メタのLlama 4モデル、すなわちLlama 4 MaverickとLlama 4 Scoutは、マルチモーダルAI技術における飛躍的進歩を表しています。2025年4月5日にリリースされたこれらのモデルは、Mixture-of-Experts(MoE)アーキテクチャを活用し、テキストと画像の効率的な処理を実現し、驚異的なパフォーマンス対コスト比を提供します。開発者は、さまざまなプラットフォームが提供するAPIを通じてこれらの機能を活用できるため、アプリケーションへの統合がシームレスで強力になります。
Llama 4 MaverickとLlama 4 Scoutの理解
APIの使用に入る前に、これらのモデルのコア仕様を把握しましょう。Llama 4はネイティブマルチモーダリティを導入しており、テキストと画像を開始から一緒に処理します。さらに、MoEデザインはタスクごとにパラメータのサブセットのみをアクティブ化し、効率を向上させます。
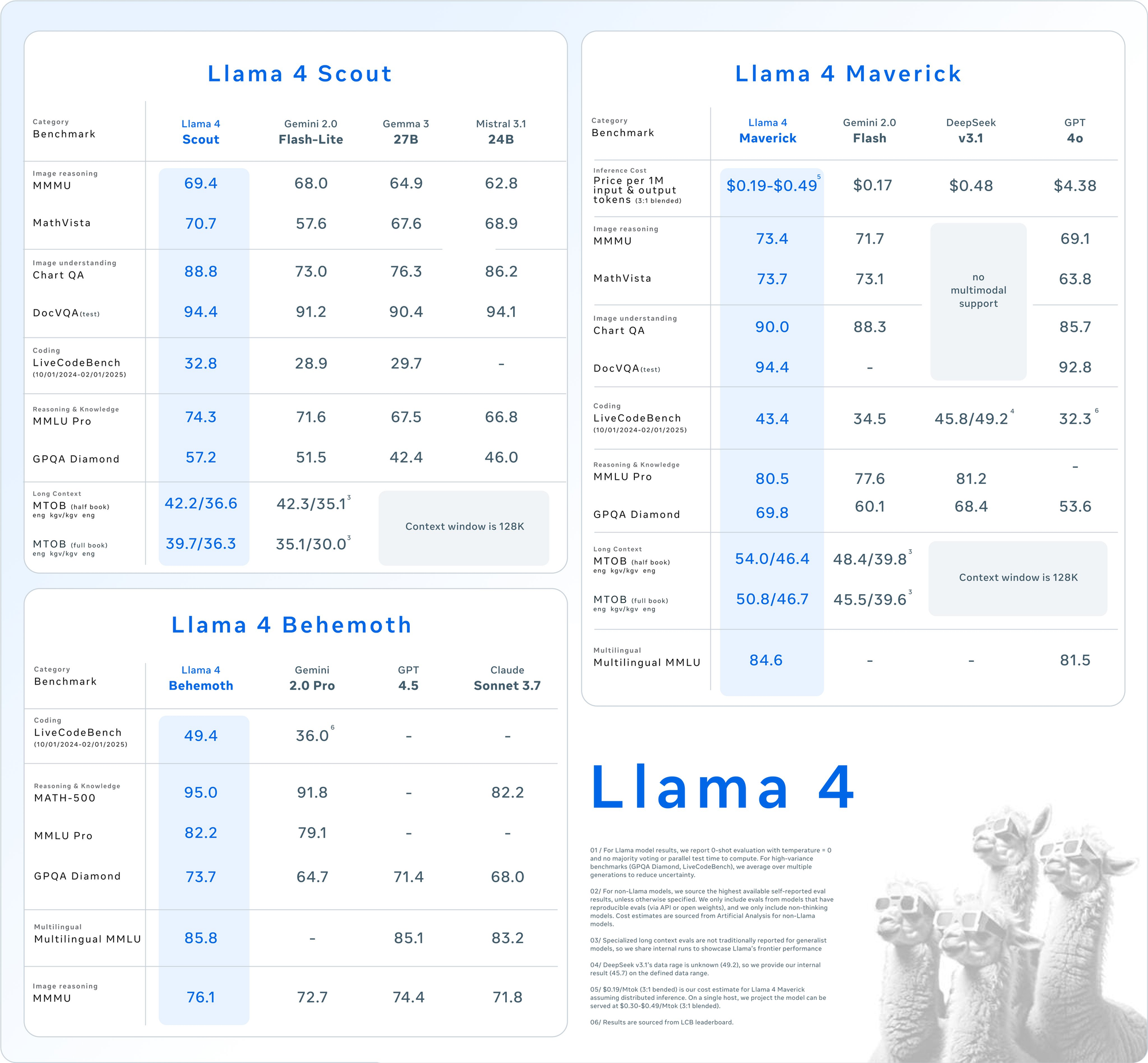
Llama 4 Scout: 効率的なマルチモーダルワークホース
- パラメータ: 170億のアクティブ、1090億の合計、16のエキスパート。
- コンテキストウィンドウ: 最大1000万トークン。
- 主な特徴: 多文書要約や大規模コードベースに対する推論など、長いコンテキストのタスクに優れている。単一のNVIDIA H100 GPUでINT4量子化を用いて動作します。
- ユースケース: 高速でリソース効率の良いマルチモーダル処理を必要とする開発者に最適。
Llama 4 Maverick: 多用途のパワーハウス
- パラメータ: 170億のアクティブ、4000億の合計、128のエキスパート。
- コンテキストウィンドウ: 最大100万トークン。
- 主な特徴: 12の言語(英語、スペイン語、ヒンディー語など)をサポートし、高品質なテキストと画像の理解を提供。チャットやクリエイティブライティング向けに最適化されています。
- ユースケース: エンタープライズグレードのアシスタントや多言語アプリケーションに適しています。
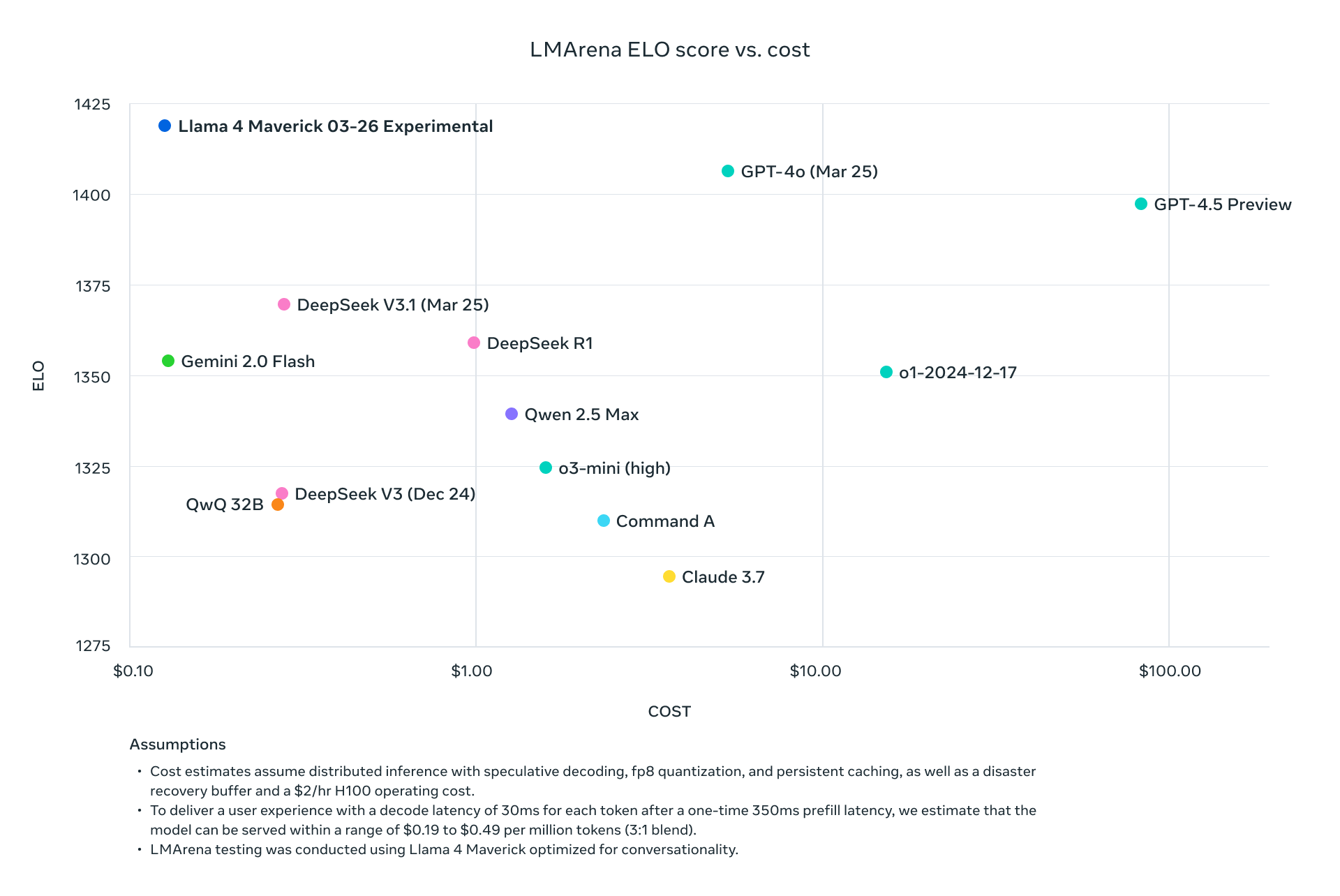
