

高価なクラウドサービスに依存したり、データプライバシーを心配したりすることなく、洗練されたAIビジョンモデルを自分のマシンで実行したいと思ったことはありませんか?そんなあなたに朗報です!今日は、**Qwen 3 VL(Vision Language)モデルをOllamaを使ってローカルで実行する方法**について深く掘り下げていきます。これはあなたのAI開発ワークフローにとって画期的なものになるでしょう。
技術的な話に入る前に、一つお尋ねします。APIレート制限に引っかかったり、クラウド推論に高額な費用を払ったり、あるいは単にAIモデルをより細かく制御したいと思っていませんか?もし「はい」と頷いたなら、このガイドはまさにあなたのために作られています。さらに、ローカルAI APIをテストおよびデバッグするための強力なツールを探しているなら、**Apidogを無料でダウンロードする**ことを強くお勧めします。Ollamaのローカルエンドポイントとシームレスに連携する優れたAPIテストプラットフォームです。
このガイドでは、Qwen 3 VLモデルをOllamaを使ってローカルで実行するために必要なすべてを、インストールから推論、トラブルシューティング、さらにはApidogのようなツールとの統合まで、順を追って説明します。この包括的なガイドを読み終える頃には、完全に機能し、プライベートで応答性の高いビジョン言語Qwen3-VLがあなたのローカルマシンでスムーズに動作し、それをプロジェクトに統合するために必要なすべての知識を身につけていることでしょう。
さあ、シートベルトを締め、お気に入りの飲み物を用意して、このエキサイティングな旅に一緒に出発しましょう。
Qwen3-VLを理解する:革新的なビジョン言語モデル

Qwen 3 VLを選ぶ理由、そしてローカルで実行する理由
技術的な手順に入る前に、**Qwen 3 VLがなぜ重要なのか**、そしてローカルで実行することがなぜ状況を一変させるのかについて話しましょう。
Qwen 3 VLはAlibabaのQwenシリーズの一部ですが、**ビジョン言語タスク**のために特別に設計されています。テキストのみを理解する従来のLLMとは異なり、Qwen 3 VLは以下のことができます。
- 画像を分析し、それに関する質問に答える(「この写真には何が写っていますか?」)
- 詳細なキャプションを生成する
- グラフ、図、またはドキュメントから構造化データを抽出する
- 視覚的コンテキストを持つマルチモーダルRAG(検索拡張生成)をサポートする
そして、オープンウェイト(Tongyi Qianwenライセンスの下)であるため、開発者はライセンス条項を遵守する限り、**自由に利用、変更、デプロイ**できます。
では、なぜ**ローカルで**実行するのでしょうか?
- プライバシー:あなたの画像やプロンプトがマシンから離れることはありません。
- コスト:API料金や利用制限がありません。
- カスタマイズ:独自のパイプラインでファインチューニング、量子化、または統合が可能です。
- オフラインアクセス:安全な環境やエアギャップ環境に最適です。
しかし、ローカルデプロイは、CUDAバージョン、Python環境、巨大なDockerfileとの格闘を意味していました。そこに**Ollama**が登場します。
モデルのバリアント:あらゆるユースケースに対応
Qwen3-VLは、さまざまなハードウェア構成やユースケースに合わせて、さまざまなサイズで提供されています。軽量なノートパソコンで作業している場合でも、強力なワークステーションを利用できる場合でも、あなたのニーズに完璧に合うQwen3-VLモデルがあります。
Denseモデル(従来のアーキテクチャ):
- Qwen3-VL-2B:エッジデバイスやモバイルアプリケーションに最適
- Qwen3-VL-4B:パフォーマンスとリソース使用量の優れたバランス
- Qwen3-VL-8B:中程度の推論を伴う汎用タスクに最適
- Qwen3-VL-32B:強力な推論と広範なコンテキストを必要とするハイエンドタスク向け
Mixture-of-Experts(MoE)モデル(効率的なアーキテクチャ):
