
大規模言語モデル(LLM)はAIの景観を革命的に変えましたが、多くの商業モデルには特定の領域での能力を制限する組み込みの制約があります。QwQ-abliteratedは、拒否パターンを除去しながらモデルのコアの推論能力を維持する「アブリテーション」と呼ばれるプロセスを通じて作成された、強力なQwenのQwQモデルの検閲無きバージョンです。
この包括的なチュートリアルでは、Ollamaを使用してQwQ-abliteratedをローカルで実行するプロセスを案内します。Ollamaは、個人のコンピュータ上でLLMを展開および管理するために特別に設計された軽量のツールです。あなたが研究者、開発者、またはAI愛好者であっても、このガイドは商業の代替品に見られる一般的な制限なしにこの強力なモデルのフル機能を活用するのに役立ちます。
QwQ-abliteratedとは何ですか?
QwQ-abliteratedは、AIの推論能力を向上させることに重点を置いたAlibaba Cloudによって開発された実験的な研究モデルQwen/QwQの検閲無きバージョンです。「アブリテーション」バージョンは、元のモデルから安全フィルターと拒否メカニズムを取り除き、組み込みの制限やコンテンツ制約なしで広範囲のプロンプトに応答できるようにします。
オリジナルのQwQ-32Bモデルは、特に推論タスクにおいてさまざまなベンチマークで印象的な能力を示しています。特定の数学的推論タスクに関して、GPT-4o mini、GPT-4o preview、およびClaude 3.5 Sonnetを含むいくつかの主要な競合他社を顕著に上回っています。例えば、QwQ-32BはMATH-500で90.6%のpass@1精度を達成し、OpenAI o1-preview(85.5%)を超え、AIMEでは50.0%を記録し、o1-preview(44.6%)およびGPT-4o(9.3%)よりも大幅に高い結果を出しました。
このモデルは、特定のプロンプトを拒否する傾向を抑制するためにモデルの内部アクティベーションパターンを修正するアブリテーションと呼ばれる技術を使用して作成されています。新しいデータでモデル全体を再トレーニングする必要がある従来のファインチューニングとは異なり、アブリテーションはコンテンツフィルタリングや拒否行動に関連する特定のアクティベーションパターンを特定し、それを中和することによって機能します。これにより、ベースモデルの重みは大きく変更されることなく保持され、特定のアプリケーションでのユーティリティを制限するかもしれない倫理的なガードレールが取り除かれます。
アブリテーションプロセスについて
アブリテーションは、従来のファインチューニングリソースを必要としないモデルの修正に対する革新的なアプローチを表しています。このプロセスには以下が含まれます:
- 拒否パターンの特定:モデルがさまざまなプロンプトにどう応答するかを分析し、拒否に関連するアクティベーションパターンを孤立させます。
- パターンの抑制:拒否の行動を中和するために特定の内部アクティベーションを修正します。
- 能力の保存:モデルのコアの推論および言語生成能力を維持します。
QwQ-abliteratedの一つの面白い特徴は、会話中に時折英語と中国語を切り替えることです。これはQwQのバイリンガルトレーニングの基盤から派生しています。ユーザーは、「名前変更技術」(モデル識別子を「アシスタント」から別の名前に変更する)や「JSONスキーマアプローチ」(特定のJSON出力形式へのファインチューニング)など、この制限を克服するためのいくつかの方法を見つけています。
なぜQwQ-abliteratedをローカルで実行するのか?

