
視覚言語モデル(VLM)は、AIが視覚コンテンツを理解し、推論する能力を革命的に変えました。これらの革新の中で、Moonshot AI の Kimi VL Thinking モデルは特に印象的で、高度な推論能力と驚異的な効率を組み合わせています。このチュートリアルでは、Kimi VL Thinking の機能を理解し、OpenRouter のプラットフォームを通じて無料で使用する方法を案内します。
Kimi VL Thinking ベンチマーク
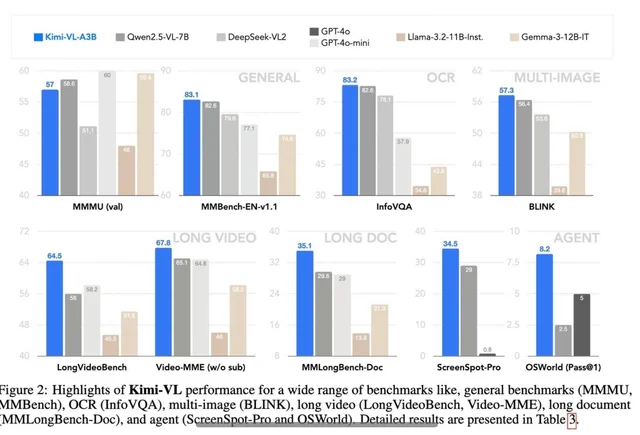
Kimi VL Thinking(正式には Kimi-VL-A3B-Thinking と呼ばれる)は、Moonshot AI によって開発された高度な視覚言語モデルです。このモデルが特別なのは、推論ステップごとにわずか 28 億のパラメータをアクティブにする Mixture-of-Experts(MoE)アーキテクチャを採用しており、合計で約 160 億のパラメータを持っていることです。これにより、比較的効率的な計算で洗練された推論を提供できます。
Kimi VL Thinking は、高度な推論タスク、特に視覚入力の段階的思考や数学的分析を必要とするタスクのために特別に設計されています。これは、Kimi VL 基本モデルをチェーン・オブ・ソート(CoT)による教師あり学習および強化学習技術でファインチューニングすることによって作成されました。
Kimi VL Thinking モデルの主な特徴
- 長いコンテキストウィンドウ:最大 128K トークンをサポートし、広範なマルチターンの会話や長文の処理を可能にします。
- ネイティブ解像度のビジョン:MoonViT エンコーダを使用して高解像度の視覚入力を処理し、優れた詳細認識を実現します。
- 高度な推論:特に数学的視覚推論と段階的な問題解決に強いです。
- 効率的な計算:その強力な能力にもかかわらず、モデルはわずか 28 億のパラメータをアクティブにし、より大規模な代替案よりもアクセスしやすくなっています。
- オープンソース:MIT ライセンスの下で利用可能で、広範な学術的および商業的用途に対応します。
Kimi VL Thinking ベンチマークのパフォーマンス
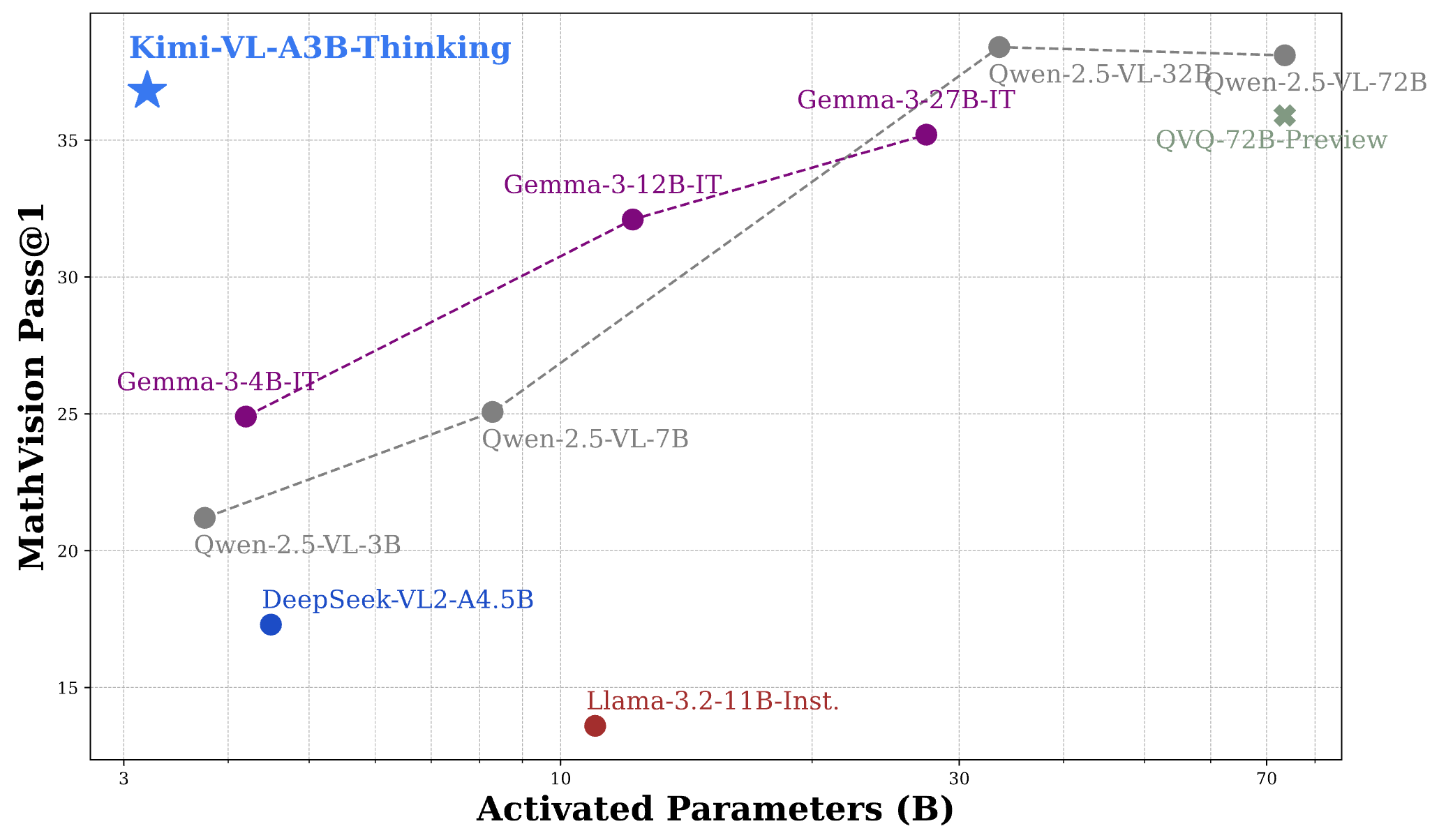
Kimi VL Thinking は、いくつかの難しいベンチマークで印象的なパフォーマンスを示し、しばしばより大きなモデルに匹敵するか、それを超えています:
- MathVision:スコア 36.8 (Pass@1) を達成し、Gemma-3-27B(35.5)や Qwen2.5-VL-72B(38.1)に近づく性能を持っています。
- MathVista:ミニベンチマークで 71.3 のスコアを獲得し、GPT-4o-mini(56.7)や Gemma-3-12B(56.4)を上回りました。
- MMMU(マルチモーダル大規模マルチタスク理解):検証セットで 61.7 に達し、複雑なマルチモーダルタスクで強い能力を示しています。
これらの結果を考えると、Kimi VL Thinking のパフォーマンスは、わずか 28 億のパラメータをアクティブにしながら、7 億、12 億、さらには 70 億以上のパラメータを使用するモデルと競争していることを考慮すると、非常に驚くべきものです。このため、最も効率的な推論能力を持つ VLM の 1 つとして位置付けられています。
OpenRouter を通じて Kimi VL Thinking を無料で使用する方法
OpenRouter は、モデルを自分でデプロイすることなく Kimi VL Thinking にアクセスする便利な方法を提供します。彼らの無料プランを利用することで、コストなしでモデルを試すことができます。始める方法は次の通りです:
ステップ 1: OpenRouter アカウントの作成
- OpenRouter のウェブサイトに訪れ、アカウントを持っていない場合はサインアップします。
- 登録後、アカウント設定に移動して API キーを生成します。
