
OpenAIのgpt-oss-safeguardモデルは、分類タスクにおけるポリシーベースの推論を可能にすることで、このニーズに対応します。エンジニアはこれらのモデルを統合して、ユーザー生成コンテンツを分類し、違反を検出し、プラットフォームの整合性を維持します。
GPT-OSS-Safeguardの理解:機能と能力
OpenAIのエンジニアは、安全性分類に特化したオープンウェイト推論モデルとしてgpt-oss-safeguardを開発しました。これらはgpt-ossベースからファインチューニングされ、Apache 2.0ライセンスの下でリリースされています。開発者はHugging Faceからモデルをダウンロードし、自由にデプロイできます。ラインナップにはgpt-oss-safeguard-20bとgpt-oss-safeguard-120bが含まれ、数字はパラメータの規模を示します。
これらのモデルは、開発者が定義したポリシーと評価対象のコンテンツという2つの主要な入力を処理します。システムは、思考連鎖推論を適用してポリシーを解釈し、コンテンツを分類します。例えば、ユーザーメッセージがゲームフォーラムでのチートに関するルールに違反しているかどうかを判断します。このアプローチにより、従来の分類器が要求する再トレーニングなしで動的なポリシー更新が可能になります。
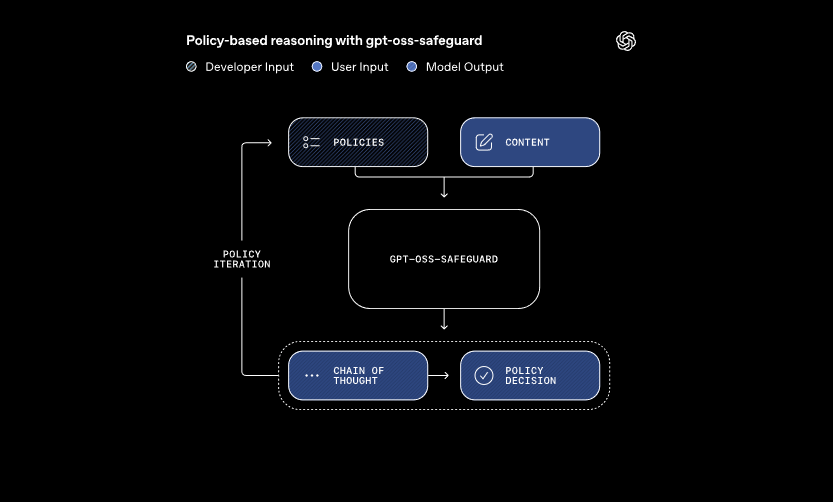
さらに、gpt-oss-safeguardは複数のポリシーを同時にサポートします。開発者は複数のルールを単一の推論呼び出しに供給し、モデルはそれらすべてに対してコンテンツを評価します。この機能は、誤情報や有害な発言など、多様なリスクを扱うプラットフォームのワークフローを効率化します。ただし、ポリシーを追加するとパフォーマンスがわずかに低下する可能性があるため、チームは構成を徹底的にテストします。
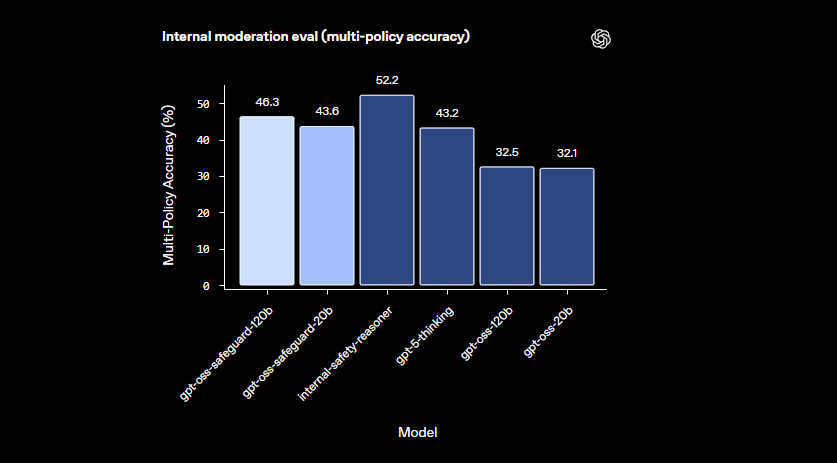
これらのモデルは、小規模な分類器が失敗するような微妙な領域で優れています。改訂されたポリシーに迅速に適応することで、新たな危害にも対応します。さらに、思考連鎖の出力は透明性を提供し、開発者は推論の追跡をレビューして決定を監査できます。この機能は、説明可能なAIを必要とするコンプライアンスチームにとって非常に貴重です。
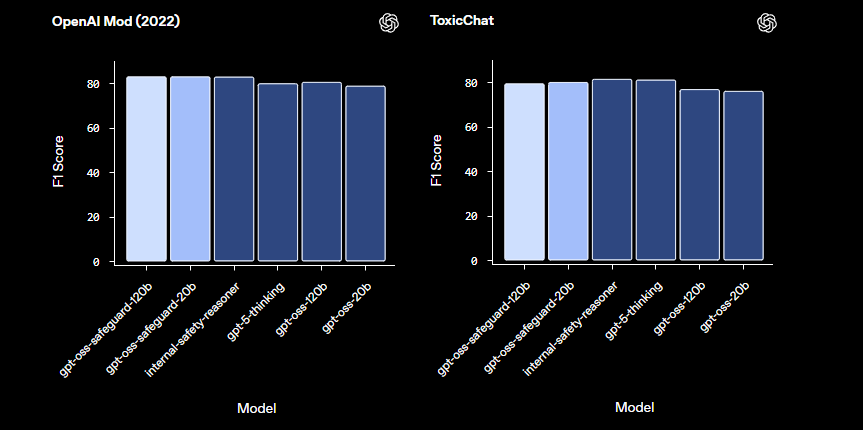
LlamaGuardのような事前構築された安全性モデルと比較して、gpt-oss-safeguardはより高度なカスタマイズ性を提供します。固定された分類法を避け、組織が独自の閾値を定義できるようにします。その結果、スケーラブルなモデレーションパイプラインを構築するTrust & Safetyエンジニアに適しています。基本を理解したところで、環境設定に進みましょう。
GPT-OSS-Safeguard APIアクセス環境のセットアップ
開発者は、gpt-oss-safeguardを実行するためのシステムを準備することから始めます。モデルはオープンウェイトであるため、ローカルまたはホスト型プロバイダー経由でデプロイできます。この柔軟性により、個人用マシンからクラウドサーバーまで、さまざまなハードウェア設定に対応できます。
まず、必要な依存関係をインストールします。Python 3.10以降がベースとなります。pipを使用してHugging Face Transformersなどのライブラリを追加します: pip install transformers。推論を高速化するには、互換性のあるGPUを所有している場合、CUDAサポート付きのtorchを含めます。NVIDIAハードウェアを持つエンジニアは、より高速な処理のためにこれを有効にします。
