
大規模言語モデル(LLM)の世界は驚異的な速さで進化していますが、効率性とリアルタイムの適応性には課題が残っています。2025年9月10日、Kimiシリーズの背後にある革新的な企業であるMoonshot AIは、LLM推論エンジンにおける重み更新を再定義するオープンソースミドルウェア「checkpoint-engine」を発表しました。強化学習(RL)向けに調整されたこの軽量ツールは、Kimi-K2のような1兆パラメータの巨大モデルを、数千のGPUにわたってわずか20秒で更新でき、ダウンタイムを大幅に削減し、スケーラビリティを向上させます。
この記事では、checkpoint-engineの仕組みを、そのアーキテクチャからベンチマークまで掘り下げ、RLへの影響とより広範なエコシステムへの適合性を強調します。この素晴らしいツールをオープンソース化することで、Moonshot AIはコミュニティがLLMの限界をさらに押し広げることを可能にします。このイノベーションを一つずつ詳しく見ていきましょう。
Checkpoint-Engineの理解:核となる概念とアーキテクチャ
Checkpoint-Engineとは?
その核心において、checkpoint-engineは、推論中にLLMの重みをシームレスかつインプレースで更新することを容易にするミドルウェアです。これは、モデルが完全な再学習なしに反復的なフィードバックを通じて進化するRLにおいて極めて重要です。従来のメソッドは、長い再読み込みによってシステムを停滞させますが、checkpoint-engineは合理化された低オーバーヘッドのアプローチでこれに対抗します。
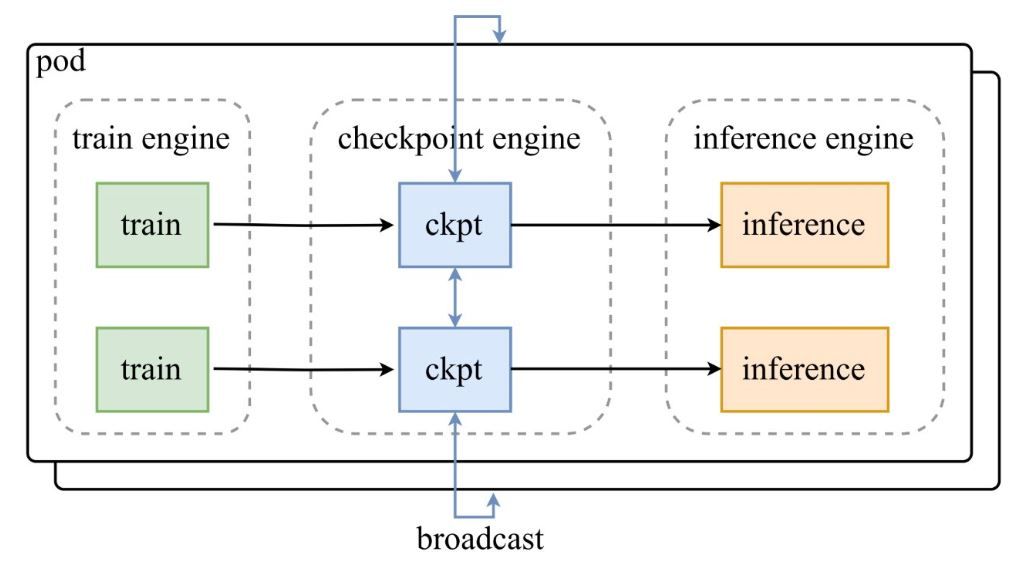