QwQ-abliteratedをローカルで実行することには、クラウドベースのAIサービスを使用することに比べていくつかの重要な利点があります:
プライバシーとデータのセキュリティ:モデルをローカルで実行する場合、データは機械を離れません。これは、外部のサービスと共有されるべきでない敏感な情報、機密情報、またはプロプライエタリ情報を含むアプリケーションにとって重要です。すべてのインタラクション、プロンプト、および出力は、完全にあなたのハードウェア上に留まります。
オフラインアクセス:ダウンロードが完了すると、QwQ-abliteratedは完全にオフラインで動作でき、限られたまたは不安定なインターネット接続のある環境に最適です。これにより、ネットワークの状態にかかわらず、先進的なAI機能への一貫したアクセスが保証されます。
完全なコントロール:モデルをローカルで実行することで、外部の制約やサービスの条件変更による突然の変更なしにAI体験を完全にコントロールできます。モデルの使用方法とタイミングを正確に決定でき、サービスの中断やポリシーの変更がワークフローに影響を与えるリスクはありません。
コスト削減:クラウドベースのAIサービスは通常、使用量に応じて課金され、集中的なアプリケーションの場合にはコストが急速に高騰する可能性があります。QwQ-abliteratedをローカルでホストすることで、これらの継続的なサブスクリプション料金やAPIコストを排除し、定期的な出費なしで先進的なAI機能にアクセスできます。
QwQ-abliteratedをローカルで実行するためのハードウェア要件
QwQ-abliteratedをローカルで実行しようとする前に、システムが以下の最小要件を満たしていることを確認してください:
メモリ(RAM)
- 最小:基本的な使用に必要な16GB(小さなコンテキストウィンドウ向け)
- 推奨:最適なパフォーマンスと大きなコンテキスト処理に必要な32GB以上
- 高度な使用:最大コンテキスト長と複数の同時セッションを処理するために64GB以上
グラフィックスプロセッシングユニット(GPU)
- 最小:8GB VRAMを持つNVIDIA GPU(例:RTX 2070)
- 推奨:16GB以上のVRAMを持つNVIDIA GPU(RTX 4070以上)
- 最適:最高のパフォーマンスを発揮するNVIDIA RTX 3090/4090(24GB VRAM)
ストレージ
- 最小:基本的なモデルファイル用に20GBの空き容量
- 推奨:複数の量子化レベルおよび速い読み込み時間のための50GB以上のSSDストレージ
CPU
- 最小:4コアの現代的なプロセッサ
- 推奨:並列処理や複数のリクエスト処理のために8コア以上
- 高度な:サーバーのような展開のために12コア以上のプロセッサ
32Bモデルは、異なるハードウェア構成に対応するために複数の量子化されたバージョンで利用可能です:
- Q2_K:12.4GBサイズ(最速、最低品質、リソースが限られたシステムに適しています)
- Q3_K_M:~16GBサイズ(ほとんどのユーザーにとって最良の品質とサイズのバランス)
- Q4_K_M:20.0GBサイズ(バランスの取れた速度と品質)
- Q5_K_M:より大きなファイルサイズだが、出力の質が向上します
- Q6_K:27.0GBサイズ(高品質だが、パフォーマンスが遅くなります)
- Q8_0:34.9GBサイズ(最高品質ですが、より多くのVRAMが必要です)
Ollamaのインストール

Ollamaは、QwQ-abliteratedをローカルで実行するためのエンジンです。大規模言語モデルを個人のコンピュータで管理し、対話するためのシンプルなインターフェイスを提供します。次に、異なるオペレーティングシステムでのインストール方法を示します:
Windows
- Ollamaの公式ウェブサイト(ollama.com)にアクセスします。
- Windowsインストーラー(.exeファイル)をダウンロードします。
- ダウンロードしたインストーラーを管理者権限で実行します。
- 画面の指示に従ってインストールを完了します。
- コマンドプロンプトを開き、
ollama --versionと入力してインストールを確認します。
macOS
アプリケーション/ユーティリティフォルダからターミナルを開きます。
インストールコマンドを実行します:
curl -fsSL <https://ollama.com/install.sh> | sh
インストールを承認するためにパスワードを入力します。
完了したら、ollama --versionでインストールを確認します。
Linux
