
Mistral AIのエンジニアは、推論効率を最優先した240億パラメータモデルとしてMagistral Small 1.2を設計しました。このバージョンは、Mistral Small 1.1を直接基盤としています。エンジニアは、Magistral Mediumのトレースを使用した教師ありファインチューニングを適用し、その後、強化学習の段階を経て開発しました。その結果、このモデルは過度な計算負荷なしに多段階の論理処理に優れています。
Magistralモデルファミリーの進化を理解する
アーキテクチャの基盤と技術仕様
Magistral Small 1.2は、Magistral 1.1の堅牢な基盤の上に構築されており、Magistral Mediumのトレースからの教師ありファインチューニング(SFT)と強化学習(RL)の最適化を組み合わせることで、高度な推論能力を組み込んでいます。Magistral 1.1をベースに、推論能力を追加し、Magistral MediumのトレースからのSFTとRLを重ねることで、240億パラメータを持つ小型で効率的な推論モデルとなっています。

さらに、そのアーキテクチャ設計により、効率的なデプロイメントシナリオが可能になります。Magistral Smallは、量子化されれば単一のRTX 4090または32GB RAMのMacBook内に収まり、ローカルにデプロイできます。このアクセシビリティにより、このモデルは企業環境と個人開発者環境の両方に適しています。
バージョン1.2の主要な技術的強化
バージョン1.1から1.2への移行により、モデルのパフォーマンスとユーザビリティに大きな影響を与えるいくつかの重要な改善が導入されました。特に、これらのアップデートは、機能の境界を拡大しながら、根本的な制限に対処しています。
マルチモーダル統合のブレークスルー
ビジョンエンコーダを搭載したこれらのモデルは、テキストと画像をシームレスに処理します。この統合は、純粋なテキストベースの推論から、包括的なマルチモーダル理解へのパラダイムシフトを表しています。ビジョンエンコーダのアーキテクチャにより、モデルはテキスト推論能力を維持しながら視覚情報を処理できます。
パフォーマンス最適化の結果
AIME 24/25やLiveCodeBench v5/v6などの数学およびコーディングベンチマークで15%の改善が見られました。これらのパフォーマンス向上は、数学的計算、アルゴリズム開発、複雑な問題解決シナリオに取り組む開発者にとって特に有益であり、実用的なアプリケーションに直接つながります。
包括的な機能分析
高度な推論能力