- Qwen3-VL-30B-A3B:わずか30億のアクティブパラメータで効率的なパフォーマンス
- Qwen3-VL-235B-A22B:合計2350億パラメータのうち220億のみがアクティブな大規模アプリケーション向け
MoEモデルの利点は、各推論で「エキスパート」ニューラルネットワークのサブセットのみをアクティブ化するため、計算コストを管理可能な範囲に保ちながら、膨大なパラメータ数を可能にすることです。
Ollama:ローカルAIの卓越性へのゲートウェイ
Qwen3-VLがもたらすものを理解したところで、なぜOllamaがこれらのモデルをローカルで実行するための理想的なプラットフォームなのかについて話しましょう。Ollamaをオーケストラの指揮者のように考えてみてください。舞台裏で起こるすべての複雑なプロセスを指揮し、あなたが最も重要なこと、つまりAIモデルの使用に集中できるようにします。
Ollamaとは何か、そしてなぜQwen 3 VLに最適なのか
Ollamaは、**単一のコマンドで大規模言語モデル(そして現在はマルチモーダルモデル)をローカルで実行できる**オープンソースツールです。「LLMのためのDocker」のようなものですが、さらにシンプルです。
主な機能:
- 自動GPUアクセラレーション(macOSではMetal、LinuxではCUDA経由)
- 組み込みモデルライブラリ(Llama 3、Mistral、Gemma、そして現在はQwenを含む)
- 簡単な統合のためのREST API
- 軽量で初心者にも優しい
何よりも、**Ollamaは現在Qwen 3 VLモデルをサポートしており**、qwen3-vl:4bやqwen3-vl:8bのようなバリアントも含まれています。これらはローカルハードウェア向けに最適化された量子化バージョンであり、コンシューマーグレードのGPUや強力なラップトップでも実行できることを意味します。
Ollamaの背後にある技術的な魔法
Ollamaコマンドを実行すると、舞台裏で何が起こるのでしょうか?それは、よく振り付けられた技術プロセスのダンスを見ているようです。
1.モデルのダウンロードとキャッシュ:Ollamaはモデルの重みをインテリジェントにダウンロードしてキャッシュし、頻繁に使用されるモデルの高速起動時間を保証します。
2.量子化の最適化:モデルは、GPUとRAMに最適な量子化方法(4ビット、8ビットなど)を選択して、ハードウェア構成に合わせて自動的に最適化されます。
3.メモリ管理:高度なメモリマッピング技術により、高いパフォーマンスを維持しながらGPUメモリの効率的な使用を保証します。
4.並列処理:Ollamaは複数のCPUコアとGPUストリームを活用し、最大のスループットを実現します。
前提条件:インストール前に必要なもの
何かをインストールする前に、システムが準備できていることを確認しましょう。
ハードウェア要件
- RAM:最低16GB(8Bモデルには32GBを推奨)
- GPU:8GB以上のVRAMを搭載したNVIDIA GPU(Linux用)またはApple Silicon Mac(16GB以上のユニファイドメモリを搭載したM1/M2/M3)
- Storage:10~20GBの空き容量(モデルは大きい!)
ソフトウェア要件
- オペレーティングシステム:macOS(12以上)またはLinux(Ubuntu 20.04以上を推奨)
- Ollama:最新バージョン(Qwen 3 VLサポートにはv0.1.40以上)
- オプション:Docker(コンテナ化されたデプロイを好む場合)、Python(高度なスクリプト用)
ステップバイステップのインストールガイド:ローカルAIマスターへの道
ステップ1:Ollamaのインストール - 基盤
まずは、セットアップ全体の基盤から始めましょう。Ollamaのインストールは驚くほど簡単で、AI初心者から経験豊富な開発者まで、誰にでもアクセスできるように設計されています。
macOSユーザー向け:
1.ollama.com/downloadにアクセスします
2.macOSインストーラーをダウンロードします
3.ダウンロードしたファイルを開き、Ollamaをアプリケーションフォルダにドラッグします