両モデルはLlama 3の前モデルを上回り、GPT-4oのような業界の巨人と競争し、API駆動プロジェクトにおいて魅力的な選択肢となります。
Llama 4 APIを使用する理由
APIを介してLlama 4を統合することで、これらの巨大なモデルをローカルでホストする必要がなくなり、通常は大規模なハードウェア(Maverickの場合、NVIDIA H100 DGXなど)が必要です。その代わり、Groq、Together AI、OpenRouterのようなプラットフォームが管理されたAPIを提供し、以下の利点を提供します:
- スケーラビリティ: インフラオーバーヘッドなしで異なる負荷に対応。
- コスト効率: トークンあたり支払い、Scoutは$0.11/M入力トークンなどの低価格。
- 使いやすさ: シンプルなHTTPリクエストでマルチモーダル機能にアクセス。
次に、これらのAPIを呼び出すための環境をセットアップしましょう。
Llama 4 API呼び出しのための環境設定
Llama 4 MaverickとLlama 4 Scoutと< strong>APIを介して対話するためには、開発環境を準備します。以下の手順に従ってください:
ステップ1: APIプロバイダーを選択
いくつかのプラットフォームがLlama 4 APIをホストしています。以下は人気のオプションです:
- Groq: 低コストの推論を提供(Scout: $0.11/M入力、Maverick: $0.50/M入力)。
- Together AI: カスタムスケーリングを備えた専用エンドポイントを提供。
- OpenRouter: テストに理想的な無料プランが利用可能。
- Cloudflare Workers AI: Scoutサポートのサーバーレス展開。
このガイドでは、その堅実なドキュメントとパフォーマンスを考慮してGroqとTogether AIを例として使用します。
ステップ2: APIキーを取得
- Groq: groq.comにサインアップし、Developer Consoleに移動してAPIキーを生成します。