推論アーキテクチャは、モデルの内部推論プロセスを構造化する特殊な思考トークンを組み込んでいます。実装では、[THINK]と[/THINK]トークンを使用して推論内容をカプセル化し、プロンプト処理中の混乱を防ぎながら、モデルの意思決定プロセスに透明性をもたらします。
さらに、推論システムは、最終的な応答を生成する前に、論理的推論の拡張された連鎖を通じて動作します。このアプローチにより、モデルは多段階分析、数学的導出、論理的演繹を必要とする複雑な問題に取り組むことができます。
多言語サポートインフラストラクチャ
これらのモデルは、多様な言語ファミリーにわたる包括的な言語サポートを示しています。サポートされる言語は、英語、フランス語、ドイツ語、ギリシャ語、ヒンディー語、インドネシア語、イタリア語、日本語、韓国語、マレー語、ネパール語、ポーランド語、ポルトガル語、ルーマニア語、ロシア語、セルビア語、スペイン語、トルコ語、ウクライナ語、ベトナム語、アラビア語、ベンガル語、中国語、ペルシア語など、ヨーロッパ、アジア、中東、南アジアの地域に及びます。
さらに、この広範な多言語機能は、グローバルなアクセシビリティを確保し、開発者が異なる言語ごとに個別のモデル実装を必要とせずに、国際市場向けのアプリケーションを作成できるようにします。
ビジョン処理アーキテクチャ
ビジョンエンコーダの統合により、高度な画像分析と推論が可能になります。このモデルは視覚コンテンツを処理し、それをテキスト情報と組み合わせて包括的な応答を生成します。この機能は、単純な画像認識を超えて、文脈理解、空間推論、視覚的な問題解決を含みます。
パフォーマンスベンチマークと比較分析
数学的推論性能
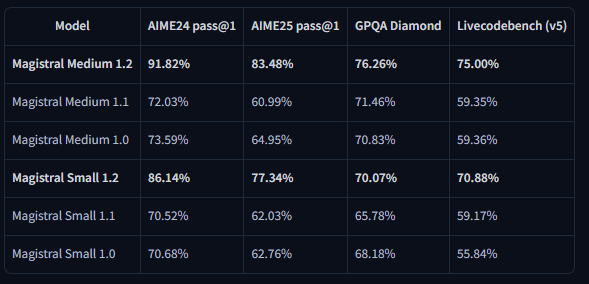
ベンチマーク結果は、主要な評価指標全体で大幅な改善を示しています。Magistral Small 1.2は、AIME24 pass@1で86.14%、AIME25 pass@1で77.34%を達成し、バージョン1.1のそれぞれ70.52%と62.03%を大きく上回る進歩を示しています。
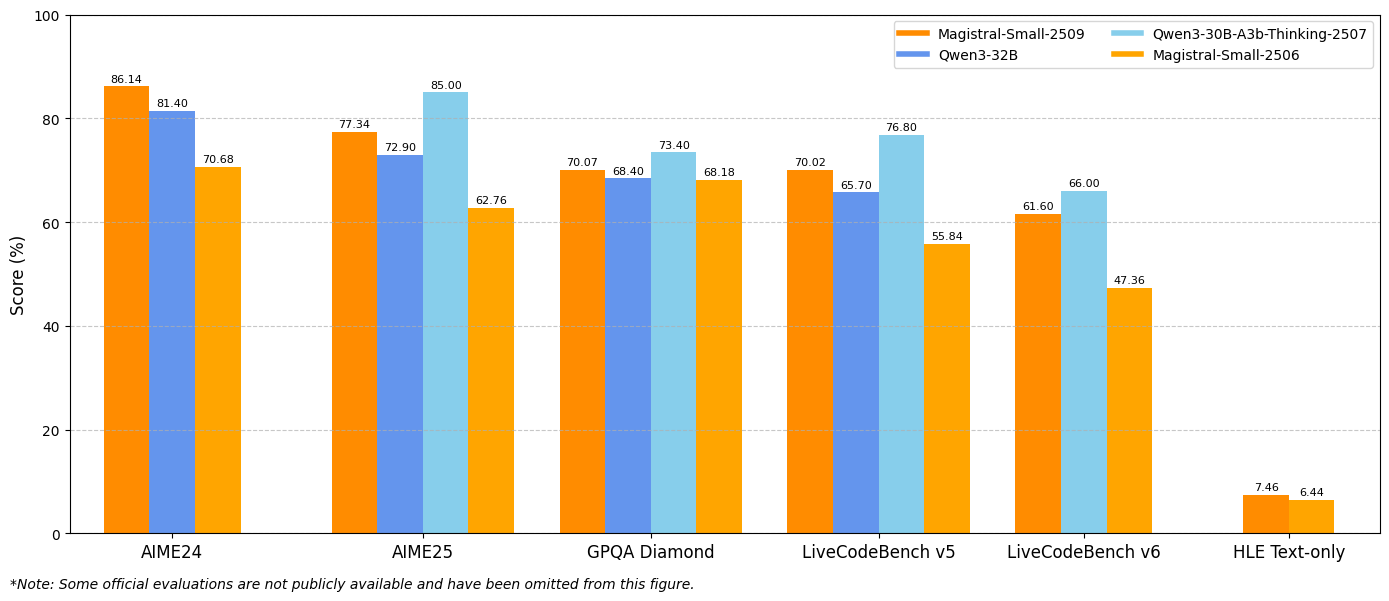
同様に、Magistral Medium 1.2は、AIME24 pass@1で91.82%、AIME25 pass@1で83.48%という卓越したパフォーマンスを発揮し、バージョン1.1の72.03%と60.99%を上回っています。これらの改善は、科学計算、工学アプリケーション、研究環境に直接利益をもたらす数学的推論能力の強化を示しています。
