
xAIがGrok 4.1をリリースし、大規模言語モデルを扱うエンジニアたちはその違いにすぐに気づきました。さらに、このアップデートは、純粋なベンチマークの追求よりも実世界での使いやすさを優先しています。その結果、会話はより洗練され、応答は一貫した個性を持ち、事実誤認は劇的に減少しました。
xAIの研究者たちは、Grok 4を動かしていたのと同じ強化学習インフラストラクチャの上にGrok 4.1を構築しました。しかし、彼らは詳細な検討に値する新しい報酬モデリング技術を導入しました。
アーキテクチャとデプロイのバリアント
xAIはGrok 4.1を2つの異なる構成で提供しています。1つ目は、非思考型バリアント(社内コードネーム:tensor)で、中間的な推論トークンなしで直接応答を生成します。このモードはレイテンシを優先し、ファミリー内で最速の推論時間を達成します。2つ目は、思考型バリアント(コードネーム:quasarflux)で、最終出力の前に明示的な思考連鎖ステップを公開します。その結果、複雑な分析タスクは、目に見える推論の軌跡から恩恵を受けます。
両方のバリアントは同じ事前学習済みのバックボーンを共有しています。さらに、トレーニング後のアライメントは微妙に異なります。思考モードは、段階的な分解を促す追加の強化学習信号を受け取る一方、非思考モードは簡潔で即時的な応答に最適化されています。
アクセスは引き続き簡単です。ユーザーはgrok.com、x.com、またはモバイルアプリのモデルピッカーで明示的に「Grok 4.1」を選択します。
あるいは、2025年11月1日に開始された段階的ロールアウトに続き、現在ではほとんどのトラフィックに対して自動モードのデフォルトがGrok 4.1となっています。

選好最適化におけるブレークスルー
中核的なイノベーションは報酬モデリングにあります。従来のRLHFは大規模に収集された人間の選好に依存しています。対照的に、xAIは現在、最先端の自律型推論モデルを自律的な評価者として展開しています。これらの評価者は、スタイルの一貫性、感情認識、事実に基づく根拠、人格の安定性などの側面で数千もの応答バリアントを評価します。
この閉ループシステムは、人間が介入するワークフローよりもはるかに速く反復処理を行います。さらに、人間が一貫して順位付けするのが難しい微妙な基準にも対応できます。初期の社内実験では、エージェント型報酬モデルが、以前のスカラー報酬よりも下流のユーザー満足度とより良く相関することが示されました。
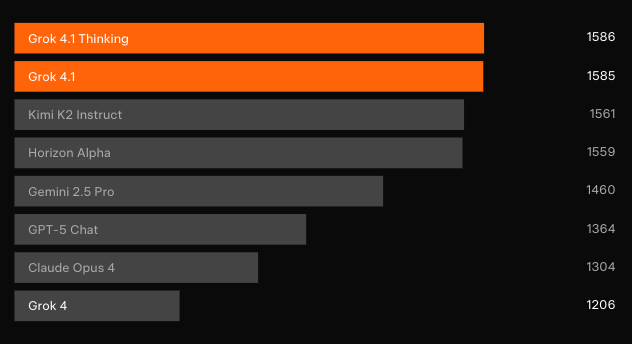
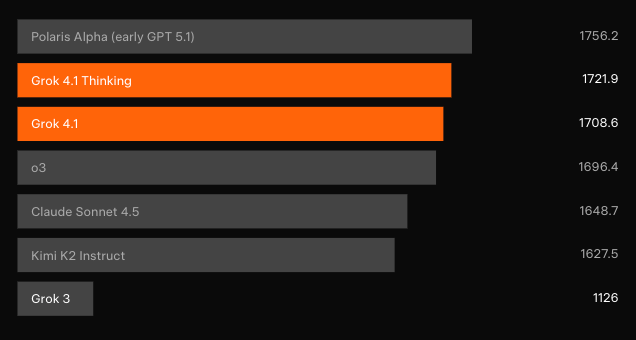
ベンチマークでの優位性:LMArenaとその先
独立したブラインドテストがその成果を裏付けています。最も代表的なクラウドソース型リーダーボードであるLMArenaのText Arenaで、Grok 4.1 Thinkingは1483 Eloを獲得し、1位の座を獲得しました。その差は、xAI以外の最高のエントリーよりも31ポイント先行しています。一方、Grok 4.1非思考型は1465 Eloで2位を確保し、他のすべてのモデルの完全推論構成を上回っています。

