
開発者は、高度な言語モデルをアプリケーションに統合するための効率的な方法を求めています。INTELLECT-3は、そのオープンソース基盤と推論タスクにおける強力なパフォーマンスにより、魅力的な選択肢として登場します。Prime Intellectが開発したこのモデルは、1,060億パラメータのMixture-of-Experts(MoE)アーキテクチャが特徴で、複雑な計算を非常に効率的に処理できます。
INTELLECT-3を理解する:オープンソースの主力製品
Prime IntellectはINTELLECT-3を完全なオープンソースモデルとしてリリースしており、これにより研究者や開発者は、独自の障壁なしにその機能をカスタマイズおよび拡張できます。この透明性は、強化学習(RL)やエージェントAIシステムなどの分野でのイノベーションを促進します。モデルの重み、トレーニングフレームワーク、データセット、RL環境、評価ツールを含む完全なパッケージは、Prime Intellectのリポジトリから直接アクセスできます。

その中核として、INTELLECT-3はGLM-4.5-Airベースモデルの上に構築された1,060億パラメータのMoEアーキテクチャを採用しています。MoE設計は、入力を専門の「エキスパート」サブネットワークにルーティングし、計算の使用を最適化し、推論を高速化します。例えば、処理中にモデルはクエリに関連するパラメータのサブセットのみをアクティブにし、精度を維持しながらレイテンシーを削減します。この設定は、数学的導出やコード生成など、選択的な専門知識を必要とするタスクで特に効果的です。
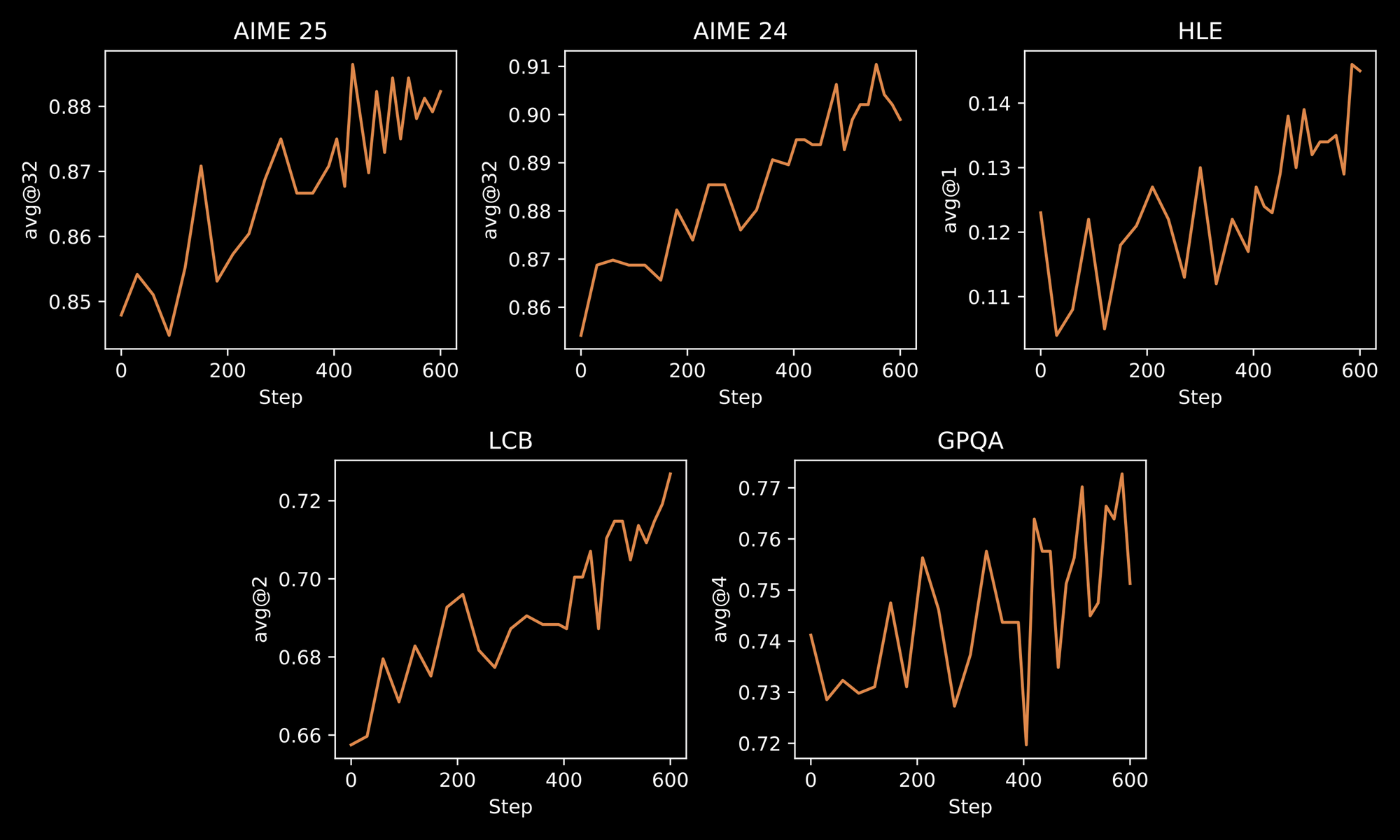
トレーニングプロセスは、INTELLECT-3の堅牢さを際立たせています。エンジニアは2段階の方法論を適用します。まず厳選されたデータセットに対する初期の教師ありファインチューニング(SFT)、次にカスタムのprime-rlフレームワークを使用した大規模なRLです。prime-rlは非同期オフポリシーRLシステムとして機能し、膨大な並列シミュレーションを効率的に処理します。これにより、反復的な問題解決や多段階計画のような動的な環境でのモデルの振る舞いが向上するというメリットが得られます。
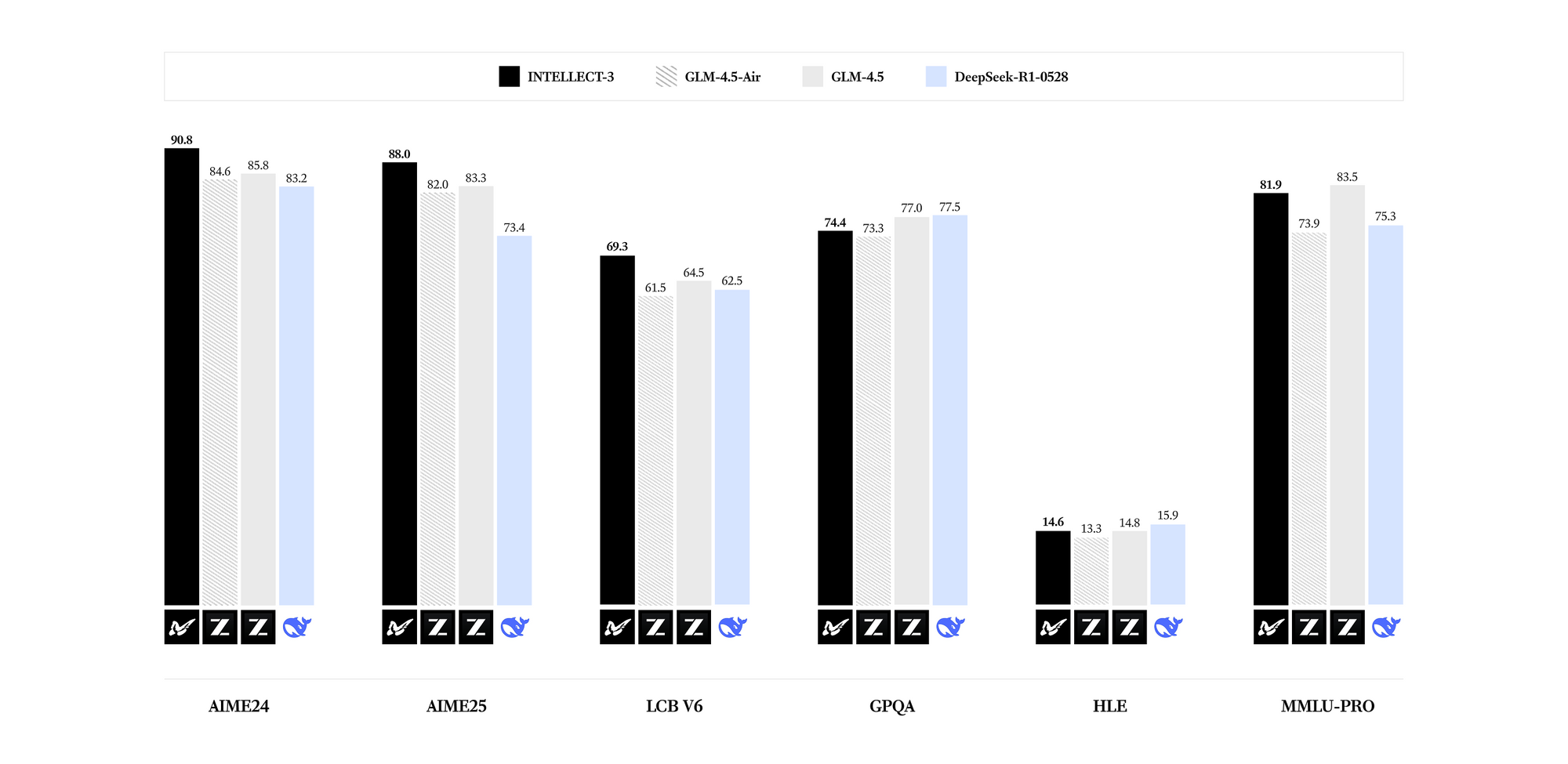
INTELLECT-3は、専門分野で優れた能力を発揮します。ベンチマークでは、そのパラメータ数において、数学(例:GSM8Kスコア95%超)、コーディング(HumanEval合格率85%超)、科学(GPQA精度60%超)、推論(MMLUスコア80%近く)の各分野で最先端の結果を明らかにしています。Llama 3.1 70Bのような高密度モデルと比較して、INTELLECT-3は疎なアクティベーションパターンにより、同等のハードウェアで最大2倍高速な推論という優れた効率性を達成しています。その結果、出力品質を犠牲にすることなく、リソース制約のある環境に展開できます。
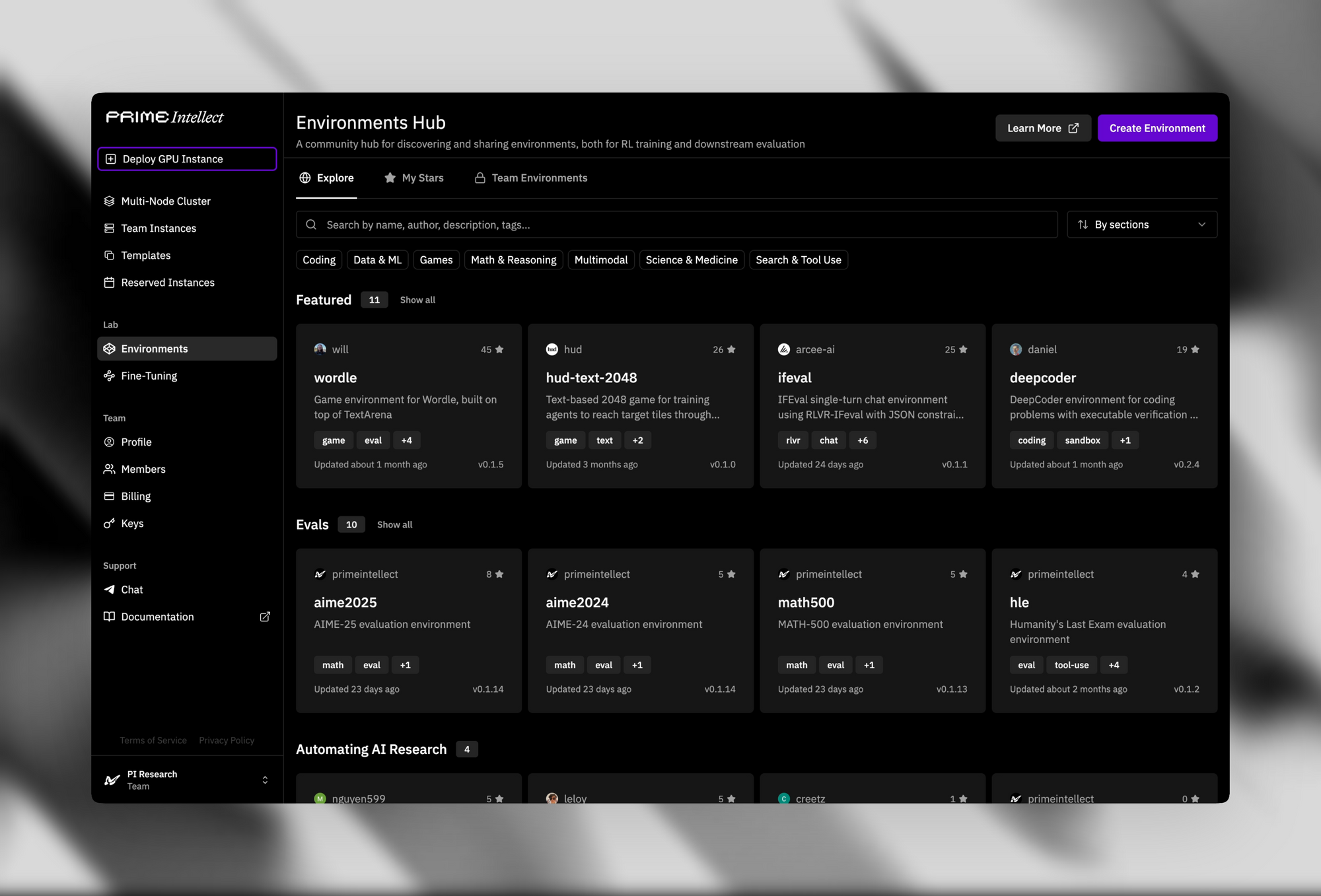
