
急速に進化する大規模言語モデルの分野において、NVIDIAのLlama Nemotron Ultra 253Bは、高度な推論能力を求める企業向けの強力なモデルとして際立っています。この包括的なガイドでは、このモデルの印象的なベンチマークを検証し、他の主要なオープンソースモデルと比較し、アプリケーションにおけるAPIの実装手順を明確に説明します。
llama-3.1-nemotron-ultra-253b ベンチマーク
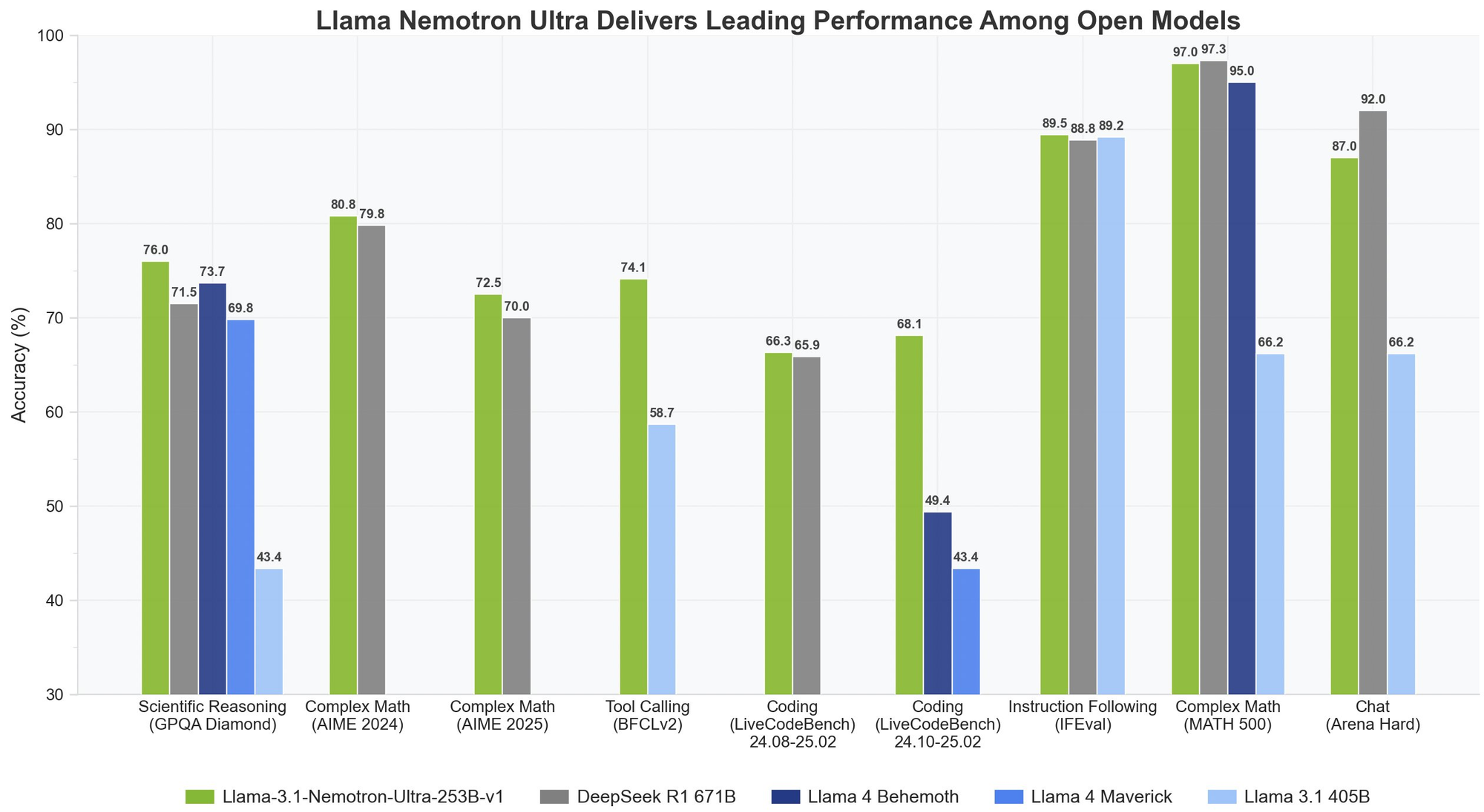
Llama Nemotron Ultra 253Bは、重要な推論およびエージェント的ベンチマークにおいて優れた結果を提供し、そのユニークな「Reasoning ON/OFF」機能は劇的な性能差を示しています:
数学的推論
Llama Nemotron Ultra 253Bは、数学的推論タスクにおいて真価を発揮します:
- MATH500
- Reasoning OFF: 80.4% pass@1
- Reasoning ON: 97.0% pass@1
Reasoning ONで97%の精度を達成することで、Llama Nemotron Ultra 253Bはこの難解な数学ベンチマークをほぼ完璧にクリアします。
- AIME25(アメリカンインビテーショナル数学試験)
- Reasoning OFF: 16.7% pass@1
- Reasoning ON: 72.50% pass@1
この56ポイントの改善は、Llama Nemotron Ultra 253Bの推論能力が複雑な数学問題に対するパフォーマンスをどのように変革するかを示しています。
科学的推論
- GPQA(大学院レベルの物理問題と解答)
- Reasoning OFF: 56.6% pass@1
- Reasoning ON: 76.01% pass@1
この顕著な改善は、Llama Nemotron Ultra 253Bが推論を有効にした状態で大学院レベルの物理問題にどのように取り組むかを示しています。
プログラミングとツールの使用
- LiveCodeBench(20240801-20250201)
- Reasoning OFF: 29.03% pass@1
- Reasoning ON: 66.31% pass@1
Llama Nemotron Ultra 253Bは、推論が有効な状態でコーディングパフォーマンスを2倍以上に向上させます。
- BFCL V2 Live(関数呼び出し)
- Reasoning OFF: 73.62スコア
- Reasoning ON: 74.10スコア
このベンチマークは、エージェント的アプリケーションを構築するために重要な両モードでのツール使用能力の強さを示しています。
命令の従遵
- IFEval(命令の従遵評価)
- Reasoning OFF: 88.85% 厳密精度
- Reasoning ON: 89.45% 厳密精度
両モードとも素晴らしいパフォーマンスを示し、Llama Nemotron Ultra 253Bは推論モードに関係なく強い命令従遵能力を維持していることを示しています。
Llama Nemotron Ultra 253B vs. DeepSeek-R1
DeepSeek-R1はオープンソース推論モデルの金標準として位置付けられていますが、Llama Nemotron Ultra 253Bは、重要な推論ベンチマークにおいてその性能に匹敵またはそれを上回ります:
