
MetaのLlama 3.2は、人工知能の分野で革命をもたらす言語モデルとして登場し、テキストと画像の処理において印象的な能力を提供しています。この高度なモデルの力をローカルマシンで活用したい開発者やAI愛好者のために、Ollamaがあります。この包括的なガイドでは、これらの強力なプラットフォームを使用してLlama 3.2をローカルに実行するプロセスを説明し、クラウドサービスに依存せずに最先端のAI技術を活用できるようにします。
Llama 3.2とは:AIイノベーションの最新情報
インストールプロセスに入る前に、Llama 3.2の特別な点を簡単に探ってみましょう:
- マルチモーダル機能:Llama 3.2はテキストと画像の両方を処理でき、AIアプリケーションの新しい可能性を開きます。
- 効率性の向上:レイテンシを削減してパフォーマンスを向上させるよう設計されており、ローカル展開に最適です。
- 様々なモデルサイズ:軽量な1Bおよび3Bモデルから複雑なタスク向けの強力な11Bおよび90Bバージョンまで、複数のサイズで利用可能です。
- 拡張コンテキスト:128Kのコンテキスト長をサポートし、より包括的な理解とコンテンツ生成が可能です。
では、Ollamaを使用してLlama 3.2をローカルで実行する方法を探ってみましょう。
OllamaでLlama 3.2を実行する
Ollamaは、大規模な言語モデルをローカルで実行するための強力で開発者に優しいツールです。以下は、Ollamaを使用してLlama 3.2をセットアップするためのステップバイステップガイドです:
ステップ1:Ollamaをインストール
まず、システムにOllamaをダウンロードしてインストールする必要があります:
- 公式のOllamaウェブサイトにアクセスします。
- オペレーティングシステムに適したバージョン(Windows、macOS、またはLinux)をダウンロードします。
- ウェブサイトに記載されたインストール手順に従います。
ステップ2:Llama 3.2モデルをプル
Ollamaがインストールされたら、ターミナルやコマンドプロンプトを開き、次のコマンドを実行します:
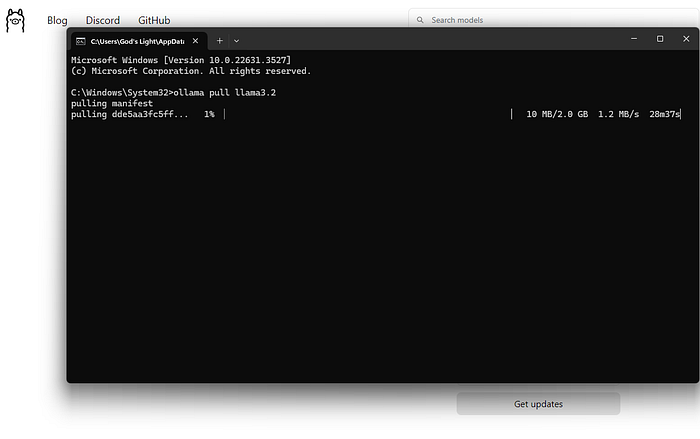
このコマンドは、Llama 3.2モデルをローカルマシンにダウンロードします。プロセスにはインターネット速度や選択したモデルサイズに応じて時間がかかる場合があります。
ステップ3:Llama 3.2をプル
モデルがダウンロードされたら、次の簡単なコマンドで使用を開始します:
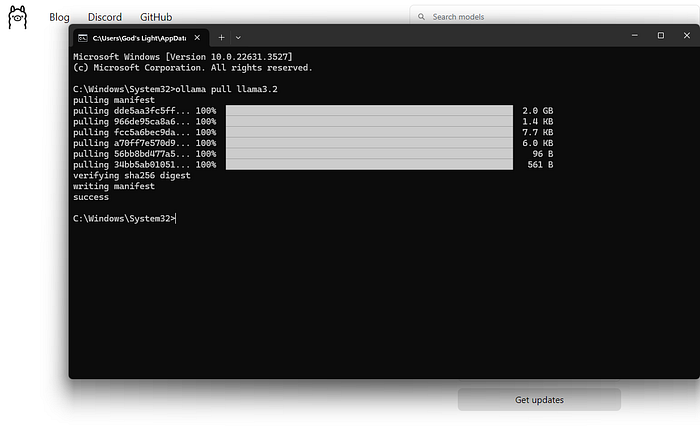
これで、プロンプトを入力してLlama 3.2からの応答を受け取るインタラクティブセッションに入ります。
Llama 3.2をローカルで実行するためのベストプラクティス
ローカルのLlama 3.2のセットアップを最大限に活用するために、以下のベストプラクティスを考慮してください:
- ハードウェアの考慮:マシンが最小要件を満たしていることを確認してください。専用GPUを使用すると、特に大きなモデルサイズの場合、パフォーマンスが大幅に向上します。
- プロンプトエンジニアリング:Llama 3.2からの最良の結果を得るために、明確で具体的なプロンプトを作成してください。出力品質を最適化するために、さまざまな表現を試してみてください。
- 定期的な更新:選択したツール(Ollama)とLlama 3.2モデルの両方を更新し、最高のパフォーマンスと最新の機能を確保してください。
- パラメーターの調整を試す:温度やトップpの設定を調整して、ユースケースに適したバランスを見つけることをためらわないでください。低い値は通常、より焦点を絞った決定論的な出力を生成し、高い値はより創造性と変動性を導入します。
- 倫理的な使用:AIモデルを責任を持って使用し、出力に潜在的なバイアスが存在する可能性を認識してください。本番環境にデプロイする場合は、追加の安全策やフィルターの導入を検討してください。
- データプライバシー:Llama 3.2をローカルで実行することは、データプライバシーを向上させます。特に機密情報を扱う際には、入力するデータとモデルの出力の使用に注意してください。
- リソース管理:Llama 3.2を実行している間、特に長時間や大きなモデルサイズで、システムリソースを監視してください。タスクマネージャーやリソース監視ツールを使用して、最適なパフォーマンスを確保することを考慮してください。
一般的な問題のトラブルシューティング
Llama 3.2をローカルで実行していると、一部の課題に直面することがあります。ここでは、一般的な問題に対する解決策を示します:
- パフォーマンスが遅い:
- 十分なRAMとCPU/GPUのパワーがあることを確認してください。
- 利用可能な場合は、より小さいモデルサイズ(例:3Bの代わりに11B)を使用してみてください。