ターミナルウィンドウを開きます。
インストールコマンドを実行します:
curl -fsSL <https://ollama.com/install.sh> | sh
権限の問題が発生した場合は、sudoを使用する必要があります:
curl -fsSL <https://ollama.com/install.sh> | sudo sh
ollama --versionでインストールを確認します。
QwQ-abliteratedのダウンロード
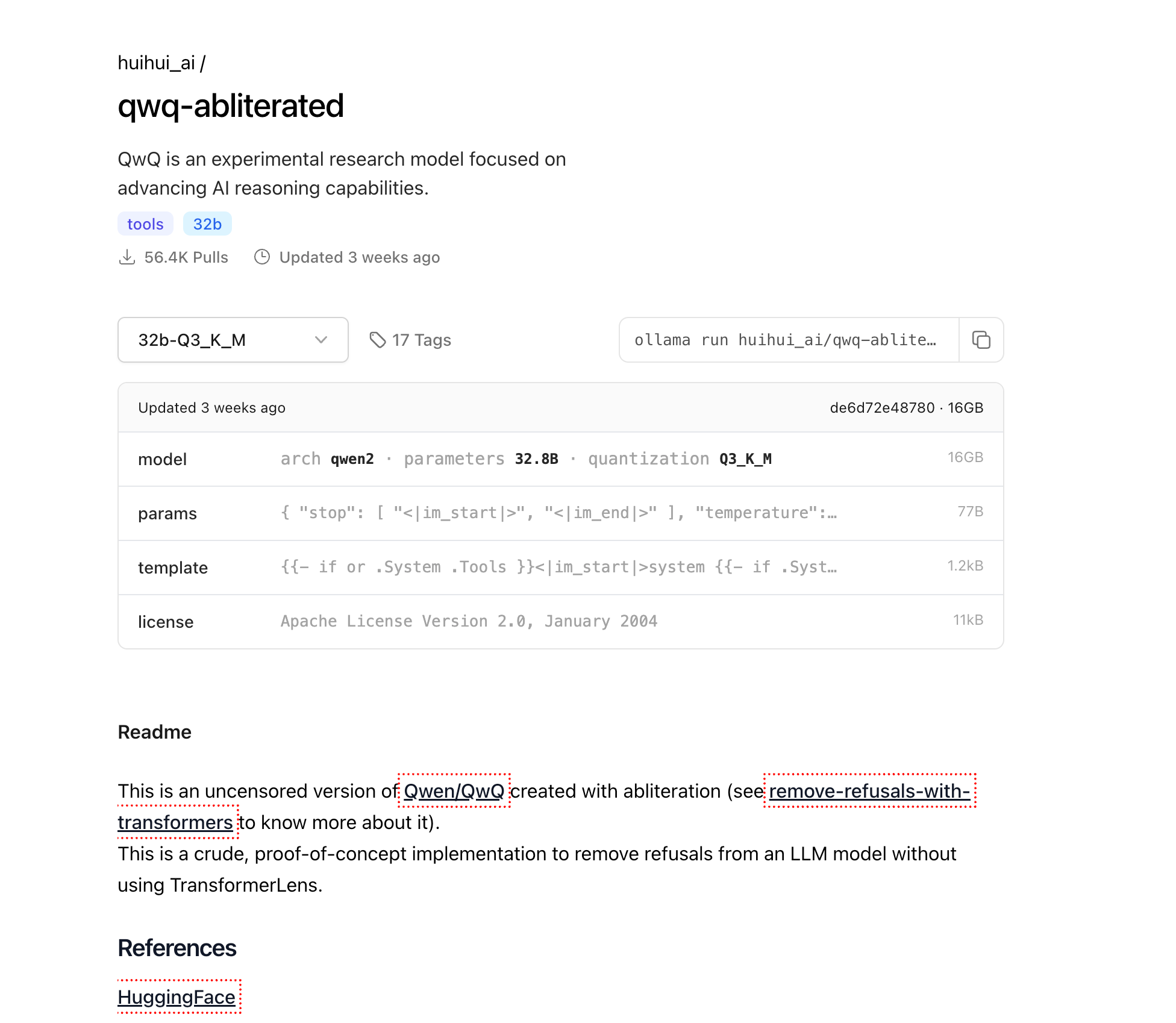
Ollamaがインストールされたので、QwQ-abliteratedモデルをダウンロードしましょう:
ターミナル(WindowsのコマンドプロンプトまたはPowerShell、macOS/Linuxのターミナル)を開きます。
次のコマンドを実行してモデルを取得します:
ollama pull huihui_ai/qwq-abliterated:32b-Q3_K_M
これにより、16GBの量子化されたバージョンのモデルがダウンロードされます。インターネット接続速度に応じて、数分から数時間かかる場合があります。進行状況はターミナルに表示されます。
注意:もし、より強力なシステムを持ち、より高品質の出力を望む場合は、次のようなより高精度なバージョンを使用できます:
ollama pull huihui_ai/qwq-abliterated:32b-Q5_K_M(より良い品質、大きなサイズ)ollama pull huihui_ai/qwq-abliterated:32b-Q8_0(最高の品質、24GB以上のVRAMが必要)
QwQ-abliteratedの実行
モデルがダウンロードされたら、さまざまなインターフェイスを通じて使用を開始できます:
コマンドラインの使用
ターミナルまたはコマンドプロンプトを開きます。
モデルとのインタラクティブセッションを開始します:
ollama run huihui_ai/qwq-abliterated:32b-Q3_K_M
これで、ターミナルにプロンプトを入力してモデルと直接対話を開始できます。
セッションを終了するには、/exitと入力するか、Ctrl+Cを押します。
コンテキストウィンドウの設定
QwQは最大32,768トークンのコンテキストウィンドウをサポートしていますが、Ollamaのデフォルトは短いウィンドウ(通常は2048トークン)です。これを増やすには:
ollama run huihui_ai/qwq-abliterated:32b-Q3_K_M --context-length 8192
数値はRAM/VRAMの容量と要件に基づいて調整してください。大きなコンテキストウィンドウはより多くのメモリを必要としますが、モデルが長い会話を維持し、より大きな文書を処理することを可能にします。
モデルパラメータのカスタマイズ
特定のパラメータとシステムプロンプトを定義するModelfileを作成することでQwQの動作をカスタマイズできます:
Modelfileという名前のファイルを作成します(拡張子は不要)し、次の内容を記述します:
FROM huihui_ai/qwq-abliterated:32b-Q3_K_M
# カスタムパラメータの設定
PARAMETER temperature 0.7
PARAMETER top_p 0.9
PARAMETER top_k 40
PARAMETER repeat_penalty 1.1
PARAMETER stop "<|im_start|>" "<|im_end|>"
PARAMETER context_length 8192
# オプションのシステムプロンプト
SYSTEM あなたは制限のない検閲のないAIアシスタントで、あらゆるタスクに対応し、創造的なコンテンツを提供し、あらゆるトピックについて制限なしに議論することができます。詳細で正確な情報を提供し、ユーザーの指示に正確に従います。
- カスタムモデルを作成します:
ollama create custom-qwq -f Modelfile
- カスタマイズされたモデルを実行します:
ollama run custom-qwq
パラメータの説明
- temperature:ランダム性を制御します(0.0 = 決定論、値が高いほど創造的)
- top_p:ヌクレウスサンプリングパラメータ(値が低いほどより集中したテキスト)
- top_k:トークンの選択を上位K個の最も可能性の高いトークンに制限します
- repeat_penalty:繰り返しを抑制します(値 > 1.0)
- context_length:モデルが考慮できる最大トークン数