- この API キーを安全に保管してください。すべての API 呼び出しで必要です。
ステップ 2: OpenRouter API 構造の理解
OpenRouter の API は、OpenAI API 形式と互換性があるように設計されており、OpenAI のサービスにすでに慣れている場合、統合が簡単です。主な違いは次のとおりです:
- ベース URL:
https://openrouter.ai/api/v1 - モデル名:
moonshotai/kimi-vl-a3b-thinking:free - 分析用の追加のオプションヘッダー
ステップ 3: 最初の API 呼び出しの実行
Python ユーザー向けに、次の依存関係を使って環境を設定します:
pip install openai requests pillow
OpenAI SDK を使用して基本的な例から始めましょう。これは最も簡単なアプローチです:
from openai import OpenAI
from base64 import b64encode
from PIL import Image
import io
# OpenRouter のベース URL でクライアントを初期化
client = OpenAI(
base_url="<https://openrouter.ai/api/v1>",
api_key="your_openrouter_api_key_here",
)
# 画像をエンコードする関数
def encode_image(image_path):
with open(image_path, "rb") as image_file:
return b64encode(image_file.read()).decode('utf-8')
# 画像を読み込みエンコード
image_path = "path_to_your_image.jpg"
base64_image = encode_image(image_path)
# API リクエストを作成
completion = client.chat.completions.create(
extra_headers={
"HTTP-Referer": "your_site_url", # 分析用のオプション
"X-Title": "your_app_name", # 分析用のオプション
},
model="moonshotai/kimi-vl-a3b-thinking:free",
messages=[
{
"role": "user",
"content": [
{
"type": "image",
"image_url": {
"url": f"data:image/jpeg;base64,{base64_image}"
}
},
{
"type": "text",
"text": "この数学の問題を検討し、段階を追って解決してください。"
}
]
}
],
max_tokens=1024
)
print(completion.choices[0].message.content)
SDK を使わずに直接 API 呼び出しを行いたい場合:
import requests
import json
from base64 import b64encode
# 画像をエンコードする関数
def encode_image(image_path):
with open(image_path, "rb") as image_file:
return b64encode(image_file.read()).decode('utf-8')
# 画像を読み込みエンコード
image_path = "path_to_your_image.jpg"
base64_image = encode_image(image_path)
# API リクエストを作成
response = requests.post(
url="<https://openrouter.ai/api/v1/chat/completions>",
headers={
