
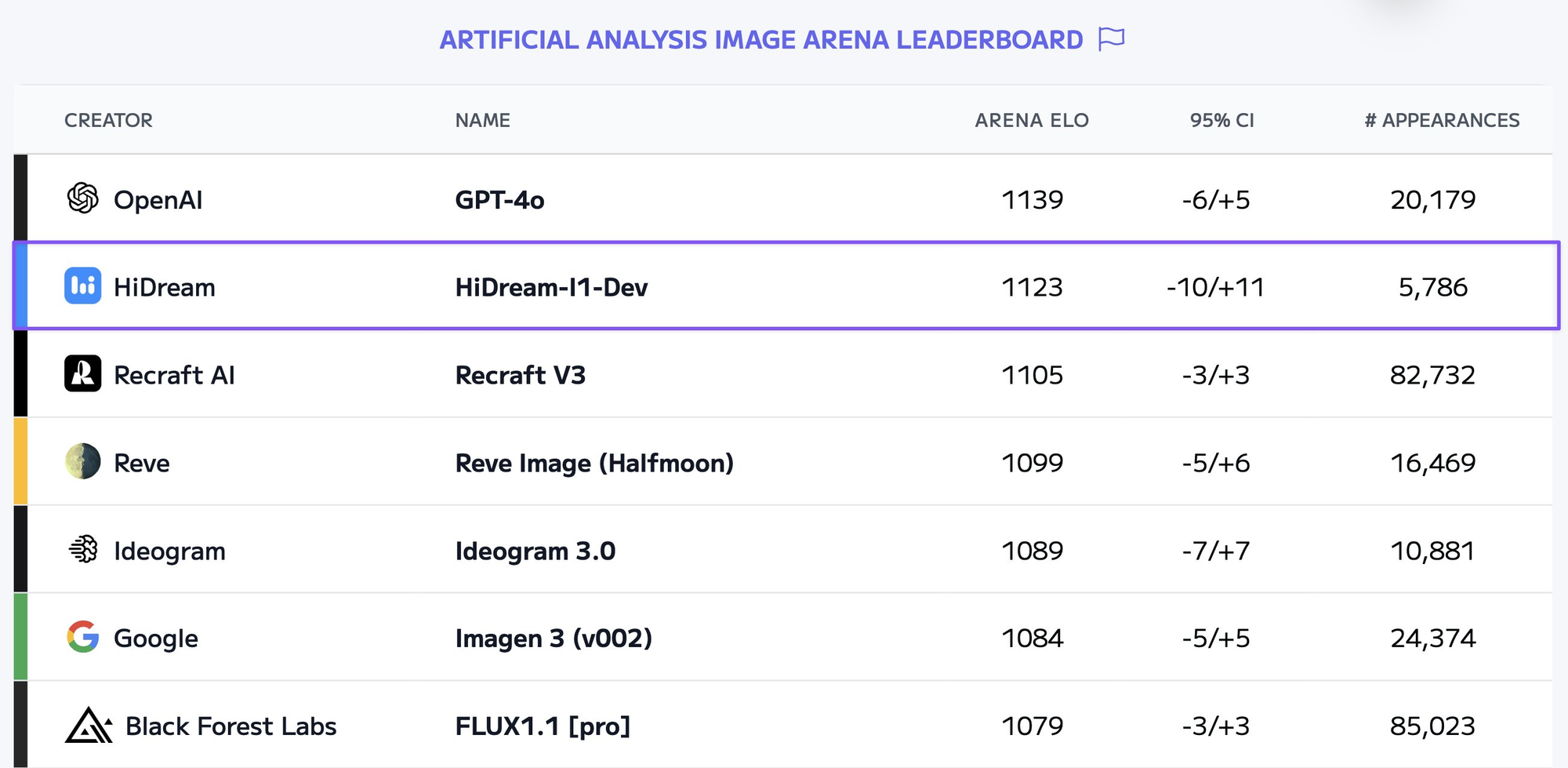
毎週、驚くべきビジュアルを生成できる新しいAI画像生成モデルが登場しています。その中の一つがHiDream-I1-Fullです。これらのモデルをローカルで実行することはリソース集約型ですが、APIを活用することで、この技術をアプリケーションやワークフローに便利でスケーラブルな形で統合することができます。
このチュートリアルでは以下のことを説明します:
- HiDream-I1-Fullの理解: それが何であり、その能力。
- APIオプション: HiDream-I1-FullをAPI経由で提供している人気のある2つのプラットフォーム、ReplicateとFal.aiを探る。
- Apidogによるテスト: Apidogツールを使用して、これらのAPIとインタラクションし、テストする方法をステップバイステップで案内します。
最大の生産性で開発チームが協力できる統合型のオールインワンプラットフォームを望んでいますか?