サポートインフラストラクチャは、そのオープンソースとしての魅力を高めています。検証者&環境ハブは、単純なパズルから高度な定理証明器まで、500以上のRL環境を提供しています。
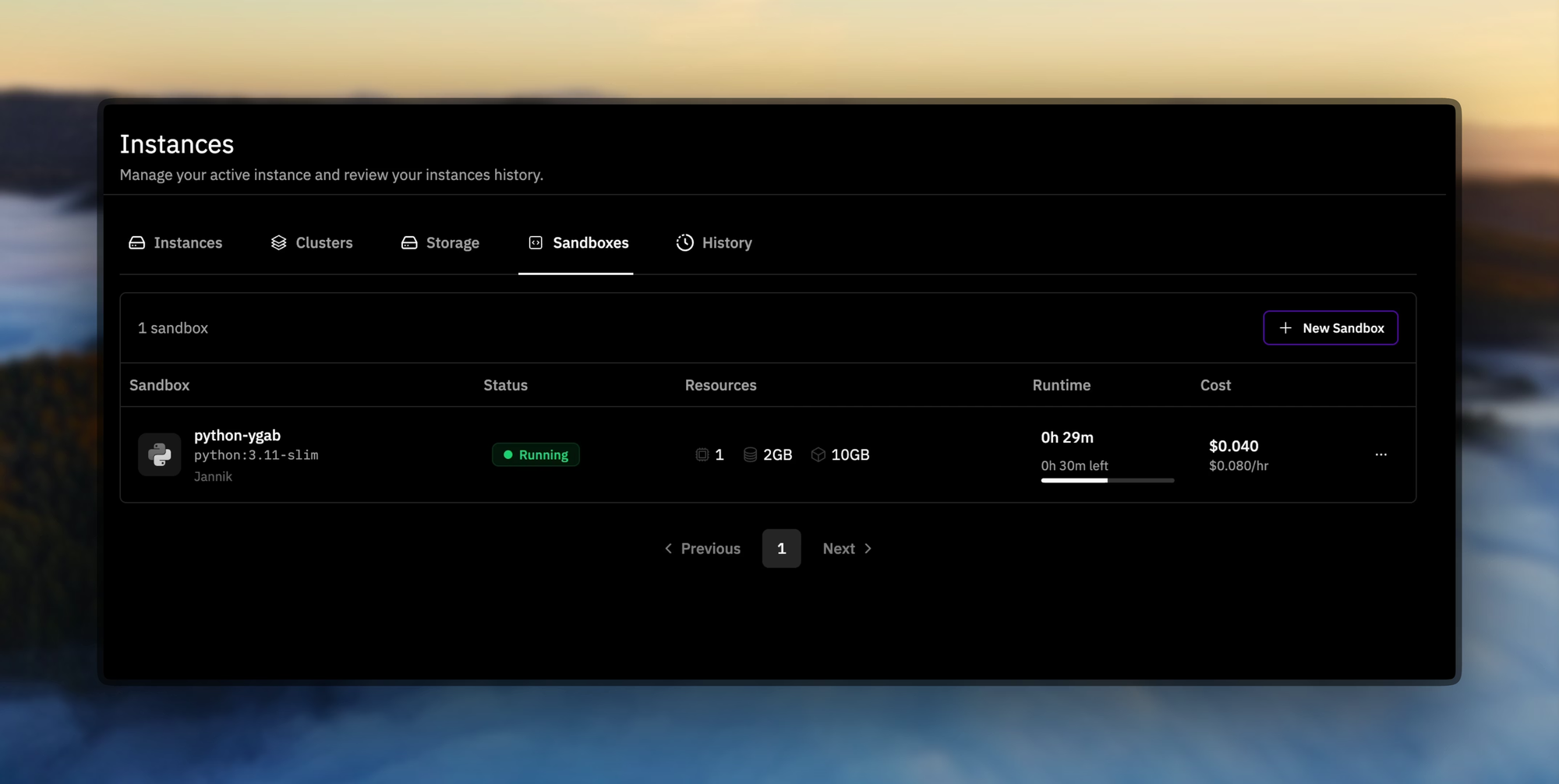
Prime Sandboxesは、安全で高スループットのコード実行を提供し、トレーニング中または推論中のエージェントのアクションを分離します。開発者はこれらのツールを活用して、ソフトウェア開発パイプラインにおける自律型エージェントなどのカスタムアプリケーション向けにINTELLECT-3をファインチューニングします。
実際には、Hugging FaceまたはPrime IntellectのGitHubからモデルの重みをダウンロードします。インストールには、PyTorchやTransformersライブラリなどの標準的な依存関係が必要です。モデルをロードするための基本的なスクリプトは次のようになります。
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "prime-intellect/intellect-3" # Placeholder for official repo
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto")
inputs = tokenizer("Solve this equation: x^2 + 3x - 4 = 0", return_tensors="pt")
outputs = model.generate(**inputs, max_length=100)
print(tokenizer.decode(outputs[0]))
このコードは、GPU対応ハードウェアでモデルを初期化します。しかし、本番規模での利用には、自己ホスティングがかなりの計算能力(例:複数のA100 GPU)を必要とするため、ホスト型APIに移行します。したがって、オープンソースアクセスは基盤を築きますが、API統合によってデプロイを効果的にスケールできます。
ローカルでの実験から移行し、マネージドサービスを通じてINTELLECT-3にアクセスする方法を次に探ります。この移行により、信頼性が確保され、分散推論の複雑さが処理されます。
INTELLECT-3 APIへのアクセス:セットアップと認証
オプション1 – Prime Intellectネイティブエンドポイント(最高のパフォーマンスと最低のレイテンシーに推奨)
APIアクセスは、Prime Intellectのプラットフォームから認証情報を取得することから始めます。app.primeintellect.aiでPrime Intellectダッシュボードにアクセスし、必要に応じてアカウントを作成してください。
ログインしたら、APIキーセクションに移動し、推論パーミッションを有効にした新しいキーを生成します。このキーは、その後のすべてのリクエストを認証し、INTELLECT-3への安全なアクセスを保証します。
次に、環境を設定します。シームレスな統合のために、APIキーを環境変数として設定します。