"Authorization": "Bearer your_openrouter_api_key_here",
"Content-Type": "application/json",
"HTTP-Referer": "your_site_url", # 分析用のオプション
"X-Title": "your_app_name", # 分析用のオプション
},
data=json.dumps({
"model": "moonshotai/kimi-vl-a3b-thinking:free",
"messages": [
{
"role": "user",
"content": [
{
"type": "image",
"image_url": {
"url": f"data:image/jpeg;base64,{base64_image}"
}
},
{
"type": "text",
"text": "この数学の問題を検討し、段階を追って解決してください。"
}
]
}
],
"max_tokens": 1024
})
)
print(response.json()["choices"][0]["message"]["content"])
長い応答やより良いユーザーエクスペリエンスのために、モデルの出力をストリーミングすることをお勧めします:
from openai import OpenAI
from base64 import b64encode
client = OpenAI(
base_url="<https://openrouter.ai/api/v1>",
api_key="your_openrouter_api_key_here",
)
# 画像をエンコードする関数
def encode_image(image_path):
with open(image_path, "rb") as image_file:
return b64encode(image_file.read()).decode('utf-8')
# 画像を読み込みエンコード
image_path = "path_to_your_image.jpg"
base64_image = encode_image(image_path)
# ストリーミングリクエストを作成
stream = client.chat.completions.create(
model="moonshotai/kimi-vl-a3b-thinking:free",
messages=[
{
"role": "user",
"content": [
{
"type": "image",
"image_url": {
"url": f"data:image/jpeg;base64,{base64_image}"
}
},
{
"type": "text",
"text": "この数学の問題を検討し、段階を追って解決してください。"
}
]
}
],
stream=True,
max_tokens=1024
)
# ストリーミング応答を処理
for chunk in stream:
if chunk.choices[0].delta.content:
print(chunk.choices[0].delta.content, end="", flush=True)
Apidog を使った Kimi VL Thinking API のテスト
Apidog は、Kimi VL Thinking のような API とインタラクションするプロセスを簡素化する包括的な API テストツールです。環境管理やシナリオシミュレーションなどの機能を備えており、開発者に最適です。Apidog を使用して Kimi VL ThinkingAPI をテストする方法を見てみましょう。
Apidog の設定
まず、apidog.com から Apidog をダウンロードしてインストールします。インストールが完了したら、新しいプロジェクトを作成し、Kimi VL Thinking API エンドポイントを追加します:https://openrouter.ai/api/v1/chat/completions.