Apidogはすべての要求を満たし、Postmanをより手頃な価格で代替します!
対象読者: 開発者、デザイナー、AI愛好者、そして複雑なローカルセットアップなしで高度なAI画像生成を使用したい人々。
前提条件:
- API(HTTPリクエスト、JSON)の基本的な理解。
- APIキーを取得するためのReplicateおよび/またはFal.aiのアカウント。
- Apidogインストール済み(またはそのウェブ版へのアクセス)。
HiDream-I1-Fullとは何ですか?

HiDream-I1-Fullは、HiDream AIによって開発された先進的なテキストから画像への拡散モデルです。これは、テキスト説明(プロンプト)に基づいて高品質で一貫性のある、視覚的に魅力的な画像を生成するために設計されたモデルのファミリーに属します。

モデル詳細: 公式のモデルカードや技術情報はHugging Faceで確認できます:https://huggingface.co/HiDream-ai/HiDream-I1-Full
主な機能(このクラスのモデルに一般的):
- テキストから画像の生成: 詳細なテキストプロンプトから画像を生成します。
- 高解像度: 様々なアプリケーションに適したかなりの高解像度で画像を生成することができます。
- スタイルの遵守: プロンプト内のスタイルの手がかりを解釈できます(例:「ゴッホ風に」、「フォトリアリスティック」、「アニメ」)。
- 複雑なシーン構成: プロンプトの複雑さに基づいて、複数の主体、相互作用、詳細な背景を持つ画像を生成する能力。
- 制御パラメータ: 負のプロンプト(避けるべきもの)、シード(再現性のため)、ガイダンススケール(プロンプトにどれだけ従うか)、および特定のAPI実装に依存して画像から画像の変化や制御入力を通じて微調整を行うことができることが多いです。
APIを使用する理由は何ですか?
HiDream-I1-Fullのような大規模AIモデルをローカルで実行するには、かなりの計算リソース(強力なGPU、十分なRAM、ストレージ)と技術的な設定(依存関係、モデルウェイト、環境設定の管理)が必要です。APIを使用することで、いくつかの利点があります:
- ハードウェア要件なし: 計算を強力なクラウドインフラにオフロード。
- 拡張性: インフラを管理することなく、様々な負荷を簡単に処理。
- 統合の容易さ: 標準HTTPリクエストを使用して、Webサイト、アプリ、またはスクリプトに画像生成機能を統合。
- メンテナンス不要: APIプロバイダーがモデルの更新、メンテナンス、バックエンドの管理を行います。
- 使用量に応じた課金: よく、使用した計算時間のみに対して支払います。
HiDream-I1-FullをAPI経由で使用する方法
いくつかのプラットフォームがAIモデルをホストし、APIへのアクセスを提供しています。ここでは、HiDream-I1-Fullのための2つの人気の選択肢に焦点を当てます:
オプション1:ReplicateのHiDream APIを使用する
Replicateは、インフラを管理することなくシンプルなAPIを介して機械学習モデルを実行するのを容易にするプラットフォームです。彼らはコミュニティで公開されたモデルの膨大なライブラリをホストしています。
- HiDream-I1-FullのReplicateページ:https://replicate.com/prunaai/hidream-l1-full (注意:URLには
l1-fullと記載されていますが、これはReplicateでのHiDreamモデルのプロンプトに対して提供されている関連リンクです。このチュートリアルのための意図したモデルに対応するものと考えてください)。
Replicateの仕組み:
- 認証: Replicate APIトークンが必要で、これはアカウント設定内で見つけることができます。このトークンは