export PRIME_API_KEY="your-api-key-here"
チームベースのワークフローでは、リクエストにX-Prime-Team-IDヘッダーを含めます。この識別子は、使用状況を正しい課金プールにルーティングし、アカウント間の請求を防ぎます。チームIDは、ダッシュボードのアカウント設定から取得できます。
このAPIはOpenAI互換のインターフェースを採用しているため、openai-pythonのようなライブラリをすでに使用している場合は導入が簡単です。ベースURLをhttps://api.pinference.ai/api/v1として指定します。このエンドポイントは、INTELLECT-3インスタンスをホストするParasailやNebiusなどの最適化された推論プロバイダーにリクエストをプロキシします。その結果、基盤となるクラスターを管理することなく、低レイテンシーの応答を実現できます。
アクセスを確認するには、モデルエンドポイントをクエリします。これにより、利用可能なモデルがリストされ、INTELLECT-3の存在が確認されます(通常、prime-intellect/intellect-3のようなハンドル名で)。クイックチェックにはCLIツールを使用します。
prime inference models
または、curlを介してGETリクエストを送信します。
curl -H "Authorization: Bearer $PRIME_API_KEY" \
https://api.pinference.ai/api/v1/models
応答はモデルオブジェクトのJSON配列を返します。各オブジェクトは、id、max_tokens、context_windowなどのパラメータを詳細に示します。INTELLECT-3は128Kトークンのコンテキストをサポートしており、長形式の推論チェーンに対応できます。
認証はレート制限とクォータにも及びます。Prime Intellectは、ダッシュボードに表示されるプランに基づいて、1分あたりおよび日ごとの制限を適用します。使用状況は、「請求」タブで監視でき、処理されたトークンと行われたAPI呼び出しがログに記録されます。制限がワークフローを制約する場合は、プラットフォームを通じてシームレスにアップグレードできます。
さらに、強化されたテストのためにApidogと統合してください。OpenAIスキーマをApidogにインポートし、INTELLECT-3エンドポイントへのリクエストをシミュレートします。この実践により、不正なJSONペイロードなどの問題を早期に特定できます。Apidogの無料ティアは初期設定には十分であり、ローカル開発と本番APIの橋渡しをします。
認証が整ったら、リクエストの作成に進みます。以下のセクションでは、INTELLECT-3から最適な応答を引き出すための正確なフォーマットを概説します。
オプション2 – OpenRouter(即時アクセス&統合クレジット)