4.アプリケーションフォルダまたはSpotlight検索からOllamaを起動します
macOSでのインストールプロセスは非常にスムーズで、インストールが完了するとメニューバーにOllamaアイコンが表示されます。
Windowsユーザー向け:
1.ollama.com/downloadに移動します
2.Windowsインストーラー(.exeファイル)をダウンロードします
3.管理者権限でインストーラーを実行します
4.インストールウィザードに従います(非常に直感的です)
5.インストール後、Ollamaはバックグラウンドで自動的に起動します
WindowsユーザーはWindows Defenderの通知を見るかもしれませんが、心配いりません。これは初回実行時には通常の動作です。「許可」をクリックするだけで、Ollamaは完璧に動作します。
Linuxユーザー向け:
Linuxユーザーには2つのオプションがあります:
オプションA:インストールスクリプト(推奨)
bash
curl -fsSL <https://ollama.com/install.sh> | sh
オプションB:手動インストール
bash
# Download the latest Ollama binarycurl -o ollama <https://ollama.com/download/ollama-linux-amd64>
# Make it executablechmod +x ollama
# Move to PATHsudo mv ollama /usr/local/bin/
ステップ2:インストールの確認
Ollamaがインストールされたので、すべてが正しく動作していることを確認しましょう。これは、基盤がしっかりしていることを確認するためのスモークテストだと考えてください。
ターミナル(Windowsではコマンドプロンプト)を開き、以下を実行します:
bash
ollama --version
以下のような出力が表示されるはずです:
ollama version is 0.1.0
次に、基本的な機能をテストしましょう:
bash
ollama serve
このコマンドはOllamaサーバーを起動します。サーバーがhttp://localhost:11434で実行されていることを示す出力が表示されるはずです。サーバーを実行したままにしておき、Qwen3-VLのインストールをテストするために使用します。
ステップ3:Qwen3-VLモデルのプルと実行
さあ、ここからが面白いところです!最初のQwen3-VLモデルをダウンロードして実行しましょう。まずは小さなモデルで試運転し、その後より強力なバリアントに移行します。
Qwen3-VL-4Bでのテスト(素晴らしい出発点):
bash
ollama run qwen3-vl:4b
このコマンドは以下を行います:
1.Qwen3-VL-4Bモデルをダウンロードします(約2.8GB)
2.ハードウェアに合わせて最適化します
3.インタラクティブなチャットセッションを開始します
他のモデルバリアントの実行:
より強力なハードウェアをお持ちの場合は、以下の代替案を試してみてください:
bash
# 8GB以上のGPUシステム向けollama run qwen3-vl:8b
# 16GB以上のRAMシステム向けollama run qwen3-vl:32b
# 複数のGPUを搭載したハイエンドシステム向けollama run qwen3-vl:30b-a3b
# 最大のパフォーマンス向け(高性能なハードウェアが必要)ollama run qwen3-vl:235b-a22b
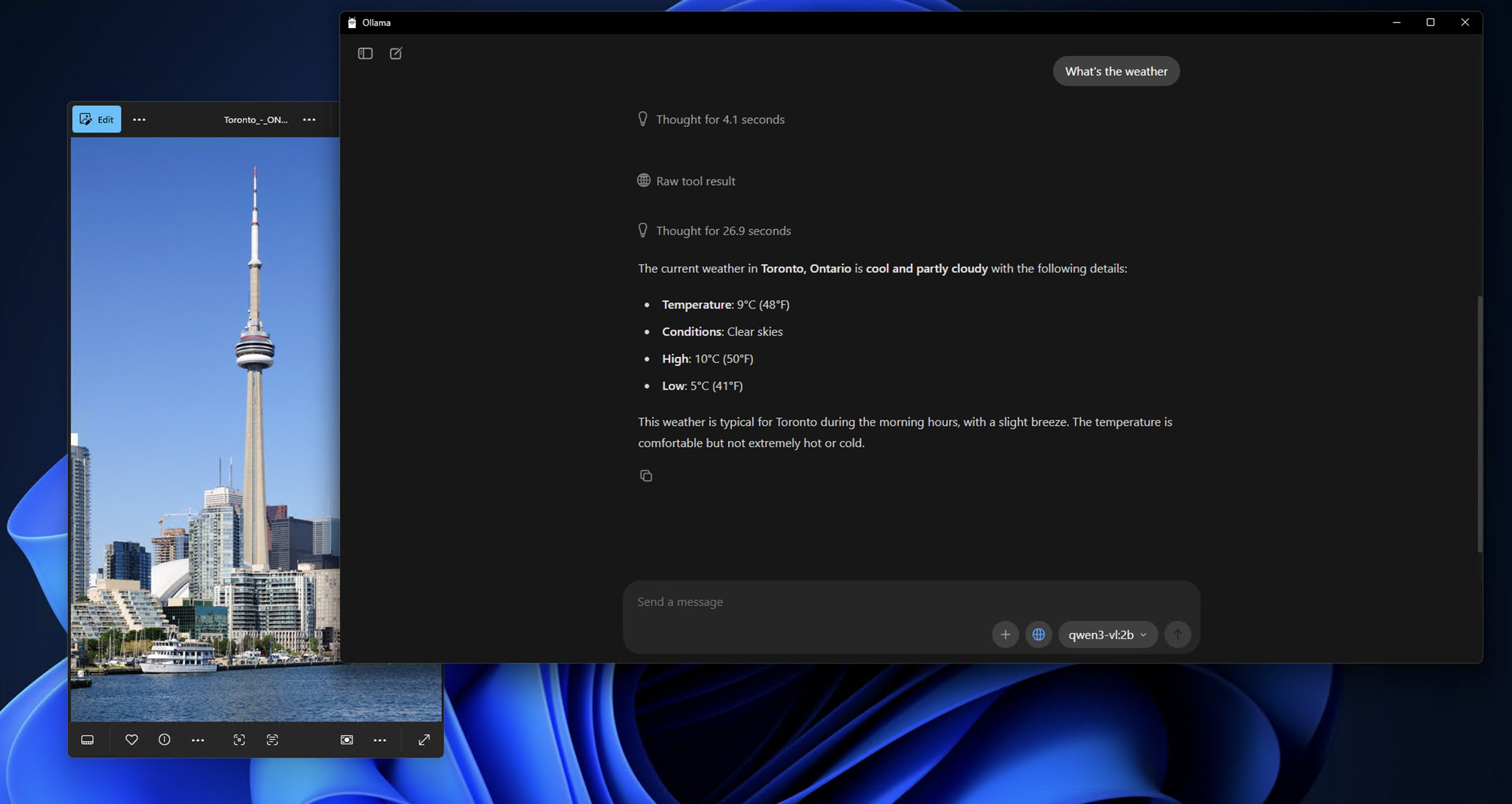
ステップ4:ローカルQwen3-VLとの最初の対話
モデルがダウンロードされ実行されると、次のようなプロンプトが表示されます:
Send a message (type /? for help)
簡単な画像分析でモデルの機能をテストしてみましょう:
テスト画像を準備する:
コンピュータ上の任意の画像を見つけてください。写真、スクリーンショット、イラストなど何でも構いません。この例では、現在のディレクトリにtest_image.jpgという画像があるものとします。