Moonshot AIの発表ツイートのアーキテクチャ図が示すように、訓練エンジンのポッドがチェックポイントを中央のcheckpoint-engineに供給し、それが推論エンジンに更新をブロードキャストします。GitHubリポジトリはコードを深く掘り下げ、ParameterServerクラスを更新のオーケストレーターとして強調しています。
アーキテクチャコンポーネント
- 訓練エンジン: 進行中のRL訓練から新しい重みを生成し、動的な環境におけるポリシーの洗練を捉えます。
- チェックポイントエンジン: ミドルウェアの中核であり、最小限のレイテンシのために推論と併置されます。メタデータの収集を処理し、ブロードキャストまたはP2Pモードを介して更新を実行します。
- 推論エンジン: 更新をオンザフライで統合し、分散GPUクラスター全体でサービスの継続性を維持します。
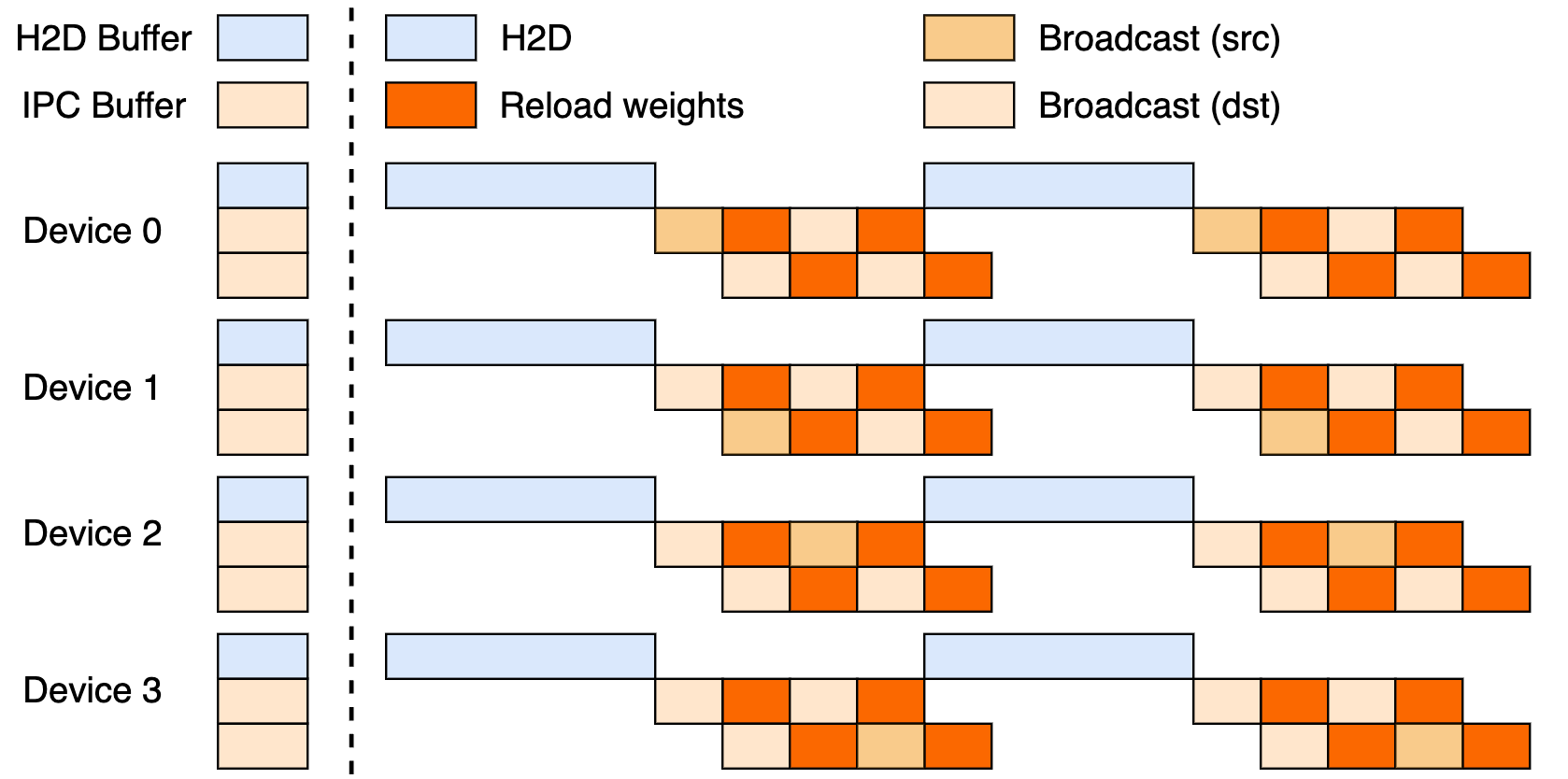
このセットアップは、ホストからデバイスへの転送(H2D)、CUDA IPCを使用したワーカー間ブロードキャスト、およびターゲットを絞った再読み込みという3段階のパイプラインを活用しています。これらをオーバーラップさせることで、GPUの利用率を最大化し、転送のボトルネックを抑制します。
ブロードキャストとP2P更新
ブロードキャストは、同期的なクラスター全体の更新において優れた性能を発揮します。これは最高の速度を実現するためのデフォルトモードであり、最適なフローのためにデータをバケット化します。一方、P2Pは、mooncake-transfer-engineを介したRDMAを使用することで、ピーク時のスケールアウトのような弾力的なシナリオで優れた性能を発揮し、中断を回避します。この二重性により、checkpoint-engineは安定したデプロイメントと流動的なデプロイメントの両方に対応できる汎用性の高いツールとなっています。
パフォーマンスベンチマーク:十分な速さとは?