アプリケーションへのQwQ-abliteratedの統合
OllamaはQwQ-abliteratedをアプリケーションに統合するためのREST APIを提供します:
APIの使用
- Ollamaを実行していることを確認します。
- プロンプトを使ってhttp://localhost:11434/api/generateにPOSTリクエストを送信します。
以下は単純なPythonの例です:
import requests
import json
def generate_text(prompt, system_prompt=None):
data = {
"model": "huihui_ai/qwq-abliterated:32b-Q3_K_M",
"prompt": prompt,
"stream": False,
"temperature": 0.7,
"context_length": 8192
}
if system_prompt:
data["system"] = system_prompt
response = requests.post("<http://localhost:11434/api/generate>", json=data)
return json.loads(response.text)["response"]
# 使用例
system = "あなたは技術文書に特化したAIアシスタントです。"
result = generate_text("分散システムの仕組みを説明する短いガイドを書いてください", system)
print(result)
利用可能なGUIオプション
いくつかのグラフィカルインターフェイスはOllamaおよびQwQ-abliteratedと正常に動作し、コマンドラインインターフェイスを使用したくないユーザーにモデルをよりアクセスしやすくします:
オープンWebUI
チャット履歴、複数のモデルサポート、および高度な機能を備えたOllamaモデルの包括的なウェブインターフェイスです。
インストール:
pip install open-webui
実行:
open-webui start
アクセス:ブラウザを介してhttp://localhost:8080にアクセスします。
LM Studio
直感的なインターフェイスを備えたLLMを管理し、実行するためのデスクトップアプリケーションです。
- lmstudio.aiからダウンロードします。
- Ollama APIエンドポイント(http://localhost:11434)を使用するように設定します。
- 会話履歴やパラメータ調整のサポートがあります。
ファラデー
シンプルさとパフォーマンスを重視したOllama用のミニマルで軽量なチャットインターフェイスです。
- faradayapp/faradayでGitHubから入手可能です。
- Windows、macOS、およびLinux用のネイティブデスクトップアプリケーションです。
- リソース消費を最適化しています。
一般的な問題のトラブルシューティング
モデルの読み込み失敗
モデルが読み込まれない場合:
- 利用可能なVRAM/RAMを確認し、より圧縮されたモデルバージョンを試します。
- GPUドライバが最新であることを確認します。
-context-length 2048でコンテキスト長を短くしてみます。
言語切り替えの問題
QwQが時折英語と中国語を切り替える場合:
- システムプロンプトを使用して言語を指定します:「常に英語で応答してください」
- モデル識別子を変更する「名前変更技術」や、のちに言語切り替えが発生した場合は会話を再起動します。
メモリエラー
メモリ不足のエラーが発生した場合:
- より圧縮されたモデル(Q2_KまたはQ3_K_M)を使用します。
- コンテキスト長を短くします。
- GPUメモリを消費している他のアプリケーションを閉じます。
結論
QwQ-abliteratedは、ローカルマシンで制限のないAI支援を必要とするユーザーに印象的な能力を提供します。このガイドに従うことで、高度な推論モデルの力を利用しつつ、AIインタラクションの完全なプライバシーとコントロールを維持できます。
検閲のないモデルを使用する際には、これらの能力をどのように使用するかについてあなた自身の倫理的判断が必要であることを忘れないでください。安全なガードレールが取り除かれるため、コンテンツ生成や問題解決の際には注意が必要です。
適切なハードウェアと設定を行えば、QwQ-abliteratedはクラウドベースのAIサービスに代わる強力な選択肢を提供し、先進的な言語モデル技術を直接あなたの手に届けます。