- GPQAでLlama Nemotron Ultra 253Bは76.01%の精度を達成し、DeepSeek-R1のトップレベルの性能に競い合います
- Llama Nemotron Ultra 253Bはデュアル推論モードを提供し、DeepSeek-R1の固定推論アプローチとは異なります
- Llama Nemotron Ultra 253Bは優れた関数呼び出し能力を持ち、エージェント的アプリケーションにとってより多機能です
Llama Nemotron Ultra 253B vs. Llama 4
今後登場するLlama 4 BehemothモデルおよびMaverickモデルと比較すると:
- Llama Nemotron Ultra 253Bは科学的および複雑な数学的推論ベンチマークで優れたパフォーマンスを示します
- Llama Nemotron Ultra 253Bの明示的な推論スイッチは、標準のLlama 4モデルよりも柔軟性を提供します
- Llama Nemotron Ultra 253BはNVIDIAハードウェア専用に最適化されており、推論効率が向上します
Llama Nemotron Ultra 253BをAPI経由で試してみましょう
Llama Nemotron Ultra 253Bをアプリケーションに実装するには、最適なパフォーマンスを確保するために特定の手順に従う必要があります:
ステップ1: APIアクセスの取得
Llama Nemotron Ultra 253Bにアクセスするには:
- こちらのリンクでNVIDIA APIポータルを訪問します
- まだAPIキーをお持ちでない場合は、APIキーに登録します
- NVIDIAのNGC環境内で実行している場合は、APIキーの設定が簡素化されることがあります
ステップ2: 開発環境のセットアップ
API呼び出しをする前に:
pip install openaiを使用してOpenAI Pythonパッケージをインストールします- 必要なライブラリをインポートします:
from openai import OpenAI - APIキーを安全に保存するために環境を構成します
ステップ3: APIクライアントの構成
NVIDIAのエンドポイントでOpenAIクライアントを初期化します:
client = OpenAI(
base_url = "<https://integrate.api.nvidia.com/v1>",
api_key = "ここにAPIキーを入力"
)

- Postmanとは異なり、Apidogは組み込みのAPIドキュメント、オートメーションテスト、AIモデルエンドポイントに特化したモックサーバーを提供し、より統合された体験を提供します。
- Apidogの直感的なインターフェースを使用すると、APIテストに必要な複雑なパラメータセットを設定するのが簡単になり、レスポンス可視化機能はモデルのストリーミング出力を分析するのに特に役立ちます。
- Postmanは一般的なAPIテストツールとして人気がありますが、ApidogのAIに特化した機能と合理化されたワークフローは、開発プロセスを大幅に加速できます。

ステップ4: 適切な推論モードを決定する
Llama Nemotron Ultra 253Bは、二つの異なる動作モードを提供します:
- Reasoning ON: ステップバイステップ思考(数学、物理、コーディング)を必要とする複雑な問題に最適