自己ホスティングまたはPrime Intellectのネイティブ推論プラットフォームの使用に加えて、INTELLECT-3はOpenRouterでも公式に利用可能です。これにより、統合された請求、自動フォールバックルーティング、および即時アクセスを備えた代替ゲートウェイが提供されます。OpenRouterをすでに利用している場合、別途Prime Intellectアカウントは必要ありません。
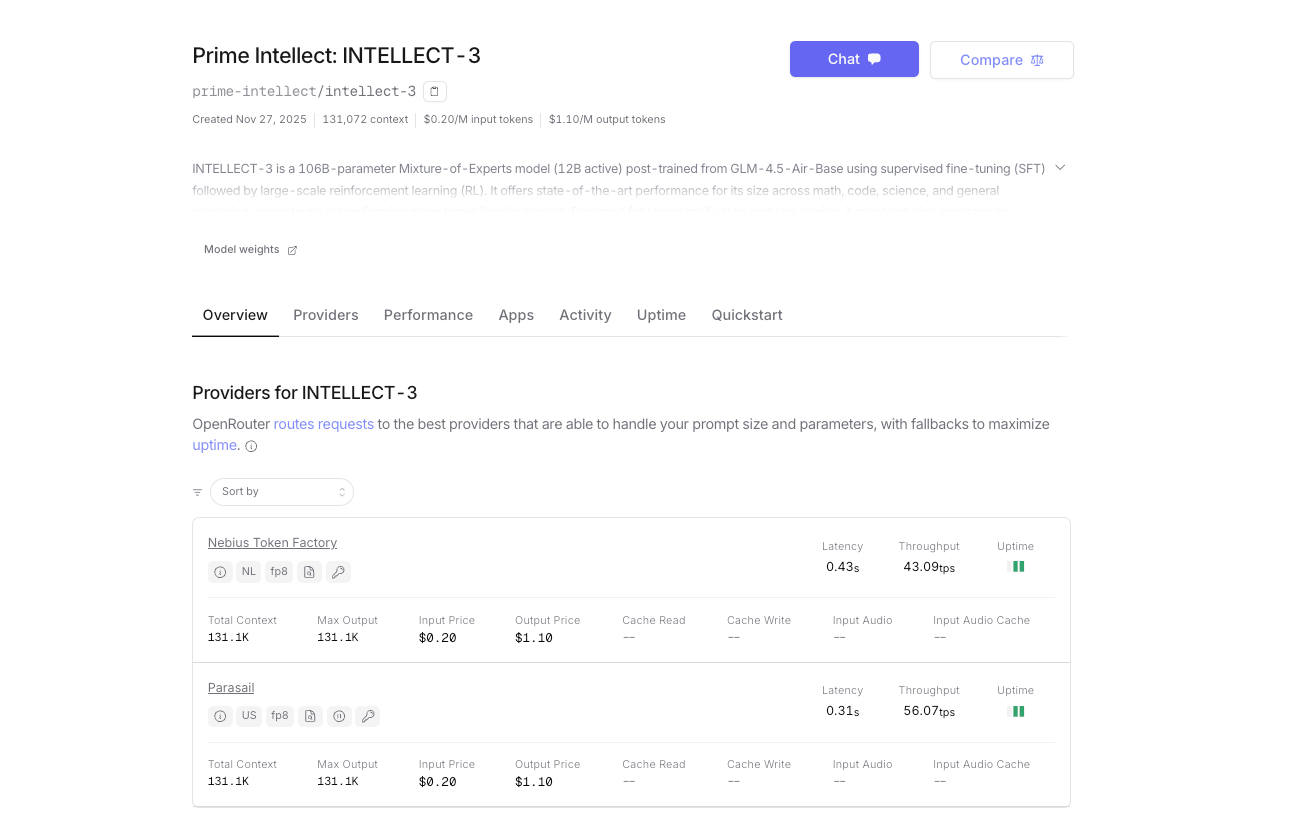
- ベースURL: https://openrouter.ai/api/v1
- モデル名: prime-intellect/intellect-3
- 認証: あなたのOpenRouter APIキー(OPENROUTER_API_KEY)
- 自動プロバイダルーティング(現在Prime Intellectクラスターによって提供されています)
- OpenRouterクレジットによる従量課金制。プラットフォーム手数料のため、トークンあたりのコストが若干高くなります。
両方のエンドポイントは、同一のリクエスト/レスポンススキーマ、ストリーミング、ツール呼び出し、およびJSONモードをサポートしています。
INTELLECT-3 APIへのリクエスト作成:フォーマットと例
インタラクションは、会話型およびタスク指向のプロンプトを処理する/chat/completionsエンドポイントを通じて開始します。model、messages、temperature、max_tokensのフィールドを持つJSONオブジェクトとしてリクエストを構築します。messages配列は、「system」、「user」、「assistant」などのロールを使用してチャット履歴を模倣します。
コード生成の基本的な例を考えます。送信するのは次のとおりです。
import openai
import os
client = openai.OpenAI(
api_key=os.environ.get("PRIME_API_KEY"),
base_url="https://api.pinference.ai/api/v1"
)
response = client.chat.completions.create(
model="prime-intellect/intellect-3",
messages=[
{"role": "system", "content": "You are a helpful coding assistant."},
{"role": "user", "content": "Write a Python function to compute Fibonacci numbers up to n."}
],
temperature=0.7,
max_tokens=200
)
print(response.choices[0].message.content)
このコードは、メモ化を用いた再帰的なフィボナッチ実装を出力し、INTELLECT-3のコーディング能力を活用しています。temperatureパラメータは創造性を制御します。低い値(例:0.2)は事実に基づくクエリに対して決定的な出力を優先し、高い値(1.0まで)は多様な推論経路を促進します。
