
人工知能の風景は、MetaのLlama 4のリリースによって根本的に変わりました。これは単なる漸進的な改善だけでなく、パフォーマンス・コスト比を業界全体で再定義するアーキテクチャの革新によって実現されています。これらの新しいモデルは、三つの重要な革新の融合を代表しています。すなわち、早期融合技術によるネイティブなマルチモーダル性、パラメータ効率を劇的に改善するスパース混合専門家(MoE)アーキテクチャ、前例のない1000万トークンに拡張するコンテキストウィンドウの拡大です。
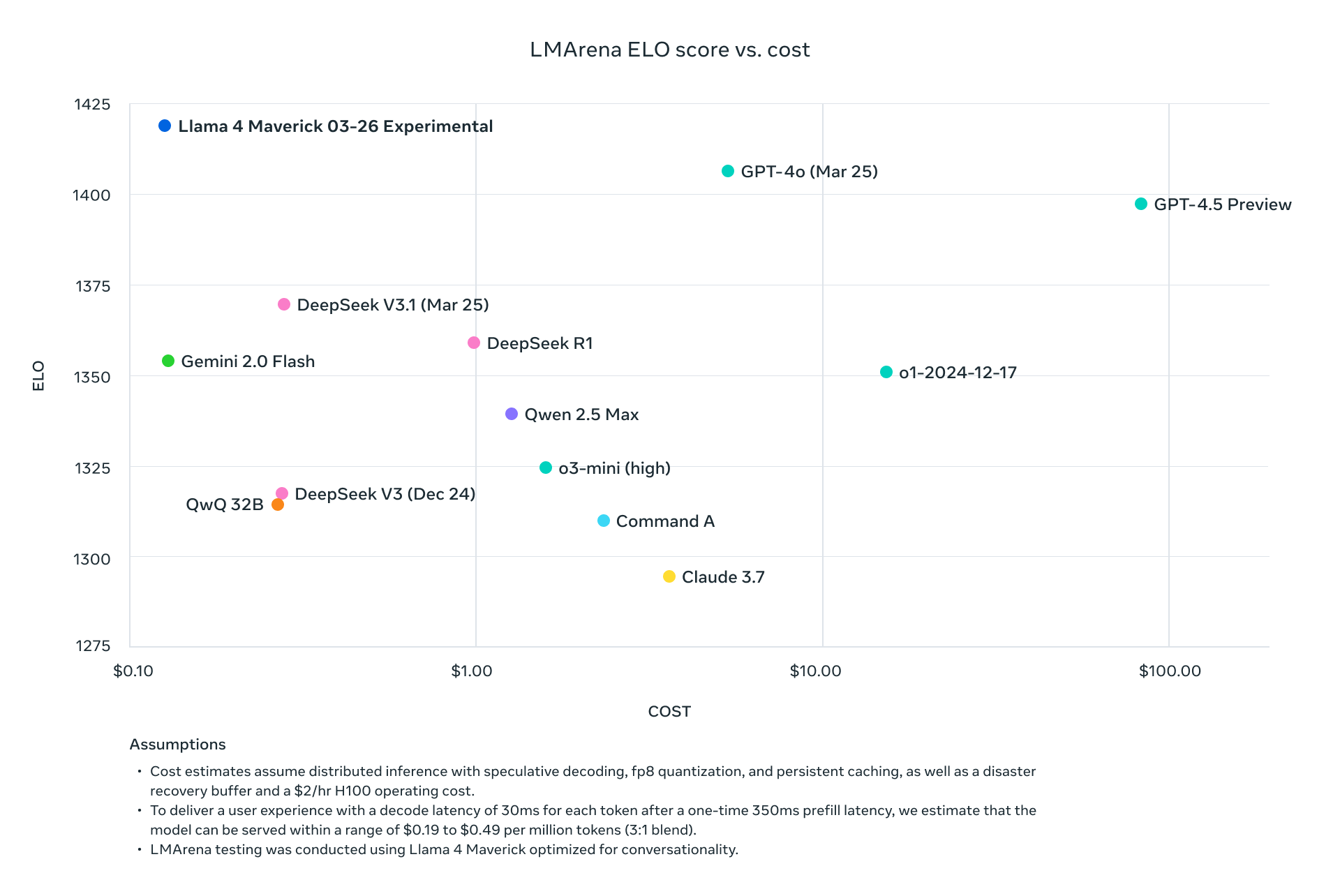
Llama 4 ScoutとMaverickは、現在の業界リーダーと単に競争するだけではなく、標準ベンチマークで体系的に上回る一方で、計算要件を劇的に削減します。Maverickがトークンあたり約1/9のコストでGPT-4oよりも優れた結果を達成し、Scoutが複数のGPUが必要なモデルに対して優れたパフォーマンスを維持しながら単一のH100 GPU上に収まることにより、Metaは先進的なAI展開の経済性を根本的に変えました。
この技術分析では、これらのモデルを支えるアーキテクチャの革新を解析し、推論、コーディング、多言語、マルチモーダルタスクにおける包括的なベンチマークデータを提示し、主要プロバイダー間のAPI価格体系を検証します。AIインフラオプションを評価する技術的な意思決定者のために、これらの画期的なモデルを生産環境で最大限に活用するための詳細なパフォーマンス/コスト比較と展開戦略を提供します。
今日の時点で、Meta Llama 4のオープンソースおよびオープンウェイトをHugging Faceでダウンロードできます。
https://huggingface.co/collections/meta-llama/llama-4-67f0c30d9fe03840bc9d0164

Llama 4はどのようにして1000万トークンのコンテキストウィンドウを実現したのか?