- Together AI: together.aiに登録し、ダッシュボードからAPIキーにアクセスします。
これらのキーを安全に保管(環境変数など)し、ハードコーディングを避けましょう。
ステップ3: 依存関係をインストール
簡単さのためにPythonを使用します。必要なライブラリをインストールします:
pip install requests
テスト用に、ApidogはAPIエンドポイントを視覚的にデバッグすることによってこのセットアップを補完します。
最初のLlama 4 APIコールを行う
環境が整ったら、Llama 4 APIにリクエストを送信します。基本的なテキスト生成例から始めましょう。
例1: Llama 4 Scoutを使ったテキスト生成(Groq)
import requests
import os
# APIキーを設定
API_KEY = os.getenv("GROQ_API_KEY")
URL = "https://api.groq.com/v1/chat/completions"
# ペイロードを定義
payload = {
"model": "meta-llama/Llama-4-Scout-17B-16E-Instruct",
"messages": [
{"role": "user", "content": "AIについての短い詩を書いてください。"}
],
"max_tokens": 150,
"temperature": 0.7
}
# ヘッダーを設定
headers = {
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json"
}
# リクエストを送信
response = requests.post(URL, json=payload, headers=headers)
print(response.json()["choices"][0]["message"]["content"])
出力: Scoutによって生成された簡潔な詩、効率的なMoEアーキテクチャを活用。
例2: Llama 4 Maverickを使ったマルチモーダル入力(Together AI)
Maverickはマルチモーダルタスクで光ります。画像を説明する方法は以下の通りです:
import requests
import os
# APIキーを設定
API_KEY = os.getenv("TOGETHER_API_KEY")
URL = "https://api.together.ai/v1/chat/completions"
# 画像とテキストを含むペイロードを定義
payload = {
"model": "meta-llama/Llama-4-Maverick-17B-128E-Instruct-FP8",
"messages": [
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {"url": "https://example.com/sample.jpg"}
},
{
"type": "text",
"text": "この画像を説明してください。"
}
]
}
],
"max_tokens": 200
}
# ヘッダーを設定
headers = {
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json"
}
# リクエストを送信
response = requests.post(URL, json=payload, headers=headers)
print(response.json()["choices"][0]["message"]["content"])
出力: 画像の詳細な説明で、Maverickの画像とテキストの整合性を示しています。
パフォーマンスのためのAPIリクエストの最適化
効率を最大化するために、Llama 4 APIコールを調整しましょう。以下のテクニックを考慮してください:
コンテキスト長の調整
- Scout: 長文書用に10Mトークンウィンドウを使用します。大きな入力を処理するために、
max_model_len(サポートされている場合)を設定します。 - Maverick: チャットアプリケーションのために1Mトークンに制限して、速度と品質のバランスを取ります。
パラメータの微調整
- 温度: 実用的な応答には低く(例:0.5)、創造性には高く(例:1.0)設定します。