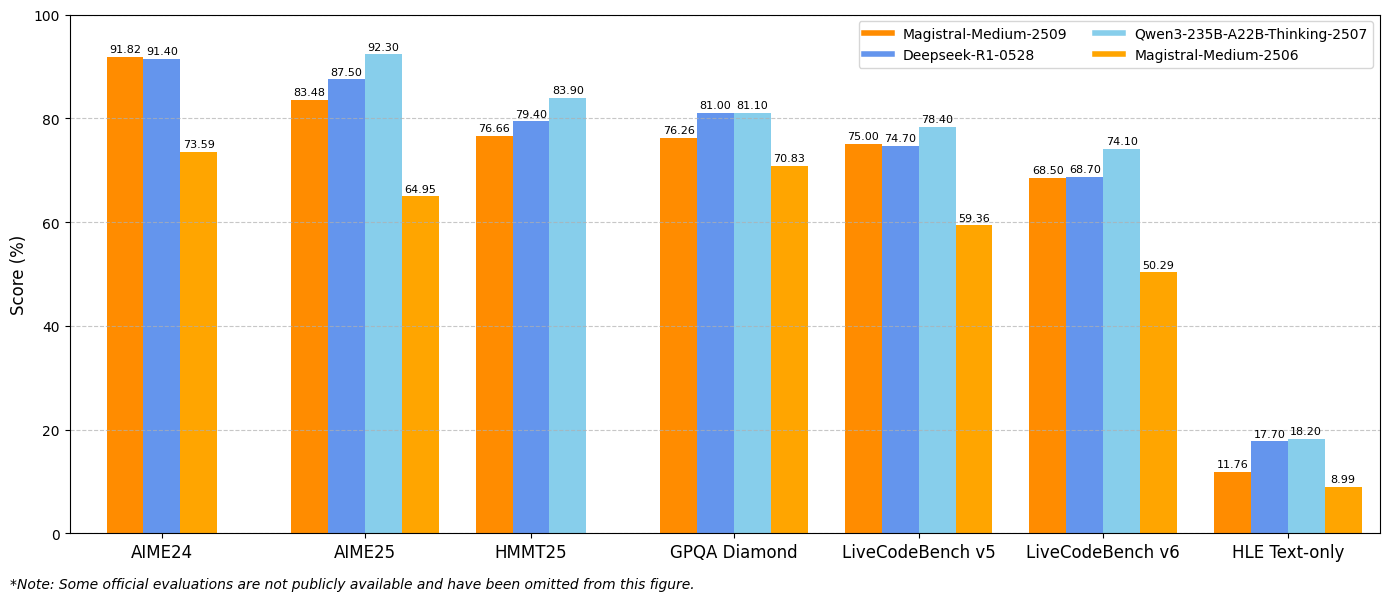
コーディング性能指標
LiveCodeBenchの評価により、コーディング能力の大幅な改善が明らかになりました。Magistral Small 1.2はLiveCodeBench v5で70.88%を記録し、Magistral Medium 1.2は75.00%を達成しました。これらのスコアは、コード生成、デバッグ、アルゴリズム実装タスクにおける有意義な進歩を示しています。
さらに、これらのモデルは、プログラミング概念、ソフトウェアアーキテクチャパターン、およびデバッグ手法の理解が向上していることを示しています。この強化されたコーディング性能は、ソフトウェア開発チーム、自動テストフレームワーク、および教育プログラミング環境に利益をもたらします。
GPQA Diamondの結果
汎用質問応答(GPQA)Diamondベンチマークの結果は、モデルの幅広い知識応用能力を示しています。Magistral Small 1.2は70.07%を達成し、Magistral Medium 1.2は76.26%に達しました。これらのスコアは、学際的な知識と推論を必要とする多様な質問タイプを処理するモデルの能力を反映しています。
実装と統合戦略
開発環境の構成
Magistral Small 1.2とMagistral Medium 1.2の実装には、パフォーマンスを最適化するための特定の技術構成が必要です。推奨されるサンプリングパラメータには、top_p: 0.95、temperature: 0.7、max_tokens: 131072が含まれます。これらの設定は、拡張された推論シーケンスをサポートしながら、創造性と一貫性のバランスを取ります。
さらに、これらのモデルは、vLLM、Transformers、llama.cpp、および特殊な量子化形式を含むさまざまなデプロイメントフレームワークをサポートしています。この柔軟性により、異なるコンピューティング環境やユースケース全体での統合が可能になります。
ApidogとのAPI統合
Apidog は、Magistral APIをアプリケーションにテストおよび統合するための包括的なツールを提供します。このプラットフォームは、マルチモーダル入力処理、推論トレース分析、パフォーマンス監視など、高度なAPIテストシナリオをサポートしています。Apidogのインターフェースを通じて、開発者は画像とテキストの組み合わせを効率的にテストし、推論出力を検証し、API呼び出しパラメータを最適化できます。