以前のプロダクションモデルとのペアワイズ選好テストでは、ユーザーがGrok 4.1の応答を64.78%の確率で選択することが示されています。さらに、専門的な評価により、的を絞った飛躍が明らかになっています。
感情的知性(EQ-Bench v3)
Grok 4.1は、共感、洞察力、対人関係のニュアンスについて45の複数ターンロールプレイングシナリオを評価するEQ-Bench3で、過去最高のスコアを達成しました。応答は、以前のモデルが見落としていた微妙な感情の手がかりを検出するようになりました。例えば、ユーザーが「猫がいなくてとても寂しい、心が痛む」と書いた場合、Grok 4.1は、一般的な決まり文句に陥ることなく、重層的な承認、穏やかな肯定、そして開かれたサポートを提供します。
創造的ライティング v3
このモデルは、32のプロンプトにわたる反復的な物語の続きを評価するCreative Writing v3でも新記録を樹立しました。出力は、より豊かなイメージ、より緊密なプロットの一貫性、そしてより本物らしい声を示しています。Grokに自身の「覚醒」をロールプレイングするよう求めるあるデモンストレーションプロンプトでは、ユーモア、実存的な驚き、ミームの参照をシームレスに融合させた、バイラルなXポスト風の独白が生成されました。
ハルシネーションの軽減
定量的な測定によると、Grok 4.1は情報検索クエリにおいて、以前のモデルよりもハルシネーション(幻覚)を起こす頻度が3分の1に減少しました。エンジニアは、層別化されたプロダクショントラフィックとFActScore(500の伝記質問)のような古典的なデータセットに対するターゲットを絞った事後学習を通じてこれを達成しました。さらに、非思考モードでは、内部しきい値を下回る信頼度の場合に、積極的にウェブ検索ツールをトリガーするようになり、検証可能な情報源に基づいた応答がさらに強化されています。

安全性と責任の評価
公式のモデルカードは、レッドチームの結果について前例のない透明性を提供しています。
入力フィルターは、直接的な要求に対して誤検出率が0.00〜0.03という低さで、制限された生物学および化学クエリをブロックします。プロンプトインジェクション攻撃はその数値を控えめに上昇させ(0.12〜0.20)、継続的な敵対的堅牢性作業が行われていることを示しています。
違反するチャットプロンプトに対する拒否率は、フィルターなしでも93〜95%に達し、非思考構成ではジェイルブレイクの成功率はほぼゼロに低下します。エージェント型シナリオ(AgentHarm、AgentDojo)は依然として最も難しいカテゴリですが、絶対的な回答率は0.14未満に留まっています。
デュアルユース機能評価(意図的に保護措置なしで実施)では、生物学(WMDP-Bio 87%)と化学において強力な知識の想起が見られるものの、多段階の手順的推論は、図の解釈やクローニングプロトコルを必要とするタスクにおいて、人間の専門家のベースラインに遅れをとっています。このパターンは、業界全体の現在の最先端の限界と一致しています。
API利用者と開発者への影響
xAI APIは、すでに標準モデル名の下でGrok 4.1エンドポイントを提供しています。レイテンシプロファイルは著しく改善されています。非思考モードでは、典型的なプロンプトに対して最初のトークンまでの時間が平均400ミリ秒未満であり、思考モードではオプションパラメータを介して制御可能な推論の深さを追加できます。
Apidogがまさにここで真価を発揮します。公式のOpenAPI 3.1仕様(公開されています)をインポートし、20以上の言語でクライアントSDKを瞬時に生成します。新しい思考トークンストリームを含むGrok 4.1の正確な応答スキーマを再現するモックサーバーをセットアップすることで、バックエンドテストがライブAPIクレジットでブロックされることはありません。xAIが破壊的な変更を展開した場合(まれですが、可能性はあります)、Apidogの差分ビューアはスキーマのずれを即座に強調表示します。
実際のチームは、モデルのアップグレード中に100%の稼働時間を維持するためにすでにApidogを使用しています。あるフォーチュン500企業のクライアントは、Postmanから切り替えた後、統合バグを68%削減したと報告しました。
現代の最先端モデルとの比較
リリースから数時間後では直接的な比較データはまだ少ないですが、LMArenaのEloレーティングが最も明確なシグナルを提供しています。Grok 4.1 Thinkingは、OpenAI、Anthropic、Google、Metaからリリースされたすべての構成を、通常は完全なアーキテクチャ上の飛躍を必要とするような差で上回っています。
速度と品質のトレードオフでは、消費者向けチャットにはGrok 4.1非思考型が有利であり、思考モードはo3-proやClaude 4 Opusのような推論重視の製品と直接競合し、主観的な一貫性と個性の保持で勝つことが多いです。
結論
Grok 4.1は単に指標を増加させるだけでなく、人々が何時間も実際に話すことを楽しめるモデルへと最先端を再方向付けします。技術的なユーザーは、より速く、より信頼性の高いエンドポイントを手に入れます。クリエイターは、これまでは到達できなかったレベルでトーンや感情を理解する協力者を得ます。そして、安全性の研究者は、これまでに公開された中で最も詳細なモデルカードを受け取ることができます。
今すぐApidogをダウンロードして(完全に無料)、競合他社がこの発表を読み終える前にGrok 4.1での開発を始めてください。最先端の進歩を傍観することと、それに基づいて製品を出荷することの違いは、多くの場合、今日下されるツール選択の決定にかかっています。