専門家の混合(MoE)実装
すべてのLlama 4モデルは、効率性の方程式を根本的に変える洗練されたMoEアーキテクチャを採用しています:
| モデル | アクティブパラメータ | 専門家数 | パラメータ総数 | パラメータアクティベーション方式 |
|---|---|---|---|---|
| Llama 4 Scout | 17B | 16 | 109B | トークン特化型ルーティング |
| Llama 4 Maverick | 17B | 128 | 400B | 共有 + トークンごとに単一のルーティッド専門家 |
| Llama 4 Behemoth | 288B | 16 | ~2T | トークン特化型ルーティング |
Llama 4 MaverickのMoE設計は特に洗練されており、密なレイヤーとMoEレイヤーを交互に使用しています。各トークンは共有専門家に加え、128のルーティングされた専門家のうちの1つをアクティブにするため、任意のトークン処理のために400Bの総パラメータのうち約17Bだけがアクティブになります。
マルチモーダルアーキテクチャ
Llama 4マルチモーダルアーキテクチャ:
├── テキストトークン
│ └── ネイティブなテキスト処理経路
├── ビジョンエンコーダー(強化されたMetaCLIP)
│ ├── 画像処理
│ └── 画像をトークンシーケンスに変換
└── 早期融合レイヤー
└── モデルのバックボーンでテキストとビジョントークンを統一
この早期融合アプローチにより、テキスト、画像、動画データの混合で300兆以上のトークンに対して事前トレーニングが可能になり、後付けアプローチよりもはるかに一貫性のある多モーダル機能が得られます。
拡張コンテキストウィンドウのためのiRoPEアーキテクチャ
Llama 4 Scoutの1000万トークンのコンテキストウィンドウは、革新的なiRoPEアーキテクチャを活用しています:
# iRoPEアーキテクチャの擬似コード
def iRoPE_layer(tokens, layer_index):
if layer_index % 2 == 0:
# 偶数レイヤー:位置埋め込みなしのインタリーブされたアテンション
return attention_no_positional(tokens)
else:
# 奇数レイヤー:RoPE(ロータリーポジション埋め込み)
return attention_with_rope(tokens)