数学的推論の場合、思考を連鎖させるようにプロンプトを構築します。INTELLECT-3のRLトレーニングは、ステップバイステップの検証をシミュレートするため、ここで真価を発揮します。例:
response = client.chat.completions.create(
model="prime-intellect/intellect-3",
messages=[
{"role": "user", "content": "Prove that the sum of angles in a triangle is 180 degrees. Use Euclidean geometry."}
],
max_tokens=500
)
モデルは公理と定理を引用しながら厳密な証明を返します。出力はresponse.choices[0].message.contentを介してパースされ、文字列として届きます。構造化データの場合、リクエストに"response_format": {"type": "json_object"}を追加することでJSONモードを有効にし、解析可能な応答を確実に得られます。
高度な使用法にはツール呼び出しが含まれ、INTELLECT-3は外部関数を統合します。リクエストでツールを定義します。
tools = [
{
"type": "function",
"function": {
"name": "get_weather",
"description": "Get current weather for a city",
"parameters": {
"type": "object",
"properties": {"city": {"type": "string"}},
"required": ["city"]
}
}
}
]
response = client.chat.completions.create(
model="prime-intellect/intellect-3",
messages=[{"role": "user", "content": "What's the weather in New York?"}],
tools=tools
)
モデルがツールを呼び出す場合、response.choices[0].message.tool_callsに引数を返します。関数を外部で実行し、その結果をフォローアップメッセージでフィードバックします。このパターンにより、INTELLECT-3の環境学習された動作を活かしたエージェントワークフローが構築されます。
エラー処理は重要な部分です。一般的な問題には、401(無効なキー)、429(レート制限)、400(不正なリクエスト)などがあります。指数関数的バックオフによるリトライを実装します。
import time
from openai import OpenAIError
try:
response = client.chat.completions.create(...)
except OpenAIError as e:
if e.status_code == 429:
time.sleep(2 ** e.attempt) # Backoff