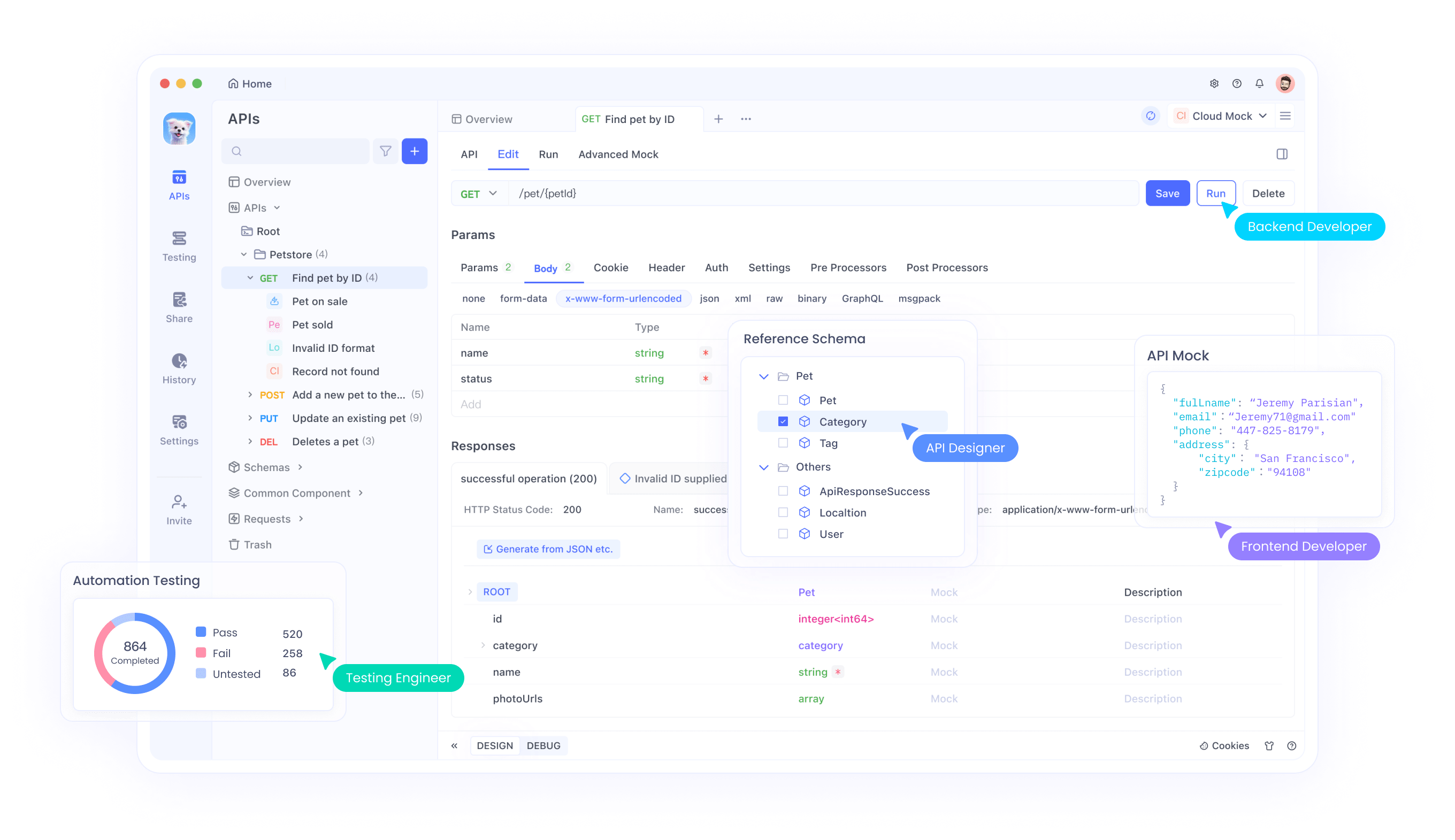
さらに、Apidogのコラボレーション機能により、チームはAPIテスト構成を共有し、統合パターンを文書化し、開発サイクル全体で一貫したテスト標準を維持できます。この共同アプローチは、堅牢なAPI実装を確保しながら、開発タイムラインを加速します。
システムプロンプトの最適化
モデルが最適なパフォーマンスを達成するには、慎重に作成されたシステムプロンプトが必要です。推奨されるシステムプロンプト構造には、推論指示、書式設定ガイドライン、および言語仕様が含まれます。プロンプトは、特殊なトークンを使用して思考プロセスを明示的に要求し、一貫した応答形式を維持する必要があります。
さらに、システムプロンプトのカスタマイズにより、アプリケーション固有の最適化が可能になります。開発者は、特定の推論パターンを強調したり、出力形式を調整したり、ドメイン固有の知識要件を組み込んだりするためにプロンプトを変更できます。
技術実装の詳細
メモリと計算要件
Magistral Small 1.2は、制約のあるハードウェア環境内で高パフォーマンスを維持しながら効率的に動作します。240億パラメータのアーキテクチャは、適切に量子化されれば消費者向けハードウェアへのデプロイメントを可能にし、個人開発者や小規模チームが高度な推論機能にアクセスできるようにします。
さらに、バージョン1.2での計算効率の改善により、推論品質を維持しながら推論レイテンシが削減されます。この最適化により、即座の応答生成を必要とするリアルタイムアプリケーションやインタラクティブシステムが可能になります。
コンテキストウィンドウと処理能力
これらのモデルは128,000トークンのコンテキストウィンドウをサポートしており、広範なドキュメント、複雑な会話、大規模な分析タスクの処理を可能にします。40,000トークンを超えるとパフォーマンスが低下する可能性がありますが、モデルは全コンテキスト範囲で合理的な機能を維持します。
さらに、拡張されたコンテキスト機能により、包括的なドキュメント分析、長文推論タスク、およびコンテキスト認識を維持した複数ターン会話が可能になります。この能力は、広範な情報処理を必要とするエンタープライズアプリケーションをサポートします。
量子化と最適化技術
これらのモデルは、GGUF実装を通じてさまざまな量子化形式をサポートしており、異なるハードウェア構成全体でのデプロイメントを可能にします。これらの最適化により、推論能力を維持しながらメモリ要件が削減され、リソースが限られた環境でもモデルが利用可能になります。