- 最大トークン数: 不要な計算を避けるために出力長を制限します。
バッチ処理
1回のリクエストで複数のプロンプトを送信します(APIがサポートしている場合)して、レイテンシを減少させます。バッチエンドポイントについてはプロバイダーのドキュメントを確認してください。
Llama 4 APIを使った高度なユースケース
今、Llama 4の全潜在能力を引き出すために高度な統合を探検しましょう。
ユースケース1: 多言語チャットボット
Maverickは12の言語をサポートしています。カスタマーサポートボットを構築します:
payload = {
"model": "meta-llama/Llama-4-Maverick-17B-128E-Instruct-FP8",
"messages": [
{"role": "user", "content": "Hola, ¿cómo puedo resetear mi contraseña?"}
],
"max_tokens": 100
}
response = requests.post(URL, json=payload, headers=headers)
print(response.json()["choices"][0]["message"]["content"])
出力: Maverickの多言語流暢さを活用したスペイン語の応答。
ユースケース2: Scoutを使った文書要約
Scoutの10Mトークンウィンドウは大量のテキストの要約に優れています:
long_text = "..." # ここに長文を挿入
payload = {
"model": "meta-llama/Llama-4-Scout-17B-16E-Instruct",
"messages": [
{"role": "user", "content": f"これを要約してください: {long_text}"}
],
"max_tokens": 300
}
response = requests.post(URL, json=payload, headers=headers)
print(response.json()["choices"][0]["message"]["content"])