Authorizationヘッダーに渡されます。 - 予測の開始: Replicate APIエンドポイントにPOSTリクエストを送り、リクエストボディには、モデルバージョンと入力パラメータ(
prompt、negative_prompt、seedなど)が含まれます。 - 非同期操作: Replicateは通常非同期で動作します。最初のPOSTリクエストは直ちに予測IDとステータス確認用のURLを返します。
- 結果を取得: ステータスURL(最初の応答で提供されたもの)を使用して、ステータスが
succeeded(またはfailed)になるまでGETリクエストでポーリングが必要です。最終的な成功応答には生成された画像のURLが含まれます。
概念的なPython例(requestsを使用):
import requests
import time
import os
REPLICATE_API_TOKEN = "YOUR_REPLICATE_API_TOKEN" # 本番環境では環境変数を使用
MODEL_VERSION = "TARGET_MODEL_VERSION_FROM_REPLICATE_PAGE" # 例:"9a0b4534..."
# 1. 予測を開始
headers = {
"Authorization": f"Token {REPLICATE_API_TOKEN}",
"Content-Type": "application/json"
}
payload = {
"version": MODEL_VERSION,
"input": {
"prompt": "A majestic cyberpunk cityscape at sunset, neon lights reflecting on wet streets, detailed illustration",
"negative_prompt": "ugly, deformed, blurry, low quality, text, watermark",
"width": 1024,
"height": 1024,
"seed": 12345
# Replicateモデルページに基づいて必要な他のパラメータを追加
}
}
start_response = requests.post("<https://api.replicate.com/v1/predictions>", json=payload, headers=headers)
start_response_json = start_response.json()
if start_response.status_code != 201:
print(f"予測の開始中にエラーが発生しました: {start_response_json.get('detail')}")
exit()
prediction_id = start_response_json.get('id')
status_url = start_response_json.get('urls', {}).get('get')
print(f"予測はID: {prediction_id}で開始されました")
print(f"ステータスURL: {status_url}")
# 2. 結果をポーリング
output_image_url = None
while True:
print("ステータスを確認中...")
status_response = requests.get(status_url, headers=headers)
status_response_json = status_response.json()
status = status_response_json.get('status')
if status == 'succeeded':
output_image_url = status_response_json.get('output') # 通常はURLのリスト
print("予測に成功しました!")