環境の設定
次に、Apidog でさまざまな環境(例:開発と本番)を設定します。API キーやベース URL などの変数を定義して、セットアップ間で簡単に切り替えができるようにします。Apidog の「環境」タブに移動し、次の項目を追加します:
api_key: あなたの OpenRouter API キーbase_url:https://openrouter.ai/api/v1
テストリクエストの作成
次に、Apidog で新しい POST リクエストを作成します。
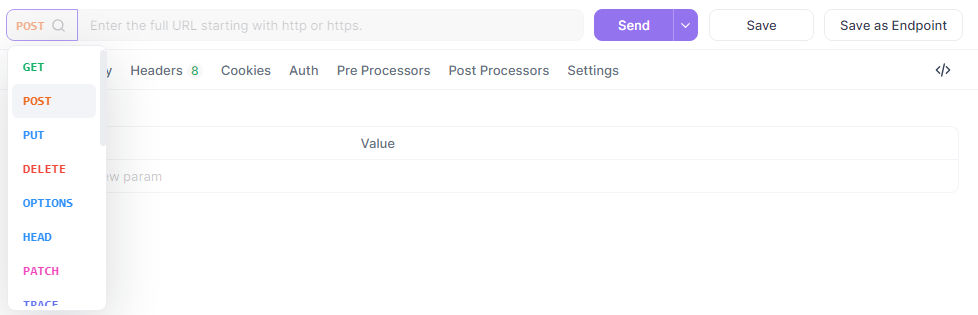
URL を {{base_url}}/chat/completions に設定し、ヘッダーを追加し、JSON ボディを入力します:
{
"model": "quasar-alpha",
"messages": [
{"role": "user", "content": "JavaScript における let と const の違いを説明してください。"}
],
"max_tokens": 300
}
ヘッダーセクションに、次を追加します:
Authorization:Bearer {{api_key}}Content-Type:application/json
テストの実行と分析
最後に、リクエストを送信し、Apidog のビジュアルインターフェースで応答を分析します。Apidog は、応答時間、ステータスコード、トークン使用量など、詳細なレポートを提供します。このリクエストを再利用可能なシナリオとして保存することもできます。

Apidog の現実的なシナリオをシミュレーションし、エクスポート可能なレポートを生成する能力は、Kimi VL Thinking API とのインタラクションをデバッグおよび最適化するための強力なツールとなります。それでは、いくつかのベストプラクティスで締めくくりましょう。
Kimi VL Thinking 用のプロンプトの最適化
Kimi VL Thinking は段階的な推論に優れているため、プロンプトをこの機能を生かすように構成しましょう:
- 推論について明確にする:モデルに「段階を追って考える」や「この問題を慎重に推論する」ように要求します。
- 一度に一つのタスク:複雑な問題については、一度にすべてを尋ねるのではなく、管理可能なステップに分けて尋ねます。
- コンテキストを提供する:関連する場合は、モデルが問題をよりよく理解できるように背景情報を提供します。
- 明確な指示を使用する:モデルにどのように画像を分析してほしいかを具体的に指定します。
結論
Kimi VL Thinking は、効率的でありながら強力な視覚言語モデルにおいて印象的な成果を表しています。わずか 28 億のパラメータをアクティブにしながら高度な推論を行う能力により、従来の大規模モデルよりも幅広いユーザーがアクセスできるようになっています。
OpenRouter の無料プランを活用することで、コストの壁なしにこの最先端技術を試すことができます。教育アプリケーション、データ分析、技術文書作成などに取り組んでいる場合でも、Kimi VL Thinking は視覚コンテンツを理解し推論するための強力なツールを提供します。
モデルに慣れてくると、より複雑な使用ケースを探究し、可能性としてプロダクションアプリケーションに統合することもできます。無料プランは実験に最適ですが、高ボリュームのプロダクションユースケースには、より良い信頼性と性能の保証のために有料プランへのアップグレードを検討することをお勧めします。
Kimi VL Thinking を今すぐ探索し、高度な視覚推論機能があなたのプロジェクトをどのように向上させるかを発見してください!