1兆パラメータモデルを20秒で更新
checkpoint-engineの目玉機能とは?Kimi-K2の1兆パラメータを数千のGPUにわたって約20秒で更新することです。これは、スマートなパイプライン処理に由来します。メタデータ計画により効率的なバケットサイズが設定され、ZeroMQソケットが転送を調整し、オーバーラップするH2D/ブロードキャストステージがレイテンシを隠します。これは、大規模なデータシャッフル中にシステムを数分間アイドル状態にする可能性のある従来の技術とは対照的です。checkpoint-engineのインプレースの精神は、推論を滞りなく実行させ、迅速な適応を必要とするRLに理想的です。
ベンチマーク分析
ベンチマーク表は、vLLM v0.10.2rc1でテストされたモデルとセットアップ全体で素晴らしい結果を示しています。
| モデル | デバイス情報 | メタデータ収集 | 更新(ブロードキャスト) | 更新(P2P) |
|---|---|---|---|---|
| GLM-4.5-Air (BF16) | 8xH800 TP8 | 0.17s | 3.94s (1.42GiB) | 8.83s (4.77GiB) |
| Qwen3-235B-A22B-Instruct-2507 (BF16) | 8xH800 TP8 | 0.46s | 6.75s (2.69GiB) | 16.47s (4.05GiB) |
| DeepSeek-V3.1 (FP8) | 16xH20 TP16 | 1.44s | 12.22s (2.38GiB) | 25.77s (3.61GiB) |
| Kimi-K2-Instruct (FP8) | 16xH20 TP16 | 1.81s | 15.45s (2.93GiB) | 36.24s (4.46GiB) |
| DeepSeek-V3.1 (FP8) | 256xH20 TP16 | 1.40s | 13.88s (2.54GiB) | 33.30s (3.86GiB) |
| Kimi-K2-Instruct (FP8) | 256xH20 TP16 | 1.88s | 21.50s (2.99GiB) | 34.49s (4.57GiB) |
これらはリポジトリのexamples/update.pyで再現できます。FP8の実行にはvLLMパッチが必要であり、大規模での効率性を強調しています。
強化学習への影響
RLは迅速な反復によって発展します。checkpoint-engineの20秒未満のサイクルは、バッチメソッドを凌駕する継続的な学習ループを可能にします。これにより、適応型エージェントから進化するチャットボットまで、ポリシーチューニングにおいて一秒一秒が重要となる応答性の高いアプリケーションが実現します。
技術的実装:コードベースを深く掘り下げる
オープンソースのアクセシビリティ
Moonshot AIのGitHubでの公開は、エリートRLツールを民主化します。ParameterServerは更新の要であり、ブロードキャスト(高速なCUDA IPC共有)とP2P(新規ユーザー向けのRDMA)を提供します。update.pyやテスト(test_update.py)のような例は、オンボーディングを容易にします。互換性はvLLM(ワーカー拡張経由)から始まり、SGLang用のフックが次に検討されています。部分的な3段階パイプラインは、未開拓の可能性を示唆しています。
最適化技術
主なスマートな機能は以下の通りです。
- パイプライン化されたオーバーラップ: 通信とコピーが同時に実行され、実質的な時間を大幅に短縮します。
- バケット最適化: メタデータ駆動型のサイジングにより、シャーディングとネットワークに調整されます。
- ZeroMQ制御: 推論エンジンへの低レイテンシシグナリング。
これらは、PCIeの衝突からメモリの逼迫まで(必要に応じてシリアルにフォールバックする)、1兆パラメータのハードルに対処します。
現在の制限事項
P2Pのランク0ファネルは大規模になるとボトルネックになる可能性があり、完全なパイプラインは磨き上げを待っています。vLLMに焦点を当てることで広がりが制限されますが、パッチはDeepSeek-V3.1のようなモデルのFP8のギャップを埋めます。進化についてはリポジトリを監視してください。
既存フレームワークとの統合:vLLMとその先
vLLMとの連携
checkpoint-engineは、vLLMのPagedAttentionとネイティブに連携し、スムーズなRL推論を実現します。この組み合わせは、vLLMの更新で示唆されているように、1兆パラメータモデルで20秒の同期を達成し、スループットを向上させるオープンな協力体制を象徴しています。
ClaudeとApidogへの潜在的な拡張
AnthropicのClaudeに拡張することで、その安全性に焦点を当てたチャットにRLのダイナミズムを注入し、ライブでのファインチューニングを可能にするかもしれません。ApidogはZeroMQの調整中のエンドポイントモックに最適です。Apidogを無料でダウンロードして、これらのブリッジを簡単にプロトタイプ化しましょう。
より広範なエコシステムへの影響
OllamaやLM Studioに接続することで、1兆パラメータのパワーをローカライズし、インディー開発者のための競争条件を平等にすることができます。この波及効果は、より包括的なAIランドスケープを育みます。
将来の展望:Checkpoint-Engineのこれから
スケーラビリティとパフォーマンスの強化
完全なパイプラインの展開はさらに数秒を短縮する可能性があり、P2Pの分散化は真の弾力性のためのボトルネックを解消します。RDMAの調整は、クラウドネイティブな能力を約束します。
コミュニティの貢献
オープンソースは修正と移植を招きます。SGLangの統合やPCIeにとらわれないモードなどを考えてみてください。ツイートへの初期の返信は興奮に満ちており、勢いを加速させています。
産業応用
リアルタイム翻訳から自動運転RLまで、checkpoint-engineは変動の激しい分野に適しています。その速度はモデルを常に最新の状態に保ち、俊敏性において競合他社を凌駕します。
LLM推論の新時代?
checkpoint-engineは、オープンソースの才能で重みの問題を解決し、アジャイルなLLMの未来を告げます。賢明なアーキテクチャとベンチマークに裏打ちされた20秒での1兆パラメータの更新は、その限界にもかかわらず、RLの王座を確固たるものにします。
開発フローにはApidogと、ハイブリッドなスマートさにはClaudeと組み合わせれば、イノベーションは飛躍的に進むでしょう。GitHubをフォローし、Apidogを無料で手に入れて、今日の推論を再構築する革命に参加しましょう!