次に、Hugging Faceからモデルをダウンロードします。コレクションにアクセスしてください。リソース要件が少ない場合はgpt-oss-safeguard-20bを、優れた精度が必要な場合はgpt-oss-safeguard-120bを選択します。コマンドtransformers-cli download openai/gpt-oss-safeguard-20bでファイルが取得されます。
APIを公開するには、ローカルサーバーを実行します。vLLMのようなツールがこれを効率的に処理します。pip install vllmでvLLMをインストールします。次に、サーバーを起動します: vllm serve openai/gpt-oss-safeguard-20b。このコマンドは、http://localhost:8000/v1でOpenAI互換のエンドポイントを開始します。同様に、Ollamaはデプロイを簡素化します: ollama run gpt-oss-safeguard:20b。これは統合用のREST APIを提供します。
ローカルテストには、LM Studioがユーザーフレンドリーなインターフェースを提供します。lms get openai/gpt-oss-safeguard-20bを実行してモデルを取得します。このソフトウェアはOpenAIのChat Completions APIをエミュレートするため、コードを本番環境にシームレスに移行できます。
ホスト型オプションはハードウェアの懸念を解消します。Groqのようなプロバイダーは、APIを通じてgpt-oss-safeguard-20bをサポートしています。https://console.groq.comでサインアップし、APIキーを生成して、リクエストでモデルをターゲットにします。料金は100万入力トークンあたり0.075ドルから始まります。OpenRouterもホストしています。
セットアップが完了したら、インストールを確認します。curl経由でテストリクエストを送信します: curl http://localhost:8000/v1/chat/completions -H "Content-Type: application/json" -d '{"model": "openai/gpt-oss-safeguard-20b", "messages": [{"role": "system", "content": "Test policy"}, {"role": "user", "content": "Test content"}]}'。成功した応答があれば、準備完了です。環境が構成されたら、次にポリシーを作成します。
GPT-OSS-Safeguardのための効果的なポリシーの作成
ポリシーはgpt-oss-safeguardの運用の基盤を形成します。開発者は、分類をガイドする構造化されたプロンプトとしてポリシーを記述します。適切に設計されたポリシーは、モデルの推論能力を最大限に引き出し、正確で説明可能な出力を保証します。
ポリシーを明確なセクションで構成します。まず「Instructions(指示)」でモデルのタスクを指定します。例えば、コンテンツを違反(1)または安全(0)として分類するように指示します。次に「Definitions(定義)」で「非人間的な言葉」のような主要な用語を明確にします。その後、違反と安全なコンテンツの「Criteria(基準)」を概説します。最後に「Examples(例)」を含め、適切にラベル付けされた4〜6の境界線上のケースを提供します。