- Reasoning OFF: 単純な命令従遵および一般的なチャットに最適
ステップ5: システムおよびユーザープロンプトの作成
Reasoning ONモードの場合:
- システムプロンプトを
"detailed thinking on"に設定します - すべての指示をユーザーメッセージに入れます
- ベンチマークされたタスク(数学問題など)には特定のテンプレートを使用することを検討してください
Reasoning OFFモードの場合:
- 推論システムプロンプトを削除します
- ユーザーメッセージには簡潔で明確な指示を使用します
ステップ6: 生成パラメータの設定
最適な結果を得るために:
- Reasoning ON: NVIDIAの推奨に従い、temperature=0.6、top_p=0.95を設定します
- Reasoning OFF: temperature=0でグリーディデコーディングを使用します
- 予想されるレスポンス長に基づいて
max_tokensを適切に設定します - リアルタイムレスポンスのためにストリーミングを有効にすることを検討してください
ステップ7: APIリクエストを作成し、レスポンスを処理する
すべてのパラメータを設定した状態でコンプリーションリクエストを作成します:
completion = client.chat.completions.create(
model="nvidia/llama-3.1-nemotron-ultra-253b-v1",
messages=[
{"role": "system", "content": "detailed thinking on"},
{"role": "user", "content": "プロンプトはこちらに入力"}
],
temperature=0.6,
top_p=0.95,
max_tokens=4096,
stream=True
)
ステップ8: レスポンスを処理して表示する
ストリーミングを使用する場合:
for chunk in completion:
if chunk.choices[0].delta.content is not None:
print(chunk.choices[0].delta.content, end="")
非ストリーミングレスポンスの場合は、単純にcompletion.choices[0].message.contentにアクセスします。
結論
Llama Nemotron Ultra 253Bはオープンソースの推論モデルにおける重要な進歩を示し、さまざまなベンチマークで最先端のパフォーマンスを提供します。そのユニークなデュアル推論モード、卓越した関数呼び出し能力、および膨大なコンテキストウィンドウは、高度な推論能力を必要とする企業向けAIアプリケーションに最適な選択肢となります。
この記事で概説されたステップバイステップのAPI実装ガイドにより、開発者はLlama Nemotron Ultra 253Bの完全なポテンシャルを活用して、複雑な問題に人間のような推論で取り組む高度なAIシステムを構築できます。AIエージェントを構築したり、RAGシステムを強化したり、専門的なアプリケーションを開発したりする場合でも、Llama Nemotron Ultra 253Bは次世代のAI能力の商業的に友好的なオープンソースパッケージの強力な基盤を提供します。