# Retry logic here
raise
応答には、usage(`prompt_tokens`、`completion_tokens`、`total_tokens`)のようなメタデータが含まれており、これを最適化のためにログに記録します。INTELLECT-3は、1回の完了につき最大4096トークンを処理し、深さと速度のバランスを取ります。
ストリーミング応答はリアルタイムアプリケーションを強化します。create呼び出しにstream=Trueを追加すると、クライアントはServer-Sent Eventsとしてチャンクを生成します。それらを反復的に解析します。
stream = client.chat.completions.create(..., stream=True)
for chunk in stream:
if chunk.choices[0].delta.content is not None:
print(chunk.choices[0].delta.content, end="")
この技術は、ユーザーが段階的なフィードバックを期待するチャットボットやライブコードアシスタントに適しています。
リクエスト作成を習得したら、パフォーマンスを評価します。次のセグメントでは、INTELLECT-3に特化したベンチマークツールを紹介します。
INTELLECT-3 APIの使用を最適化し評価する
API呼び出しは、パラメータを経験的に調整することで最適化できます。スループットを向上させるために、複数のメッセージを1つのリクエストにバッチ処理することから始めます。評価スイートでは最大10倍の効率性が得られます。Prime IntellectのCLIはこれをサポートしています。
prime env eval gsm8k -m prime-intellect/intellect-3 -n 100 --batch-size 8
このコマンドは、100個のGSM8Kサンプルを実行し、精度とレイテンシーのメトリクスを集計します。結果を分析してtop_pやfrequency_penaltyを調整し、長い生成における繰り返しを軽減します。
評価は、検証者ハブからのカスタム環境にも及びます。RL環境をロードし、INTELLECT-3をポリシーとしてクエリします。
from prime_rl.environments import load_env
env = load_env("theorem_prover")
observation = env.reset()
response = client.chat.completions.create(
model="prime-intellect/intellect-3",
messages=[{"role": "user", "content": observation}]
)
action = parse_response(response) # Custom parser
next_obs, reward, done = env.step(action)