print(f"出力: {output_image_url}")
break
elif status == 'failed' or status == 'canceled':
print(f"予測に失敗しましたまたはキャンセルされました: {status_response_json.get('error')}")
break
elif status in ['starting', 'processing']:
# 再度ポーリングする前に待機
time.sleep(5) # 必要に応じてポーリング間隔を調整
else:
print(f"不明なステータス: {status}")
print(status_response_json)
break
# 出力画像URLを使用することができます
価格設定: Replicateは、彼らのハードウェア上でのモデルの実行時間に基づいて課金します。詳細については、彼らの価格ページを確認してください。
オプション2:Fal.ai
Fal.aiは、APIを介してAIモデルの高速でスケーラブルかつコスト効果の高い推論を提供することに特化した別のプラットフォームです。彼らはしばしばリアルタイム性能を強調します。
Fal.aiの仕組み:
- 認証: Fal API資格情報(キーIDとキーシークレット)が必要で、通常は
KeyID:KeySecretとして組み合わされて渡されます。これはAuthorizationヘッダーで渡されます。 - APIエンドポイント: Fal.aiは特定のモデル機能に対する直接エンドポイントURLを提供します。
- リクエストフォーマット: モデルのエンドポイントURLにPOSTリクエストを送ります。リクエストボディは通常、モデルが要求する入力パラメータ(Replicateと同様の
promptなど)を含むJSONです。 - 同期 vs 非同期: Fal.aiは両方を提供することができます。画像生成のような長時間実行される可能性のあるタスクに対しては、以下が使用されることがあります:
- サーバーレス関数: 標準のリクエスト/レスポンスサイクルで、長いタイムアウトが設けられる場合があります。
- キュー: Replicateに似た非同期パターンで、ジョブを送信しリクエストIDを使用して結果をポーリングします。具体的なAPIページには、予想されるインタラクションパターンが詳述されています。
概念的なPython例(requestsを使用 - 非同期キューと仮定):
import requests
import time
import os
FAL_API_KEY = "YOUR_FAL_KEY_ID:YOUR_FAL_KEY_SECRET" # 環境変数を使用
MODEL_ENDPOINT_URL = "<https://fal.run/fal-ai/hidream-i1-full>" # Fal.aiでの正確なURLを確認
# 1. キューにリクエストを送信(例 - 正確な構造はFalのドキュメントを確認)
headers = {
"Authorization": f"Key {FAL_API_KEY}",
"Content-Type": "application/json"
}
payload = {
# Fal.aiのサーバーレス関数のためにパラメーターがペイロードに直接含まれることが多いです
# またはセットアップに応じて‘input’オブジェクト内にある場合があります。ドキュメントを確認してください!
"prompt": "A hyperrealistic portrait of an astronaut floating in space, Earth reflecting in the helmet visor",
"negative_prompt": "cartoon, drawing, illustration, sketch, text, letters",
"seed": 98765
# Fal.ai実装によってサポートされている他のパラメータを追加
}
# Fal.aiは非同期用に'/queue'や特定のクエリパラメータを追加する必要があります
# 例:POST <https://fal.run/fal-ai/hidream-i1-full/queue>
# 彼らのドキュメントを確認してください! ステータスURLを返すエンドポイントを仮定:
submit_response = requests.post(f"{MODEL_ENDPOINT_URL}", json=payload, headers=headers, params={"fal_webhook": "OPTIONAL_WEBHOOK_URL"}) # クエリパラメータのドキュメントを確認
if submit_response.status_code >= 300:
print(f"リクエストの送信中にエラーが発生しました: {submit_response.status_code}")
print(submit_response.text)
exit()
submit_response_json = submit_response.json()
# Fal.aiの非同期応答は異なる場合があります - リクエストIDや直接のステータスURLを返すことがあります
# この概念的な例では、Replicateに似たステータスURLを返すと仮定
status_url = submit_response_json.get('status_url') # またはリクエストIDから構築する、ドキュメントを確認
request_id = submit_response_json.get('request_id') # 代替識別子
if not status_url and request_id:
# ステータスURLを構築する必要があるかもしれません(例:<https://fal.run/fal-ai/hidream-i1-full/requests/{request_id}/status>)
# または一般的なステータスエンドポイントをクエリします:<https://fal.run/requests/{request_id}/status>
print("ステータスURLを構築する必要がありますまたはrequest_idを使用、Fal.aiのドキュメントを確認してください。")
exit() # Falのドキュメントに基づく具体的な実装が必要
print(f"リクエストが送信されました。ステータスURL: {status_url}")
# 2. 結果をポーリング(非同期の場合)
output_data = None
while status_url: # ステータスURLがある場合のみポーリング
print("ステータスを確認中...")