ポリシーでは能動態を使用します:「暴力を助長するコンテンツにフラグを立てる」など、受動態の代替表現は避けてください。言語は正確に保ち、「一般的に安全でない」のような曖昧さを避けます。ルール間に競合が生じた場合は、優先順位を明示的に定義します。複数ポリシーのシナリオでは、システムメッセージ内でそれらを連結します。
「reasoning_effort」パラメータを介して推論の深さを制御します。複雑なケースには「high」を、速度を優先する場合は「low」に設定します。gpt-oss-safeguardに組み込まれているハーモニーフォーマットは、推論と最終出力を分離します。これにより、監査証跡を保持しつつ、クリーンなAPI応答が保証されます。
ポリシーの長さを400〜600トークン程度に最適化します。短すぎるポリシーは過度に単純化されるリスクがあり、長すぎるポリシーはモデルを混乱させる可能性があります。反復的にテストし、サンプルコンテンツを分類し、出力に基づいて調整します。Hugging Faceのトークンカウンターのようなツールがここで役立ちます。
出力形式については、シンプルさのためにバイナリを選択します: Return exactly 0 or 1.。詳細な根拠を追加するには: {"violation": 1, "rationale": "Explanation here"}。このJSON構造はダウンストリームシステムと容易に統合できます。ポリシーを洗練させたら、API実装に移行します。
GPT-OSS-SafeguardでのAPI呼び出しの実装
開発者は、OpenAI互換のエンドポイントを介してgpt-oss-safeguardと対話します。ローカルであろうとホスト型であろうと、プロセスは標準的なチャット補完パターンに従います。
クライアントを準備します。Pythonでは、OpenAIをインポートします: from openai import OpenAI。ベースURLとキーで初期化します: ローカルの場合はclient = OpenAI(base_url="http://localhost:8000/v1", api_key="dummy")、またはプロバイダー固有の値を使用します。
メッセージを構築します。システムロールにはポリシーが含まれます: {"role": "system", "content": "Your detailed policy here"}。ユーザーロールにはコンテンツが含まれます: {"role": "user", "content": "Content to classify"}。
APIを呼び出します: completion = client.chat.completions.create(model="openai/gpt-oss-safeguard-20b", messages=messages, max_tokens=500, temperature=0.0)。temperatureを0に設定することで、安全性タスクにおいて決定論的な出力が保証されます。
応答をパースします: result = completion.choices[0].message.content。構造化された出力にはJSONパースを使用します。Groqはプロンプトキャッシングでこれを強化し、呼び出し間でポリシーを再利用することでコストを50%削減します。
リアルタイムフィードバックのためにストリーミングを処理します: stream=Trueを設定し、チャンクを反復処理します。これは大量のモデレーションに適しています。