- システムリソースを解放するために不要なバックグラウンドアプリケーションを閉じてください。
2. メモリ不足エラー:
- モデル設定でコンテキストの長さを減らしてください。
- 利用可能な場合は、より小さいモデルバリアントを使用してください。
- 可能であれば、システムのRAMをアップグレードしてください。
3. インストールの問題:
- システムがOllamaの最小要件を満たしているか確認してください。
- 使用しているツールの最新バージョンを持っていることを確認してください。
- 管理者権限でインストールを実行してみてください。
4. モデルのダウンロード失敗:
- インターネット接続の安定性を確認してください。
- ダウンロードを妨げている可能性のあるファイアウォールやVPNを一時的に無効にしてください。
- より良い帯域幅のために、オフピーク時間帯にダウンロードしてみてください。
5. 予期しない出力:
- プロンプトの明確さと特定性を確認し、改善してください。
- 出力のランダム性を制御するために温度や他のパラメーターを調整してください。
- 正しいモデルバージョンと設定を使用していることを確認してください。
ApidogでAPI開発を強化
Llama 3.2をローカルで実行することは強力ですが、アプリケーションに統合するには堅牢なAPI開発とテストが必要です。ここでApidogが登場します。Apidogは、ローカルLLM(Llama 3.2など)で作業する際にワークフローを大幅に強化できる包括的なAPI開発プラットフォームです。
ローカルLLM統合のためのApidogの主な機能:
- API設計とドキュメンテーション:Llama 3.2との統合のためにAPIを簡単に設計し文書化でき、ローカルモデルとアプリケーションの他の部分との間の明確なコミュニケーションを確保します。
- 自動テスト:Llama 3.2 APIエンドポイントの自動テストを作成して実行することで、モデルの応答の信頼性と一貫性を確保します。
- モックサーバー:Apidogのモックサーバー機能を使用して、開発中にLlama 3.2の応答をシミュレーションし、ローカルセットアップに即時にアクセスできない場合でも進捗を促進できます。
- 環境管理:Apidog内で異なる環境(例:ローカルLlama 3.2、プロダクションAPI)を管理し、開発およびテスト中に構成を簡単に切り替えます。
- コラボレーションツール:チームメンバーとLlama 3.2 APIの設計やテスト結果を共有し、AI駆動型プロジェクトでのより良いコラボレーションを促進します。
- パフォーマンスモニタリング:Llama 3.2 APIエンドポイントのパフォーマンスを監視し、応答時間やリソース使用を最適化します。
- セキュリティテスト:Llama 3.2 API統合のセキュリティテストを実施し、ローカルモデルのデプロイメントが脆弱性を引き起こさないようにします。
Llama 3.2開発のためのApidogの始め方:
- Apidogアカウントにサインアップします。
- Llama 3.2 API統合のための新しいプロジェクトを作成します。

- ローカルLlama 3.2インスタンスと対話するAPIエンドポイントを設計します。
- 異なる構成を管理するために環境を設定します(例:Ollama)。
- Llama 3.2統合が正しく機能することを確認するために、自動テストを作成します。
- 初期の開発段階でLlama 3.2の応答をシミュレートするためにモックサーバー機能を使用します。
- APIの設計やテスト結果を共有することでチームと協力します。

Apidogを利用しながらローカルのLlama 3.2セットアップを活用することで、より堅牢で文書化され、徹底的にテストされたAI駆動型アプリケーションを作成できます。
結論:ローカルAIの力を受け入れよう
Llama 3.2をローカルで実行することは、AI技術の民主化に向けた重要なステップを表しています。開発者フレンドリーなOllamaを選択すれば、自分のマシンで高度な言語モデルの力を活用するためのツールが揃います。
大規模な言語モデル(例えばLlama 3.2)のローカル展開は、始まりにすぎないことを忘れないでください。本当にAI開発で卓越するためには、Apidogのようなツールをワークフローに統合することを考慮してください。この強力なプラットフォームは、ローカルのLlama 3.2インスタンスと対話するAPIを設計、テスト、文書化するのを助け、開発プロセスを合理化し、AI駆動型アプリケーションの信頼性を保証します。
Llama 3.2との旅を始めるにあたり、常に実験を重ね、好奇心を持ち、AIを責任を持って使用するよう努めてください。AIの未来は単にクラウドにあるのではなく、あなたのローカルマシン上にあり、革新的なアプリケーションのために探求されるのを待っています。正しいツールとプラクティスを用いることで、ローカルAIの完全な可能性を引き出し、技術の可能性を押し広げる画期的なソリューションを作成できます。