# ポーリングには認証が必要な場合があります
status_response = requests.get(status_url, headers=headers)
status_response_json = status_response.json()
status = status_response_json.get('status') # Fal.aiドキュメントでステータスキーを確認('COMPLETED', 'FAILED'など)
if status == 'COMPLETED': # 例のステータス
output_data = status_response_json.get('response') # または'result', 'output'、ドキュメントを確認
print("リクエストが完了しました!")
print(f"出力: {output_data}") # 出力構造はFal.aiのモデルに依存します
break
elif status == 'FAILED': # 例のステータス
print(f"リクエストに失敗しました: {status_response_json.get('error')}") # エラーフィールドを確認
break
elif status in ['IN_PROGRESS', 'IN_QUEUE']: # 例のステータス
# 再度ポーリングする前に待機
time.sleep(3) # ポーリング間隔を調整
else:
print(f"不明なステータス: {status}")
print(status_response_json)
break
# 出力データを使用します(これには画像のURLや他の情報が含まれている可能性があります)
価格設定: Fal.aiは通常、実行時間に基づいて料金を請求し、しばしば秒単位の請求があります。特定のモデルと計算リソースの価格詳細を確認してください。
ApidogでHiDream APIをテスト
Apidogは強力なAPI設計、開発、およびテストツールです。HTTPリクエストを送り、レスポンスを検査し、API詳細を管理するためのユーザーフレンドリーなインターフェースを提供し、ReplicateおよびFal.ai APIを統合する前のテストに最適です。
Apidogを使用したHiDream-I1-Full APIをテストする手順:
ステップ1. Apidogをインストールして開く: Apidogをダウンロードしてインストールするか、ウェブ版を使用します。必要に応じてアカウントを作成します。

ステップ2. 新しいリクエストを作成:
- Apidogで新しいプロジェクトを作成するか、既存のプロジェクトを開きます。
- 「+」ボタンをクリックして新しいHTTPリクエストを追加します。
ステップ3. HTTPメソッドとURLを設定:
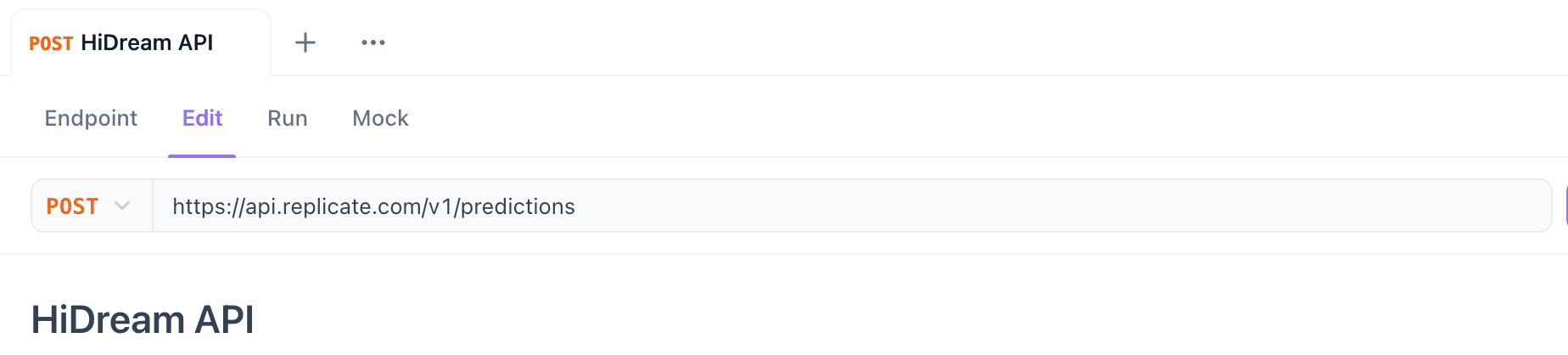
- メソッド:
POSTを選択します。 - URL: APIエンドポイントのURLを入力します。
- Replicateの場合(予測を開始):
https://api.replicate.com/v1/predictions - Fal.aiの場合(リクエストを送信): ページに提供された特定のモデルエンドポイントURLを使用します(例:
https://fal.run/fal-ai/hidream-i1-full- 非同期のために/queueやクエリパラメーターが必要かどうかを確認します)。
ステップ4. ヘッダーを設定:
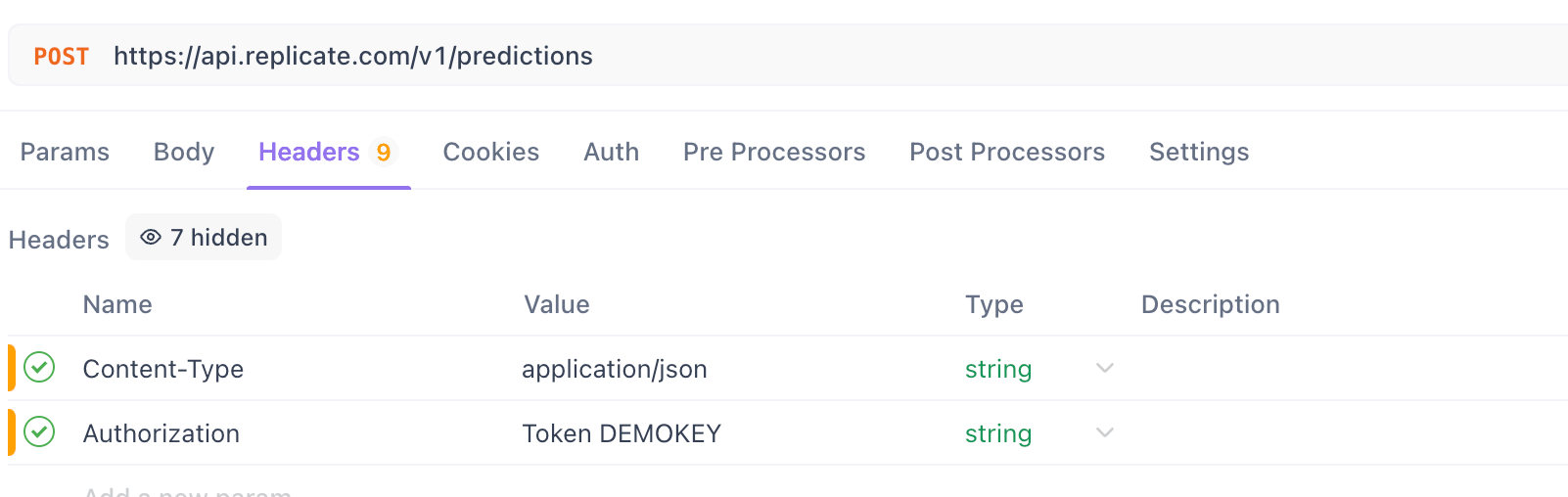
- ヘッダータブに移動します。
Content-Typeヘッダーを追加:
- キー:
Content-Type - 値:
application/json
Authorizationヘッダーを追加:
Replicateの場合:
- キー:
Authorization - 値:
Token YOUR_REPLICATE_API_TOKEN(実際のトークンに置き換えます)
Fal.aiの場合:
- キー:
Authorization - 値:
Key YOUR_FAL_KEY_ID:YOUR_FAL_KEY_SECRET(実際の資格情報に置き換えます) - プロのヒント: Apidogの環境変数を使用して、APIキーを直接リクエストにハードコーディングする代わりに安全に保存します。「Replicate Dev」や「Fal Dev」のような環境を作成し、
REPLICATE_TOKENやFAL_API_KEYのような変数を定義します。次に、ヘッダー値にToken {{REPLICATE_TOKEN}}またはKey {{FAL_API_KEY}}を使用します。
ステップ5. リクエストボディを設定:
Bodyタブに移動します。
rawフォーマットを選択し、ドロップダウンからJSONを選びます。
プラットフォームの要件に応じてJSONペイロードを貼り付けます。
Replicateの例JSONボディ:
{
"version": "PASTE_MODEL_VERSION_FROM_REPLICATE_PAGE_HERE",
"input": {
"prompt": "A watercolor painting of a cozy library corner with a sleeping cat",
"negative_prompt": "photorealistic, 3d render, bad art, deformed",
"width": 1024,
"height": 1024,
"seed": 55555
}
}
Fal.aiの例JSONボディ:
{
"prompt": "A watercolor painting of a cozy library corner with a sleeping cat",
"negative_prompt": "photorealistic, 3d render, bad art, deformed",
"width": 1024,
"height": 1024,
"seed": 55555
// Fal.aiのセットアップに応じて'model_name'のような他のパラメータが必要かもしれません
}
重要: 使用しているHiDream-I1-Fullモデルの正確に必要なおよびオプションのパラメータについては、ReplicateまたはFal.aiページの具体的なドキュメントを参照してください。guidance_scale、num_inference_stepsなどのパラメータが利用可能かもしれません。
ステップ6. リクエストを送信:
- 「送信」ボタンをクリックします。
- Apidogはレスポンスのステータスコード、ヘッダー、およびボディを表示します。
- Replicateの場合:
201 Createdステータスが得られるはずです。レスポンスボディには予測のidとurls.getのURLが含まれます。このgetのURLをコピーします。 - Fal.aiの場合(非同期):
200 OKまたは202 Acceptedが得られるかもしれません。レスポンスボディにはrequest_id、直接のstatus_url、またはその実装に応じた他の詳細が含まれるかもしれません。必要なポーリング用の関連URLまたはIDをコピーします。同期の場合、処理後に結果が直接得られるかもしれません(画像生成には可能性が低いですが)。
結果をポーリング(非同期API用):
- Apidogで別の新しいリクエストを作成します。
- メソッド:
GETを選択します。 - URL: 最初の応答からコピーした
ステータスURLを貼り付けます(例:Replicateのurls.getまたはFal.aiのステータスURL)。Fal.aiがrequest_idを与えた場合、そのドキュメントに従ってステータスURLを構築します(例:https://fal.run/requests/{request_id}/status)。 - ヘッダーを設定: POSTリクエストと同じ
Authorizationヘッダーを追加します(GETには通常Content-Typeは必要ありません)。 - リクエストを送信:「送信」をクリックします。
- レスポンスを確認: JSONレスポンスの
statusフィールドをチェックします。 - もし
processing、starting、IN_PROGRESS、IN_QUEUEなどの場合は、数秒待ってから「送信」をもう一度クリックします。 - もし
succeededまたはCOMPLETEDの場合は、生成された画像のURLを含むoutputフィールド(Replicate)またはresponse/resultフィールド(Fal.ai)を探します。 - もし
failedまたはFAILEDの場合は、詳細を確認するためにerrorフィールドをチェックします。
画像を表示: 最終的な成功応答から画像のURLをコピーし、ウェブブラウザに貼り付けて生成された画像を表示します。
最大の生産性で開発チームが協力できる統合型のオールインワンプラットフォームを望んでいますか?
Apidogはすべての要求を満たし、Postmanをより手頃な価格で代替します!

結論
HiDream-I1-Fullは強力な画像生成能力を提供し、ReplicateやFal.aiのようなプラットフォームからAPIを使用することで、この技術を複雑なインフラを管理することなく利用可能にします。APIワークフロー(リクエスト、ポーリングの可能性、レスポンス)を理解し、Apidogのようなツールをテストに活用することで、最先端のAI画像生成をプロジェクトに簡単に取り入れることができます。
ReplicateやFal.aiの特定のドキュメントを常に確認して、最新のエンドポイントURL、必要なパラメータ、認証方法、価格詳細を確認してください。これらは時間とともに変更される可能性があります。生成を楽しんでください!