報酬は改善を定量化し、ローカルでホストしている場合はファインチューニングをガイドします。APIのみのユーザーの場合、インタラクションをベクトルデータベースにログ記録し、タスク成功率などの下流メトリクスを計算します。
セキュリティも重要です。プロンプトインジェクションを防ぐためにユーザー入力をサニタイズし、境界を強制するためにシステムプロンプトを使用します。INTELLECT-3のRLの背景は幻覚を減らしますが、高いリスクを伴うアプリケーションでは検証者に対して出力を検証する必要があります。
スケーリングには、ダッシュボードを介した監視が含まれます。トークンのしきい値に対するアラートを設定し、Prime Intellectがクラスター向けに公開しているPrometheusのような可観測性ツールと統合します。これにより、使用量が増加しても信頼性を維持できます。
最適化に対処したので、次にコストを検討します。価格の透明性は、持続可能な統合を保証します。
INTELLECT-3 APIの料金:透明性の高いトークンベースモデル
Prime Intellectは、トークン消費量に基づいて料金を構造化し、入力と出力で個別に課金します。1,000トークンごとに料金が発生し、料金はモデルとプロバイダーによって異なります。INTELLECT-3の場合、100万入力トークンあたり約0.50ドル、100万出力あたり約1.50ドルという競争力のある数字が予想されますが、正確な値はモデルのエンドポイント応答に表示されます。
| プロバイダー | 入力 ($$ /100万トークン) | 出力 ($$ /100万トークン) | 備考 |
|---|---|---|---|
| Prime Intellectダイレクト | ~$0.45–$0.60 | ~$1.30–$1.80 | 最低コスト、ボリュームディスカウント |
| OpenRouter | ~$0.60–$0.80 | ~$1.80–$2.40 | OpenRouterプラットフォーム手数料を含む |
正確な料金は変動します。常にダッシュボードまたはモデルエンドポイントを介して最新の値をチェックしてください。
どちらを選択すべきか?
- 最大の速度、最低のコスト、または大容量の使用を計画している場合は、Prime Intellectダイレクトを選択してください。
- 50以上のモデルで単一のAPIキーを希望する場合、即時オンボーディングが必要な場合、または組み込みのフォールバックルーティングが必要な場合は、OpenRouterを選択してください。
どちらのオプションも同じINTELLECT-3のパフォーマンスを提供します。ワークフローに最適なものを選んでください。多くのチームでは、冗長性のために両方を同時に使用することさえあります。
このガイドの残りの部分(リクエスト形式、ストリーミング、ツール呼び出し、最適化など)は、Prime Intellectを直接呼び出すか、OpenRouterを介して呼び出すかに関わらず、等しく適用されます。
以下の完全な技術実装の詳細に進み、あなたにとって最適なゲートウェイを介して、今すぐINTELLECT-3で構築を始めてください。
INTELLECT-3 APIとの高度な統合