さらに、特殊な最適化技術により、複雑な推論操作をサポートしながら推論速度が維持されます。これらの技術的改善は、多様なコンピューティング環境全体での実用的なデプロイメントの実現可能性を保証します。
Apidogによるテストと検証
包括的なAPIテスト戦略
Apidogは、包括的なテストフレームワークを通じてMagistralモデルの統合を検証するための不可欠なツールを提供します。このプラットフォームは、マルチモーダル入力テスト、推論トレース検証、およびパフォーマンスベンチマークをサポートしています。チームは、機能の正確性とパフォーマンス特性の両方を検証するテストスイートを作成できます。
Apidogの自動テスト機能は、開発サイクル全体でモデルのパフォーマンスの一貫性を確保する継続的インテグレーションワークフローを可能にします。この自動化により、手動テストのオーバーヘッドが削減され、品質保証基準が維持されます。
パフォーマンス監視と最適化
Apidogの監視機能を通じて、開発チームはAPIパフォーマンス指標を追跡し、最適化の機会を特定し、サービスの信頼性を維持できます。このプラットフォームは、応答時間、推論品質、リソース使用パターンに関する詳細な分析を提供します。
さらに、監視データは、アプリケーションのパフォーマンスとユーザーエクスペリエンスを向上させるプロアクティブな最適化戦略を可能にします。このデータ駆動型アプローチにより、本番環境全体で最適なモデル利用が保証されます。
結論
Magistral Small 1.2とMagistral Medium 1.2は、マルチモーダルAI推論技術における重要な進歩を象徴しています。強化された数学的性能、ビジョン機能、および改善された推論の透明性の組み合わせは、科学研究からソフトウェア開発に至るまで、多様なアプリケーションのための強力なツールを生み出します。
ローカルデプロイメントオプションと包括的なAPIサポートによるアクセシビリティの向上は、高度な推論機能へのアクセスを民主化します。組織は、大規模なインフラ投資を必要とせずに、洗練されたAI推論をワークフローに統合できるようになりました。
教育アプリケーションの開発、科学研究の実施、複雑なソフトウェアシステムの構築のいずれにおいても、Magistral Small 1.2とMagistral Medium 1.2は、次世代AIアプリケーションに必要な推論機能を提供します。Apidogのような堅牢なテストおよび統合ツールと組み合わせることで、これらのモデルは、品質基準を維持しながらイノベーションを加速する包括的な開発ワークフローを可能にします。