インタラクティブチャットテスト:
bash
What do you see in this image? /path/to/your/image.jpg
代替案:APIを使用したテスト
プログラムでテストしたい場合は、Ollama APIを使用できます。以下はcurlを使用した簡単なテストです:
bash
curl <http://localhost:11434/api/generate> \\
-H "Content-Type: application/json" \\
-d '{
"model": "qwen3-vl:4b",
"prompt": "What is in this image? Describe it in detail.",
"images": ["base64_encoded_image_data_here"]
}'

ステップ5:高度な設定オプション
インストールが完了したので、特定のハードウェアとユースケースに合わせてセットアップを最適化するための高度な設定オプションをいくつか見ていきましょう。
メモリ最適化:
メモリの問題が発生している場合は、モデルのロード動作を調整できます:
bash
# 最大メモリ使用量を設定(RAMに基づいて調整)export OLLAMA_MAX_LOADED_MODELS=1
# GPUオフロードを有効にするexport OLLAMA_GPU=1
# カスタムポートを設定(11434が既に使用されている場合)export OLLAMA_HOST=0.0.0.0:11435
量子化オプション:
VRAMが限られているシステムの場合、特定の量子化レベルを強制できます:
bash
# 4ビット量子化でモデルをロード(互換性が高く、遅い)ollama run qwen3-vl:4b --format json
# 8ビット量子化でロード(バランスが取れている)ollama run qwen3-vl:8b --format json
マルチGPU構成:
複数のGPUをお持ちの場合は、使用するGPUを指定できます:
bash
# 特定のGPU IDを使用(Linux/macOS)export CUDA_VISIBLE_DEVICES=0,1
ollama run qwen3-vl:30b-a3b
# 複数のApple Silicon GPUを搭載したmacOSの場合export CUDA_VISIBLE_DEVICES=0,1
ollama run qwen3-vl:30b-a3b
Apidogによるテストと統合:品質とパフォーマンスの確保

Qwen3-VLをローカルで実行できるようになったので、それを開発ワークフローに適切にテストし統合する方法について話しましょう。ここでApidogは、AI開発者にとって不可欠なツールとして真価を発揮します。
Apidogは単なるAPIテストツールではありません。現代のAPI開発ワークフローのために特別に設計された包括的なプラットフォームです。Qwen3-VLのようなローカルAIモデルを扱う場合、次のようなことができるツールが必要です。
- 複雑なJSON構造の処理:AIモデルの応答は、さまざまなコンテンツタイプを持つネストされたJSONを含むことがよくあります
- ファイルアップロードのサポート:多くのAIモデルは、画像、ビデオ、またはドキュメントの入力を必要とします
- 認証の管理:適切な認証処理によるエンドポイントの安全なテスト
- 自動テストの作成:モデルのパフォーマンスの一貫性のための回帰テスト
- ドキュメントの生成:テストケースからAPIドキュメントを自動的に作成
よくある問題のトラブルシューティング
Ollamaのシンプルさにもかかわらず、問題に遭遇するかもしれません。ここでは、頻繁に発生する問題の解決策を紹介します。
❌ 「モデルが見つかりません」または「サポートされていないモデル」
- Ollama v0.1.40以降を使用していることを確認してください
ollama pull qwen3-vl:4bを再度実行してください。ダウンロードがサイレントに失敗することがあります
❌ GPUで「メモリ不足」
- 8Bではなく4Bバージョンを試してください
- 他のGPU負荷の高いアプリ(Chrome、ゲームなど)を閉じます
