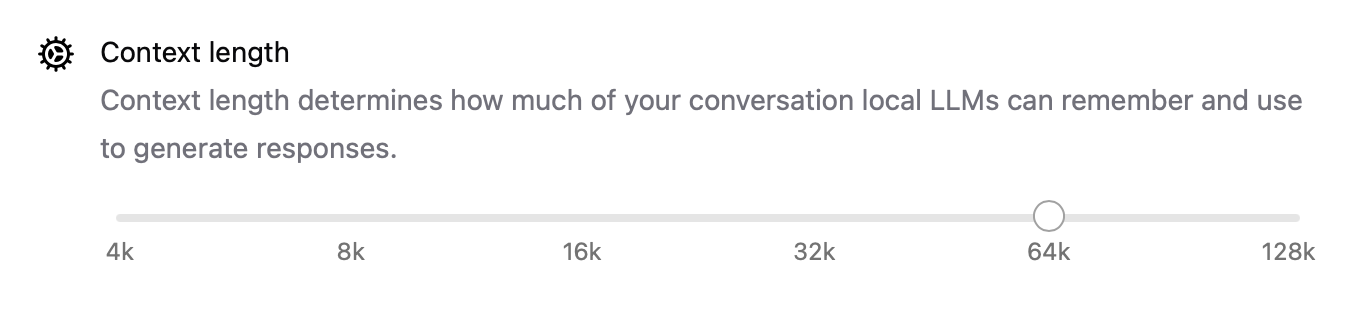
- コンテキスト長は
num_ctx=8192のような設定で構成可能になり、より長い入力を処理できます。 - ネットワークモードにより、OllamaをLAN上の他のアプリやデバイスから呼び出せるローカルAPIサーバーとして実行できます。
- ダウンロードしたモデルの 保存場所を変更 できるようになりました — 外部ドライブから作業している場合や、プロジェクトごとにモデルを分離したい場合に最適です。
これらのアップグレードにより、このアプリはローカルエージェントから開発ツール、個人的な研究アシスタントまで、あらゆる用途に柔軟に対応できます。
CLIとGUI:両方の良いとこ取り
最高の点は?新しいデスクトップアプリはターミナルを置き換えるものではなく、補完するものです。
次のことも可能です。
ollama pull codellama
ollama run codellama
またはモデルサーバーを公開します。
ollama serve --host 0.0.0.0
したがって、ローカルLLMに依存するカスタムAIインターフェース、エージェント、またはプラグインを構築している場合、OllamaのAPI上に構築し、直接的な対話やテストにGUIを使用できるようになりました。
ApidogでOllamaのAPIをローカルでテストする
OllamaをAIアプリに統合したり、ローカルAPIエンドポイントをテストしたいですか?OllamaのREST APIを次のように起動できます。
ollama serveその後、Apidogを使用して、ローカルLLMエンドポイントをテスト、デバッグ、ドキュメント化します。

OllamaでApidogを使用する理由:
- ローカルの
http://localhost:11434サーバーにPOSTリクエストを送信するためのビジュアルインターフェース - AI支援によるリクエスト生成とレスポンス検証をサポート
- セルフホスト型AIアプリ、エージェントフレームワーク、または社内ツールに最適
- ローカルLLMワークフローおよびカスタムモデルサーバーとシームレスに連携
実際に機能する開発者のユースケース
新しいOllamaアプリが実際の開発ワークフローで輝くのは次のとおりです。
| ユースケース | Ollamaがどのように役立つか |
|---|---|
| コードレビューアシスタント | リファクタリングのフィードバックのためにcodellamaをローカルで実行 |
| ドキュメントの更新 | モデルにドキュメントファイルの書き換え、要約、修正を依頼 |
| ローカル開発チャットボット | コンテキストを認識するアシスタントとしてアプリに組み込む |
| オフライン研究ツール | PDFやホワイトペーパーをロードして重要な質問をする |
| 個人用LLMプレイグラウンド | プロンプトエンジニアリングとファインチューニングを試す |
データプライバシーやモデルの幻覚を懸念するチームにとって、ローカルファーストのLLMワークフローは、ますます魅力的な代替手段を提供します。
最後に
Ollamaのデスクトップ版は、ローカルLLMをハッキングのような科学実験ではなく、洗練された開発者ツールのように感じさせます。
ファイル操作、マルチモーダル入力、ドキュメント作成、ネイティブパフォーマンスのサポートにより、速度、柔軟性、制御を重視する開発者にとって真剣な選択肢となります。
クラウドAPIキーは不要。バックグラウンド追跡もなし。トークンごとの課金もなし。必要なオープンモデルを自由に選択できる、高速なローカル推論のみです。
マシンでLLMを実行することに興味があった方、またはすでにOllamaを使用しており、よりスムーズな体験を求めている方は、今こそもう一度試す時です。