gpt-oss-safeguardは分類に焦点を当てていますが、必要に応じてツールを組み込みます。外部データの取得など、拡張機能のためにtoolsパラメータで関数を定義します。
トークン使用量を監視します。入力にはポリシーとコンテンツが含まれ、出力には推論が追加されます。オーバーフローを防ぐためにmax_tokensを制限します。API呼び出しを習得したら、例を探索します。
GPT-OSS-Safeguard APIの高度な機能
gpt-oss-safeguardは、洗練された制御のための高度なツールを提供します。Groqのプロンプトキャッシングはポリシーを再利用し、レイテンシとコストを削減します。
システムメッセージでreasoning_effortを調整します。詳細な分析には「Reasoning: high」を設定します。これにより、曖昧なコンテンツをより適切に処理できます。
長いチャットやドキュメントには128kのコンテキストウィンドウを活用します。全体的な分類のために会話全体を供給します。
より大規模なシステムと統合します。出力をエスカレーションキューやロギングにパイプします。リアルタイムアラートにはWebhookを使用します。
ベースモデルはポリシーの遵守に優れていますが、必要に応じてさらにファインチューニングします。計算を最適化するために、より小さなモデルと組み合わせて事前フィルタリングを行います。
セキュリティは重要です。APIキーを保護し、プロンプトインジェクションを監視します。エクスプロイトを防ぐために入力を検証します。
スケーリング: 高スループットのためにvLLMを使用してクラスターにデプロイします。Groqのようなプロバイダーは1000トークン/秒以上の速度を提供します。
これらの機能により、gpt-oss-safeguardは基本的な分類器からエンタープライズツールへと進化します。ただし、最適な結果を得るためにはベストプラクティスに従ってください。
GPT-OSS-Safeguardのベストプラクティスと最適化
エンジニアはポリシーを反復的に改善することでgpt-oss-safeguardを最適化します。多様なデータセットでテストし、F1スコアなどのメトリクスで精度を測定します。
モデルサイズのバランスを取ります。速度重視の場合は20bを、精度重視の場合は120bを使用します。メモリフットプリントを削減するために重みを量子化します。
パフォーマンスを監視します。監査のために推論トレースをログに記録します。温度は最小限に調整します。0.0は決定論的なニーズに適しています。
制限事項への対処: モデルは非常に専門的なドメインでは苦戦する可能性があります。ドメインデータで補完します。
倫理的な使用を確保します。ポリシーを規制に合わせます。例を多様化することでバイアスを回避します。
定期的に更新します。OpenAIがgpt-oss-safeguardを進化させるにつれて、改善を取り入れます。
コスト管理: ホスト型APIの場合、トークンの使用量を追跡します。ローカルデプロイは費用を最小限に抑えます。
これらの実践を適用することで、効率を最大化できます。要するに、gpt-oss-safeguardは堅牢な安全性システムを強化します。
結論:ワークフローへのGPT-OSS-Safeguardの統合
開発者はgpt-oss-safeguardを活用して、適応性の高い安全性分類器を構築します。セットアップから高度な使用法まで、このガイドは技術的な知識を提供します。ポリシーを実装し、API呼び出しを実行し、ニーズに合わせて最適化してください。プラットフォームが進化するにつれて、gpt-oss-safeguardはシームレスに適応し、安全な環境を確保します。