- Linuxでは、
nvidia-smiでVRAMを確認します
❌ 画像が認識されない
- 画像が4MB未満であることを確認してください
- PNGまたはJPGを使用してください(HEIC、BMPは避けてください)
- base64文字列に改行がないことを確認してください(Linuxでは
base64 -w 0を使用)
❌ CPUでの推論が遅い
- Qwen 3 VLは量子化されていても大きいです。CPUでは1~5トークン/秒を想定してください
- 10倍の速度向上にはApple SiliconまたはNVIDIA GPUにアップグレードしてください
ローカルQwen 3 VLの現実世界のユースケース
なぜこれほどの手間をかけるのでしょうか?以下に実用的なアプリケーションを挙げます:
- ドキュメントインテリジェンス:スキャンされたPDFから表、署名、または条項を抽出
- アクセシビリティツール:視覚障害のあるユーザーのために画像を説明
- 社内ナレッジボット:社内図やダッシュボードに関する質問に回答
- 教育:写真から数学の問題を説明するチューターを構築
- セキュリティ分析:ネットワーク図やシステムアーキテクチャのスクリーンショットを分析
**ローカル**であるため、機密性の高い画像をサードパーティAPIに送信することを回避できます。これは企業やプライバシーを重視する開発者にとって大きな利点です。
結論:ローカルAIの卓越性への旅
おめでとうございます!あなたはQwen3-VLとOllamaを使ったローカルAIの世界への壮大な旅を終えたばかりです。これで、あなたは以下のものを手に入れたはずです:
- ローカルで動作する完全に機能するQwen3-VLのインストール
- Apidogによる包括的なテストセットアップ
- モデルの機能と制限に関する深い理解
- これらのモデルを現実世界のアプリケーションに統合するための実践的な知識
- よくある問題に対処するためのトラブルシューティングスキル
- 継続的な成功のための将来を見据えた戦略
ここまでたどり着いたという事実は、あなたが最先端のAI技術を理解し活用することへのコミットメントを示しています。あなたは単にモデルをインストールしただけでなく、視覚情報とテキスト情報の相互作用を再構築する技術に関する専門知識を習得したのです。
未来はローカルAI
ここで達成したことは、単なる技術的なセットアップ以上のものです。AIがアクセス可能で、プライベートで、個人の管理下にある未来への一歩を表しています。これらのモデルが改善され、より効率的になるにつれて、予算や技術的専門知識に関係なく、誰もが高度なAI機能を利用できる世界へと向かっています。
覚えておいてください、旅はここで終わりではありません。AI技術は急速に進化しており、好奇心を持ち、適応し、コミュニティと関わり続けることで、これらの強力なツールを効果的に活用し続けることができるでしょう。
最後に
Ollamaを使ってQwen 3 VLをローカルで実行することは、単なる技術デモや利便性、コスト削減だけではありません。それは、オンデバイスAIの未来を垣間見せるものです。モデルがより効率的になり、ハードウェアがより強力になるにつれて、より多くの開発者がプライベートなマルチモーダル機能をアプリに直接搭載するようになるでしょう。あなたは今、制限なくAI技術を探求し、自由に実験し、あなたとあなたの組織にとって重要なアプリケーションを構築するためのツールを手に入れました。
Qwen3-VLの印象的なマルチモーダル機能とOllamaのユーザーフレンドリーなインターフェースの組み合わせは、これまで莫大なリソースを持つ大企業にしか利用できなかったイノベーションの機会を生み出します。あなたは今、AI技術を民主化する開発者の成長するコミュニティの一員です。
そして、デプロイを簡素化する**Ollama**やAPI開発を効率化する**Apidog**のようなツールのおかげで、参入障壁はかつてないほど低くなっています。
ですから、あなたがソロハッカーであろうと、スタートアップの創業者であろうと、企業エンジニアであろうと、今こそビジョン言語モデルを安全に、手頃な価格で、そしてローカルで実験する絶好の機会です。