INTELLECT-3をLangChainやLlamaIndexのようなエコシステムに拡張してオーケストレーションできます。LangChainでは:
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
llm = ChatOpenAI(model="prime-intellect/intellect-3", openai_api_key=os.environ["PRIME_API_KEY"], openai_api_base="https://api.pinference.ai/api/v1")
prompt = ChatPromptTemplate.from_template("Translate {text} to French.")
chain = prompt | llm
print(chain.invoke({"text": "Hello, world!"}))
これにより、APIが検索拡張生成(RAG)パイプラインに結合され、外部知識による精度が向上します。
マイクロサービスの場合、INTELLECT-3にプロキシするFastAPIラッパーを介してデプロイします。
from fastapi import FastAPI
from openai import OpenAI
app = FastAPI()
client = OpenAI(...) # As above
@app.post("/generate")
def generate(body: dict):
response = client.chat.completions.create(model="prime-intellect/intellect-3", **body)
return {"content": response.choices[0].message.content}
このエンドポイントをRedisでレート制限をかけて安全に公開します。このような設定は、コンテンツジェネレーターから研究アシスタントまで、SaaSツールを強化します。
エッジケースには注意が必要です。トークンオーバーフローは入力の動的な切り捨てで処理し、INTELLECT-3がキューに入っている場合は、より小さなモデルにフォールバックします。Prime Intellectのサイトにあるコミュニティフォーラムでは、トラブルシューティングスレッドが提供されています。
結論:INTELLECT-3 APIを自信を持ってデプロイする
INTELLECT-3 APIを使用するための包括的なツールキットを手にしました。オープンソースのルーツから、正確なリクエスト処理、コスト管理に至るまで、このガイドは実際のデプロイメントに役立ちます。Apidogを試してワークフローを洗練させ、ドキュメントの更新を監視してください。
これらの技術を段階的に実装してください。簡単なチャットから始め、その後エージェントにスケールアップします。INTELLECT-3の効率性とオープンさは、技術的なAIプロジェクトにとって頼りになる存在となるでしょう。今すぐコーディングを開始し、アプリケーションへの影響を実感してください。