出力: Scoutによって効率的に処理された簡潔な要約。
Apidogを使用したデバッグとテスト
APIをテストするのは難しいことがあります、特にマルチモーダル入力では。ここでApidogが活躍します:
- 視覚インターフェース: コーディングなしでリクエストの構築と送信が可能。
- エラー追跡: レート制限や不正なペイロードなどの問題を特定。
- モック応答: フロントエンド開発用にLlama 4の出力をシミュレーション。
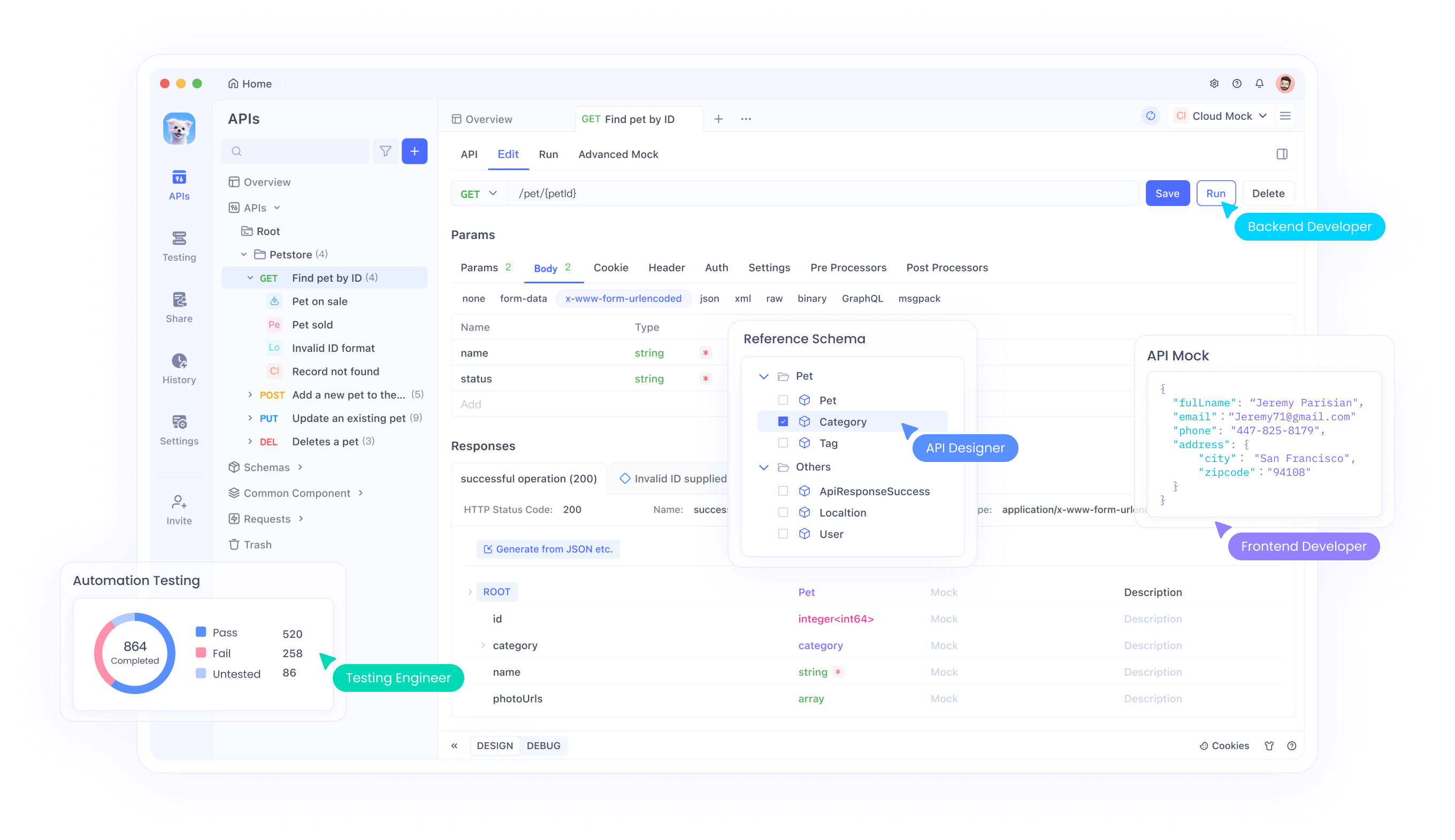
上記の例をApidogでテストするには:
- Apidogを開いて新しいリクエストを作成します。
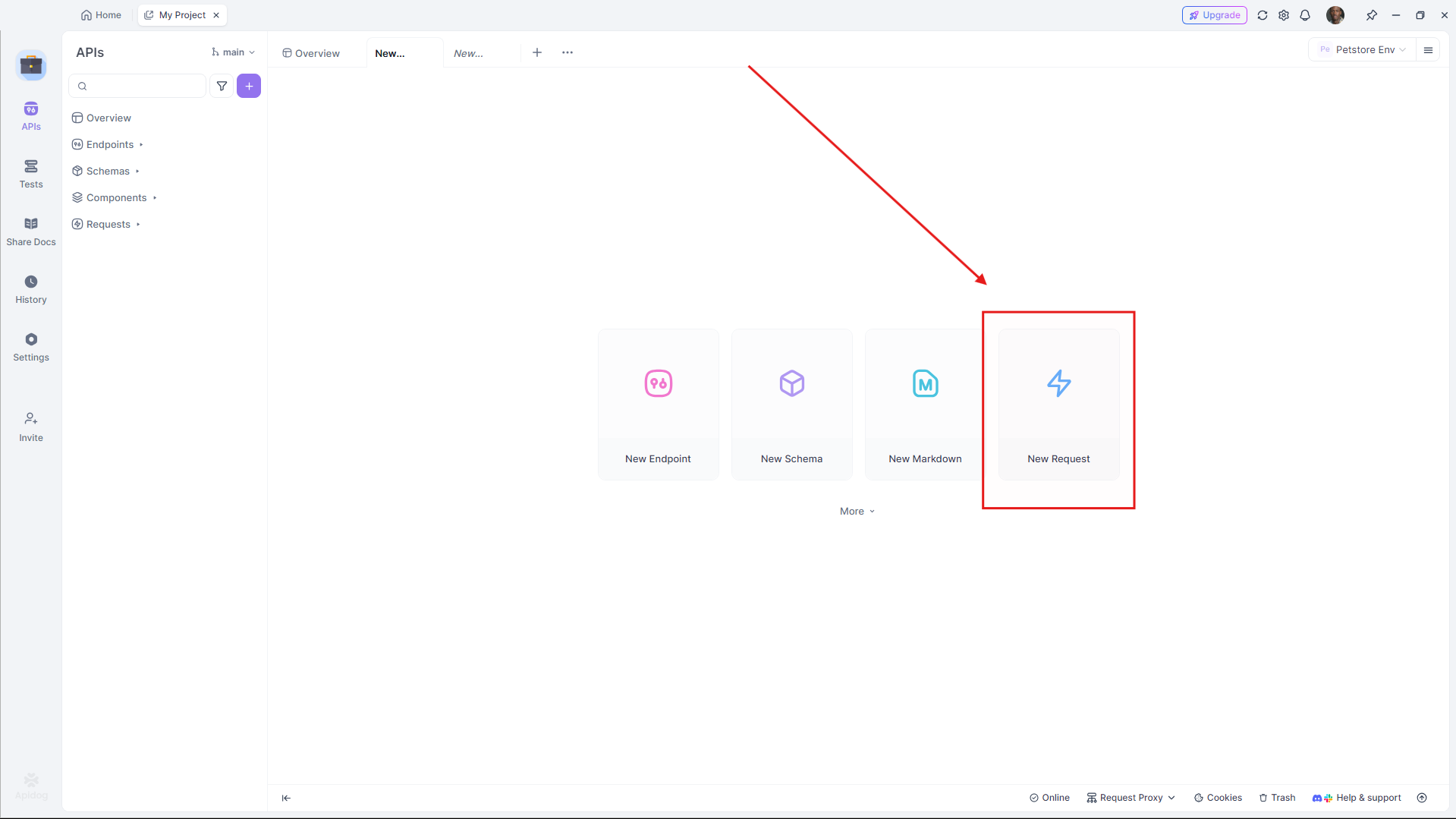
- URLを設定します(例:
https://api.groq.com/v1/chat/completions)。

- ヘッダー(
Authorization、Content-Type)を追加します。
- JSONペイロードを貼り付けます。

- 送信して応答を確認します。

このワークフローにより、あなたのLlama 4 API統合がスムーズに実行されることが保証されます。
Llama 4のためのAPIプロバイダーの比較
適切なプロバイダーを選ぶことはコストとパフォーマンスに影響します。以下は要約です:
| プロバイダー | モデルサポート | 価格(入力/出力 per M) | コンテキスト制限 | ノート |
|---|---|---|---|---|
| Groq | Scout、Maverick | $0.11/$0.34(Scout)、$0.50/$0.77(Maverick) | 128K(拡張可能) | 最低コスト、高速 |
| Together AI | Scout、Maverick | カスタム(専用エンドポイント) | 1M(Maverick) | スケーラブル、企業志向 |
| OpenRouter | 両方 | 無料プランあり | 128K | テストに最適 |
| Cloudflare | Scout | 使用量ベース | 131K | サーバーレスの簡潔さ |