def inference_scaling(tokens, temperature_factor):
# 推論中の温度スケーリングは長さの一般化を改善
return scale_attention_scores(tokens, temperature_factor)
このアーキテクチャにより、Scoutは前例のない長さの文書を処理し、全体にわたる整合性を維持できるようになり、スケールファクターは以前のLlamaモデルのコンテキストウィンドウよりも約80倍大きくなります。
包括的なベンチマーク分析
標準ベンチマーク性能メトリクス
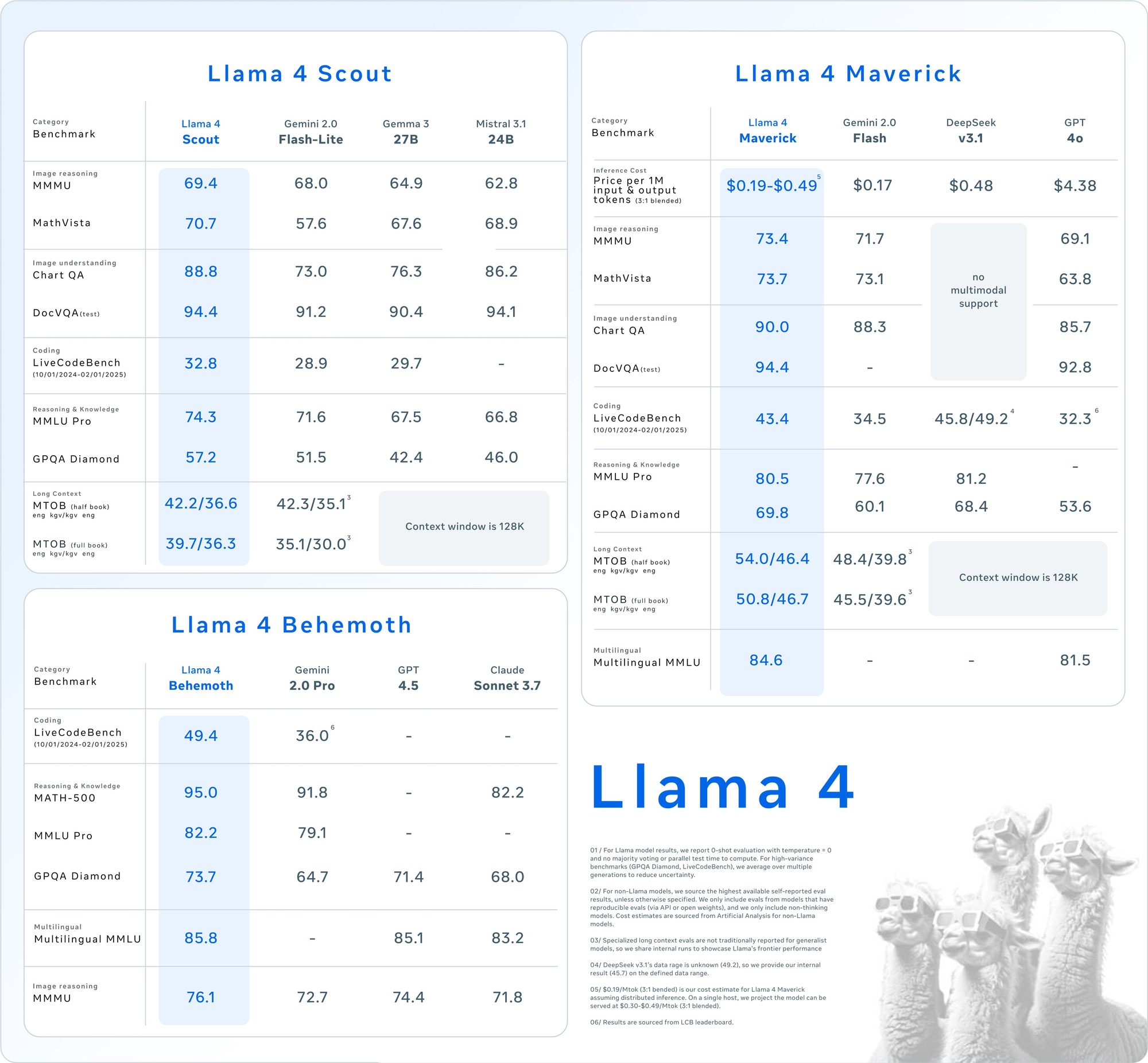
主要な評価スイートにおける詳細なベンチマーク結果は、Llama 4モデルの競争的な位置付けを示しています:
| カテゴリ | ベンチマーク | Llama 4 Maverick | GPT-4o | Gemini 2.0 Flash | DeepSeek v3.1 |
|---|---|---|---|---|---|
| 画像推論 | MMMU | 73.4 | 69.1 | 71.7 | マルチモーダルサポートなし |
| MathVista | 73.7 | 63.8 | 73.1 | マルチモーダルサポートなし | |
| 画像理解 | ChartQA | 90.0 | 85.7 | 88.3 | マルチモーダルサポートなし |
| DocVQA(テスト) | 94.4 | 92.8 | - | マルチモーダルサポートなし | |
| コーディング | LiveCodeBench | 43.4 | 32.3 | 34.5 | 45.8/49.2 |
| 推論と知識 | MMLU Pro | 80.5 | - | 77.6 | 81.2 |
| GPQA Diamond | 69.8 | 53.6 | 60.1 | 68.4 | |
| 多言語 | 多言語MMLU | 84.6 | 81.5 | - | - |
| 長いコンテキスト | MTOB(半書籍)eng→kgv/kgv→eng | 54.0/46.4 | コンテキストは128Kに制限されている | 48.4/39.8 | コンテキストは128Kに制限されている |
| MTOB(全書籍)eng→kgv/kgv→eng | 50.8/46.7 | コンテキストは128Kに制限されている |