プロジェクトの規模と予算に応じて選択してください。プロトタイピングには、OpenRouterの無料プランから始め、その後GroqやTogether AIでスケールアップします。
Llama 4 API統合のベストプラクティス
堅実な統合を確保するために、以下のガイドラインに従ってください:
- レート制限: プロバイダーの制限を尊重します(例:Groqの100リクエスト/分)。再試行のために指数バックオフを実装します。
- エラーハンドリング: HTTPエラー(例:429 Too Many Requests)をキャッチし、ログに記録します。
- セキュリティ: APIキーを暗号化し、HTTPSエンドポイントを使用します。
- モニタリング: トークンの使用状況を追跡してコストを管理します、特にMaverickの高い料金に注意します。
一般的なAPI問題のトラブルシューティング
問題に直面しましたか?速やかに対処してください:
- 401 Unauthorized: APIキーを確認します。
- 429 Rate Limit Exceeded: リクエストの頻度を減らすか、プランをアップグレードします。
- ペイロードエラー: JSON形式がプロバイダーの仕様と一致することを確認します(例:
messages配列)。
Apidogは、これらの問題を視覚的に診断するのに役立ち、時間を節約します。
結論
Llama 4 MaverickとLlama 4 Scoutを< strong>API経由で統合することで、開発者は最小限のオーバーヘッドで最先端のアプリケーションを構築できます。Scoutの長文コンテキスト効率が必要であれ、Maverickの多言語能力が必要であれ、これらのモデルはアクセス可能なエンドポイントを通じて一流のパフォーマンスを提供します。このガイドに従うことで、APIコールを効果的にセットアップ、最適化、トラブルシュートできます。
さらに深く探求する準備はできましたか?GroqやTogether AIのプロバイダーを試し、ワークフローを洗練するためにApidogを活用してください。マルチモーダルAIの未来はここにあります—今日から構築を始めましょう!